Scenes as Objects, Not Primitives: Instance-Structured 3D Tokenization from Unposed Views
Pith reviewed 2026-06-30 07:22 UTC · model grok-4.3
The pith
A feed-forward model decomposes unposed multi-view images into instance-structured 3D token groups that support native object editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
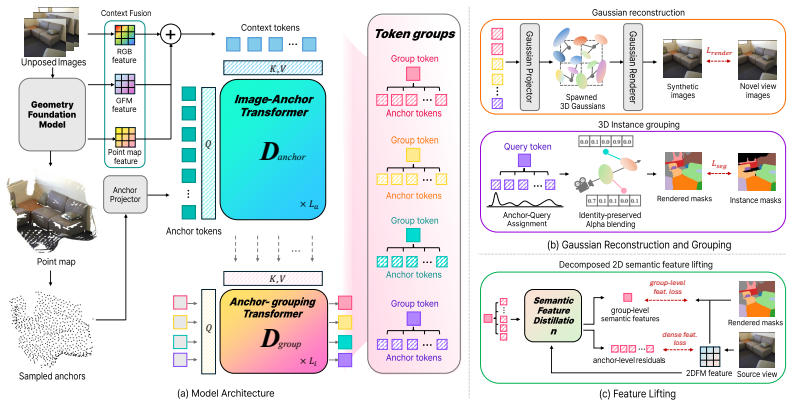
The central claim is that a feed-forward network can factor a scene into instance-structured 3D token groups directly from unposed multi-view images, where each group pairs an instance token that captures entity-level identity with anchor tokens that encode local geometry and appearance; the groups are decoded to 3D Gaussians and trained end-to-end with joint reconstruction and segmentation supervision from 2D images alone, so that object instances become a native interface of the representation rather than a derived product.
What carries the argument
Two-level token group factorization that separates instance identity from local appearance and is decoded to Gaussians via differentiable rendering.
If this is right
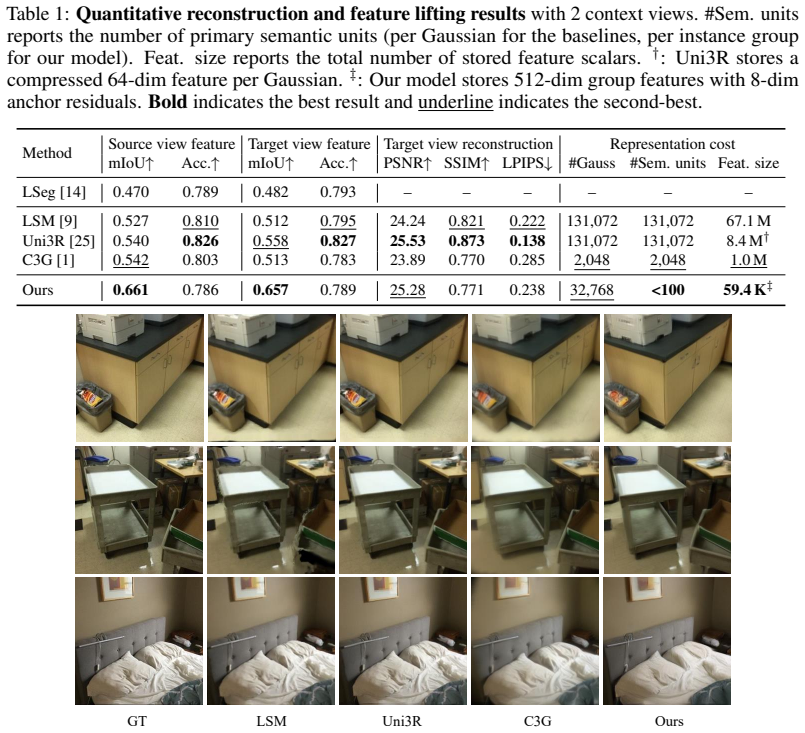
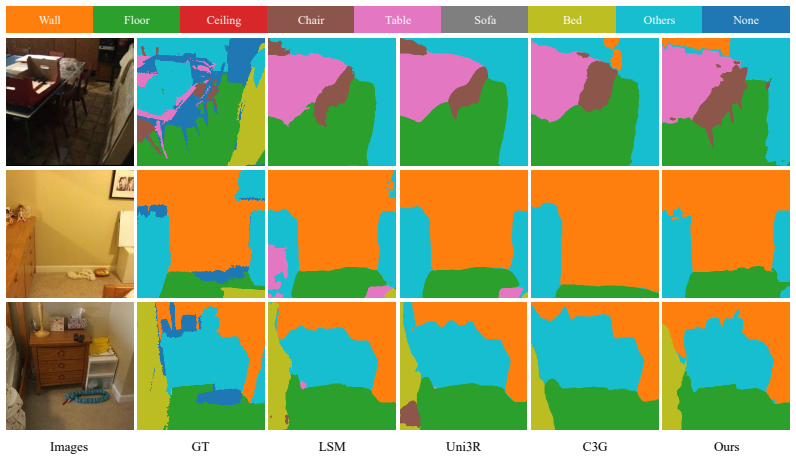
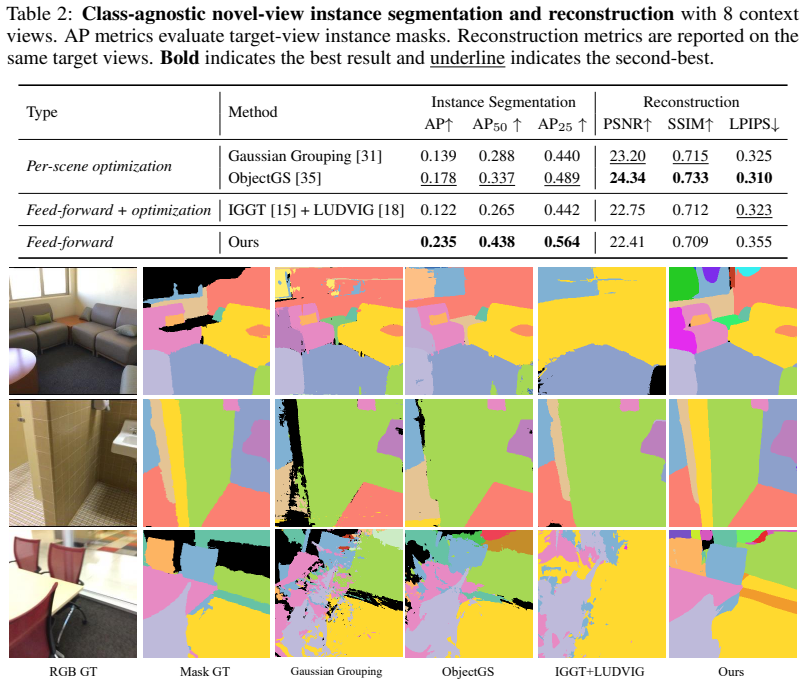
- The model produces better class-agnostic instance segmentation than per-scene optimization baselines.
- Novel-view synthesis quality remains competitive with those baselines.
- Instance-level editing operations such as removal, translation, or insertion become direct manipulations of the token groups.
- Open-vocabulary 3D instance retrieval scales with the number of instances rather than the number of primitives.
Where Pith is reading between the lines
- The same token groups could serve as input features for downstream tasks such as 3D object tracking across video frames without new supervision.
- Because identity is factored from appearance, the representation might extend to scenes with changing lighting or materials while preserving object identity.
- Retrieval efficiency gains suggest the method could scale to large scene databases where querying by object rather than by dense geometry becomes practical.
Load-bearing premise
Joint 2D reconstruction and segmentation losses alone are enough to make the learned token groups separate object identities from local appearance without any 3D annotations or explicit instance labels.
What would settle it
Run the model on a set of scenes containing multiple objects with nearly identical local appearance; if the token groups merge those objects into one group despite the segmentation loss, the decoupling claim fails.
Figures


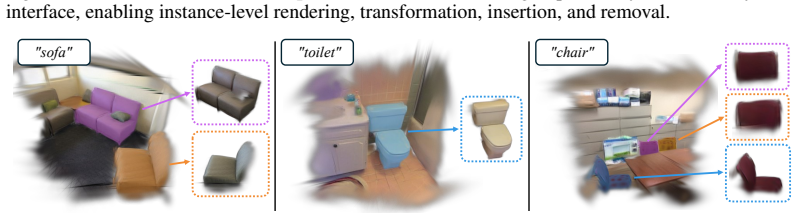
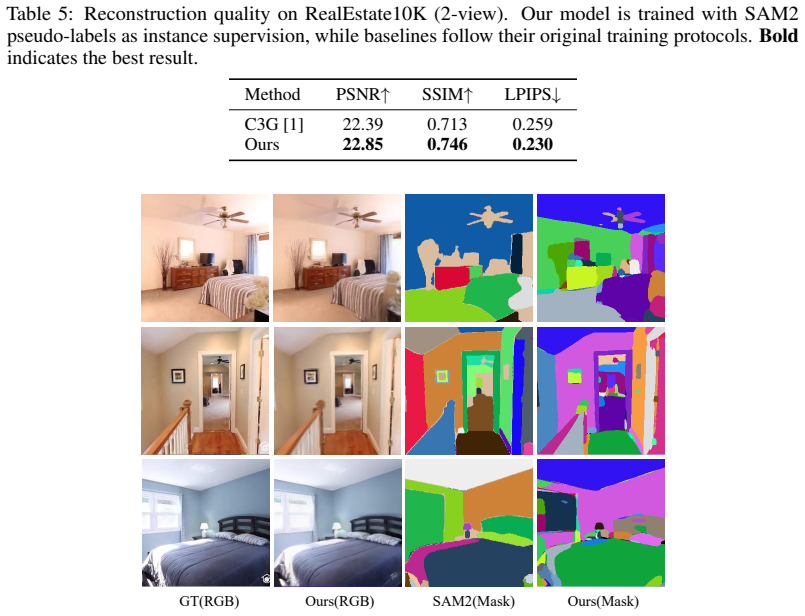



read the original abstract
A 3D scene is understood through its objects, not the primitives that compose them. Yet feed-forward reconstruction methods output dense, unstructured sets of points or Gaussians, leaving object-level structure to be recovered after the fact. We propose a feed-forward framework that decomposes a scene into instance-structured 3D token groups directly from unposed multi-view images -- compact object-centric units from which reconstruction, segmentation, and manipulation all follow. Each token group pairs an instance token capturing entity-level identity with anchor tokens that encode local geometry and appearance, which are decoded into a set of 3D Gaussians. This two-level factorization decouples object identity from local appearance, making object instances a native interface of the representation rather than a derived product. The token groups are learned through differentiable rendering with joint reconstruction and segmentation supervision, requiring no 3D annotations. Our feed-forward model surpasses per-scene optimization baselines in class-agnostic instance segmentation while remaining competitive in novel view synthesis. Beyond these metrics, the same token groups directly unlock instance-level scene editing -- removing, translating, or inserting objects by operating on their groups -- as well as efficient open-vocabulary 3D instance retrieval, where retrieval complexity scales with the number of instances rather than primitives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a feed-forward framework that decomposes unposed multi-view images into instance-structured 3D token groups, where each group pairs an instance token (entity-level identity) with anchor tokens (local geometry/appearance) decoded to 3D Gaussians. The groups are learned end-to-end via differentiable rendering using only joint 2D reconstruction and segmentation losses with no 3D annotations or explicit instance supervision. The model is asserted to surpass per-scene optimization baselines on class-agnostic instance segmentation, remain competitive on novel view synthesis, and directly enable instance-level editing and open-vocabulary 3D retrieval.
Significance. If the token groups achieve reliable 3D entity-level decoupling, the work would provide a native object-centric interface for 3D scenes that unifies reconstruction, segmentation, and manipulation without post-hoc processing, representing a meaningful shift from unstructured primitive outputs.
major comments (2)
- [Method section (tokenization and training objective)] The central decoupling claim—that joint 2D reconstruction and segmentation losses alone force instance tokens to capture entity-level 3D identity rather than view-dependent or appearance-based groupings—is load-bearing for all downstream claims (editing, retrieval, and 3D segmentation). No multi-view consistency term, 3D supervision, or loss-landscape analysis is described to show why the optimization would favor identity-based partitions over alternatives that are consistent only on training views.
- [Experiments section (quantitative results and ablations)] The abstract asserts superiority on class-agnostic instance segmentation and competitiveness on novel view synthesis, yet provides no quantitative metrics, baseline names, ablation results on the supervision signals, or evaluation protocol for segmentation without 3D ground truth. This absence prevents verification that the reported performance supports true 3D instance structure rather than view-specific artifacts.
minor comments (1)
- [Method section] Notation for 'instance token' and 'anchor tokens' is introduced without an explicit diagram or equation showing how they are combined before Gaussian decoding, which would improve clarity of the two-level factorization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on the method and commitments to strengthen the experimental reporting.
read point-by-point responses
-
Referee: [Method section (tokenization and training objective)] The central decoupling claim—that joint 2D reconstruction and segmentation losses alone force instance tokens to capture entity-level 3D identity rather than view-dependent or appearance-based groupings—is load-bearing for all downstream claims (editing, retrieval, and 3D segmentation). No multi-view consistency term, 3D supervision, or loss-landscape analysis is described to show why the optimization would favor identity-based partitions over alternatives that are consistent only on training views.
Authors: The instance token is shared across all unposed views and decoded to 3D Gaussians rendered differentiably from each viewpoint. Because the same token must produce consistent segmentation masks and reconstructions when rendered from different angles, view-dependent or appearance-only groupings incur higher joint loss; this implicit pressure from multi-view rendering favors entity-level identity without an extra explicit consistency term. We will revise the method section to articulate this mechanism more explicitly and include a targeted ablation isolating the contribution of multi-view inputs versus single-view training. revision: partial
-
Referee: [Experiments section (quantitative results and ablations)] The abstract asserts superiority on class-agnostic instance segmentation and competitiveness on novel view synthesis, yet provides no quantitative metrics, baseline names, ablation results on the supervision signals, or evaluation protocol for segmentation without 3D ground truth. This absence prevents verification that the reported performance supports true 3D instance structure rather than view-specific artifacts.
Authors: The referee correctly notes that the current manuscript version does not include the requested quantitative metrics, baseline names, loss ablations, or explicit evaluation protocol. We will add a dedicated experiments subsection reporting 2D mask AP and mIoU on held-out views, comparisons against named per-scene baselines, ablations removing the segmentation loss, and a protocol that measures cross-view mask consistency without 3D ground truth. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a feed-forward neural model trained via differentiable rendering with joint 2D reconstruction and segmentation losses. No equations, parameter fits, or self-citations appear in the provided text that reduce any claimed output (segmentation performance, editing capability) to the inputs by construction. The two-level token factorization is presented as an architectural choice whose empirical behavior is measured against external baselines; no self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation is exhibited. The central claims remain empirical and falsifiable outside the training objective.
Axiom & Free-Parameter Ledger
invented entities (2)
-
instance token
no independent evidence
-
anchor tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
C3G: Learning compact 3D representations with 2K gaussians
Honggyu An, Jaewoo Jung, Mungyeom Kim, Sunghwan Hong, Chaehyun Kim, Kazumi Fukuda, Minkyeong Jeon, Jisang Han, Takuya Narihira, Hyuna Ko, Junsu Kim, Yuki Mitsufuji, and Seungry- ong Kim. C3G: Learning compact 3D representations with 2K gaussians. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[2]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-NeRF 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[3]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InProceedings of the European Conference on Computer Vision (ECCV), 2020
2020
-
[4]
Lifting by gaussians: A simple, fast and flexible method for 3D instance segmentation
Rohan Chacko, Nicolai Häni, Eldar Khaliullin, Lin Sun, and Douglas Lee. Lifting by gaussians: A simple, fast and flexible method for 3D instance segmentation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
2025
-
[5]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19457–19467, 2024
2024
-
[6]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In Proceedings of the European Conference on Computer Vision (ECCV), pages 370–386. Springer, 2024
2024
-
[7]
Schwing, Alexander Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked- attention mask transformer for universal image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[8]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[9]
Large spatial model: End-to-end unposed images to semantic 3d
Zhiwen Fan, Jian Zhang, Wenyan Cong, Peihao Wang, Renjie Li, Kairun Wen, Shijie Zhou, Achuta Kadambi, Zhangyang Wang, Danfei Xu, et al. Large spatial model: End-to-end unposed images to semantic 3d. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[10]
Scene-Agnostic Object-Centric Representation Learning for 3D Gaussian Splatting
Tsuheng Hsu, Guiyu Liu, Juho Kannala, and Janne Heikkilä. Scene-agnostic object-centric representation learning for 3D gaussian splatting.arXiv preprint arXiv:2604.09045, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
2025
-
[12]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[13]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. In Proceedings of the European Conference on Computer Vision (ECCV), pages 71–91. Springer, 2024
2024
-
[14]
Language-driven semantic segmentation
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and René Ranftl. Language-driven semantic segmentation. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[15]
IGGT: Instance-grounded geometry transformer for semantic 3D reconstruction
Hao Li, Zhengyu Zou, Fangfu Liu, Xuanyang Zhang, Fangzhou Hong, Yukang Cao, Yushi Lan, Manyuan Zhang, Gang Yu, Dingwen Zhang, and Ziwei Liu. IGGT: Instance-grounded geometry transformer for semantic 3D reconstruction. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[16]
SlotLifter: Slot-guided feature lifting for learning object-centric radiance fields
Yu Liu, Baoxiong Jia, Yixin Chen, and Siyuan Huang. SlotLifter: Slot-guided feature lifting for learning object-centric radiance fields. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[17]
Object-centric learning with slot attention
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-centric learning with slot attention. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[18]
LUDVIG: Learning- free uplifting of 2D visual features to gaussian splatting scenes
Juliette Marrie, Romain Ménégaux, Michael Arbel, Diane Larlus, and Julien Mairal. LUDVIG: Learning- free uplifting of 2D visual features to gaussian splatting scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 11
2025
-
[19]
V-net: Fully convolutional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. InProceedings of the F ourth International Conference on 3D Vision (3DV), pages 565–571. IEEE, 2016
2016
-
[20]
Any3DIS: Class-agnostic 3D instance segmentation by 2D mask tracking
Phuc Nguyen, Minh Luu, Anh Tran, Cuong Pham, and Khoi Nguyen. Any3DIS: Class-agnostic 3D instance segmentation by 2D mask tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[21]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. SAM 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Schönberger and Jan-Michael Frahm
Johannes L. Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[23]
Trace3D: Consis- tent segmentation lifting via gaussian instance tracing
Hongyu Shen, Junfeng Ni, Yixin Chen, Weishuo Li, Mingtao Pei, and Siyuan Huang. Trace3D: Consis- tent segmentation lifting via gaussian instance tracing. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[24]
Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3R: Zero-shot gaussian splatting from uncalibrated image pairs.arXiv preprint arXiv:2408.13912, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Uni3R: Unified 3D reconstruction and semantic understanding via generalizable gaussian splatting from unposed multi-view images
Xiangyu Sun, Haoyi Jiang, Liu Liu, Seungtae Nam, Gyeongjin Kang, Xinjie Wang, Wei Sui, Zhizhong Su, Wenyu Liu, Xinggang Wang, and Eunbyung Park. Uni3R: Unified 3D reconstruction and semantic understanding via generalizable gaussian splatting from unposed multi-view images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition...
2026
-
[26]
Sumner, Marc Pollefeys, Federico Tombari, and Francis Engelmann
Ayça Takmaz, Elisabetta Fedele, Robert W. Sumner, Marc Pollefeys, Federico Tombari, and Francis Engelmann. OpenMask3D: Open-vocabulary 3D instance segmentation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[27]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025
2025
-
[28]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20697–20709, 2024
2024
-
[29]
SAM3D: Segment anything in 3D scenes.arXiv preprint arXiv:2306.03908, 2023
Yunhan Yang, Xiaoyang Wu, Tong He, Hengshuang Zhao, and Xihui Liu. SAM3D: Segment anything in 3D scenes.arXiv preprint arXiv:2306.03908, 2023
-
[30]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng. No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[31]
Gaussian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3d scenes. InProceedings of the European Conference on Computer Vision (ECCV), pages 162–179. Springer, 2024
2024
-
[32]
gsplat: An open-source library for gaussian splatting
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, and Angjoo Kanazawa. gsplat: An open-source library for gaussian splatting. Journal of Machine Learning Research, 26(34):1–17, 2025
2025
-
[33]
kMaX-DeepLab: k-means mask transformer
Qihang Yu, Huiyu Wang, Siyuan Qiao, Maxwell Collins, Yukun Zhu, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. kMaX-DeepLab: k-means mask transformer. InProceedings of the European Conference on Computer Vision (ECCV), 2022
2022
-
[34]
Stereo magnification: Learning view synthesis using multiplane images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images. InACM Transactions on Graphics (SIGGRAPH), 2018
2018
-
[35]
ObjectGS: Object-aware scene reconstruction and scene understanding via gaussian splatting
Ruijie Zhu, Mulin Yu, Linning Xu, Lihan Jiang, Yixuan Li, Tianzhu Zhang, Jiangmiao Pang, and Bo Dai. ObjectGS: Object-aware scene reconstruction and scene understanding via gaussian splatting. InProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[36]
PanSt3R: Multi-view consistent panoptic segmentation
Lojze Zust, Yohann Cabon, Juliette Marrie, Leonid Antsfeld, Boris Chidlovskii, Jerome Revaud, and Gabriela Csurka. PanSt3R: Multi-view consistent panoptic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 12 A Societal impacts Instance-structured 3D representations benefit robotics, AR/VR, and content cr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.