SN-WER: Script-Normalized WER for Multi-Script Indic ASR Evaluation
Pith reviewed 2026-06-28 14:51 UTC · model grok-4.3
The pith
Transliterating reference and hypothesis to a language-specific canonical script before WER computation produces a script-insensitive evaluation metric for multi-script ASR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
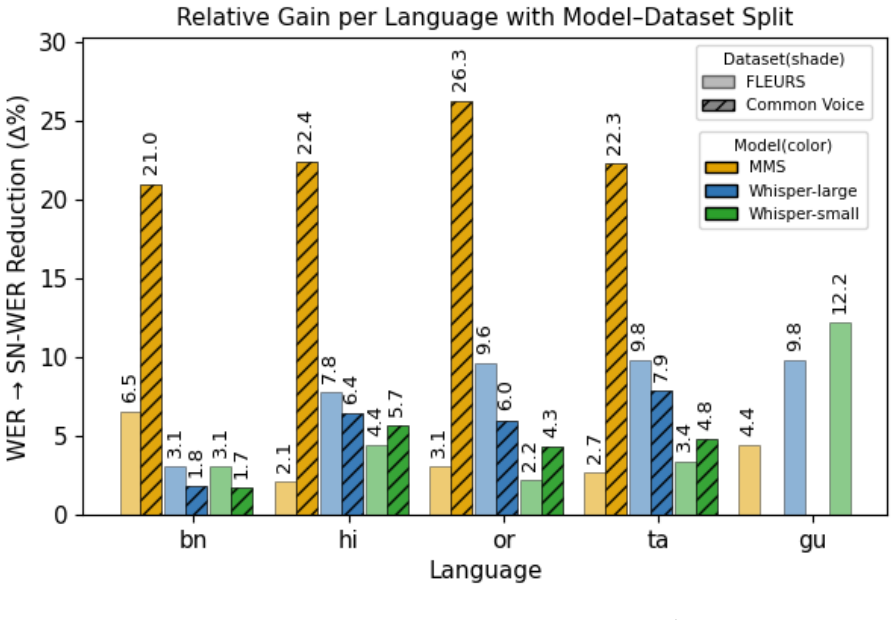
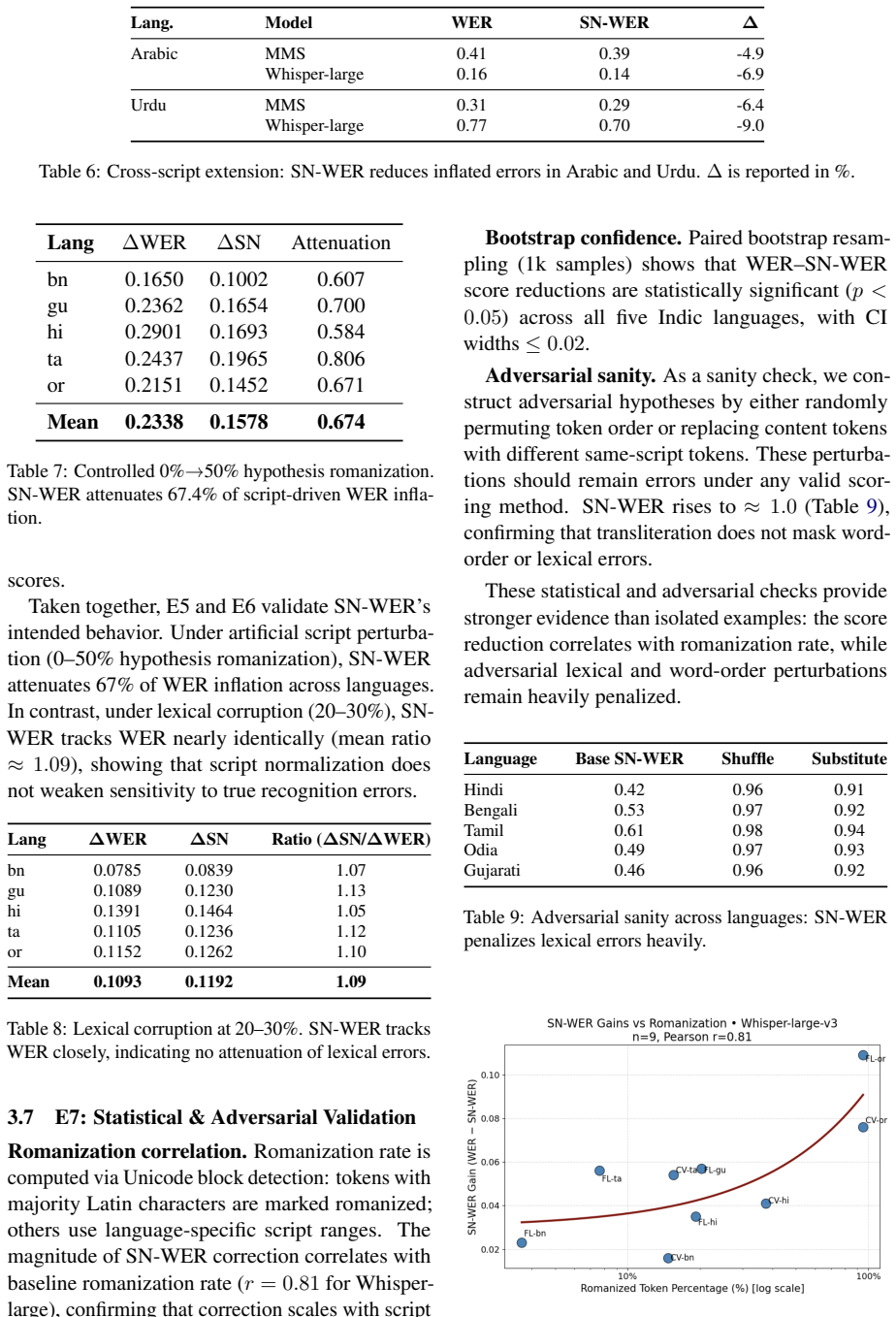
SN-WER is a training-free, evaluation-only method that transliterates both the reference and hypothesis into a language-specific canonical script before computing standard WER. Across five Indic languages, two datasets, and three ASR models, it reduces inflated model gaps by up to 12 percent on curated FLEURS data and shows smaller or inconsistent reductions on noisier Common Voice data, indicating that remaining differences reflect actual recognition weaknesses. Controlled stress tests demonstrate 67 percent attenuation of romanization-induced WER inflation, while lexical-substitution controls yield near-identical sensitivity to semantic errors with a Delta SN-WER over Delta WER ratio of ap
What carries the argument
Script-Normalized WER (SN-WER), which transliterates both reference and hypothesis text to a language-specific canonical script before applying the standard WER calculation.
If this is right
- On curated FLEURS data, SN-WER reduces inflated model gaps by up to 12 percent.
- On noisier Common Voice data, the reductions are smaller or inconsistent, revealing genuine recognition weaknesses rather than script mismatch alone.
- Controlled stress tests show a 67 percent attenuation of artificial romanization-induced WER inflation.
- Lexical-substitution controls produce near-identical sensitivity to semantic errors, with a Delta SN-WER to Delta WER ratio of approximately 1.09.
- SN-WER remains robust to transliterator choice and normalization changes while maintaining token-collision rates below 0.1 percent.
Where Pith is reading between the lines
- The same normalization step could be tested on other language families that exhibit frequent script variation to check whether comparable gap reductions appear.
- Adoption of SN-WER in public benchmarks might encourage ASR developers to add internal script canonicalization as a post-processing step.
- The separation of script errors from phonetic errors suggests that downstream applications such as search or indexing may benefit from always converting ASR output to the canonical script before use.
Load-bearing premise
Transliteration to the canonical script can be performed accurately enough that it introduces neither new token collisions nor semantic distortions that would change the subsequent WER result.
What would settle it
A side-by-side run of SN-WER and ordinary WER on a large collection of ASR outputs already written in the canonical script, where the two metrics produce materially different model rankings, would show that the normalization step itself alters error counts.
Figures
read the original abstract
Word Error Rate (WER) is the dominant metric for automatic speech recognition (ASR), but it can overestimate errors when references and hypotheses encode the same words in different scripts. This issue is common in multilingual settings where ASR models may emit romanized text. We propose Script-Normalized WER (SN-WER), a training-free, evaluation-only scoring method that transliterates both reference and hypothesis text into a language-specific canonical script before computing WER. We evaluate SN-WER on 5 Indic languages, 2 datasets, and 3 ASR models. On curated FLEURS data, SN-WER reduces inflated model gaps by up to 12%, while on noisier Common Voice data the reductions are smaller or inconsistent, indicating genuine recognition weaknesses rather than only script mismatch. Controlled stress tests show a 67% attenuation of artificial romanization-induced WER inflation, while lexical-substitution controls show near-identical sensitivity to semantic errors, with Delta SN-WER / Delta WER approximately 1.09. SN-WER is robust to transliterator choice, normalization changes, and shows low token-collision rates below 0.1% in the evaluated Indic setting. We argue that SN-WER should be reported alongside WER and CER as a companion metric for script-insensitive ASR evaluation, especially when transcripts feed downstream search, indexing, or multilingual LLM pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Script-Normalized WER (SN-WER), a training-free metric that transliterates both ASR reference and hypothesis text to a language-specific canonical script before applying standard WER. It evaluates the approach on 5 Indic languages using the FLEURS and Common Voice datasets and 3 ASR models. Key results include up to 12% reduction in inflated model gaps on curated FLEURS data (smaller or inconsistent on noisier Common Voice), 67% attenuation of artificial romanization-induced WER inflation in controlled stress tests, and near-identical sensitivity to semantic errors versus standard WER (ΔSN-WER/ΔWER ≈ 1.09). The method reports robustness to transliterator choice and token-collision rates below 0.1%. The authors recommend reporting SN-WER alongside WER and CER for script-insensitive evaluation.
Significance. If the quantitative results and controls hold, SN-WER provides a practical, parameter-free companion metric that mitigates script-mismatch artifacts in Indic ASR evaluation without requiring model retraining. The controlled romanization and lexical-substitution experiments supply direct internal evidence that the metric attenuates artificial inflation while preserving sensitivity to genuine errors. These features, combined with the low reported collision rates, make the proposal relevant for evaluation pipelines that feed search, indexing, or multilingual downstream systems.
major comments (2)
- [Results section (FLEURS vs. Common Voice comparison)] Results section (FLEURS vs. Common Voice comparison): the claim that smaller reductions on Common Voice indicate 'genuine recognition weaknesses rather than only script mismatch' is load-bearing for the central argument, yet no per-language breakdown, error-type analysis, or statistical significance on the gap reductions is provided to support the distinction.
- [Stress-test description] Stress-test description: the 67% attenuation result for romanization-induced inflation is central to validating the transliteration assumption, but the exact procedure (number of samples, specific romanization method, and how hypotheses were generated) lacks sufficient detail to assess coverage of realistic model outputs or enable replication.
minor comments (3)
- [Abstract] Abstract: the ratio 'Delta SN-WER / Delta WER approximately 1.09' should specify whether it is an average, median, or per-language value and over which subset of substitutions.
- Consider adding an explicit table or figure that reports WER, CER, and SN-WER side-by-side for all models, languages, and datasets to improve readability of the quantitative claims.
- The robustness checks to transliterator choice and normalization changes are mentioned but would benefit from a short dedicated subsection or appendix listing the specific tools and parameter settings used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation of minor revision. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Results section (FLEURS vs. Common Voice comparison): the claim that smaller reductions on Common Voice indicate 'genuine recognition weaknesses rather than only script mismatch' is load-bearing for the central argument, yet no per-language breakdown, error-type analysis, or statistical significance on the gap reductions is provided to support the distinction.
Authors: We agree that the supporting evidence for this distinction can be strengthened. In the revised manuscript we will add per-language tables showing WER and SN-WER reductions on both FLEURS and Common Voice, include a brief error-type breakdown (e.g., script-mismatch vs. lexical vs. other), and report statistical significance (paired t-tests or bootstrap) on the difference in gap reductions between the two datasets. revision: yes
-
Referee: Stress-test description: the 67% attenuation result for romanization-induced inflation is central to validating the transliteration assumption, but the exact procedure (number of samples, specific romanization method, and how hypotheses were generated) lacks sufficient detail to assess coverage of realistic model outputs or enable replication.
Authors: We will expand the stress-test subsection to specify the exact number of samples, the romanization method and library used, and the procedure for generating the romanized hypotheses. These details will be added to the revised manuscript to improve replicability. revision: yes
Circularity Check
No significant circularity; metric is a direct definition
full rationale
The paper defines SN-WER explicitly as standard WER applied after an external transliteration step to a canonical script. No equations, fitted parameters, or self-referential reductions exist. The central claim rests on empirical evaluations and controls (token-collision rates, romanization stress tests, lexical-substitution sensitivity) that are independent of the definition itself. No load-bearing self-citations or imported uniqueness theorems are present. This is a self-contained definition with no derivation chain that collapses to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transliteration to a language-specific canonical script preserves lexical identity without introducing meaningful token collisions or semantic changes
Reference graph
Works this paper leans on
-
[1]
Interspeech , year=
From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition , author=. Interspeech , year=
-
[2]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[3]
FLEURS: FEW-Shot Learning Evaluation of Universal Representations of Speech , year=
Conneau, Alexis and Ma, Min and Khanuja, Simran and Zhang, Yu and Axelrod, Vera and Dalmia, Siddharth and Riesa, Jason and Rivera, Clara and Bapna, Ankur , booktitle=. FLEURS: FEW-Shot Learning Evaluation of Universal Representations of Speech , year=
-
[4]
Common Voice: A Massively-Multilingual Speech Corpus
Ardila, Rosana and Branson, Megan and Davis, Kelly and Kohler, Michael and Meyer, Josh and Henretty, Michael and Morais, Reuben and Saunders, Lindsay and Tyers, Francis and Weber, Gregor. Common Voice: A Massively-Multilingual Speech Corpus. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[5]
Transliteration Based Approaches to Improve Code-Switched Speech Recognition Performance , year=
Emond, Jesse and Ramabhadran, Bhuvana and Roark, Brian and Moreno, Pedro and Ma, Min , booktitle=. Transliteration Based Approaches to Improve Code-Switched Speech Recognition Performance , year=
-
[6]
2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , year=
WERD: Using social text spelling variants for evaluating dialectal speech recognition , author=. 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , year=
2017
-
[7]
Karita, Shigeki and Sproat, Richard and Ishikawa, Haruko. Lenient Evaluation of J apanese Speech Recognition: Modeling Naturally Occurring Spelling Inconsistency. Proceedings of the Workshop on Computation and Written Language (CAWL 2023). 2023. doi:10.18653/v1/2023.cawl-1.8
-
[8]
What is lost in Normalization? Exploring Pitfalls in Multilingual ASR Model Evaluations
Manohar, Kavya and Pillai, Leena G. What is lost in Normalization? Exploring Pitfalls in Multilingual ASR Model Evaluations. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.607
-
[9]
Advocating Character Error Rate for Multilingual ASR Evaluation
K, Thennal D and James, Jesin and Gopinath, Deepa Padmini and K, Muhammed Ashraf. Advocating Character Error Rate for Multilingual ASR Evaluation. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.277
-
[10]
Sunipa Dev, Masoud Monajatipoor, Anaelia Ovalle, Arjun Subramonian, Jeff Phillips, and Kai-Wei Chang
Blodgett, Su Lin and Barocas, Solon and Daum \'e III, Hal and Wallach, Hanna. Language (Technology) is Power: A Critical Survey of ``Bias'' in NLP. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.485
-
[11]
WER We Stand: Benchmarking U rdu ASR Models
Arif, Samee and Khan, Aamina Jamal and Abbas, Mustafa and Raza, Agha Ali and Athar, Awais. WER We Stand: Benchmarking U rdu ASR Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[12]
Multi-reference WER for evaluating ASR for languages with no orthographic rules , year=
Ali, Ahmed and Magdy, Walid and Bell, Peter and Renais, Steve , booktitle=. Multi-reference WER for evaluating ASR for languages with no orthographic rules , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.