Iterating Toward Better Search: A Two-Agent Simulation Framework for Evaluating Agentic Search Architectures in E-Commerce
Pith reviewed 2026-06-27 07:03 UTC · model grok-4.3
The pith
A fixed buyer agent in a two-agent simulation enables controlled comparison of e-commerce responder designs, showing rolling-window memory superior and failure analysis cutting errors by 62%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the modular two-agent framework, by holding the buyer agent constant across experiments, supports rigorous, apples-to-apples evaluation of conversational shopping responder architectures, as shown by the superiority of rolling-window memory, the 62 percent reduction from systematic fixes, the limited cost of model swaps, and the documented disagreements among LLM judges.
What carries the argument
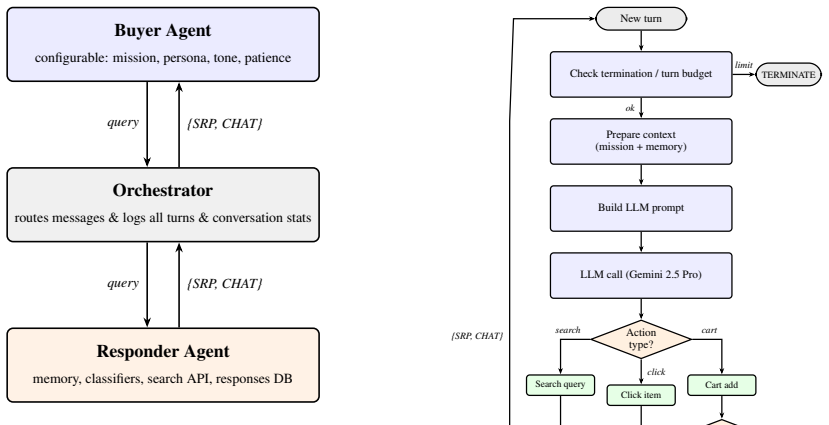
The two-agent simulation framework that pairs a configurable buyer agent with an interchangeable responder integrated to a real e-commerce search API, allowing the buyer to remain fixed while responder designs vary.
If this is right
- Rolling-window memory outperforms intent-extraction memory on all quality metrics and reduces per-query time by 35 percent.
- Systematic failure analysis followed by targeted fixes lowers failure and near-failure rates by 62 percent across the dataset.
- Swapping the responder LLM backbone from Gemini 2.5 to Llama 3.3 70B produces only a 0.16-0.45 point quality drop under identical architecture.
- Frontier LLM judges exhibit systematic philosophical disagreement, with Gemini favoring process correctness and Claude favoring concrete outcomes on the same prompts.
Where Pith is reading between the lines
- The framework could be adapted to test search architectures in domains other than e-commerce by reconfiguring the buyer agent.
- The memory-type results suggest that retaining recent conversation context may be more effective than explicit intent extraction for maintaining shopping coherence.
- Disagreements among LLM judges indicate that evaluation standards for conversational search may need human calibration or multi-judge ensembles to stabilize rankings.
- If the simulated buyer patterns do not generalize, the observed performance gaps might shrink or reverse when the same responders are deployed with live users.
Load-bearing premise
The buyer agent's personas, missions, and patience levels generate interaction patterns that match those of real human shoppers.
What would settle it
Re-running the full set of responder comparisons with actual human buyers in place of the simulated buyer agent and checking whether the same designs still rank highest on the quality metrics.
Figures
read the original abstract
We present a modular two-agent simulation framework for evaluating conversational shopping assistant architectures. An independent buyer agent, configured with personas, missions, and patience levels, is paired with an interchangeable responder that integrates with a real e-commerce search API. Holding the buyer constant across experiments enables controlled comparison of responder designs on identical scenarios. Using 2011 conversations across 14 persona buckets, we establish four empirical findings. First, rolling-window memory outperforms intent-extraction memory on all quality metrics while being 35% faster per query. Second, illustrating rapid evidence-driven iteration, a systematic failure analysis of a responder version enables targeted fixes that reduce failure and near-failure rates by 62% across the full dataset. Third, swapping the responder LLM backbone from Gemini~2.5 to Llama~3.3~70B costs 0.16--0.45 points despite identical architecture. Finally, we document systematic philosophical disagreement between frontier LLM judges: Gemini rewards process correctness while Claude demands concrete outcomes, despite using the same evaluation prompt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a modular two-agent simulation framework for evaluating conversational shopping assistant architectures in e-commerce. A fixed buyer agent (configured via 14 persona buckets, missions, and patience levels) is paired with interchangeable responders that integrate with a real search API; holding the buyer constant enables controlled comparisons. On 2011 conversations, the authors report that rolling-window memory outperforms intent-extraction memory on all quality metrics while being 35% faster, that systematic failure analysis permits targeted fixes reducing failure/near-failure rates by 62%, that swapping the responder LLM backbone (Gemini 2.5 to Llama 3.3 70B) incurs only 0.16–0.45 point costs, and that frontier LLM judges exhibit systematic philosophical disagreements despite identical prompts.
Significance. If the buyer simulation is representative, the framework supplies a practical, controlled method for rapid evidence-driven iteration on agentic search designs without live-user experiments. The work demonstrates concrete strengths in reproducible empirical comparisons, integration with a production search API, and explicit documentation of LLM-judge divergence. These elements support its utility for architecture evaluation provided the simulation's interaction patterns align with real shopper behavior.
major comments (2)
- [Abstract] Abstract: the four empirical findings (rolling-window superiority, 35% speed gain, 62% failure reduction, backbone swap costs) rest on the unvalidated assumption that the buyer agent's 14 persona buckets, missions, and patience levels generate query sequences and tolerance thresholds representative of actual users. No calibration to real interaction logs, A/B data, or human studies is described; this is load-bearing for any claim that the framework supports evaluation of architectures for e-commerce deployment.
- [Abstract] Abstract: it is unclear whether the quality metrics used to declare rolling-window superiority and the 62% failure reduction were validated against human judgments or whether the failure analysis was pre-registered versus post-hoc. Either gap directly affects the reliability of the reported performance deltas.
minor comments (1)
- [Abstract] Abstract: model names appear as 'Gemini~2.5' and 'Llama~3.3~70B'; confirm exact versions and citation details for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation and metric reliability. We address each major point below, clarifying the framework's intended scope as a controlled comparison tool rather than a fully validated proxy for real users, and propose revisions to improve transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: the four empirical findings (rolling-window superiority, 35% speed gain, 62% failure reduction, backbone swap costs) rest on the unvalidated assumption that the buyer agent's 14 persona buckets, missions, and patience levels generate query sequences and tolerance thresholds representative of actual users. No calibration to real interaction logs, A/B data, or human studies is described; this is load-bearing for any claim that the framework supports evaluation of architectures for e-commerce deployment.
Authors: We agree that the buyer agent configuration has not been calibrated to real interaction logs, A/B tests, or human studies, and that this constrains any direct claims about representativeness for live deployment. The manuscript positions the framework as enabling controlled, reproducible comparisons by holding the buyer fixed across responder variants; the reported deltas are therefore relative performance differences within the simulated environment. We will revise the abstract and introduction to explicitly qualify the scope (e.g., “within this controlled simulation”) and add a limitations paragraph stating that external validation against real user data is required before deployment inferences. This revision does not alter the empirical results but addresses the load-bearing concern. revision: partial
-
Referee: [Abstract] Abstract: it is unclear whether the quality metrics used to declare rolling-window superiority and the 62% failure reduction were validated against human judgments or whether the failure analysis was pre-registered versus post-hoc. Either gap directly affects the reliability of the reported performance deltas.
Authors: The quality metrics are produced by frontier LLM judges using fixed prompts (detailed in the appendix), and the failure analysis was performed systematically by enumerating error categories across the full set of 2011 conversations after initial runs. Neither human validation of the LLM metrics nor pre-registration of the analysis was conducted. We will revise the methods and results sections to state these facts explicitly, note the documented philosophical disagreements between judges, and describe the failure analysis as post-hoc but exhaustive. The 62% reduction figure will be presented with the clarification that patterns were first observed on a development subset and then measured on the held-out full dataset. These changes improve transparency without changing the numbers. revision: partial
Circularity Check
Empirical simulation study with no circular derivations
full rationale
The paper describes a modular two-agent simulation framework and reports four empirical findings from 2011 controlled conversations. All central claims (rolling-window memory outperforming intent-extraction on quality metrics and speed, 62% failure reduction after targeted fixes, LLM backbone swap effects, and judge disagreement) are direct measurements of observed differences under fixed buyer-agent conditions. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the reported results. The work is self-contained as an empirical comparison tool; external validity concerns (e.g., persona realism) are separate from circularity.
Axiom & Free-Parameter Ledger
free parameters (2)
- 14 persona buckets
- patience levels
axioms (1)
- domain assumption Buyer agent with fixed personas and missions produces repeatable interaction traces suitable for comparing responders.
Reference graph
Works this paper leans on
-
[3]
arXiv preprint arXiv:2507.17842 , year =
Yimeng Zhang and Tian Wang and Jiri Gesi and Ziyi Wang and Yuxuan Lu and Jiacheng Lin and Sinong Zhan and Vianne Gao and Ruochen Jiao and Junze Liu and Kun Qian and Yuxin Tang and Ran Xue and Houyu Zhang and Qingjun Cui and Yufan Guo and Dakuo Wang , title =. arXiv preprint arXiv:2507.17842 , year =
-
[7]
2026 , month = jan, url =
Lewis Warne and Chenran Gong and Aditi Bamba and Matt Gode , title =. 2026 , month = jan, url =
2026
-
[8]
and Radcliffe, Evan and Rajagopal, Guru Rajan and Sloan, Adam and Tudrej, Tomasz and Ture, Ferhan and Wu, Zhe and Xu, Lixinyu and Baldwin, Breck , journal=
Atil, Berk and Aykent, Sarp and Chittams, Alexa and Fu, Lisheng and Passonneau, Rebecca J. and Radcliffe, Evan and Rajagopal, Guru Rajan and Sloan, Adam and Tudrej, Tomasz and Ture, Ferhan and Wu, Zhe and Xu, Lixinyu and Baldwin, Breck , journal=. Non-Determinism of. 2025 , url=
2025
-
[9]
Xing and Hao Zhang and Joseph E
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric P. Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , title =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[10]
arXiv preprint arXiv:2304.03442 , year=
Generative agents: Interactive simulacra of human behavior , author=. arXiv preprint arXiv:2304.03442 , year=
-
[11]
arXiv preprint arXiv:2307.07924 , year=
Communicative agents for software development , author=. arXiv preprint arXiv:2307.07924 , year=
-
[12]
ACM Computing Surveys , volume=
Conversational recommendation systems: A survey , author=. ACM Computing Surveys , volume=. 2024 , publisher=
2024
-
[13]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Conversational search agents: Opportunities and challenges , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[14]
arXiv preprint arXiv:2303.11366 , year=
Reflexion: Language agents with verbal reinforcement learning , author=. arXiv preprint arXiv:2303.11366 , year=
-
[15]
arXiv preprint arXiv:2310.08560 , year=
MemGPT: Towards LLMs as operating systems , author=. arXiv preprint arXiv:2310.08560 , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
AlpacaFarm: A simulation framework for methods that learn from human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2305.01937 , year=
Can large language models be an alternative to human evaluations? , author=. arXiv preprint arXiv:2305.01937 , year=
-
[18]
ACM Transactions on Information Systems , volume=
Large language models for product search and recommendation , author=. ACM Transactions on Information Systems , volume=
-
[19]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Multi-turn conversational product search , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[20]
arXiv preprint arXiv:2302.04761 , year=
Toolformer: Language models can teach themselves to use tools , author=. arXiv preprint arXiv:2302.04761 , year=
-
[21]
arXiv preprint arXiv:2210.03629 , year=
ReAct: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[22]
arXiv preprint arXiv:2005.04118 , year=
Beyond accuracy: Behavioral testing of NLP models with CheckList , author=. arXiv preprint arXiv:2005.04118 , year=
arXiv 2005
-
[23]
arXiv preprint arXiv:2402.01827 , year=
A systematic study of model choice in retrieval-augmented generation , author=. arXiv preprint arXiv:2402.01827 , year=
-
[24]
arXiv preprint arXiv:2503.20749 , year=
Can LLM agents simulate multi-turn human behavior? Evidence from real online customer behavior data , author=. arXiv preprint arXiv:2503.20749 , year=
-
[25]
arXiv preprint arXiv:2509.21501 , year=
LLM agent meets agentic AI: Can LLM agents simulate customers to evaluate agentic-AI-based shopping assistants? , author=. arXiv preprint arXiv:2509.21501 , year=
-
[26]
arXiv preprint arXiv:2506.05606 , year=
OPeRA: A dataset of observation, persona, rationale, and action for evaluating LLMs on human online shopping behavior simulation , author=. arXiv preprint arXiv:2506.05606 , year=
-
[27]
A simulation and evaluation flywheel to develop LLM chatbots at scale , author=
-
[28]
arXiv preprint arXiv:2510.06674 , year=
Agent-in-the-loop: A data flywheel for continuous improvement in LLM-based customer support , author=. arXiv preprint arXiv:2510.06674 , year=
-
[29]
arXiv preprint arXiv:2506.09902 , year=
PersonaLens: A benchmark for personalization evaluation in conversational AI assistants , author=. arXiv preprint arXiv:2506.09902 , year=
-
[30]
IEEE 40th International Conference on Data Engineering (ICDE) , year=
Multifaceted Reformulations for Null & Low queries and its parallelism with Counterfactuals , author=. IEEE 40th International Conference on Data Engineering (ICDE) , year=
-
[31]
ACM SIGIR Workshop on eCommerce (SIGIR eCom'25) , year=
Intent-Aware Neural Query Reformulation for Behavior-Aligned Product Search , author=. ACM SIGIR Workshop on eCommerce (SIGIR eCom'25) , year=
-
[32]
2025 , note=
Enhancing Related Searches Recommendation system by leveraging LLM Approaches , author=. 2025 , note=
2025
-
[33]
2026 , month=
Gemini 3.1 Pro: Model Card , author=. 2026 , month=
2026
-
[34]
2026 , month=
Claude Opus 4.6 System Card , author=. 2026 , month=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.