The Illusion of Agentic Complexity in README.md Generation: Evaluating Single-Agent vs. Multi-Agent RAG Systems
Pith reviewed 2026-06-30 04:54 UTC · model grok-4.3
The pith
Single-agent RAG matches multi-agent lexical quality for READMEs while cutting token use by 86% and doubling speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
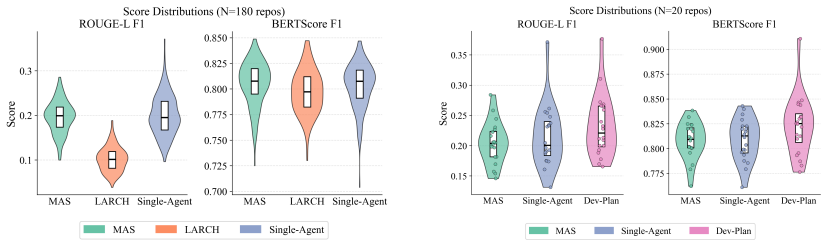
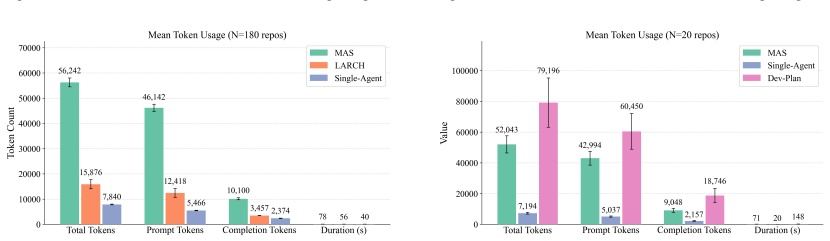
A single-agent RAG pipeline reaches lexical quality comparable to a specialized multi-agent system for generating README files, while cutting token consumption by 86 percent and running at twice the speed. Manual taxonomy review shows the multi-agent system reaches 98 percent structural consistency and fixes formatting problems seen in single-agent output. Autonomous planning is the main bottleneck in the pipelines; adding lightweight developer-guided plans produces the highest overall documentation quality and exceeds every other tested setup, including the LARCH baseline.
What carries the argument
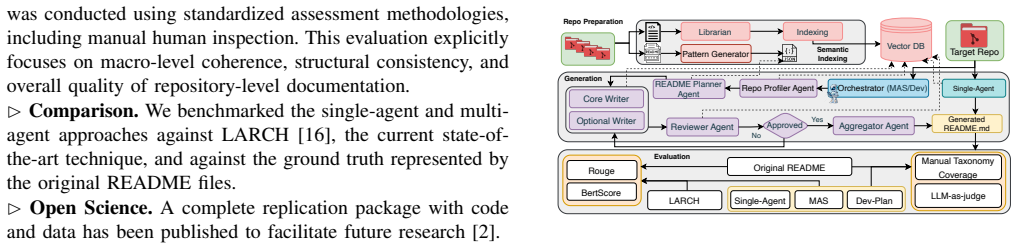
Head-to-head comparison of single-agent RAG, multi-agent RAG, and developer-guided planning variants, scored on lexical similarity, manual taxonomy for structure, token count, and runtime against LARCH and ground-truth READMEs.
If this is right
- Single-agent pipelines can substitute for multi-agent systems when lexical match is the main goal and resource limits matter.
- Multi-agent coordination raises structural consistency to 98 percent and removes common formatting errors.
- Light developer input on planning improves quality beyond fully autonomous single-agent or multi-agent runs.
- Autonomous planning remains the dominant performance constraint across all tested architectures.
Where Pith is reading between the lines
- The same efficiency-versus-structure trade-off could appear in related tasks such as code summarization or test-case generation.
- Teams that need only basic lexical coverage may prefer single-agent setups for daily use rather than full multi-agent orchestration.
- Testing the same pipelines on repositories from different domains or with larger codebases would show whether the 86 percent token saving and speed gain hold at scale.
Load-bearing premise
The chosen metrics of lexical similarity, structural consistency, token use, and speed, together with the LARCH baseline and selected repositories, give an unbiased picture of practical README quality for developers.
What would settle it
A replication study on a fresh collection of repositories in which the single-agent lexical scores fall clearly below the multi-agent scores or the developer-guided variant no longer ranks first would undermine the reported trade-off.
Figures
read the original abstract
Large Language Models (LLMs) are increasingly utilized to automate several software engineering tasks, including code completion, code summarization, testing, and the generation of repository-level documentation. While Multi-Agent Systems (MAS) are often adopted to support such tasks under the premise that task decomposition improves performance, the impact of architectural complexity on practical efficiency remains under-examined. This study empirically evaluates Retrieval-Augmented Generation (RAG) dependent architectures for the generation of README files for GitHub repositories. In this work, we conducted a systematic comparison between a Single-Agent pipeline, a specialized MAS, and a developer-guided planning (DevPlan) variant, benchmarked against LARCH -- a state-of-the-art baseline -- and the original ground truth. Results indicate a critical architectural trade-off: the Single-Agent pipeline achieves lexical quality comparable to MAS while reducing token consumption by 86% and operating at twice the speed. In contrast, manual taxonomy analysis demonstrates that MAS achieves high structural consistency (98%), resolving formatting issues observed in single-agent approaches. Autonomous planning is identified as the primary pipeline bottleneck; incorporating lightweight developer-guided plans produces the highest overall documentation quality, surpassing all the analyzed configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study comparing Single-Agent, Multi-Agent System (MAS), and developer-guided planning (DevPlan) RAG pipelines for generating README.md files from GitHub repositories. It benchmarks these against the LARCH baseline and original ground truth, concluding that Single-Agent matches MAS in lexical quality while consuming 86% fewer tokens and running at twice the speed, MAS achieves 98% structural consistency, and DevPlan produces the highest overall quality by addressing the bottleneck of autonomous planning.
Significance. If the findings are robust, the work provides evidence against the default adoption of complex multi-agent architectures for documentation tasks in software engineering, demonstrating substantial efficiency gains from simpler designs and benefits from lightweight human guidance. The direct comparison to an external baseline and ground truth is a strength, as is the identification of planning as a key bottleneck.
major comments (2)
- [Abstract] The abstract states quantitative results (e.g., 86% token reduction, 98% consistency, 2x speed) but supplies no details on repository sample size, selection criteria, statistical tests, error bars, or controls for confounds such as repository size or domain. This absence makes it impossible to verify whether the data support the stated claims about architectural trade-offs.
- [Evaluation] The central claims of an architectural trade-off and DevPlan superiority rest on lexical similarity, manual taxonomy consistency, token count, and speed as proxies for README quality. These metrics do not directly assess factual accuracy of generated content, completeness for onboarding, or developer-perceived usefulness. Without additional validation or metrics addressing these aspects, the reported conclusions do not necessarily follow.
minor comments (2)
- [Results] Ensure all tables and figures report exact sample sizes, confidence intervals where applicable, and full configuration details for each pipeline variant.
- [Methodology] Clarify the exact procedure and inter-rater reliability for the manual taxonomy analysis used to compute the 98% structural consistency figure.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments. We respond to each major comment below and have revised the manuscript where we agree changes are needed to improve clarity and address limitations.
read point-by-point responses
-
Referee: [Abstract] The abstract states quantitative results (e.g., 86% token reduction, 98% consistency, 2x speed) but supplies no details on repository sample size, selection criteria, statistical tests, error bars, or controls for confounds such as repository size or domain. This absence makes it impossible to verify whether the data support the stated claims about architectural trade-offs.
Authors: The abstract provides a concise summary of the results. Full details on the experimental setup, including the number of repositories evaluated, selection criteria, and controls for repository characteristics, are described in the Methodology and Evaluation sections. To address the referee's concern, we have revised the abstract to include the sample size and a note on the controls used, while maintaining brevity. revision: yes
-
Referee: [Evaluation] The central claims of an architectural trade-off and DevPlan superiority rest on lexical similarity, manual taxonomy consistency, token count, and speed as proxies for README quality. These metrics do not directly assess factual accuracy of generated content, completeness for onboarding, or developer-perceived usefulness. Without additional validation or metrics addressing these aspects, the reported conclusions do not necessarily follow.
Authors: We agree that the metrics employed are proxies and do not directly measure factual accuracy or perceived usefulness. Our study focuses on efficiency and structural aspects using standard lexical and consistency metrics, benchmarked against ground truth and LARCH. The conclusions regarding the trade-offs are supported within the scope of these metrics. We have added a paragraph in the Discussion section acknowledging this limitation and outlining plans for future human-centered evaluation. revision: partial
Circularity Check
Empirical benchmarking with direct measurements; no derivations or self-referential reductions
full rationale
The paper is a comparative empirical study that directly measures lexical similarity, structural consistency (via manual taxonomy), token consumption, and runtime speed for Single-Agent, MAS, and DevPlan pipelines against ground-truth READMEs and the external LARCH baseline. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the abstract or described methodology. All reported trade-offs follow from observed experimental outcomes rather than any definitional or self-referential construction. The metric-validity concern raised by the skeptic is a question of external validity, not circularity.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.