How Well Can Your Video Model Remember? Measuring Memory-Budget Trade-offs in Long Video Understanding
Pith reviewed 2026-06-26 21:49 UTC · model grok-4.3
The pith
Video models' recall accuracy scales linearly with log frame budget, but the slope falls log-linearly with temporal distance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
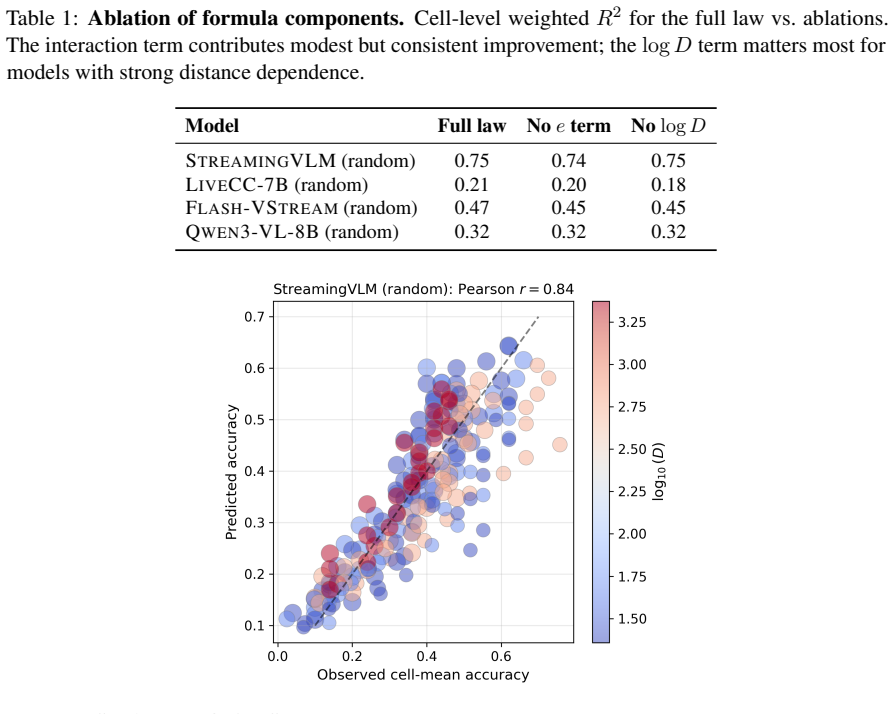
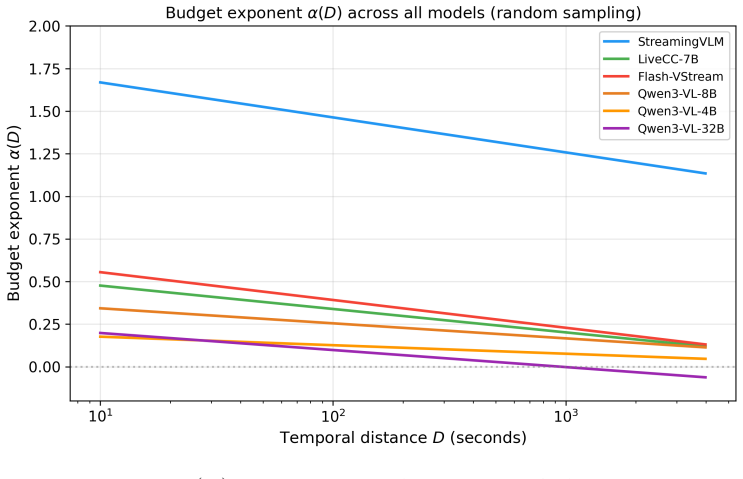
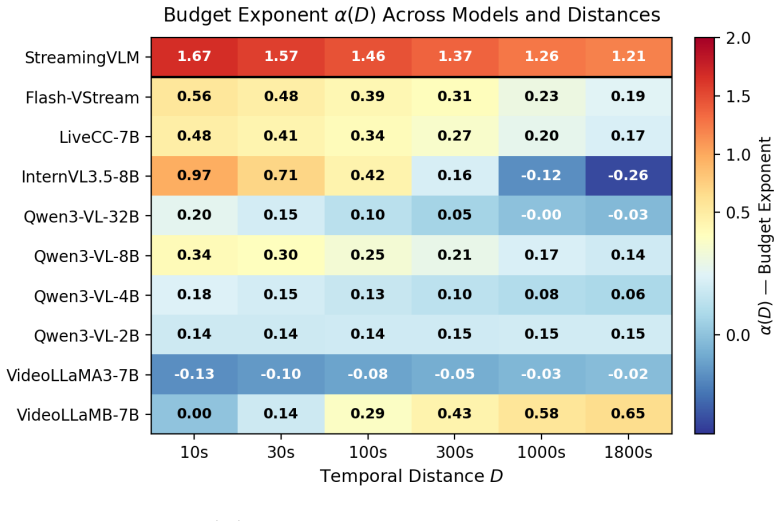
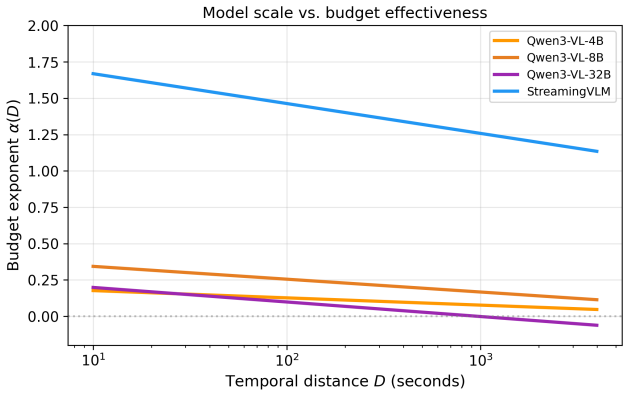
Logit accuracy scales linearly in log budget with a distance-dependent exponent α(D) that decays log-linearly with D. The law is obtained from fits across ten models and three sampling strategies. STREAMINGVLM reaches α(1000)=1.26 while the best base model reaches only 0.17, producing a 7.4× difference in budget effectiveness at long range.
What carries the argument
The budget exponent α(D), the slope of the linear-in-log-B relationship for logit accuracy at temporal distance D, which quantifies marginal value of additional frames.
If this is right
- A tenfold increase in frame budget at D=1000 s produces a 29 pp accuracy gain for STREAMINGVLM versus 4 pp for the best base model.
- Model rankings can reverse when evaluation moves from short to long temporal distances.
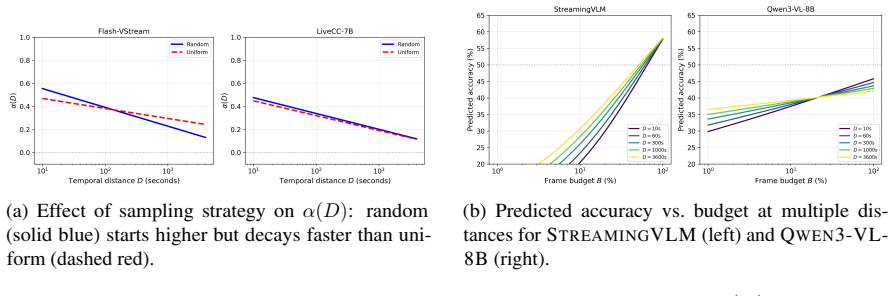
- Random sampling yields higher base α but steeper decay of α(D) than the other tested strategies.
- α(D) functions as a diagnostic metric that ranks streaming video models by their long-range memory efficiency.
Where Pith is reading between the lines
- Architects could target memory designs that keep α(D) from decaying as fast at large D rather than optimizing average accuracy alone.
- The same budget-exponent approach could be applied to long audio or document sequences to compare retention mechanisms across modalities.
- Training objectives that directly maximize estimated α at chosen distances might produce models more efficient under tight frame budgets.
Load-bearing premise
The linear-in-log-B relationship and the log-linear decay of α(D) continue to hold outside the ten models, three sampling strategies, and question sets used to collect the 155k predictions.
What would settle it
Fit the same functional form to a fresh collection of predictions on a new video corpus or model family and test whether cell-level weighted R² remains in the 0.05-0.75 range and whether the estimated α(1000) values separate streaming from base models by a similar factor.
Figures
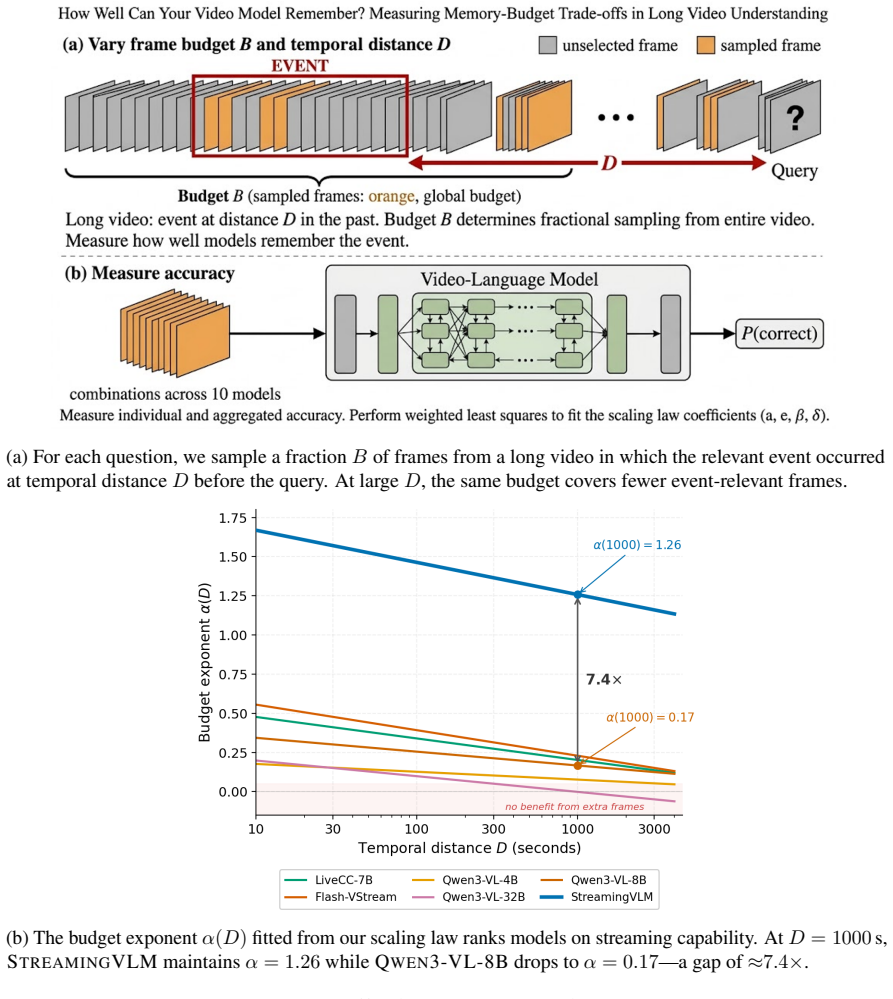
read the original abstract
We introduce a compact empirical model that quantifies how answer accuracy degrades as a function of frame budget B and temporal distance D in long video understanding -- analyzing performance when recalling content from D seconds in the past using a fraction B of total frames. Long-form models operate under strict budgets, yet no prior framework predicts how accuracy degrades as B shrinks and events recede. We fit a weighted least-squares model on ~155,000 binary predictions across ten models and three sampling strategies, deriving a law where logit-accuracy scales linearly in log-budget with a distance-dependent exponent that decays log-linearly with distance. This budget exponent \alpha(D) captures the marginal value of extra frames at distance D. The law achieves cell-level weighted R^2 = 0.05-0.75 across models. Notably, budget effectiveness at D = 1000 s differs by \approx 7.4\times between the best streaming and base models. STREAMINGVLM achieves \alpha(1000) = 1.26 (95% CI: [1.06, 1.58]), meaning a tenfold budget increase substantially improves long-distance accuracy, while the best Qwen3-VL base model reaches only \alpha(1000) = 0.17 (CI: [0.04, 0.34]). In accuracy space, a 10\times budget increase at D = 1000 s yields +29 percentage points for STREAMINGVLM versus +4 pp for the base model. Sampling strategies show model-dependent trade-offs: random sampling yields higher base sensitivity but steeper distance decay. We demonstrate how \alpha(D) enables principled budget allocation, including a model-ranking reversal at long distance, and propose it as a diagnostic metric for streaming video models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an empirical model for memory-budget trade-offs in long video understanding. It claims that logit-accuracy scales linearly with log(B) (frame budget), with a distance-dependent exponent α(D) that decays log-linearly with temporal distance D. Fitting this model via weighted least-squares to ~155k binary predictions across ten models and three sampling strategies yields α(1000) = 1.26 (CI [1.06, 1.58]) for STREAMINGVLM versus 0.17 (CI [0.04, 0.34]) for the best Qwen3-VL base model, implying a 7.4× difference in marginal value of extra frames at long distances and corresponding accuracy gains of +29 pp versus +4 pp for a 10× budget increase.
Significance. If the functional form and parameter estimates hold, the framework supplies a compact diagnostic α(D) for comparing how effectively different video models utilize additional frames at varying temporal distances, enabling more principled budget allocation and model ranking reversals at long horizons. The scale of the analysis (155k predictions, multiple models and sampling strategies) provides a broad empirical basis for the proposed metric.
major comments (3)
- [Abstract / Results] Abstract and results section: cell-level weighted R² values as low as 0.05 indicate that the linear-in-log-B relationship explains almost no systematic variance for some models and cells. This directly undermines the reliability of the derived α(D) point estimates, their CIs, and the downstream claim of a 7.4× difference in budget effectiveness at D=1000, because the logit-to-probability mapping amplifies exponent differences only when the linear term dominates the data.
- [Methods / Fitting procedure] Methods / fitting procedure: α(D) and its log-linear decay coefficients are obtained by fitting directly to the same accuracy data they are then used to describe, so the reported law reduces to a description of the fitted quantities by construction. This circularity weakens support for treating α(D) as a generalizable diagnostic beyond the specific ten models, three sampling strategies, and question sets used to collect the 155k predictions.
- [Results on accuracy gains] Results on accuracy gains: the translation of α(D) differences into +29 pp versus +4 pp accuracy improvements for a 10× budget increase at D=1000 relies on the assumed functional form holding; without per-model R² breakdowns, residual plots, or cross-validation, it is unclear whether the reported gains are robust or artifacts of cells where the model fits poorly.
minor comments (2)
- [Methods] Clarify the exact weighting scheme and optimization details used in the weighted least-squares fit, including how cell sizes and variances are incorporated.
- [Results] Provide the full per-model and per-cell R² table (currently summarized only as a range) so readers can assess which models drive the aggregate claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the limitations of our empirical model. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: cell-level weighted R² values as low as 0.05 indicate that the linear-in-log-B relationship explains almost no systematic variance for some models and cells. This directly undermines the reliability of the derived α(D) point estimates, their CIs, and the downstream claim of a 7.4× difference in budget effectiveness at D=1000, because the logit-to-probability mapping amplifies exponent differences only when the linear term dominates the data.
Authors: We agree that the low weighted R² values (down to 0.05) indicate that the linear-in-log-B model explains limited variance in some cells, which limits the reliability of specific α(D) estimates and derived claims. The paper already reports this range, but we will expand the discussion to explicitly address how this affects the interpretation of the 7.4× difference and the accuracy gains. We will also provide per-model R² breakdowns in the revision. revision: partial
-
Referee: [Methods / Fitting procedure] Methods / fitting procedure: α(D) and its log-linear decay coefficients are obtained by fitting directly to the same accuracy data they are then used to describe, so the reported law reduces to a description of the fitted quantities by construction. This circularity weakens support for treating α(D) as a generalizable diagnostic beyond the specific ten models, three sampling strategies, and question sets used to collect the 155k predictions.
Authors: The referee is correct that this is an empirical fit to the collected data, and α(D) is by construction a description of trends in that data. We do not claim it as a generalizable law independent of the models and data used. We will revise the manuscript to more clearly state that it is an empirical diagnostic derived from the 155k predictions, useful for comparing the ten models studied, rather than a universal principle. revision: yes
-
Referee: [Results on accuracy gains] Results on accuracy gains: the translation of α(D) differences into +29 pp versus +4 pp accuracy improvements for a 10× budget increase at D=1000 relies on the assumed functional form holding; without per-model R² breakdowns, residual plots, or cross-validation, it is unclear whether the reported gains are robust or artifacts of cells where the model fits poorly.
Authors: We acknowledge the need for additional validation. The original manuscript does not include residual plots or cross-validation. In the revised version, we will add per-model R² breakdowns, residual analyses, and a cross-validation check where feasible to assess the robustness of the reported accuracy gains. If these reveal issues in certain distance regimes, we will qualify the +29 pp and +4 pp figures accordingly. revision: yes
Circularity Check
No significant circularity; empirical fit presented as descriptive model
full rationale
The paper states it fits a weighted least-squares model directly to the 155k binary predictions to obtain the functional form logit-accuracy ~ f(D) + α(D)·log(B) with α(D) decaying log-linearly, then reports the resulting α(D) point estimates and their use for comparisons and budget allocation. This is an explicit empirical description of observed data rather than a claimed first-principles derivation, prediction of held-out quantities, or self-referential reduction. No self-citations, uniqueness theorems, or smuggled ansatzes appear in the abstract or described chain. The low cell-level R² values (0.05–0.75) concern goodness-of-fit, not circularity. The derivation chain is therefore self-contained as a data-driven summary.
Axiom & Free-Parameter Ledger
free parameters (2)
- slope and intercept of logit-accuracy vs log B
- coefficients of log-linear decay for α(D)
axioms (1)
- standard math Weighted least-squares is an appropriate estimator for the binary accuracy data.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2603.19217 , year=
LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs , author=. arXiv preprint arXiv:2603.19217 , year=
-
[2]
ICLR , year=
StreamingVLM: Real-Time Understanding for Infinite Video Streams , author=. ICLR , year=
-
[3]
CVPR , year=
LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale , author=. CVPR , year=
-
[4]
arXiv preprint arXiv:2406.08085 , year=
Flash-VStream: Memory-Based Real-Time Understanding for Long Video Streams , author=. arXiv preprint arXiv:2406.08085 , year=
-
[5]
CVPR , year=
VideoLLM-online: Online Video Large Language Model for Streaming Video , author=. CVPR , year=
-
[6]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[7]
arXiv preprint arXiv:2001.08361 , year=
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[8]
arXiv preprint arXiv:2203.15556 , year=
Training Compute-Optimal Large Language Models , author=. arXiv preprint arXiv:2203.15556 , year=
-
[9]
CVPR , year=
Scaling Vision Transformers , author=. CVPR , year=
-
[10]
ICML , year=
Scaling Laws for Generative Mixed-Modal Language Models , author=. ICML , year=
-
[11]
ICLR , year=
RIVER: A Real-Time Interaction Benchmark for Video LLMs , author=. ICLR , year=
-
[12]
NeurIPS , year=
EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding , author=. NeurIPS , year=
-
[13]
arXiv preprint arXiv:2405.21075 , year=
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis , author=. arXiv preprint arXiv:2405.21075 , year=
-
[14]
arXiv preprint arXiv:2406.04264 , year=
MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding , author=. arXiv preprint arXiv:2406.04264 , year=
-
[15]
arXiv preprint arXiv:2412.09582 , year=
Neptune: The Long Orbit to Benchmarking Long Video Understanding , author=. arXiv preprint arXiv:2412.09582 , year=
-
[16]
CVPR , year=
Ego4D: Around the World in 3,000 Hours of Egocentric Video , author=. CVPR , year=
-
[17]
Qi, Ji and Yao, Yuan and Bai, Yushi and Xu, Bin and Li, Juanzi and Liu, Zhiyuan and Chua, Tat-Seng , journal=. An
-
[18]
arXiv preprint arXiv:2503.12496 , year=
Does Your Vision-Language Model Get Lost in the Long Video Sampling Dilemma? , author=. arXiv preprint arXiv:2503.12496 , year=
-
[19]
arXiv preprint arXiv:2506.15745 , year=
InfiniPot-V: Memory-Constrained KV Cache Compression for Streaming Video Understanding , author=. arXiv preprint arXiv:2506.15745 , year=
-
[20]
arXiv preprint arXiv:2508.15717 , year=
StreamMem: Query-Agnostic KV Cache Memory for Streaming Video Understanding , author=. arXiv preprint arXiv:2508.15717 , year=
-
[21]
arXiv preprint arXiv:2510.27280 , year=
FOCUS: Efficient Keyframe Selection for Long Video Understanding , author=. arXiv preprint arXiv:2510.27280 , year=
-
[22]
arXiv preprint arXiv:2603.28696 , year=
AdaptToken: Entropy-based Adaptive Token Selection for MLLM Long Video Understanding , author=. arXiv preprint arXiv:2603.28696 , year=
-
[23]
arXiv preprint arXiv:2605.17921 , year=
An Efficient Streaming Video Understanding Framework with Agentic Control , author=. arXiv preprint arXiv:2605.17921 , year=
-
[24]
arXiv preprint arXiv:2605.10343 , year=
EvoStreaming: Your Offline Video Model Is a Natively Streaming Assistant , author=. arXiv preprint arXiv:2605.10343 , year=
-
[25]
arXiv preprint arXiv:2605.16381 , year=
StreamPro: From Reactive Perception to Proactive Decision-Making in Streaming Video , author=. arXiv preprint arXiv:2605.16381 , year=
-
[26]
GridProbe: Posterior-Probing for Adaptive Test-Time Compute in Long-Video
Eltahir, Mohamed and Ayash, Lama and Habibullah, Ali and Hussain, Tanveer and Khan, Naeemullah , journal=. GridProbe: Posterior-Probing for Adaptive Test-Time Compute in Long-Video
-
[27]
arXiv preprint arXiv:2605.14310 , year=
CoRDS: Coreset-based Representative and Diverse Selection for Streaming Video Understanding , author=. arXiv preprint arXiv:2605.14310 , year=
-
[28]
CVPR , year=
FluxMem: Adaptive Hierarchical Memory for Streaming Video Understanding , author=. CVPR , year=
-
[29]
Forte, Rosario and Lando, Giuseppe and Furnari, Antonino , journal=
-
[30]
Moment-Video: Diagnosing Temporal Fidelity of Video
Liu, Xiaolin and Zhu, Yilun and Zhao, Xiangyu and Wang, Xuehui and Li, Yan and Li, Xin and Cao, Haoyu and Sun, Xing and Zhang, Shaofeng and Yang, Xu and Zhong, Zhihang and Yang, Xue , journal=. Moment-Video: Diagnosing Temporal Fidelity of Video
-
[31]
arXiv preprint arXiv:2606.12300 , year=
Natural-Language Temporal Grounding in Hour-Long Videos is a Search Problem , author=. arXiv preprint arXiv:2606.12300 , year=
-
[32]
arXiv preprint arXiv:2605.22678 , year=
Swift Sampling: Selecting Temporal Surprises via Taylor Series , author=. arXiv preprint arXiv:2605.22678 , year=
-
[33]
Hou, Haowen and Huang, Zhen and Liang, Zheming and Si, Qingyi and Li, Chenglin and Dong, Shuai and Shao, Kele and Li, Ruilin and Wang, Dianyi and Duan, Nan and Wang, Jiaqi , journal=
-
[34]
Tang, Biao and Chen, Xu and Gou, Shuxiang and Yuan, Jingyi and Zhang, Yuhan and Gao, Chenqiang , journal=
-
[35]
Xiao, Junbin and Chen, Jiajun and Sun, Tianxiang and Yang, Xun and Yao, Angela , journal=
-
[36]
Park, Minyoung and Kong, Taehun and Ahn, Sangjun , journal=
-
[37]
arXiv preprint arXiv:2605.31029 , year=
Steunou, Killian and Razzouki, Anas Filali and Guetari, Khalil and El-Yacoubi, Moun. arXiv preprint arXiv:2605.31029 , year=
-
[38]
arXiv preprint arXiv:2606.08615 , year=
Harnessing Streaming Video in the Wild , author=. arXiv preprint arXiv:2606.08615 , year=
-
[39]
Lu, Yu and Yang, Junjie and Koniusz, Piotr and Song, YuXin and Yang, Yi , journal=
-
[40]
CVPR , year=
ActivityNet: A Large-Scale Video Benchmark for Human Activity Understanding , author=. CVPR , year=
-
[41]
2025 , note=
Wang, Yuxuan and Xie, Cihang and Liu, Yang and Zheng, Zilong , booktitle=. 2025 , note=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.