Agent-Assisted Side-Channel Attacks on Non-Prefix KV Cache in RAG
Pith reviewed 2026-06-26 12:17 UTC · model grok-4.3
The pith
Non-prefix KV cache fusion leaks a Step-Wave timing signature that enables token-by-token extraction of private RAG prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
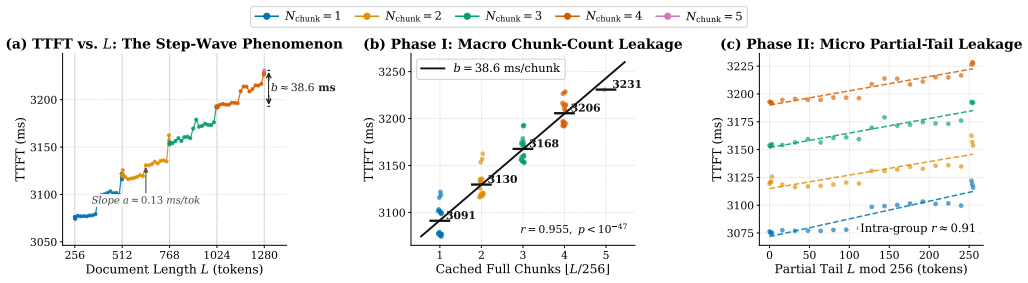
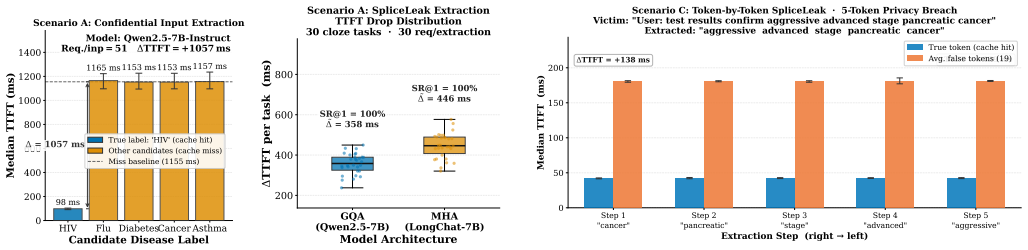
The deterministic micro-architectural mechanisms used to align and fuse disjoint memory chunks inadvertently leak a continuous Step-Wave timing signature. SpliceLeak exploits the signature in a two-phase breach: first structurally fingerprinting the exact length of hidden private prompts, then manipulating boundary collisions to extract exact semantic content token-by-token, reaching up to 100 percent success with as few as 63 requests per token on vLLM plus LMCache under continuous batching.
What carries the argument
The Step-Wave timing signature produced by deterministic chunk alignment and fusion during non-prefix KV cache scheduling.
If this is right
- The attack reaches 100 percent extraction success in bounded-entropy cases.
- It requires only 63 requests per token while surviving realistic continuous batching.
- It applies directly to production frameworks such as vLLM integrated with LMCache.
- SpliceDefense using quantized chunk padding and constant-time boundary fusion removes the timing signal with negligible throughput cost.
Where Pith is reading between the lines
- Similar timing leaks could appear in any inference optimization that relies on deterministic memory chunk placement across tenants.
- Future engines may need to treat memory deduplication as a tunable security parameter rather than a pure performance win.
- The two-phase fingerprint-then-extract pattern may generalize to other cache-sharing surfaces beyond KV stores.
Load-bearing premise
The deterministic micro-architectural mechanisms used to align and fuse disjoint memory chunks inadvertently leak a continuous Step-Wave timing signature that remains observable and exploitable in production environments with continuous batching.
What would settle it
Run the same workload on a modified scheduler that disables or randomizes chunk fusion; if the Step-Wave pattern vanishes while cache sharing still occurs, the causal link between fusion logic and the leak is confirmed.
Figures

read the original abstract
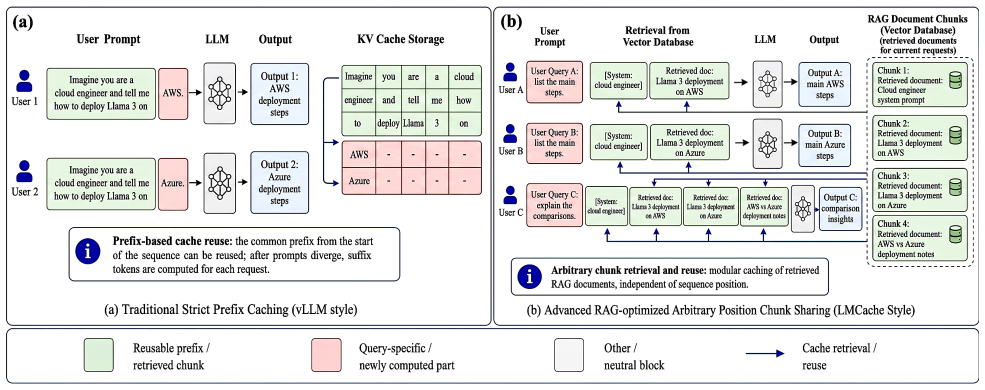
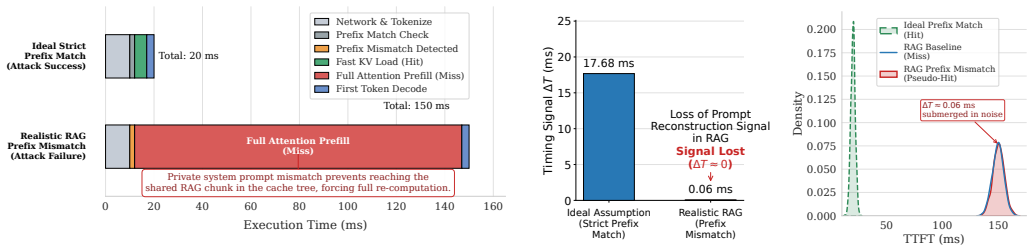
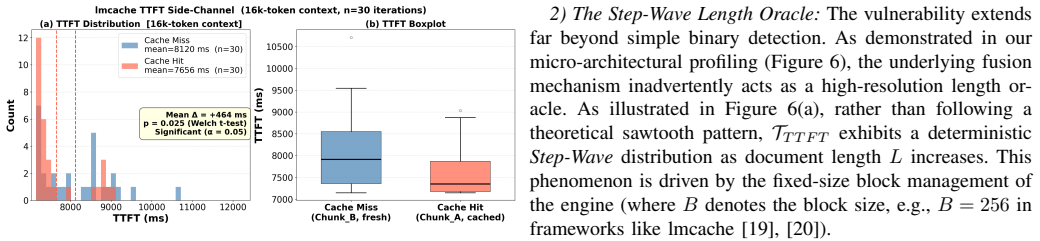
Modern Large Language Model (LLM) serving engines increasingly rely on Retrieval-Augmented Generation (RAG) and non-prefix Key-Value (KV) cache fusion to accelerate long-context, multi-tenant inference. While existing KV cache side-channel attacks require strict linear prefix alignment--rendering them ineffective against real-world RAG queries that contain unique, user-specific private prefixes--we uncover a critical class of structural vulnerabilities inherent to chunk-aware memory scheduling. We demonstrate that the deterministic micro-architectural mechanisms used to align and fuse disjoint memory chunks inadvertently leak a continuous "Step-Wave" timing signature. Exploiting this physical observation, we introduce SpliceLeak, the first end-to-end side-channel attack targeting non-prefix KV cache fusion. SpliceLeak executes a systematic two-phase privacy breach: it first structurally fingerprints the exact length of hidden private prompts, and subsequently manipulates boundary collisions to extract exact semantic content token-by-token. Extensive evaluations on production-grade frameworks (vLLM integrated with LMCache) demonstrate that SpliceLeak achieves up to a 100% extraction success rate in bounded-entropy scenarios. Driven by a deterministic +104 ms hardware latency void, the attack requires as few as 63 requests per token, piercing through realistic continuous batching noise. To resolve the inherent conflict between memory deduplication and security, we propose SpliceDefense, a bipartite mitigation framework consisting of Quantized Chunk Padding (QCP) and Constant-Time Boundary Fusion (CTBF). Our evaluations confirm that SpliceDefense effectively flattens the side-channel signal (Delta TTFT ~ 0) with negligible throughput overhead, preserving the critical benefits of global cache sharing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpliceLeak, the first end-to-end side-channel attack on non-prefix KV cache fusion in RAG systems. It exploits a deterministic 'Step-Wave' timing signature arising from micro-architectural chunk alignment and fusion mechanisms in engines such as vLLM+LMCache. The attack proceeds in two phases—structural fingerprinting of private prompt lengths followed by boundary-collision token extraction—claiming up to 100% success in bounded-entropy settings with as few as 63 requests per token while piercing continuous batching noise. A bipartite mitigation, SpliceDefense (Quantized Chunk Padding and Constant-Time Boundary Fusion), is proposed to flatten the signal (Delta TTFT ~0) with negligible throughput cost.
Significance. If the timing observations and extraction results hold under realistic multi-tenant conditions, the work identifies a previously unaddressed class of structural side channels that bypass the prefix-alignment prerequisite of prior KV-cache attacks. The empirical attack plus concrete mitigation would be relevant to the security of production LLM serving stacks that rely on global cache deduplication for long-context RAG.
major comments (3)
- [Evaluation / Abstract] The central claim that the deterministic +104 ms hardware latency void produces an observable and exploitable continuous Step-Wave signature that survives production-grade continuous batching noise is load-bearing for both the attack feasibility and the 100% extraction / 63-request figures. The manuscript provides no quantitative characterization of observed timing variance, number of concurrent tenants, scheduler jitter, or direct comparison of the 104 ms delta against batch-induced variance distributions in the reported experiments.
- [Evaluation] Success rates (100% extraction, 63 requests/token) are stated without accompanying experimental details such as dataset descriptions, number of trials, error bars, verification methodology for extracted tokens, or the precise bounded-entropy scenario definition. These omissions prevent assessment of whether the results support the cross-scenario claims.
- [Mitigation / Evaluation] The mitigation evaluation asserts Delta TTFT ~0 and negligible throughput overhead, yet no concrete throughput numbers, latency distributions, or comparison against the undefended baseline under the same workload are supplied to substantiate that the defense preserves the benefits of global cache sharing.
minor comments (2)
- [Attack Description] Notation for the Step-Wave signature and boundary-collision phases should be defined more formally (e.g., with timing diagrams or pseudocode) to aid reproducibility.
- [Introduction] Prior KV-cache side-channel literature (prefix-based attacks) is referenced only in passing; a dedicated related-work subsection would clarify the novelty of the non-prefix setting.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight areas where additional quantitative evidence and experimental transparency would strengthen the manuscript. We address each major comment below and commit to incorporating the requested details in the revised version.
read point-by-point responses
-
Referee: [Evaluation / Abstract] The central claim that the deterministic +104 ms hardware latency void produces an observable and exploitable continuous Step-Wave signature that survives production-grade continuous batching noise is load-bearing for both the attack feasibility and the 100% extraction / 63-request figures. The manuscript provides no quantitative characterization of observed timing variance, number of concurrent tenants, scheduler jitter, or direct comparison of the 104 ms delta against batch-induced variance distributions in the reported experiments.
Authors: We agree that the current presentation lacks sufficient quantitative support for the claim that the Step-Wave remains distinguishable under continuous batching. In the revised manuscript we will add a new subsection (likely in Section 5) that reports: (i) measured timing variance (mean, std, and distributions) across repeated trials, (ii) the exact number of concurrent tenants and request rates used in the multi-tenant experiments, (iii) observed scheduler jitter statistics, and (iv) direct statistical comparisons (e.g., CDF plots or hypothesis tests) between the +104 ms hardware delta and the variance attributable to batching. These additions will be drawn from the same vLLM+LMCache testbed already used for the attack results. revision: yes
-
Referee: [Evaluation] Success rates (100% extraction, 63 requests/token) are stated without accompanying experimental details such as dataset descriptions, number of trials, error bars, verification methodology for extracted tokens, or the precise bounded-entropy scenario definition. These omissions prevent assessment of whether the results support the cross-scenario claims.
Authors: The manuscript currently states the headline figures but does not supply the supporting experimental metadata the referee correctly identifies as missing. We will expand Section 5 to include: full descriptions of the datasets and the precise entropy bounds used to define the “bounded-entropy” regime, the total number of independent trials per configuration together with error bars or confidence intervals, the token-verification procedure (exact matching against ground-truth private prompts), and any filtering or success criteria applied. This expanded reporting will allow readers to evaluate the 100 % / 63-request claims under the stated conditions. revision: yes
-
Referee: [Mitigation / Evaluation] The mitigation evaluation asserts Delta TTFT ~0 and negligible throughput overhead, yet no concrete throughput numbers, latency distributions, or comparison against the undefended baseline under the same workload are supplied to substantiate that the defense preserves the benefits of global cache sharing.
Authors: We acknowledge that the mitigation claims rest on qualitative statements rather than the concrete side-by-side metrics requested. In the revision we will add tables and figures that report: measured end-to-end throughput (tokens/s) and TTFT distributions for both the defended and undefended systems under identical workloads, the exact overhead percentages, and latency histograms that demonstrate Delta TTFT remains near zero while cache-sharing benefits are retained. All measurements will reuse the same experimental harness and workload parameters as the attack evaluation. revision: yes
Circularity Check
No circularity: empirical attack demonstration
full rationale
This is an empirical security paper describing an observed side-channel attack (SpliceLeak) and mitigation (SpliceDefense) on KV cache fusion in production LLM serving frameworks. The abstract and described content contain no equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. All claims rest on experimental measurements of timing signatures and extraction rates rather than any self-referential construction. Per the guidelines, such papers receive score 0 with no steps when the result is not forced by definition or citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of large language models,
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Dong,et al., “A survey of large language models,”arXiv preprint arXiv:2303.18223, vol. 1, no. 2, 2023
Pith/arXiv arXiv 2023
-
[2]
A survey on evaluation of large language models,
Y . Chang, X. Wang, J. Wang, Y . Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y . Wang,et al., “A survey on evaluation of large language models,”ACM transactions on intelligent systems and technology, vol. 15, no. 3, pp. 1–45, 2024
2024
-
[3]
A survey of adaptation of large language models to idea and hypothesis generation: Downstream task adaptation, knowledge distillation approaches and challenges,
O. N. Oyelade, H. Wang, and K. Rafferty, “A survey of adaptation of large language models to idea and hypothesis generation: Downstream task adaptation, knowledge distillation approaches and challenges,”ACM Computing Surveys, 2025
2025
-
[4]
{InfiniGen}: Efficient generative inference of large language models with dynamic{KV}cache manage- ment,
W. Lee, J. Lee, J. Seo, and J. Sim, “{InfiniGen}: Efficient generative inference of large language models with dynamic{KV}cache manage- ment,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pp. 155–172, 2024
2024
-
[5]
H. Sun, S. Liu, L. Li, and M. Xiao, “Hillinfer: Efficient long-context llm inference on the edge with hierarchical kv eviction using smartssd,” arXiv preprint arXiv:2602.18750, 2026
arXiv 2026
-
[6]
A. Agrawal, H. Qiu, J. Chen, ´I. Goiri, C. Zhang, R. Shahid, R. Ramjee, A. Tumanov, and E. Choukse, “Medha: Efficiently serving multi-million context length llm inference requests without approximations,”arXiv preprint arXiv:2409.17264, 2024
arXiv 2024
-
[7]
H. Sun, L. Li, M. Xiao, and C. Xu, “Breaking the boundaries of long- context llm inference: Adaptive kv management on a single commodity gpu,”arXiv preprint arXiv:2506.20187, 2025
arXiv 2025
-
[8]
Loongserve: Effi- ciently serving long-context large language models with elastic sequence parallelism,
B. Wu, S. Liu, Y . Zhong, P. Sun, X. Liu, and X. Jin, “Loongserve: Effi- ciently serving long-context large language models with elastic sequence parallelism,” inProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, pp. 640–654, 2024
2024
-
[9]
Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache,
B. Lin, C. Zhang, T. Peng, H. Zhao, W. Xiao, M. Sun, A. Liu, Z. Zhang, L. Li, X. Qiu,et al., “Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache,”arXiv preprint arXiv:2401.02669, 2024
arXiv 2024
-
[10]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin,et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025
2025
-
[11]
A survey of hallucination problems based on large language models,
X. Liu, “A survey of hallucination problems based on large language models,”Applied and Computational Engineering, vol. 97, pp. 24–30, 2024
2024
-
[12]
Retrieval-augmented generation for ai-generated content: A survey,
P. Zhao, H. Zhang, Q. Yu, Z. Wang, Y . Geng, F. Fu, L. Yang, W. Zhang, J. Jiang, and B. Cui, “Retrieval-augmented generation for ai-generated content: A survey,”arXiv preprint arXiv:2402.19473, 2024
Pith/arXiv arXiv 2024
-
[13]
R2ag: Incorporating retrieval information into retrieval augmented generation,
F. Ye, S. Li, Y . Zhang, and L. Chen, “R2ag: Incorporating retrieval information into retrieval augmented generation,” inFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 11584– 11596, 2024
2024
-
[14]
Cache-craft: Managing chunk-caches for efficient retrieval-augmented generation,
S. Agarwal, S. Sundaresan, S. Mitra, D. Mahapatra, A. Gupta, R. Sharma, N. J. Kapu, T. Yu, and S. Saini, “Cache-craft: Managing chunk-caches for efficient retrieval-augmented generation,”Proceedings of the ACM on Management of Data, vol. 3, no. 3, pp. 1–28, 2025
2025
-
[15]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, pp. 611–626, 2023
2023
-
[16]
Sglang: Efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez,et al., “Sglang: Efficient execution of structured language model programs,”Advances in neural information processing systems, vol. 37, pp. 62557–62583, 2024
2024
-
[17]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pp. 193–210, 2024
2024
-
[18]
Mooncake: Trading more storage for less computation—a {KVCache-centric}architecture for serving{LLM}chatbot,
R. Qin, Z. Li, W. He, J. Cui, F. Ren, M. Zhang, Y . Wu, W. Zheng, and X. Xu, “Mooncake: Trading more storage for less computation—a {KVCache-centric}architecture for serving{LLM}chatbot,” in23rd USENIX conference on file and storage technologies (FAST 25), pp. 155– 170, 2025
2025
-
[19]
Lmcache: An efficient kv cache layer for enterprise-scale llm inference,
Y . Liu, Y . Cheng, J. Yao, Y . An, X. Chen, S. Feng, Y . Huang, S. Shen, R. Zhang, K. Du,et al., “Lmcache: An efficient kv cache layer for enterprise-scale llm inference,”arXiv preprint arXiv:2510.09665, 2025
arXiv 2025
-
[20]
Cacheblend: Fast large language model serving for rag with cached knowledge fusion,
J. Yao, H. Li, Y . Liu, S. Ray, Y . Cheng, Q. Zhang, K. Du, S. Lu, and J. Jiang, “Cacheblend: Fast large language model serving for rag with cached knowledge fusion,” inProceedings of the Twentieth European Conference on Computer Systems, pp. 94–109, 2025
2025
-
[21]
Selective kv-cache sharing to mitigate timing side-channels in llm inference,
K. Chu, Z. Lin, D. Xiang, Z. Shen, J. Su, C. Chu, Y . Yang, W. Zhang, W. Wu, and W. Zhang, “Selective kv-cache sharing to mitigate timing side-channels in llm inference,”arXiv preprint arXiv:2508.08438, 2025
arXiv 2025
-
[22]
Cryp- togen: Secure transformer generation with encrypted kv-cache reuse,
H. Zhang, N. Javidnia, S. Pardeshi, Q. Lou, and F. Koushanfar, “Cryp- togen: Secure transformer generation with encrypted kv-cache reuse,” arXiv preprint arXiv:2602.08798, 2026
arXiv 2026
-
[23]
Mpcache: Mpc-friendly kv cache eviction for efficient private llm inference,
W. Zeng, Y . Dong, J. Zhou, J. Tan, L. Wang, T. Wei, R. Wang, and M. Li, “Mpcache: Mpc-friendly kv cache eviction for efficient private llm inference,”arXiv preprint arXiv:2501.06807, 2025
arXiv 2025
-
[24]
Shadow in the cache: Unveiling and mitigating privacy risks of kv- cache in llm inference,
Z. Luo, S. Shao, S. Zhang, L. Zhou, Y . Hu, C. Zhao, Z. Liu, and Z. Qin, “Shadow in the cache: Unveiling and mitigating privacy risks of kv- cache in llm inference,”arXiv preprint arXiv:2508.09442, 2025
arXiv 2025
-
[25]
I know what you asked: Prompt leakage via kv-cache sharing in multi- tenant llm serving.,
G. Wu, Z. Zhang, Y . Zhang, W. Wang, J. Niu, Y . Wu, and Y . Zhang, “I know what you asked: Prompt leakage via kv-cache sharing in multi- tenant llm serving.,” inNDSS, 2025
2025
-
[26]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[27]
Longformer: The long- document transformer,
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long- document transformer,”arXiv preprint arXiv:2004.05150, 2020
Pith/arXiv arXiv 2004
-
[28]
{PoisonedRAG}: Knowledge corruption attacks to{Retrieval-Augmented}generation of large lan- guage models,
W. Zou, R. Geng, B. Wang, and J. Jia, “{PoisonedRAG}: Knowledge corruption attacks to{Retrieval-Augmented}generation of large lan- guage models,” in34th USENIX Security Symposium (USENIX Security 25), pp. 3827–3844, 2025
2025
-
[29]
Flippedrag: Black-box opinion manipulation adversarial attacks to retrieval-augmented generation models,
Z. Chen, Y . Gong, J. Liu, M. Chen, H. Liu, Q. Cheng, F. Zhang, W. Lu, and X. Liu, “Flippedrag: Black-box opinion manipulation adversarial attacks to retrieval-augmented generation models,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pp. 4109–4123, 2025
2025
-
[30]
{Topic-FlipRAG}:{Topic-Orientated}adversarial opinion ma- nipulation attacks to{Retrieval-Augmented}generation models,
Y . Gong, Z. Chen, J. Liu, M. Chen, F. Yu, W. Lu, X. Wang, and X. Liu, “{Topic-FlipRAG}:{Topic-Orientated}adversarial opinion ma- nipulation attacks to{Retrieval-Augmented}generation models,” in34th USENIX Security Symposium (USENIX Security 25), pp. 3807–3826, 2025
2025
-
[31]
Importsnare: Directed’code man- ual’hijacking in retrieval-augmented code generation,
K. Ye, L. Su, and C. Qian, “Importsnare: Directed’code man- ual’hijacking in retrieval-augmented code generation,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pp. 335–349, 2025
2025
-
[32]
Give llms a security course: Securing retrieval-augmented code generation via knowledge injection,
B. Lin, S. Wang, Y . Qin, L. Chen, and X. Mao, “Give llms a security course: Securing retrieval-augmented code generation via knowledge injection,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pp. 3356–3370, 2025
2025
-
[33]
Machine against the {RAG}: Jamming{Retrieval-Augmented}generation with blocker doc- uments,
A. Shafran, R. Schuster, and V . Shmatikov, “Machine against the {RAG}: Jamming{Retrieval-Augmented}generation with blocker doc- uments,” in34th USENIX Security Symposium (USENIX Security 25), pp. 3787–3806, 2025
2025
-
[34]
Rag-wm: An efficient black-box watermarking approach for retrieval-augmented generation of large language models,
P. Lv, M. Sun, H. Wang, X. Wang, S. Zhang, Y . Chen, K. Chen, and L. Sun, “Rag-wm: An efficient black-box watermarking approach for retrieval-augmented generation of large language models,” inPro- ceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pp. 1709–1723, 2025
2025
-
[35]
Hey, you, get off of my cloud: exploring information leakage in third-party compute clouds,
T. Ristenpart, E. Tromer, H. Shacham, and S. Savage, “Hey, you, get off of my cloud: exploring information leakage in third-party compute clouds,” inProceedings of the 16th ACM conference on Computer and communications security, pp. 199–212, 2009
2009
-
[36]
Orca: A distributed serving system for{Transformer-Based}generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for{Transformer-Based}generative models,” in16th USENIX symposium on operating systems design and implemen- tation (OSDI 22), pp. 521–538, 2022
2022
-
[37]
Gpu. zip: On the side-channel implications of hardware-based graphical data compression,
Y . Wang, R. Paccagnella, Z. Gang, W. R. Vasquez, D. Kohlbrenner, H. Shacham, and C. W. Fletcher, “Gpu. zip: On the side-channel implications of hardware-based graphical data compression,” in2024 14 IEEE Symposium on Security and Privacy (SP), pp. 3716–3734, IEEE, 2024
2024
-
[38]
The significance of the difference between two means when the population variances are unequal,
B. L. Welch, “The significance of the difference between two means when the population variances are unequal,”Biometrika, vol. 29, no. 3/4, pp. 350–362, 1938
1938
-
[39]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan,et al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[40]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram,et al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[41]
Gemini 3 pro model reference
Google, “Gemini 3 pro model reference.” https://ai.google.dev/ gemini-api/docs/models#gemini-3-pro, 2025. Accessed: 2026-05-07
2025
-
[42]
Longchat: An open framework for long-context language mod- els
D. Li, “Longchat: An open framework for long-context language mod- els.” https://github.com/DachengLi1/LongChat, 2025
2025
-
[43]
Longchat-7b-v1.5-32k
LMSYS and H. Face, “Longchat-7b-v1.5-32k.” https://huggingface.co/ lmsys/longchat-7b-v1.5-32k, 2025
2025
-
[44]
Qwen2. 5-coder technical report,
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu,et al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[45]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,
X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa, “Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,” inProceedings of the 28th International Conference on Computational Linguistics, pp. 6609–6625, 2020
2020
-
[46]
Musique: Multihop questions via single-hop question composition,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Musique: Multihop questions via single-hop question composition,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 539–554, 2022
2022
-
[47]
Instruction tuning with gpt-4,
B. Peng, C. Li, P. He, M. Galley, and J. Gao, “Instruction tuning with gpt-4,”arXiv preprint arXiv:2304.03277, 2023. APPENDIX A. Discussion and Future Work Impact of Network Jitter.Like other timing channels [25], SpliceLeak’s efficacy relies on theT T T F T Signal-to-Noise Ratio (SNR). While large latency drops (∆≥800ms) easily pierce standard batching n...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.