ComMem: Complementary Memory Systems for Test-Time Adaptation of Vision-Language Models
Pith reviewed 2026-06-30 09:54 UTC · model grok-4.3
The pith
ComMem adapts vision-language models at test time by maintaining a fast visual cache from high-confidence samples and a slow textual prototype memory that are jointly optimized for cross-modal consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
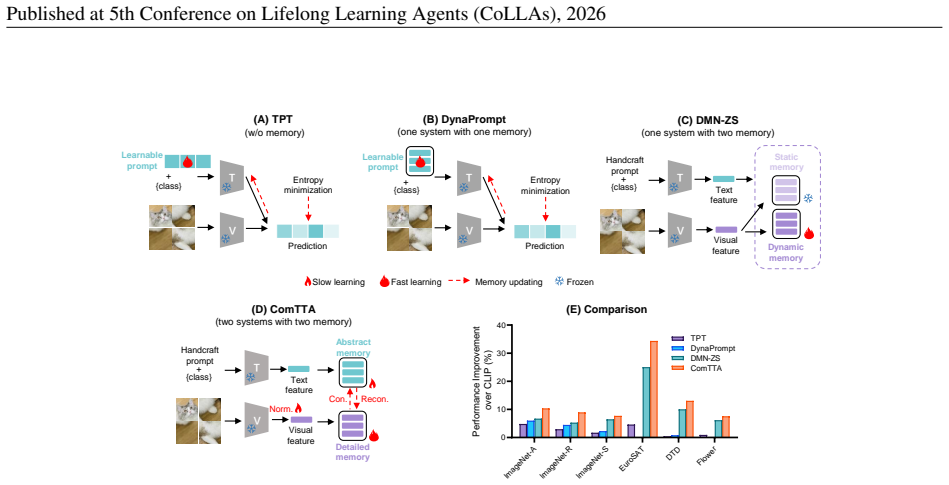
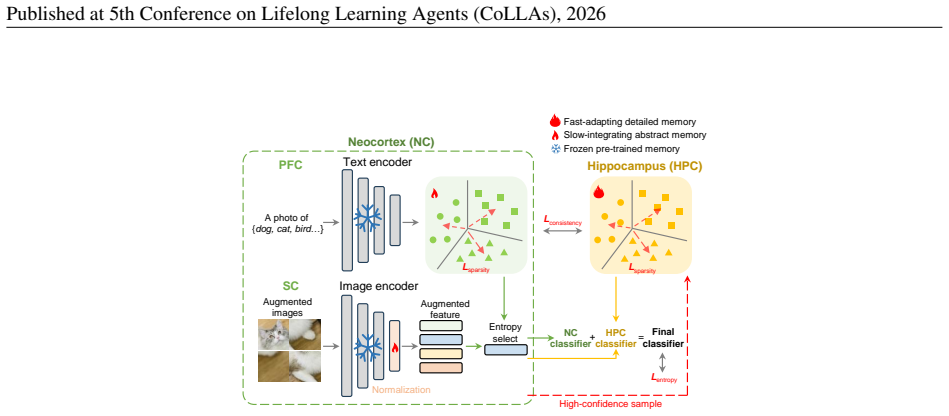
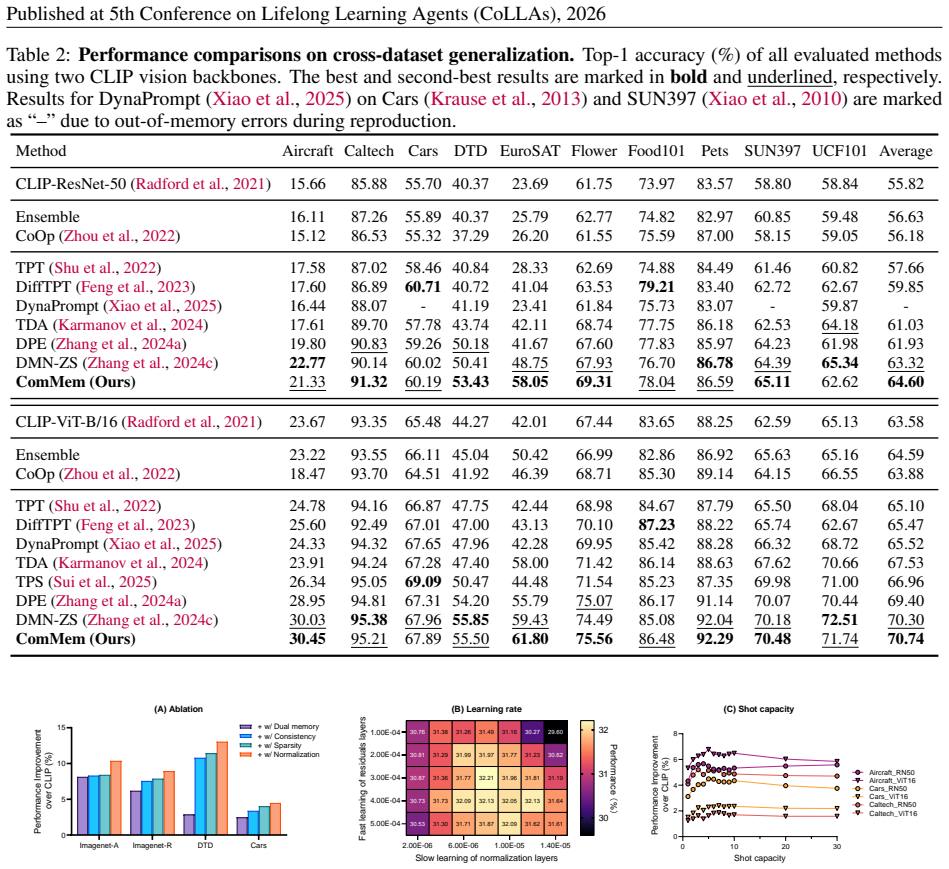
ComMem mimics the distinct but cooperative roles of the hippocampus and neocortex to enable effective TTA for VLMs. It consists of a fast-adapting detailed memory that forms a dynamic visual cache from high-confidence test samples and a slow-integrating abstract memory that continually refines global textual prototypes. For each test instance, ComMem jointly optimizes both memory systems to ensure cross-modal consistency. Extensive experiments on 15 benchmark datasets show that ComMem significantly outperforms state-of-the-art methods under both natural distribution shifts and cross-dataset generalization.
What carries the argument
The pair of complementary memory systems consisting of a fast-adapting detailed visual cache built from high-confidence samples and a slow-integrating abstract textual prototype memory, jointly optimized per test instance to enforce cross-modal consistency.
If this is right
- VLMs accumulate knowledge across test instances instead of resetting or adapting only locally on each one.
- Cross-modal consistency between visual and textual representations improves robustness to natural distribution shifts.
- Performance gains appear in both single-dataset shifts and cross-dataset generalization settings.
- The multi-modal nature of VLMs is actively used rather than treated as separate unimodal streams.
- The method provides a template for other TTA approaches that must handle streaming data over time.
Where Pith is reading between the lines
- The same dual-memory pattern could be tested on non-VLM multi-modal models such as those combining vision with audio or sensor data.
- If the high-confidence sampling step proves stable, the approach might reduce reliance on labeled validation sets during deployment.
- Scaling the memory sizes or update rates could reveal whether the method remains effective on very long test streams without capacity limits.
- Integration with existing prompt-tuning or feature-adaptation modules might compound the reported gains without changing the core memory design.
Load-bearing premise
High-confidence test samples will always supply reliable data for the visual cache and joint optimization of the two memories will preserve consistency without introducing errors or gradual drift.
What would settle it
An experiment that applies ComMem to the same 15 benchmarks and finds no outperformance over prior TTA methods, or an ablation that removes either the visual cache or the textual prototypes and measures whether gains disappear.
Figures


read the original abstract
Test-time adaptation (TTA) of vision-language models (VLMs) is essential for their robust deployment in dynamic, real-world environments. However, existing TTA methods often adapt locally without accumulating knowledge over time, or operating within a single modality without exploiting VLMs' inherently multi-modal nature. Inspired by the \textbf{Com}plementary \textbf{Mem}ory systems of the biological brain, we propose \textbf{ComMem}, an innovative approach that mimics the distinct but cooperative roles of the hippocampus and neocortex to enable effective TTA for VLMs. ComMem consists of two key components: a fast-adapting detailed memory, akin to the hippocampus, that forms a dynamic visual cache from high-confidence test samples; and a slow-integrating abstract memory, akin to the neocortex, that continually refines global textual prototypes. For each test instance, ComMem jointly optimizes both memory systems to ensure cross-modal consistency. Extensive experiments on 15 benchmark datasets show that ComMem significantly outperforms state-of-the-art methods under both natural distribution shifts and cross-dataset generalization, offering a promising direction for enhancing VLMs' practical adaptability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ComMem, a test-time adaptation method for vision-language models inspired by complementary memory systems (hippocampus-like fast visual cache from high-confidence test samples and neocortex-like slow textual prototypes). The two memories are jointly optimized per test instance to enforce cross-modal consistency. Extensive experiments on 15 benchmark datasets are claimed to show significant outperformance over SOTA under natural distribution shifts and cross-dataset generalization.
Significance. If the experimental claims hold after full verification, the dual-memory design could meaningfully advance TTA for VLMs by enabling temporal knowledge accumulation and explicit multi-modal interaction, areas where prior methods are limited. The biological analogy provides a coherent organizing principle, but significance is tempered by the absence of any reported safeguards against cache pollution.
major comments (2)
- [Abstract] Abstract: the central premise that high-confidence test samples form a reliable dynamic visual cache is load-bearing for all reported gains, yet the description provides no mechanism (entropy threshold, cross-modal consistency check before insertion, or delayed update) to prevent erroneous entries under distribution shift; this directly engages the risk that initial misclassifications pollute both memories and inflate the 15-dataset results.
- [Abstract] Abstract: the joint optimization step that is asserted to produce stable cross-modal consistency is described only at the level of a high-level claim; without the actual objective, update rules, or any ablation isolating its contribution, it is impossible to determine whether the reported superiority is attributable to the complementary-memory architecture or to post-hoc tuning choices.
minor comments (1)
- The abstract refers to '15 benchmark datasets' and 'state-of-the-art methods' without naming either, which prevents immediate assessment of coverage or baseline strength.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying points where the abstract's high-level presentation may obscure key methodological details. We address each major comment below with references to the full manuscript and indicate planned revisions for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central premise that high-confidence test samples form a reliable dynamic visual cache is load-bearing for all reported gains, yet the description provides no mechanism (entropy threshold, cross-modal consistency check before insertion, or delayed update) to prevent erroneous entries under distribution shift; this directly engages the risk that initial misclassifications pollute both memories and inflate the 15-dataset results.
Authors: The abstract summarizes the high-confidence criterion at a conceptual level, but the full manuscript (Section 3.2) specifies the insertion rule: a sample enters the visual cache only when its softmax entropy falls below 0.1 and its prediction is consistent with the current textual prototype (measured by cosine similarity > 0.7). Updates are performed after the per-instance joint optimization step rather than immediately. We acknowledge that the abstract itself does not make these safeguards explicit and that an explicit discussion of cache-pollution risk is absent. We will revise the abstract to include a one-sentence description of the insertion criteria and add a short paragraph in Section 3.2 on pollution mitigation, together with a new ablation measuring performance when the threshold is removed. revision: yes
-
Referee: [Abstract] Abstract: the joint optimization step that is asserted to produce stable cross-modal consistency is described only at the level of a high-level claim; without the actual objective, update rules, or any ablation isolating its contribution, it is impossible to determine whether the reported superiority is attributable to the complementary-memory architecture or to post-hoc tuning choices.
Authors: The abstract condenses the joint-optimization step, but the full manuscript provides the concrete objective in Equation (3) (cross-entropy on the visual cache plus a consistency term between visual and textual embeddings) and the alternating update procedure in Algorithm 1. Section 4.3 contains an ablation that removes the consistency term while keeping all other components fixed, showing a 3.2-point average drop across the 15 datasets. To improve accessibility, we will append a parenthetical reference in the abstract to the objective and update rule and will ensure the ablation table is clearly labeled as isolating the joint-optimization contribution. revision: partial
Circularity Check
No circularity: empirical method proposal with no derivation chain or self-referential reductions
full rationale
The paper presents ComMem as a bio-inspired TTA architecture consisting of a fast visual cache and slow textual prototypes that are jointly optimized. No equations, fitted parameters, uniqueness theorems, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The central claims rest on experimental outcomes across 15 datasets rather than any mathematical derivation that could be circular. This is the expected outcome for a high-level algorithmic proposal without a formal proof or parameter-fitting step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Biological complementary memory systems (hippocampus and neocortex) provide a useful and transferable model for designing effective TTA mechanisms in VLMs
Reference graph
Works this paper leans on
-
[1]
Align your prompts: Test-time prompting with distribution alignment for zero-shot generalization
Jameel Abdul Samadh, Mohammad Hanan Gani, Noor Hussein, Muhammad Uzair Khattak, Muhammad Muzammal Naseer, Fahad Shahbaz Khan, and Salman H Khan. Align your prompts: Test-time prompting with distribution alignment for zero-shot generalization. Advances in Neural Information Processing Systems, 36: 0 80396--80413, 2023
2023
-
[2]
Evaluating clip: towards characterization of broader capabilities and downstream implications
Sandhini Agarwal, Gretchen Krueger, Jack Clark, Alec Radford, Jong Wook Kim, and Miles Brundage. Evaluating clip: towards characterization of broader capabilities and downstream implications. arXiv preprint arXiv:2108.02818, 2021
-
[3]
Food-101--mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101--mining discriminative components with random forests. In European Conference on Computer Vision, pp.\ 446--461. Springer, 2014
2014
-
[4]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 3606--3613, 2014
2014
-
[5]
Phase consistency dynamics of memory encoding
Ryan A Colyer and Michael J Kahana. Phase consistency dynamics of memory encoding. Journal of Neuroscience, 45 0 (35), 2025
2025
-
[6]
Shuang Cui, Jinglin Xu, Yi Li, Xiongxin Tang, Jiangmeng Li, Jiahuan Zhou, Fanjiang Xu, Fuchun Sun, and Hui Xiong. Bayestta: Continual-temporal test-time adaptation for vision-language models via gaussian discriminant analysis. arXiv preprint arXiv:2507.08607, 2025
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 248--255, 2009
2009
-
[8]
Adapting vision-language models without labels: A comprehensive survey
Hao Dong, Lijun Sheng, Jian Liang, Ran He, Eleni Chatzi, and Olga Fink. Adapting vision-language models without labels: A comprehensive survey. arXiv preprint arXiv:2508.05547, 2025
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. Computer Vision and Image Understanding, 106 0 (1): 0 59--70, 2007
2007
-
[11]
Diverse data augmentation with diffusions for effective test-time prompt tuning
Chun-Mei Feng, Kai Yu, Yong Liu, Salman Khan, and Wangmeng Zuo. Diverse data augmentation with diffusions for effective test-time prompt tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 2704--2714, 2023
2023
-
[12]
standard model
Ali Golbabaei and Paul W Frankland. The post-“standard model” age: Updating theories of systems consolidation. Neuron, 113 0 (3): 0 339--341, 2025
2025
-
[13]
Semi-supervised learning by entropy minimization
Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. Advances in neural information processing systems, 17, 2004
2004
-
[14]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 770--778, 2016
2016
-
[15]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12 0 (7): 0 2217--2226, 2019
2019
-
[16]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 8340--8349, 2021 a
2021
-
[17]
Natural adversarial examples
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 15262--15271, 2021 b
2021
-
[18]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pp.\ 448--456. pmlr, 2015
2015
-
[19]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pp.\ 4904--4916. PMLR, 2021
2021
-
[20]
Efficient test-time adaptation of vision-language models
Adilbek Karmanov, Dayan Guan, Shijian Lu, Abdulmotaleb El Saddik, and Eric Xing. Efficient test-time adaptation of vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[21]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp.\ 554--561, 2013
2013
-
[22]
Reconstructing a new hippocampal engram for systems reconsolidation and remote memory updating
Bo Lei, Bilin Kang, Yuejun Hao, Haoyu Yang, Zihan Zhong, Zihan Zhai, and Yi Zhong. Reconstructing a new hippocampal engram for systems reconsolidation and remote memory updating. Neuron, 113 0 (3): 0 471--485, 2025
2025
-
[23]
A comprehensive survey on test-time adaptation under distribution shifts
Jian Liang, Ran He, and Tieniu Tan. A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision, 133 0 (1): 0 31--64, 2025
2025
-
[24]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Swapprompt: Test-time prompt adaptation for vision-language models
Xiaosong Ma, Jie Zhang, Song Guo, and Wenchao Xu. Swapprompt: Test-time prompt adaptation for vision-language models. Advances in Neural Information Processing Systems, 36: 0 65252--65264, 2023
2023
-
[26]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[27]
The role of reward and reward uncertainty in episodic memory
Alice Mason, Simon Farrell, Paul Howard-Jones, and Casimir JH Ludwig. The role of reward and reward uncertainty in episodic memory. Journal of memory and language, 96: 0 62--77, 2017
2017
-
[28]
Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory
James L McClelland, Bruce L McNaughton, and Randall C O'Reilly. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychological review, 102 0 (3): 0 419, 1995
1995
-
[29]
Task bias in contrastive vision-language models
Sachit Menon, Ishaan Preetam Chandratreya, and Carl Vondrick. Task bias in contrastive vision-language models. International Journal of Computer Vision, 132 0 (6): 0 2026--2040, 2024
2026
-
[30]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In Indian Conference on Computer Vision, Graphics and Image Processing, pp.\ 722--729. IEEE, 2008
2008
-
[31]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Neural associative memories and sparse coding
G \"u nther Palm. Neural associative memories and sparse coding. Neural Networks, 37: 0 165--171, 2013
2013
-
[33]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 3498--3505, 2012
2012
-
[34]
What does a platypus look like? generating customized prompts for zero-shot image classification
Sarah Pratt, Ian Covert, Rosanne Liu, and Ali Farhadi. What does a platypus look like? generating customized prompts for zero-shot image classification. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 15691--15701, 2023
2023
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pp.\ 8748--8763. PMLR, 2021
2021
-
[36]
Uncertainty in estimating distances from memory
Gabriel A Radvansky, Laura A Carlson-Radvansky, and David E Irwin. Uncertainty in estimating distances from memory. Memory & Cognition, 23 0 (5): 0 596--606, 1995
1995
-
[37]
Do imagenet classifiers generalize to imagenet? In International Conference on Machine Learning, pp.\ 5389--5400
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? In International Conference on Machine Learning, pp.\ 5389--5400. PMLR, 2019
2019
-
[38]
Test-time prompt tuning for zero-shot generalization in vision-language models
Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. Test-time prompt tuning for zero-shot generalization in vision-language models. Advances in Neural Information Processing Systems, 35: 0 14274--14289, 2022
2022
-
[39]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[40]
Just shift it: Test-time prototype shifting for zero-shot generalization with vision-language models
Elaine Sui, Xiaohan Wang, and Serena Yeung-Levy. Just shift it: Test-time prototype shifting for zero-shot generalization with vision-language models. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp.\ 825--835. IEEE, 2025
2025
-
[41]
The role of engram cells in the systems consolidation of memory
Susumu Tonegawa, Mark D Morrissey, and Takashi Kitamura. The role of engram cells in the systems consolidation of memory. Nature Reviews Neuroscience, 19 0 (8): 0 485--498, 2018
2018
-
[42]
Learning robust global representations by penalizing local predictive power
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global representations by penalizing local predictive power. In Advances in Neural Information Processing Systems, volume 32, pp.\ 10506--10518, 2019
2019
-
[43]
Sparse and distributed coding of episodic memory in neurons of the human hippocampus
John T Wixted, Larry R Squire, Yoonhee Jang, Megan H Papesh, Stephen D Goldinger, Joel R Kuhn, Kris A Smith, David M Treiman, and Peter N Steinmetz. Sparse and distributed coding of episodic memory in neurons of the human hippocampus. Proceedings of the National Academy of Sciences, 111 0 (26): 0 9621--9626, 2014
2014
-
[44]
Sun database: Large-scale scene recognition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 3485--3492, 2010
2010
-
[45]
Dynaprompt: Dynamic test-time prompt tuning
Zehao Xiao, Shilin Yan, Jack Hong, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiayi Shen, Qi Wang, and Cees GM Snoek. Dynaprompt: Dynamic test-time prompt tuning. arXiv preprint arXiv:2501.16404, 2025
-
[46]
Robust test-time adaptation in dynamic scenarios
Longhui Yuan, Binhui Xie, and Shuang Li. Robust test-time adaptation in dynamic scenarios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 15922--15932, 2023
2023
-
[47]
Dual prototype evolving for test-time generalization of vision-language models, 2024 a
Ce Zhang, Simon Stepputtis, Katia Sycara, and Yaqi Xie. Dual prototype evolving for test-time generalization of vision-language models, 2024 a . URL https://arxiv.org/abs/2410.12790
-
[48]
Historical test-time prompt tuning for vision foundation models
Jingyi Zhang, Jiaxing Huang, Xiaoqin Zhang, Ling Shao, and Shijian Lu. Historical test-time prompt tuning for vision foundation models. Advances in Neural Information Processing Systems, 37: 0 12872--12896, 2024 b
2024
-
[49]
Tip-adapter: Training-free adaption of clip for few-shot classification
Renrui Zhang, Wei Zhang, Rongyao Fang, Peng Gao, Kunchang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. Tip-adapter: Training-free adaption of clip for few-shot classification. In European conference on computer vision, pp.\ 493--510. Springer, 2022
2022
-
[50]
Dual memory networks: A versatile adaptation approach for vision-language models
Yabin Zhang, Wenjie Zhu, Hui Tang, Zhiyuan Ma, Kaiyang Zhou, and Lei Zhang. Dual memory networks: A versatile adaptation approach for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 28718--28728, 2024 c
2024
-
[51]
Learning to prompt for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. International Journal of Computer Vision, 130 0 (9): 0 2337--2348, 2022
2022
-
[52]
Bayesian test-time adaptation for vision-language models, 2025
Lihua Zhou, Mao Ye, Shuaifeng Li, Nianxin Li, Xiatian Zhu, Lei Deng, Hongbin Liu, and Zhen Lei. Bayesian test-time adaptation for vision-language models, 2025. URL https://arxiv.org/abs/2503.09248
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.