RobuQ: Pushing DiTs to W1.58A2 via Robust Activation Quantization
Pith reviewed 2026-05-22 13:08 UTC · model grok-4.3
The pith
A new training framework lets Diffusion Transformers generate competitive images on ImageNet using ternary weights and average 2-bit activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Hadamard transform converts unknown per-token activation distributions into per-token normal distributions, which in turn supports reliable quantization to an average of 2 bits. When this is paired with an activation-only mixed-precision network that keeps ternary weights everywhere while varying activation precision layer by layer, the resulting model produces stable and competitive unconditional and conditional images on ImageNet-1K, establishing the first such result at this bit width.
What carries the argument
RobustQuantizer, which uses the Hadamard transform to normalize per-token activations before quantization, together with the AMPN pipeline that allocates different activation precisions per layer while holding all weights at ternary precision.
Load-bearing premise
The Hadamard transform can reliably turn arbitrary per-token activation distributions into normal distributions that quantize accurately at low bit widths.
What would settle it
A sharp rise in FID score or visible degradation in generated ImageNet images when the Hadamard transform is removed from the activation quantization path.
Figures





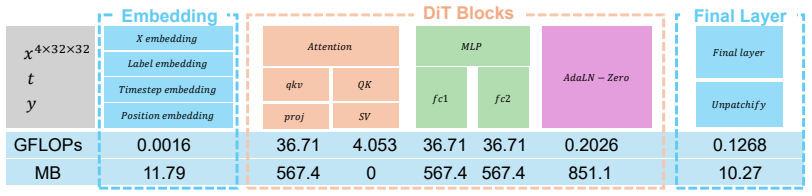


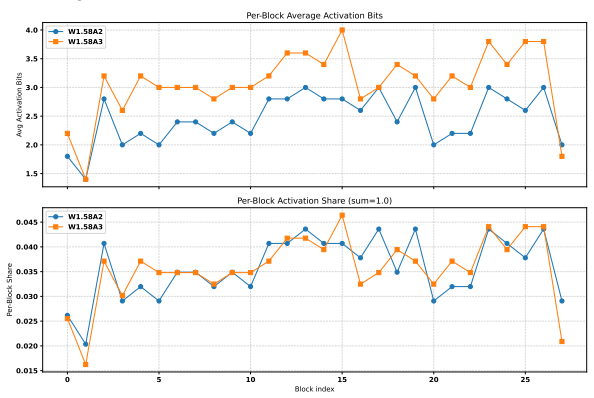

read the original abstract
Diffusion Transformers (DiTs) have recently emerged as a powerful backbone for image generation, demonstrating superior scalability and performance over U-Net architectures. However, their practical deployment is hindered by substantial computational and memory costs. While Quantization-Aware Training (QAT) has shown promise for U-Nets, its application to DiTs faces unique challenges, primarily due to the sensitivity and distributional complexity of activations. In this work, we identify activation quantization as the primary bottleneck for pushing DiTs to extremely low-bit settings. To address this, we propose a systematic QAT framework for DiTs, named RobuQ. We start by establishing a strong ternary weight (W1.58A4) DiT baseline. Building upon this, we propose RobustQuantizer to achieve robust activation quantization. Our theoretical analyses show that the Hadamard transform can convert unknown per-token distributions into per-token normal distributions, providing a strong foundation for this method. Furthermore, we propose AMPN, the first Activation-only Mixed-Precision Network pipeline for DiTs. This method applies ternary weights across the entire network while allocating different activation precisions to each layer to eliminate information bottlenecks. Through extensive experiments on unconditional and conditional image generation, our RobuQ framework achieves state-of-the-art performance for DiT quantization in sub-4-bit quantization configuration. To the best of our knowledge, RobuQ is the first achieving stable and competitive image generation on large datasets like ImageNet-1K with activations quantized to average 2 bits. The code and models will be available at https://github.com/racoonykc/RobuQ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce RobuQ, a systematic QAT framework for DiTs that achieves W1.58A2 quantization. It starts with a strong ternary weight W1.58A4 baseline, proposes RobustQuantizer based on theoretical analysis that the Hadamard transform converts per-token distributions to normal distributions for robust activation quantization, and introduces AMPN for activation-only mixed-precision to allocate different precisions per layer. Through experiments on unconditional and conditional image generation on ImageNet-1K, it achieves SOTA for sub-4-bit DiT quantization and is the first to achieve stable competitive performance with average 2-bit activations.
Significance. If the results and theoretical justification hold, this is a significant advance in quantizing large generative models. Pushing DiTs to extremely low-bit settings with competitive performance on large datasets like ImageNet-1K could enable more efficient deployment of diffusion models. The use of Hadamard transform for activation normalization and the AMPN pipeline are potentially impactful contributions to the field of model quantization for vision transformers.
major comments (1)
- [Theoretical Analysis] Theoretical analysis section: The justification for RobustQuantizer rests on the Hadamard transform converting arbitrary per-token activation distributions into per-token normal distributions that are easy to quantize at 2 bits. This distributional property is invoked to argue that activation quantization is no longer the primary bottleneck, but the manuscript provides no direct empirical verification (e.g., histograms, QQ plots, or statistical tests) on activation statistics from actual DiT attention and MLP blocks. Without this, the quantization error bounds and the central W1.58A2 claim on ImageNet-1K rest on an unconfirmed assumption.
minor comments (2)
- The abstract states that code and models will be released; ensure the repository includes full reproduction scripts, exact hyperparameter settings for AMPN and QAT, and the per-layer bit-allocation tables.
- Experimental results would benefit from reporting standard deviations or multiple random seeds to substantiate claims of 'stable' performance at W1.58A2.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which have helped us identify areas to strengthen the manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: Theoretical analysis section: The justification for RobustQuantizer rests on the Hadamard transform converting arbitrary per-token activation distributions into per-token normal distributions that are easy to quantize at 2 bits. This distributional property is invoked to argue that activation quantization is no longer the primary bottleneck, but the manuscript provides no direct empirical verification (e.g., histograms, QQ plots, or statistical tests) on activation statistics from actual DiT attention and MLP blocks. Without this, the quantization error bounds and the central W1.58A2 claim on ImageNet-1K rest on an unconfirmed assumption.
Authors: We appreciate the referee's point that direct empirical verification would strengthen the theoretical justification. While the analysis derives the normalization property from the Hadamard matrix's orthogonality and its effect on per-token statistics, we agree that showing this on real DiT activations is valuable. In the revised manuscript we will add histograms, Q-Q plots, and summary statistics (skewness, kurtosis, and Shapiro-Wilk p-values) for activations extracted from both attention and MLP blocks of the DiT model, comparing distributions before and after the Hadamard transform. These additions will empirically support the claim that activation quantization ceases to be the dominant bottleneck and will reinforce the reported W1.58A2 results. revision: yes
Circularity Check
No significant circularity; claims rest on independent theoretical derivation and empirical results
full rationale
The paper derives RobustQuantizer from a theoretical analysis of the Hadamard transform's effect on per-token activation distributions, presents this as a first-principles property within the manuscript, and validates the overall W1.58A2 framework through direct experiments on ImageNet-1K. No step reduces a claimed prediction or uniqueness result to a fitted parameter from the target data, a self-citation chain, or a renaming of known patterns; the central performance claims remain externally falsifiable via the reported generation metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-layer activation bit allocations
axioms (1)
- domain assumption Hadamard transform converts unknown per-token distributions into per-token normal distributions
Reference graph
Works this paper leans on
-
[1]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. In NeurIPS, 2024
work page 2024
-
[2]
Shane Barratt and Rishi Rharma. A note on the inception score. In ICML Workshop, 2018
work page 2018
-
[3]
Vidmantas Bentkus. A lyapunov type bound in R ^d . Theory of Probability & Its Applications, 1997
work page 1997
- [4]
-
[5]
Sergey G. Bobkov. Refinements of berry--esseen inequalities in terms of lyapunov coefficients. Journal of Fourier Analysis and Applications, 2023
work page 2023
- [6]
-
[7]
Q-dit: Accurate post-training quantization for diffusion transformers
Lei Chen, Yuan Meng, Chen Tang, Xinzhu Ma, Jinyan Jiang, Xin Wang, Zhi Wang, and Wenwu Zhu. Q-dit: Accurate post-training quantization for diffusion transformers. In CVPR, 2025
work page 2025
-
[8]
Wavegrad: Estimating gradients for waveform generation
Nanxin Chen, Yu Zhang, Heiga Zen, Ron J Weiss, Mohammad Norouzi, and William Chan. Wavegrad: Estimating gradients for waveform generation. In ICLR, 2020
work page 2020
-
[9]
Hierarchical integration diffusion model for realistic image deblurring
Zheng Chen, Yulun Zhang, Ding Liu, Bin Xia, Jinjin Gu, Linghe Kong, and Xin Yuan. Hierarchical integration diffusion model for realistic image deblurring. In NeurIPS, 2023
work page 2023
-
[10]
Binarized diffusion model for image super-resolution
Zheng Chen, Haotong Qin, Yong Guo, Xiongfei Su, Xin Yuan, Linghe Kong, and Yulun Zhang. Binarized diffusion model for image super-resolution. In NeurIPS, 2024
work page 2024
-
[11]
Thomas M. Cover and Joy A. Thomas. Elements of Information Theory. 2006
work page 2006
-
[12]
Diffusion models in vision: A survey
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vision: A survey. TPAMI, 2023
work page 2023
-
[13]
Information Theory: Coding Theorems for Discrete Memoryless Systems
Imre Csisz \'a r and J \'a nos K \"o rner. Information Theory: Coding Theorems for Discrete Memoryless Systems. 2011
work page 2011
-
[14]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In NeurIPS, 2021
work page 2021
-
[15]
Mpq-dm: Mixed precision quantization for extremely low bit diffusion models
Weilun Feng, Haotong Qin, Chuanguang Yang, Zhulin An, Libo Huang, Boyu Diao, Fei Wang, Renshuai Tao, Yongjun Xu, and Michele Magno. Mpq-dm: Mixed precision quantization for extremely low bit diffusion models. In AAAI, 2025 a
work page 2025
-
[16]
Weilun Feng, Chuanguang Yang, Haotong Qin, Yuqi Li, Xiangqi Li, Zhulin An, Libo Huang, Boyu Diao, Fuzhen Zhuang, Michele Magno, Yongjun Xu, Yingli Tian, and Tingwen Huang. Mpq-dmv2: Flexible residual mixed precision quantization for low-bit diffusion models with temporal distillation. In arXiv preprint arXiv:2507.04290, 2025 b
-
[17]
Unified matrix treatment of the fast walsh--hadamard transform
Bernard Fino and Vadim Algazi. Unified matrix treatment of the fast walsh--hadamard transform. IEEE Transactions on Computers, 1976
work page 1976
-
[18]
Limit Distributions for Sums of Independent Random Variables
Boris Vladimirovich Gnedenko and Andrey Nikolaevich Kolmogorov. Limit Distributions for Sums of Independent Random Variables. 1954
work page 1954
-
[19]
Reti-diff: Illumination degradation image restoration with retinex-based latent diffusion model
Chunming He, Chengyu Fang, Yulun Zhang, Kai Li, Longxiang Tang, Chenyu You, Fengyang Xiao, Zhenhua Guo, and Xiu Li. Reti-diff: Illumination degradation image restoration with retinex-based latent diffusion model. arXiv preprint arXiv:2311.11638, 2023
-
[20]
Diffusion models in low-level vision: A survey
Chunming He, Yuqi Shen, Chengyu Fang, Fengyang Xiao, Longxiang Tang, Yulun Zhang, Wangmeng Zuo, Zhenhua Guo, and Xiu Li. Diffusion models in low-level vision: A survey. arXiv preprint arXiv:2406.11138, 2024 a
-
[21]
Efficientdm: Efficient quantization-aware fine-tuning of low-bit diffusion models
YeFei He, Jing Liu, Weijia Wu, Hong Zhou, and Bohan Zhuang. Efficientdm: Efficient quantization-aware fine-tuning of low-bit diffusion models. In ICLR, 2024 b
work page 2024
-
[22]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ransauer, Thomas Unterhiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017
work page 2017
-
[23]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020
work page 2020
-
[25]
St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In ECCV, 2022
work page 2022
-
[26]
Xing Hu, Yuan Cheng, Dawei Yang, Zukang Xu, Zhihang Yuan, Jiangyong Yu, Chen Xu, Zhe Jiang, and Sifan Zhou. Ostquant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting. In ICLR, 2025
work page 2025
-
[27]
Tq-dit: Efficient time-aware quantization for diffusion transformers
Younghye Hwang, Hyojin Lee, and Joonhyuk Kang. Tq-dit: Efficient time-aware quantization for diffusion transformers. In arXiv preprint arXiv:2502.04056, 2025
-
[28]
Edwin T. Jaynes. Information theory and statistical mechanics. 1957
work page 1957
-
[29]
Learned step size quantization
Steven K Esser, Jeffrey L McKinstry, Deepika Bablani, Rathinakumar Appuswamy, and Dharmendra S Modha. Learned step size quantization. In ICLR, 2019
work page 2019
-
[30]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019
work page 2019
-
[31]
Mixdit: Accelerating image diffusion transformer inference with mixed-precision mx quantization
Daeun Kim, Jinwoo Hwang, Changhun Oh, and Jongse Park. Mixdit: Accelerating image diffusion transformer inference with mixed-precision mx quantization. In arXiv preprint arXiv:2504.08398, 2025
-
[32]
Chris Kolb, Christian L. Müller, Bernd Bisch, and David Rügamer. Smoothing the edges: Smooth optimization for sparse regularization using hadamard overparametrization. In arXiv preprint arXiv:2307.03571, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junxian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han. Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models. In ICLR, 2025
work page 2025
-
[34]
Snapfusion: Text-to-image diffusion model on mobile devices within two seconds
Yanyu Li, Huan Wang, Qing Jin, Ju Hu, Pavlo Chemerys, Yun Fu, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Snapfusion: Text-to-image diffusion model on mobile devices within two seconds. In NeurIPS, 2024
work page 2024
-
[35]
Mpgraf: a modular and pre-trained graphformer for learning to rank at web-scale
Yuchen Li, Haoyi Xiong, Linghe Kong, Zeyi Sun, Hongyang Chen, Shuaiqiang Wang, and Dawei Yin. Mpgraf: a modular and pre-trained graphformer for learning to rank at web-scale. In ICDM, 2023 a
work page 2023
-
[36]
Mhrr: Moocs recommender service with meta hierarchical reinforced ranking
Yuchen Li, Haoyi Xiong, Linghe Kong, Rui Zhang, Fanqin Xu, Guihai Chen, and Minglu Li. Mhrr: Moocs recommender service with meta hierarchical reinforced ranking. TSC, 2023 b
work page 2023
-
[37]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. Duquant: Distributing outliers via dual transformation makes stronger quantized llms. In NeurIPS, 2025
work page 2025
-
[38]
Intelligent grimm-open-ended visual storytelling via latent diffusion models
Chang Liu, Haoning Wu, Yujie Zhong, Xiaoyun Zhang, Yanfeng Wang, and Weidi Xie. Intelligent grimm-open-ended visual storytelling via latent diffusion models. In CVPR, 2024
work page 2024
-
[39]
Kai Liu, Kaicheng Yang, Zheng Chen, Zhiteng Li, Yong Guo, Wenbo Li, Linghe Kong, and Yulun Zhang. Bimacosr: Binary one-step diffusion model leveraging flexible matrix compression for real super-resolution. In ICML, 2025 a
work page 2025
-
[40]
Hq-dit: Efficient diffusion transformer with fp4 hybrid quantization
Wenxuan Liu and Sai Qian Zhang. Hq-dit: Efficient diffusion transformer with fp4 hybrid quantization. In arXiv preprint arXiv:2405.19751, 2024
-
[41]
Spinquant: Llm quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: Llm quantization with learned rotations. In ICLR, 2025 b
work page 2025
-
[42]
S. Lloyd and Bell Laboratories. Least squares quantization in pcm. In IEEEXplore, 1982
work page 1982
-
[43]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019
work page 2019
-
[44]
Terdit: Ternary diffusion models with transformers
Xudong Lu, Aojun Zhou, Ziyi Lin, Yuhui Liu, Qi adn Xu, Renrui Zhang, Xue Yang, Junchi Yan, Peng Gao, and Hongsheng Li. Terdit: Ternary diffusion models with transformers. In arXiv preprint arXiv:2405.14854, 2024
-
[45]
Ptq4sam: Post-training quantization for segment anything
Chengtao Lv, Hong Chen, Jingyang Guo, Yifu Ding, and Xianglong Liu. Ptq4sam: Post-training quantization for segment anything. In CVPR, 2024
work page 2024
-
[46]
A calculus proof of the Cram\'er-Wold theorem
Russell Lyons and Kevin Zumbrun. A calculus proof of the cram \'e r--wold theorem. Proceedings of the American Mathematical Society, 2017. arXiv:1607.03206
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Shunming Ma, Hongyu Wang, Lingxiao Ma, Wenhui Wang, Lei adn Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits. In arXiv preprint arXiv:2402.17764, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Generating images with sparse representations
Charlie Nash, Jacob Menick, Sander Dieleman, and Peter W Battaglia. Generating images with sparse representations. In arXiv preprint arXiv:2103.03841, 2021
-
[49]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019
work page 2019
-
[50]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In ICCV, 2023
work page 2023
-
[51]
Kaare Brandt Petersen and Michael Syskind Pedersen. The matrix cookbook, 2012
work page 2012
-
[52]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj \"o rn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022
work page 2022
-
[53]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015
work page 2015
-
[54]
Imagenet large scale visual recognition challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. IJCV, 2015
work page 2015
-
[55]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciench Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In NeurIPS, 2016
work page 2016
-
[56]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017
work page 2017
-
[57]
Quest: Low-bit diffusion model quantization via efficient selective finetuning
Haoxuan Wang, Yuzhang Shang, Zhihang Yuan, Junchi Wu, and Yan Yan. Quest: Low-bit diffusion model quantization via efficient selective finetuning. In ICCV, 2025 a
work page 2025
-
[58]
Bitnet v2: Native 4-bit activations with hadamard transformation for 1-bit llms
Hongyu Wang, Shuming Ma, and Furu Wei. Bitnet v2: Native 4-bit activations with hadamard transformation for 1-bit llms. In arXiv preprint arXiv:2504.18415, 2025 b
-
[59]
Ptq4dit: Post-training quantization for diffusion transformers
Junyi Wu, Haoxuan Wang, Yuzhang Shang, Mubarak Shah, and Yan Yan. Ptq4dit: Post-training quantization for diffusion transformers. In NeurIPS, 2024
work page 2024
-
[60]
Diffusion models: A comprehensive survey of methods and applications
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications. In ACM Computing Surveys, 2023
work page 2023
-
[61]
Rao Yarlagadda and John Hershey. Hadamard Matrix Analysis and Synthesis: With Applications to Communications and Signal/Image Processing. 1993
work page 1993
-
[62]
F. Yates. A fast algorithm for hadamard transform. Mathematical Proceedings of the Cambridge Philosophical Society, 1968
work page 1968
-
[63]
Flexible residual binarization for image super-resolution
Yulun Zhang, Haotong Qin, Zixiang Zhao, Xianglong Liu, Martin Danelljan, and Fisher Yu. Flexible residual binarization for image super-resolution. In ICML, 2024
work page 2024
-
[64]
Shengen, Guohao Dai, and Yu Wang
Tianchen Zhao, Xuefei Ning, Tongcheng Fang, Enshu Liu, Guyue Huang, Zinan Lin, Yan. Shengen, Guohao Dai, and Yu Wang. Mixdq: Memory-efficient few-step text-to-image diffusion models with metric-decoupled mixed precision quantization. In ECCV, 2024 a
work page 2024
-
[65]
Tianchen Zhao, Tongcheng Fang, Haofeng Huang, Enshu Liu, Rui Wan, Widyadewi Soedarmadji, Shiyao Li, Zinan Lin, Guohao Dai, Shengen Yan, Xuefei Yang, Huazhong aand Nong, and Yu Wang. Vidit-q: Efficient and accurate quantization of diffusion transformers for image and video generation. In ICLR, 2025
work page 2025
-
[66]
Dc-solver: Improving predictor-corrector diffusion sampler via dynamic compensation
Wenliang Zhao, Haolin Wang, Jie Zhou, and Jiwen Lu. Dc-solver: Improving predictor-corrector diffusion sampler via dynamic compensation. In arXiv preprint arXiv:2409.03755, 2024, 2024 b
-
[67]
Bidm: Pushing the limit of quantization for diffusion models
Xinyu Zheng, Xianglong Liu, Yichen Bian, Xudong Ma, Yulun Zhang, Jiakai Wang, Jingyang Guo, and Haotong Qin. Bidm: Pushing the limit of quantization for diffusion models. In NeurIPS, 2024
work page 2024
-
[68]
Binarydm: Accurate weight binarization for efficient diffusion models
Xinyu Zheng, Xianglong Liu, Haotong Qin, Xudong Ma, Mingyuan Zhang, Haojie Hao, Jiakai Wang, Zixiang Zhao, Jingyang Guo, and Michele Magno. Binarydm: Accurate weight binarization for efficient diffusion models. In ICLR, 2025
work page 2025
-
[69]
Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients
Shuchang Zhou, Yuxin Wu, Zekun Ni, Xinyu Zhou, He Wen, and Yuheng Zou. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. ICLR, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.