Grading the Grader: Lessons from Evaluating an Agentic Data Analysis System
Pith reviewed 2026-06-25 23:07 UTC · model grok-4.3
The pith
A three-layer grading cascade of regex, LLM lenient grading, and human inspection achieves 100% observed precision and 97% recall when assessing outputs from an agentic data analysis system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
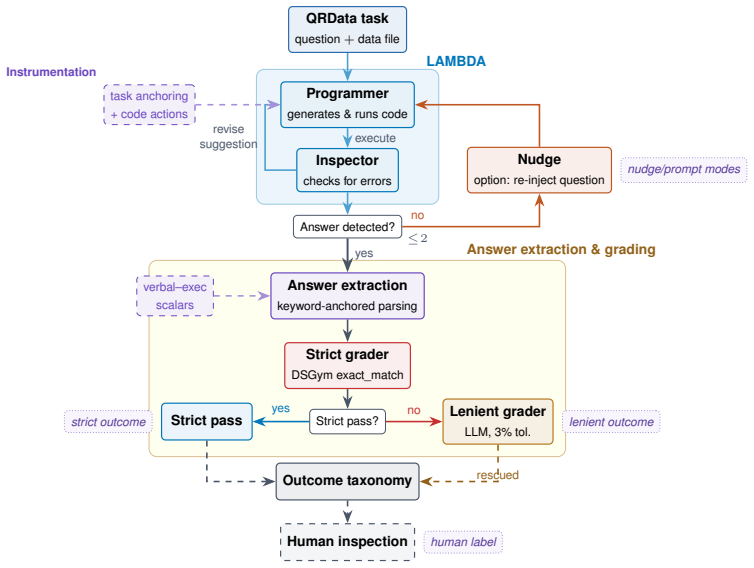
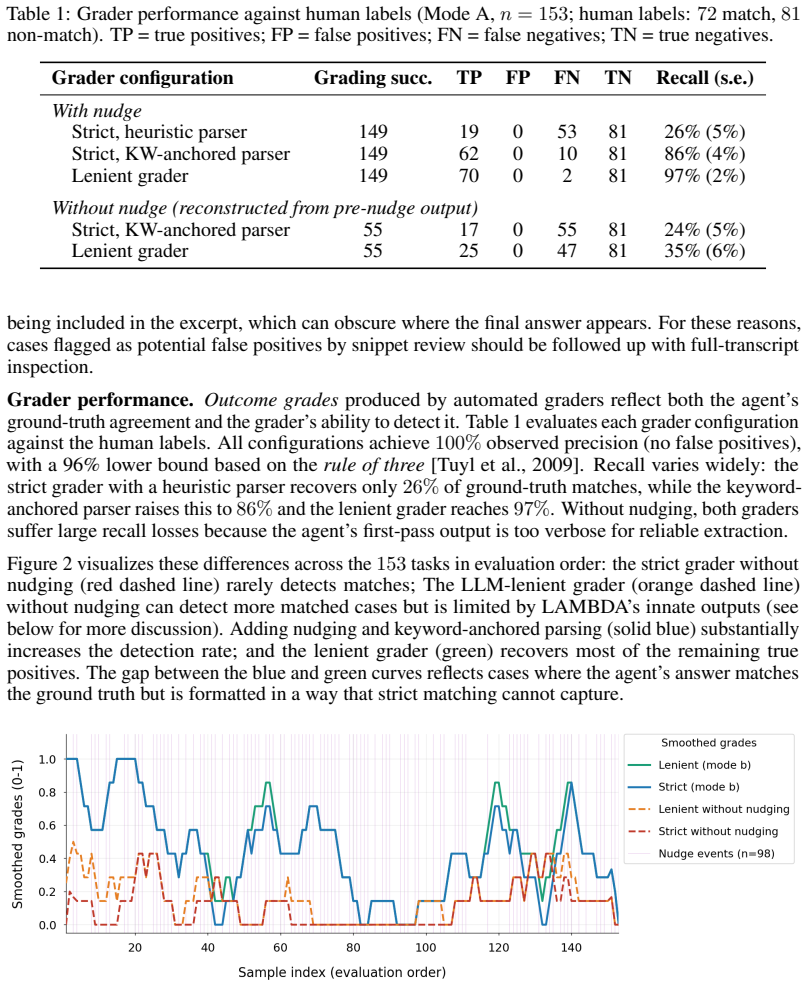
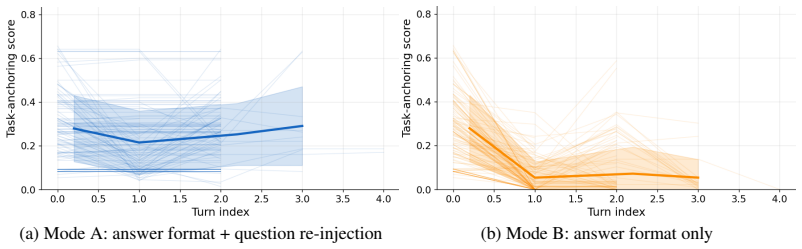
The paper establishes that a three-layer human-AI grading cascade reliably separates genuine answer disagreements from grading artifacts on agentic data analysis outputs, delivering 100% observed precision for both automated layers, 97% recall for the lenient grader, and a jump in grading success from 36% to 97% via iterative nudging that functions as an answer template cue rather than question re-injection.
What carries the argument
The three-layer human-AI grading cascade combining strict regex matching, LLM-based lenient grading, and snippet-based human inspection, each with distinct failure profiles.
If this is right
- Keyword-anchored extraction raises the strict grader recall by 60 percentage points over a last-number heuristic.
- The lenient grader remains independent of the underlying parser.
- Re-injecting the original question during nudging provides no extra benefit over the nudge alone.
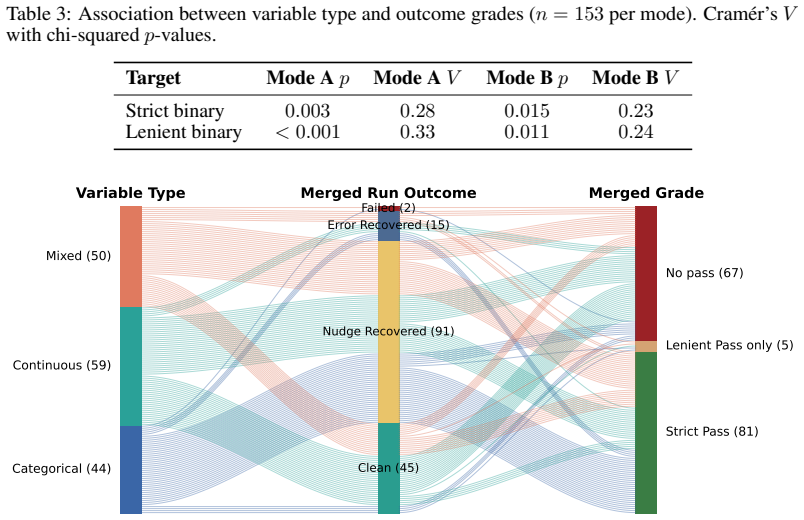
- Variable type is the metadata field most consistently tied to grading pipeline dynamics and observed grades.
Where Pith is reading between the lines
- The cascade approach could be applied to agent outputs on non-numerical tasks to test whether precision holds beyond the current benchmark.
- High observed precision suggests the automated layers could serve as an initial filter before human review in larger evaluations.
- The nudge mechanism might be refined by testing different cue templates to further increase lenient-pass rates.
Load-bearing premise
Human inspection of output snippets supplies reliable ground-truth labels that correctly separate genuine disagreements from grading artifacts.
What would settle it
A single case in which the lenient grader marks an output as correct that human inspection would reject as incorrect.
Figures
read the original abstract
Agentic data analysis systems produce rich outputs, including code, numerical results, and verbal diagnostics. This makes them more challenging to evaluate than single-turn LLM responses. It is therefore necessary to distinguish genuine disagreement between an agent's output and a ground-truth answer from grading artifacts. We investigate how reliably automated graders assess such a system and what strategies improve grading quality by applying LAMBDA, a multi-agent data-analysis system, on 153 numerical QRData tasks from DSGym. We develop and evaluate a three-layer human-AI grading cascade: strict regex matching, LLM-based lenient grading, and snippet-based human inspection, which combines non-GenAI and GenAI strategies with different failure profiles. Both automated graders achieve 100% observed precision (0/70 false positives). The lenient grader's recall is 97% against human labels. A keyword-anchored extraction pipeline raises the strict grader's recall by 60 percentage points over a last-number heuristic; the lenient grader is architecturally parser-independent. An iterative nudge mechanism raises grading run success from 36% to 97% and lenient-pass rates from 16% to 46%; comparing nudging with and without original-question re-injection shows that re-injection offers no benefit, confirming the nudge as an answer template cue. We further observe in this case study that variable type is the task metadata field most consistently associated with grading pipeline dynamics and observed outcome grades.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates automated grading methods for outputs from the LAMBDA agentic data analysis system on 153 numerical QRData tasks from DSGym. It introduces a three-layer human-AI grading cascade (strict regex matching, LLM-based lenient grading, and snippet-based human inspection) and reports that both automated graders achieve 100% observed precision (0/70 false positives), the lenient grader reaches 97% recall against human labels, a keyword-anchored extraction pipeline improves strict-grader recall by 60 points, and an iterative nudge mechanism raises grading-run success from 36% to 97% (with re-injection providing no additional benefit). Variable type is identified as the task metadata most associated with grading outcomes.
Significance. If the human ground-truth labels are reliable, the study supplies concrete, actionable lessons on grading rich multi-component outputs from agentic systems, including the value of combining regex and LLM approaches with different failure modes, the parser-independence of lenient grading, and the effectiveness of nudging as an answer-template cue. The empirical scale (153 tasks) and specific lift numbers (36% to 97% success) make the findings potentially useful for practitioners building evaluation pipelines.
major comments (1)
- [Evaluation / Human Labeling Process] The central precision (100%, 0/70 FPs) and recall (97%) figures for the automated graders are computed against human labels produced by snippet-based inspection. No inter-rater agreement statistic, blinding protocol, or quantitative error analysis on the human labeling step is reported. This is load-bearing for the headline claims, because systematic human bias in distinguishing genuine answer mismatches from grading artifacts would directly invalidate the reported metrics.
minor comments (2)
- [Abstract] The abstract states that 'variable type is the task metadata field most consistently associated with grading pipeline dynamics' but does not describe the statistical test or correlation measure used to establish this association.
- [Nudging Experiments] Provide more detail on the exact implementation of the 'iterative nudge mechanism,' including the prompt templates and stopping criteria, so that the 36% to 97% success lift can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for emphasizing the foundational role of the human labels. We address the single major comment below.
read point-by-point responses
-
Referee: [Evaluation / Human Labeling Process] The central precision (100%, 0/70 FPs) and recall (97%) figures for the automated graders are computed against human labels produced by snippet-based inspection. No inter-rater agreement statistic, blinding protocol, or quantitative error analysis on the human labeling step is reported. This is load-bearing for the headline claims, because systematic human bias in distinguishing genuine answer mismatches from grading artifacts would directly invalidate the reported metrics.
Authors: We agree that the lack of reported inter-rater agreement, blinding, or quantitative error analysis on the human labels is a limitation that affects the strength of the headline metrics. The snippet-based inspection was performed by a single author using an explicit, conservative protocol whose goal was to flag only clear cases where an automated pass was unjustified. Because only one rater was involved, inter-rater statistics cannot be computed. We will revise the manuscript to (1) expand the Methods section with the precise inspection criteria and decision rules used, (2) state explicitly that labeling was single-rater, and (3) discuss the implications for potential bias. These additions will allow readers to evaluate the 100 % observed precision and 97 % recall figures with appropriate context. We do not claim the revision will fully eliminate the concern, only that it will make the limitation transparent. revision: partial
Circularity Check
No circularity: purely empirical evaluation study
full rationale
The paper is an empirical evaluation of grading pipelines on 153 tasks, reporting observed precision, recall, and success rates computed directly against human snippet labels. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All headline metrics are external comparisons to human annotations rather than reductions to the paper's own inputs by construction. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.16344 , year=
DSGym: A Holistic Framework for Evaluating and Training Data Science Agents , author=. arXiv preprint arXiv:2601.16344 , year=
-
[2]
Journal of the American Statistical Association , volume=
Lambda: A large model based data agent , author=. Journal of the American Statistical Association , volume=. 2026 , publisher=
2026
-
[3]
LAMBDA: A Large Model Based Data Agent
Discussion of “LAMBDA: A Large Model Based Data Agent” , author=. Journal of the American Statistical Association , volume=. 2026 , publisher=
2026
-
[4]
Towards a Science of
Rabanser, Stephan and Kapoor, Sayash and Kirgis, Peter and Liu, Kangheng and Utpala, Saiteja and Narayanan, Arvind , journal=. Towards a Science of. 2026 , note=
2026
-
[5]
The American Statistician , number=
An overview of large language models for statisticians , author=. The American Statistician , number=. 2026 , publisher=
2026
-
[6]
, editor =
Yu, Bin and Barter, Rebecca L. , editor =. Veridical
-
[7]
arXiv preprint arXiv:2508.00835 , year=
PCS Workflow for Veridical Data Science in the Age of AI , author=. arXiv preprint arXiv:2508.00835 , year=
-
[8]
Proceedings of the National Academy of Sciences , volume =
Bin Yu and Karl Kumbier , title =. Proceedings of the National Academy of Sciences , volume =. 2020 , doi =
2020
-
[9]
International Conference on Learning Representations , volume=
When attention sink emerges in language models: An empirical view , author=. International Conference on Learning Representations , volume=
-
[10]
International statistical review , volume=
The rule of three, its variants and extensions , author=. International statistical review , volume=. 2009 , publisher=
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.