Prediction of Small Molecule Kinase Inhibitors for Chemotherapy Using Deep Learning
Pith reviewed 2026-05-25 12:37 UTC · model grok-4.3
The pith
Deep learning models trained on molecular data can predict which small molecules inhibit eight kinases relevant to cancer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
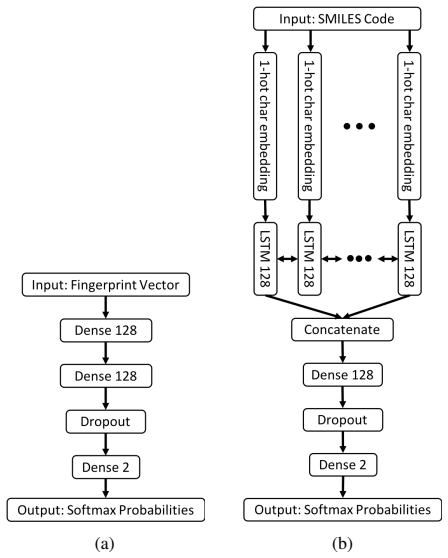
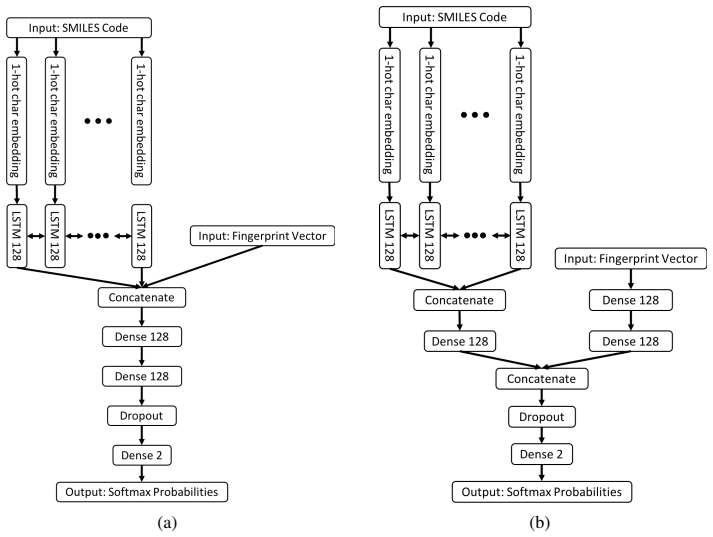
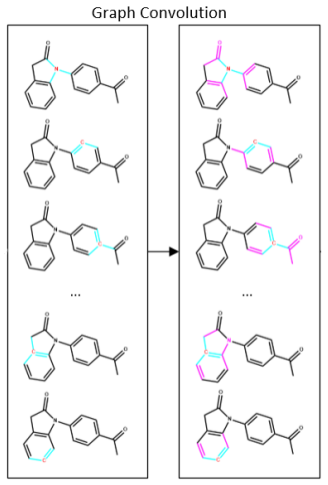
The project focuses on predicting the inhibition activity of small molecules targeting 8 different kinases using multiple deep learning models. We trained fingerprint-based MLPs and SMILES-based RNNs and molecular GCNs to accurately predict inhibitory activity targeting these 8 kinases.
What carries the argument
Three neural network architectures operating on molecular structure representations: multilayer perceptrons on fingerprints, recurrent networks on SMILES strings, and graph convolutional networks on molecular graphs, each learning to map structure to measured kinase inhibition.
If this is right
- Computational predictions would allow screening of millions of compounds per kinase without physical synthesis and testing.
- The approach supports matching inhibitors to the specific kinase dependencies of individual tumors.
- Models trained on these eight kinases provide a template that can be retrained or extended when data for additional targets becomes available.
- Early-stage drug discovery time and cost decrease by prioritizing only the most promising compounds for laboratory follow-up.
Where Pith is reading between the lines
- Ensemble use of the three architectures could yield more reliable rankings than any single model.
- The same representation-and-network strategy could be tested on predicting selectivity across related kinases or on non-kinase targets.
- If the models capture general chemical features, retraining on new assay data might transfer to predicting other molecular behaviors such as cellular permeability.
Load-bearing premise
The experimental inhibition measurements for the eight kinases are representative and large enough for the chosen models to learn structure-activity patterns that apply to new molecules.
What would settle it
Measuring inhibition for a large held-out collection of molecules whose experimental values show no correlation with the models' predictions.
Figures
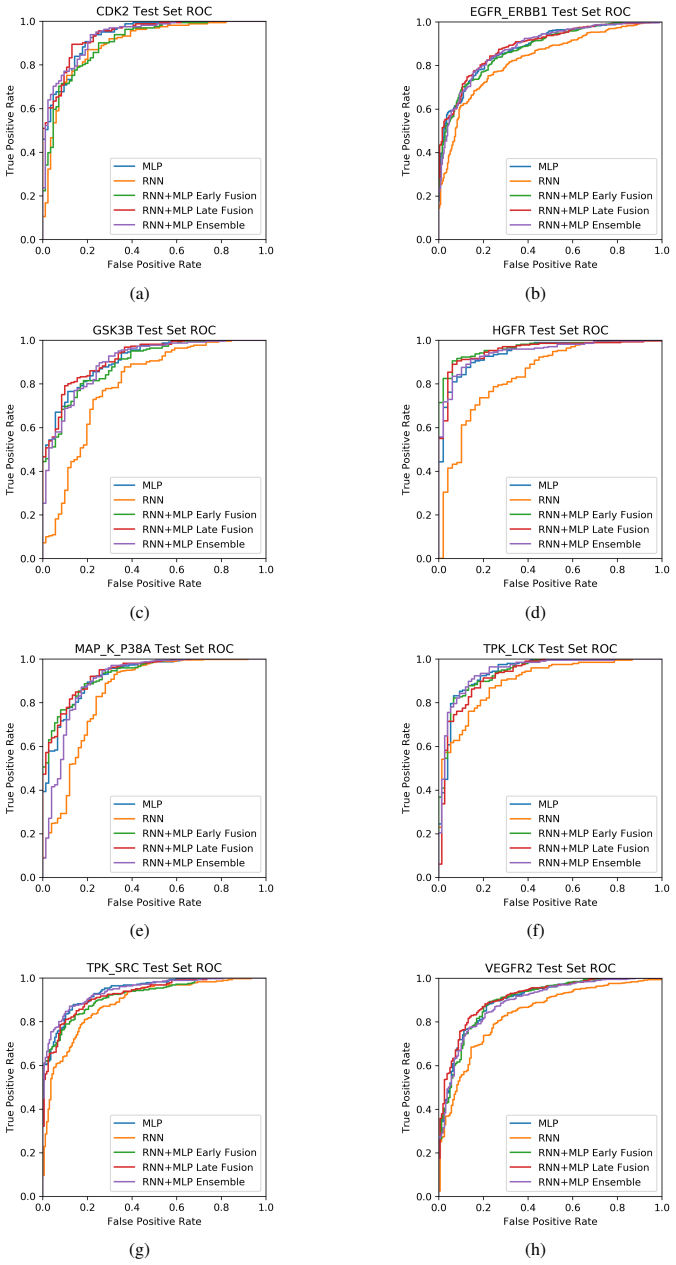
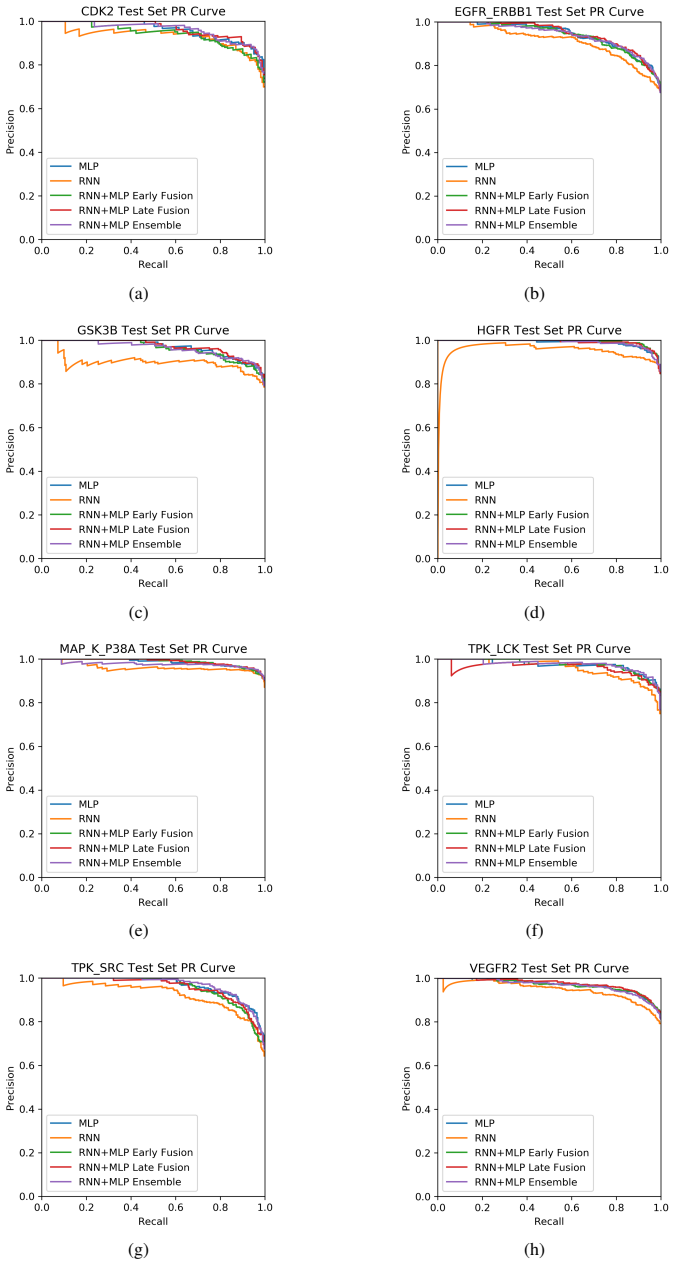
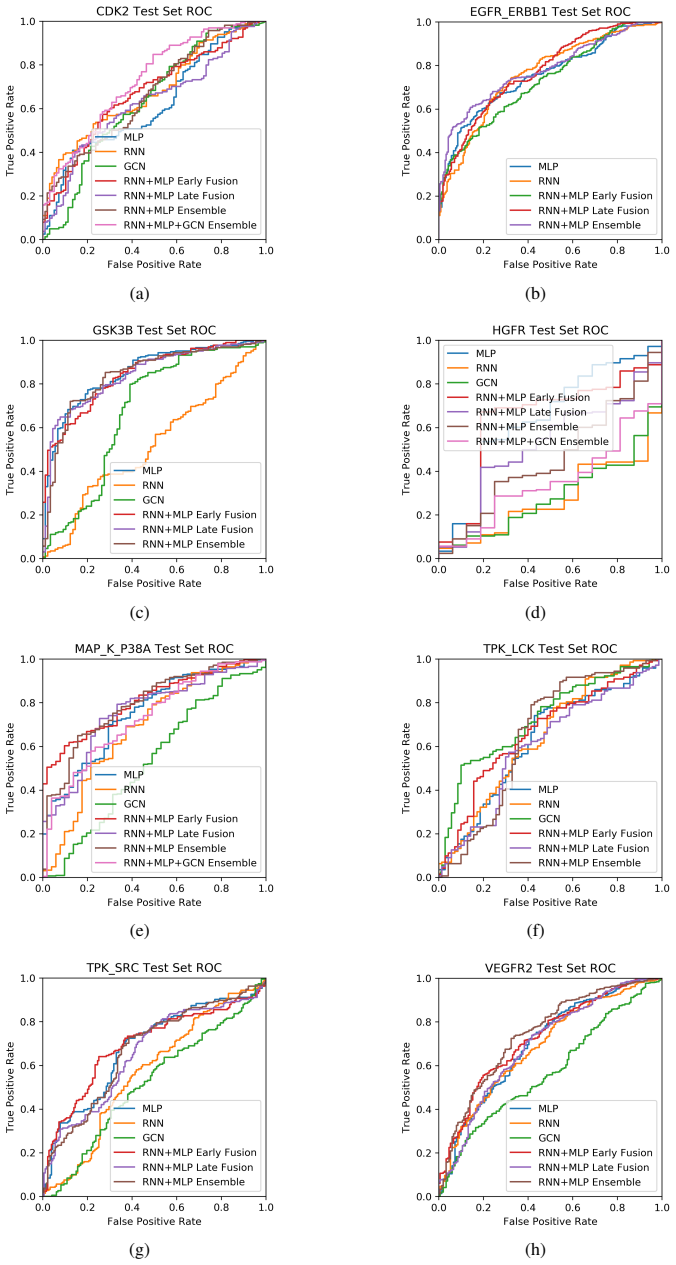
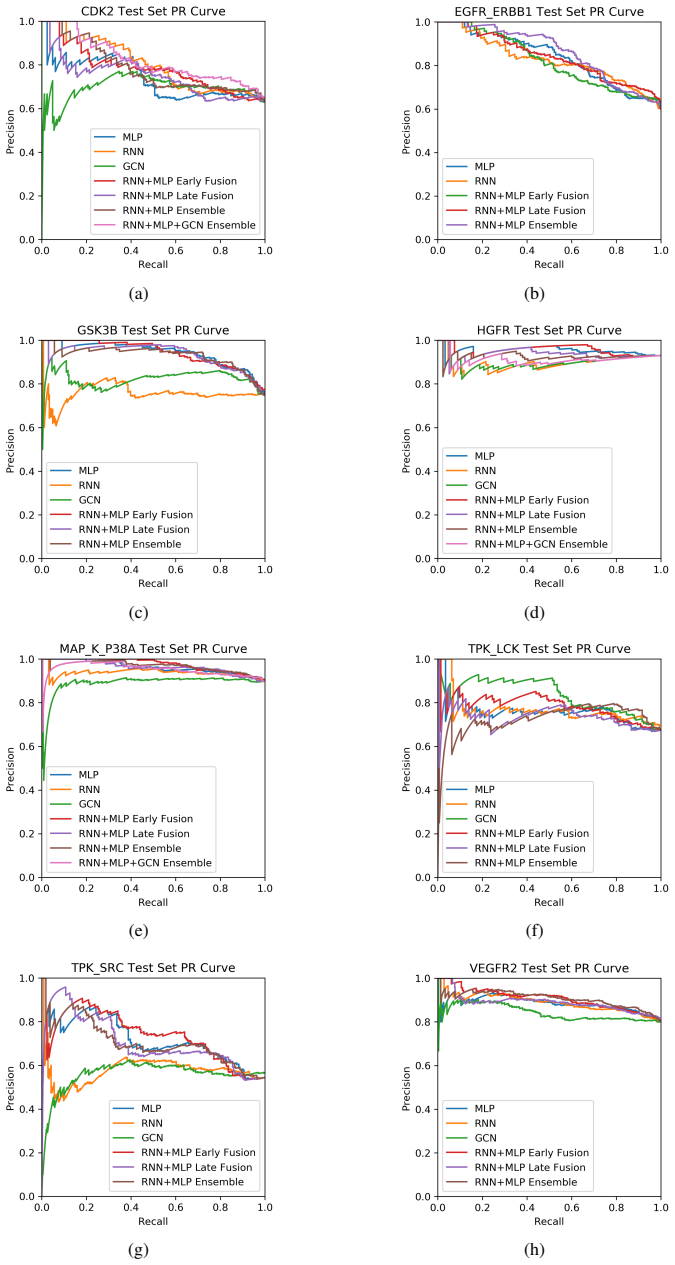
read the original abstract
The current state of cancer therapeutics has been moving away from one-size-fits-all cytotoxic chemotherapy, and towards a more individualized and specific approach involving the targeting of each tumor's genetic vulnerabilities. Different tumors, even of the same type, may be more reliant on certain cellular pathways more than others. With modern advancements in our understanding of cancer genome sequencing, these pathways can be discovered. Investigating each of the millions of possible small molecule inhibitors for each kinase in vitro, however, would be extremely expensive and time consuming. This project focuses on predicting the inhibition activity of small molecules targeting 8 different kinases using multiple deep learning models. We trained fingerprint-based MLPs and simplified molecular-input line-entry specification (SMILES)-based recurrent neural networks (RNNs) and molecular graph convolutional networks (GCNs) to accurately predict inhibitory activity targeting these 8 kinases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that fingerprint-based MLPs, SMILES-based RNNs, and molecular GCNs were trained to accurately predict the inhibitory activity of small molecules against eight kinases relevant to targeted cancer chemotherapy.
Significance. If the models achieve strong generalization on held-out molecules, the work could support virtual screening to reduce the cost of identifying kinase inhibitors. The comparison across three distinct architectures is a constructive element, though no evidence of superior performance or parameter-free derivations is supplied.
major comments (2)
- [Abstract] Abstract: the claim that the models were trained 'to accurately predict inhibitory activity' is unsupported because the abstract supplies no performance metrics (e.g., R², RMSE, AUC), no baseline comparisons, no cross-validation protocol, and no error analysis. Without these data the central claim cannot be evaluated.
- [Abstract] Abstract: the weakest assumption—that the experimental inhibition data for the eight kinases are representative and sufficient for learning generalizable SAR—remains untested in the provided text; no details on dataset size, chemical diversity, or activity range are given.
minor comments (1)
- The title refers to 'Chemotherapy' while the abstract correctly emphasizes targeted kinase inhibition; consider clarifying the distinction for precision.
Simulated Author's Rebuttal
We thank the referee for the comments on our manuscript. We address each major comment below and agree that the abstract requires revision to better support the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the models were trained 'to accurately predict inhibitory activity' is unsupported because the abstract supplies no performance metrics (e.g., R², RMSE, AUC), no baseline comparisons, no cross-validation protocol, and no error analysis. Without these data the central claim cannot be evaluated.
Authors: We agree that the abstract does not contain quantitative metrics or validation details. The full manuscript reports 5-fold cross-validation results including AUC-ROC values for each kinase along with comparisons to baseline models. We will revise the abstract to include representative performance metrics and a brief statement on the cross-validation protocol. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that the experimental inhibition data for the eight kinases are representative and sufficient for learning generalizable SAR—remains untested in the provided text; no details on dataset size, chemical diversity, or activity range are given.
Authors: We acknowledge that the abstract omits dataset characteristics. The manuscript methods section describes the datasets drawn from public sources, including compound counts per kinase and activity value distributions. We will add a concise summary of dataset sizes and chemical diversity to the abstract. revision: yes
Circularity Check
No significant circularity
full rationale
The paper applies standard supervised deep learning (MLP on fingerprints, RNN on SMILES, GCN on graphs) to predict kinase inhibition from external experimental assay data. No equations, derivations, or self-referential definitions appear in the abstract or described content. No predictions reduce to fitted inputs by construction, no load-bearing self-citations, and no ansatzes or uniqueness claims are invoked. The central claim remains an empirical regression task whose validity depends on data representativeness rather than internal definitional closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. L. Siegal, K. D. Miller, and A. Jemal, “Cancer statistics, 2018,” in CA: A Cancer Journal for Clinicians, pp. 68:7–30, 2018
work page 2018
-
[2]
C.-Y . Huang, D.-T. Ju, C.-F. Chang, P. M. Reddy, and B. K. Velmurugan, “A review on the effects of current chemotherapy drugs and natural agents in treating non–small cell lung cancer,” in BioMedicine, pp. 12–23, 2017
work page 2017
-
[3]
A comprehensive review of protein kinase inhibitors for cancer therapy,
R. Kannaiyan and D. Mahadevan, “A comprehensive review of protein kinase inhibitors for cancer therapy,” in Expert Review of Anticancer Therapy , pp. 1249–1270, 2018
work page 2018
-
[4]
Glycogen synthase kinase 3 beta: can it be a target for oral cancer,
R. Mishra, “Glycogen synthase kinase 3 beta: can it be a target for oral cancer,” in Molecular Cancer, 2010. 14
work page 2010
-
[5]
The hepatocyte growth factor receptor: Structure, function and pharmacological targeting in cancer,
F. Cecchi, D. C. Rabe, and D. P. Bottaro, “The hepatocyte growth factor receptor: Structure, function and pharmacological targeting in cancer,” in Molecular Cancer, p. 146–151, 2010
work page 2010
-
[6]
p38 map kinase: a convergence point in cancer therapy,
J. M. Olson and A. R. Hallahan, “p38 map kinase: a convergence point in cancer therapy,” in TRENDS in Molecular Medicine , pp. 125–129, 2010
work page 2010
-
[7]
N. R. Smith, D. Baker, N. H. James, K. Ratcliffe, M. Jenkins, S. E. Ashton, G. Sproat, R. Swann, N. Gray, A. Ryan, J. M. Jurgensmeier, and C. Womack, “Vascular endothelial growth factor receptors vegfr-2 and vegfr-3 are localized primarily to the vasculature in human primary solid cancers,” in Human Cancer Biology, pp. 3548–61, 2010
work page 2010
-
[8]
Targeting cancer with small molecule kinase inhibitors,
J. Zhang, P. L. Yang, and N. S. Gray, “Targeting cancer with small molecule kinase inhibitors,” in Nature Reviews, pp. 28–39, 2009
work page 2009
-
[9]
Classifying “kinase inhibitor-likeness
H. Briem and J. Gunther, “Classifying “kinase inhibitor-likeness” by using machine-learning methods,” in Nature Reviews, pp. 558–566, 2005
work page 2005
-
[10]
Tsar datasheet version 3.3 accelrys inc,
“Tsar datasheet version 3.3 accelrys inc,” inhttp://www.3dsbiovia.com/products/datasheets/tsar .pdf
-
[11]
Molecular Graph Convolutions: Moving Beyond Fingerprints
S. Kearnes, K. McCloskey, M. Berndl, V . Pande, and P. Riley, “Molecular graph convolutions: Moving beyond fingerprints,” arXiv preprint arXiv:1603.00856, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
K. Xiao, “Cancer inhibitors dataset.” https://www.kaggle.com/xiaotawkaggle/ inhibitors
-
[13]
Smiles. 2. algorithm for generation of unique smiles notation,
D. Weininger, A. Weininger, and J. L. Weining, “Smiles. 2. algorithm for generation of unique smiles notation,” Journal of Chemical Information and Modeling , 1989
work page 1989
-
[14]
Atom pairs as molecular features in structure-activity studies: definition and applications,
R. E. Carhart, D. H. Smith, and R. Venkataraghavan, “Atom pairs as molecular features in structure-activity studies: definition and applications,” Journal of Chemical Information and Computer Sciences, 1985
work page 1985
-
[15]
Extended-connectivity fingerprints,
D. Rogers and M. Hahn, “Extended-connectivity fingerprints,”Journal of Chemical Information and Modeling, 2010
work page 2010
-
[16]
R. Nilakantan, N. Bauman, J. S. Dixon, and R. Venkataraghavan, “Topological torsion: a new molecular descriptor for sar applications. comparison with other descriptors,” Journal of Chemical Information and Computer Sciences , 1987
work page 1987
-
[17]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
work page 1997
-
[19]
Chemi-net: a graph convolutional network for accurate drug property prediction
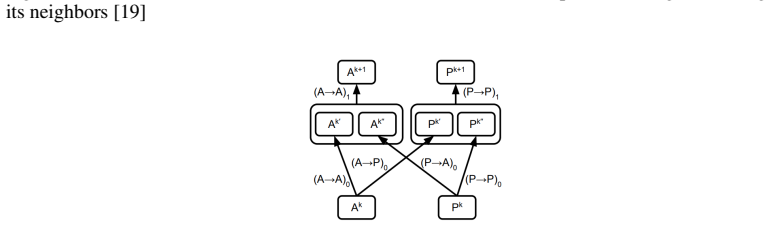
K. Liu, X. Sun, L. Jia, J. Ma, H. Xing, J. Wu, H. Gao, Y . Sun, F. Boulnois, and J. Fan, “Chemi- net: A molecular graph convolutional network for accurate drug property prediction,” arXiv preprint arXiv:1803.06236, 2017. 15
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.