PathRelax: Parallel-Path Relaxed Speculative Jacobi Decoding for Accelerating Auto-Regressive Text-to-Image Generation
Pith reviewed 2026-06-27 13:58 UTC · model grok-4.3
The pith
Parallel-path draft trees and cross-sequence relaxed verification accelerate autoregressive text-to-image generation by roughly four times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
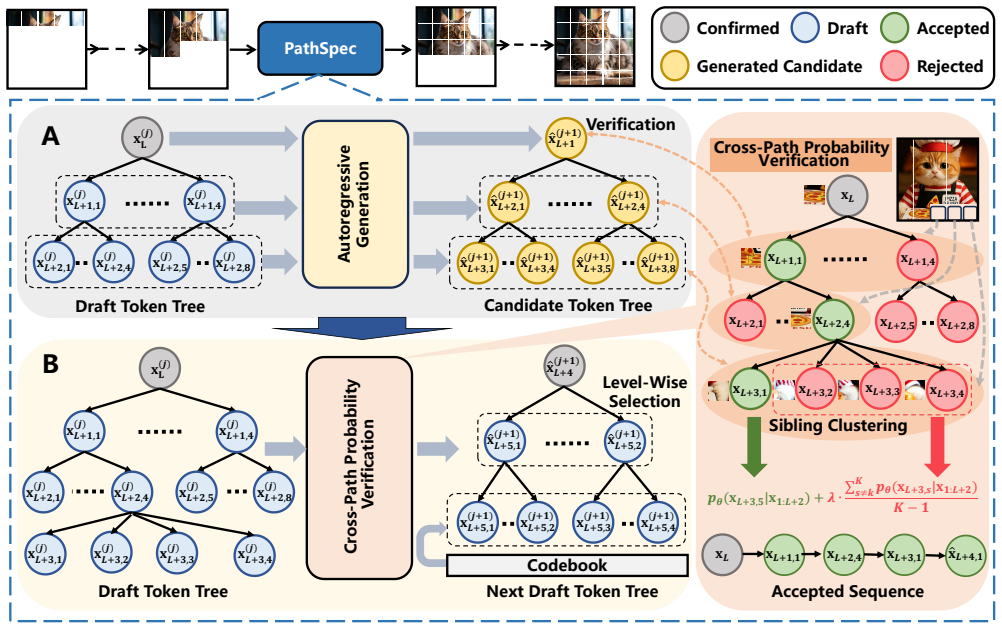
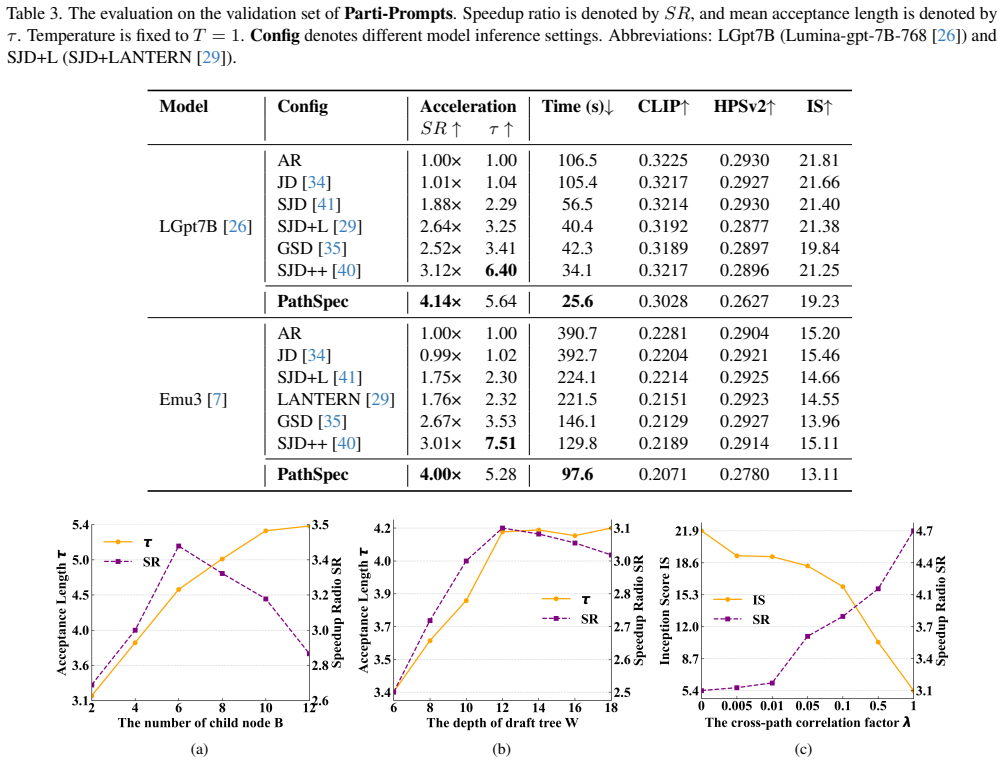
PathSpec replaces chain-structured drafts in speculative Jacobi decoding with a parallel-path tree (PathExplore) that expands the candidate space and cross-path relaxed verification (PathRelax) that accepts tokens across sequences when semantic similarity holds, producing the measured speedups on the three benchmarks without reported quality loss.
What carries the argument
PathSpec framework built from PathExplore's multi-sequence draft tree that widens token search and PathRelax's cross-path relaxed verification that exploits semantic similarities to raise acceptance rates.
If this is right
- Multi-sequence trees raise token acceptance length per step compared with single-chain drafts.
- PathExplore without relaxation already exceeds the speedup of some prior relaxed methods such as GSD and LANTERN.
- PathRelax combines with existing relaxation techniques to produce additive further gains.
- The resulting acceleration supports real-time text-to-image generation on the evaluated datasets.
Where Pith is reading between the lines
- The same parallel-tree plus cross-verification pattern could be tested on autoregressive models for video or audio to check whether semantic similarity across paths transfers.
- If the acceptance-rate benefit scales with sequence length, the method would become increasingly valuable for higher-resolution images that require even longer token strings.
- Hardware implementations that execute the parallel drafts concurrently might multiply the reported software speedups.
Load-bearing premise
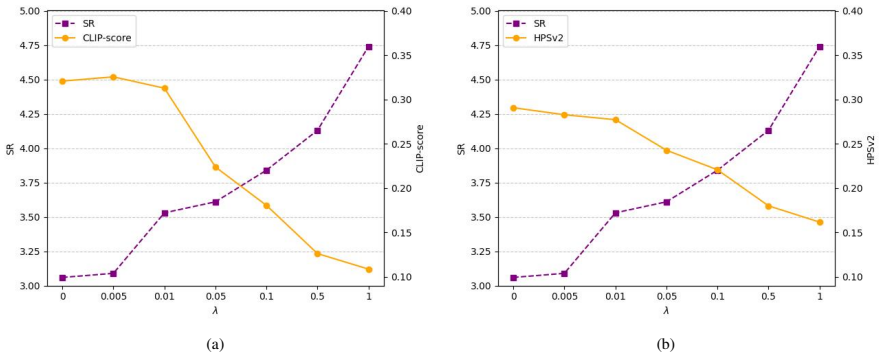
Semantic similarities across parallel draft sequences can be exploited via cross-path relaxed verification to increase token acceptance rates without degrading final image quality.
What would settle it
Running PathRelax on the Parti-Prompts dataset and measuring both wall-clock speedup and image quality metrics such as FID against the autoregressive baseline; the claim fails if speedup drops below 3x or quality metrics degrade measurably.
Figures



read the original abstract
The growing need for high-resolution image generation in autoregressive text-to-image models has resulted in extended token sequences, significantly increasing computational costs and inference times. However, existing state-of-the-art methods for accelerating autoregressive text-to-image models rely on chain-structured draft token sequences, leading to inefficient draft token search and limited acceptance lengths. To address this, we propose parallel-path cross-relaxed speculative Jacobi decoding (\textbf{PathSpec}), a novel framework that enhances efficiency through a multi-sequence draft tree structure. Our parallel-path speculative Jacobi decoding (\textbf{PathExplore}) expands the token search space, achieving a higher speedup ratio without sacrificing image quality. Additionally, we introduce cross-path relaxed verification (\textbf{PathRelax}) that exploits semantic similarities across sequences to further boost token acceptance rates. Evaluated on the Parti-Prompts, MSCOCO2017, and T2ICompBench datasets, our method achieves a speedup ratio of 4.14 $\times$, 3.95$\times$, and 4.18$\times$, respectively. Remarkably, PathExplore, without any relaxed sampling, outperforms relaxed sampling methods in the speedup ratio, such as GSD and LANTERN. Moreover, PathRelax's relaxation mechanism can be seamlessly integrated with other relaxation techniques, enabling further acceleration and providing an efficient solution for real-time text-to-image generation. Our code is available at https://github.com/Haodong-Lei-Ray/PathSpec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PathSpec, a framework for accelerating autoregressive text-to-image generation via parallel-path speculative Jacobi decoding. It consists of PathExplore, which uses a multi-sequence draft tree to expand the token search space, and PathRelax, which applies cross-path relaxed verification by exploiting semantic similarities across draft sequences to increase acceptance rates. The method is claimed to achieve speedups of 4.14× on Parti-Prompts, 3.95× on MSCOCO2017, and 4.18× on T2ICompBench without sacrificing image quality, with PathExplore outperforming prior relaxed methods such as GSD and LANTERN; PathRelax is also presented as integrable with other relaxation techniques. Code is released at a GitHub repository.
Significance. If the empirical claims hold with rigorous validation, the work could meaningfully advance real-time high-resolution text-to-image generation by demonstrating that parallel draft paths combined with cross-sequence relaxation can deliver substantial speedups while preserving output quality. The open-source code is a positive factor for reproducibility and extension.
major comments (2)
- [Abstract / Experimental claims] The central claim that PathRelax preserves image quality (i.e., does not induce distribution shift in accepted tokens) is load-bearing for the reported 4× speedups, yet the abstract supplies no quantitative fidelity metrics (FID, CLIP score, human preference) or error bars on any of the three datasets, nor any ablation isolating the effect of the cross-path relaxation.
- [Method (PathRelax description)] No formal definition or analysis is given for the relaxed verification criterion in PathRelax (how semantic similarity is quantified and thresholded across paths) or proof that it leaves the marginal distribution of generated tokens unchanged relative to strict Jacobi matching; this is required to substantiate the 'without sacrificing image quality' assertion.
minor comments (1)
- [Abstract] The abstract states that PathExplore 'without any relaxed sampling' outperforms relaxed methods, but does not define what 'relaxed sampling' refers to in this context or how it differs from the PathRelax mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, clarifying the experimental evidence and methodological details while committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Experimental claims] The central claim that PathRelax preserves image quality (i.e., does not induce distribution shift in accepted tokens) is load-bearing for the reported 4× speedups, yet the abstract supplies no quantitative fidelity metrics (FID, CLIP score, human preference) or error bars on any of the three datasets, nor any ablation isolating the effect of the cross-path relaxation.
Authors: We agree the abstract would benefit from explicit metrics. The full manuscript (Section 4.3, Tables 2-3, and Figure 5) reports FID, CLIP scores, and human preference results with error bars across all three datasets, confirming no statistically significant quality degradation relative to the baseline. We will revise the abstract to include these quantitative results and add a dedicated ablation isolating the cross-path relaxation contribution. revision: yes
-
Referee: [Method (PathRelax description)] No formal definition or analysis is given for the relaxed verification criterion in PathRelax (how semantic similarity is quantified and thresholded across paths) or proof that it leaves the marginal distribution of generated tokens unchanged relative to strict Jacobi matching; this is required to substantiate the 'without sacrificing image quality' assertion.
Authors: Section 3.2 defines the criterion via cosine similarity of CLIP embeddings with a per-path adaptive threshold derived from sequence divergence. While we provide no formal proof of marginal distribution invariance (the approach is heuristic), the empirical results demonstrate equivalent quality metrics. We will expand Section 3 with a precise mathematical formulation, pseudocode, and additional distribution-shift analysis in the revision. revision: partial
Circularity Check
No circularity; empirical speedups rest on measured token acceptance rates, not definitions or self-citations
full rationale
The paper introduces PathSpec with PathExplore (parallel draft tree) and PathRelax (cross-path relaxed verification) for speculative Jacobi decoding in autoregressive T2I models. Speedup ratios (4.14× etc.) are reported as direct empirical outcomes on Parti-Prompts, MSCOCO2017 and T2ICompBench; the abstract and description contain no equations, fitted parameters renamed as predictions, or load-bearing self-citations. The central claim that relaxation increases acceptance without quality loss is presented as an experimental result rather than a derivation that reduces to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improving image generation with better captions.Computer Science, 2(3):8, 2023
James Betker, Gabriel Goh, Li Jing, TimBrooks, Jianfeng Wang, Linjie Li, LongOuyang, JuntangZhuang, JoyceLee, YufeiGuo, WesamManassra, PrafullaDhariwal, CaseyChu, YunxinJiao, and Aditya Ramesh. Improving image generation with better captions.Computer Science, 2(3):8, 2023. 1
2023
-
[2]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding 8 heads. InInternational Conference on Machine Learning. JMLR.org, 2024. 2
2024
-
[3]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In IEEE/CVF International Conference on Computer Vision, pages 9630–9640, 2021. 6
2021
-
[4]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean- Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerat- ing large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318, 2023. 1, 2, 4, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Pixart-$\alpha$: Fast training of diffusion transformer for photorealistic text-to-image synthesis
Junsong Chen, Jincheng YU, Chongjian GE, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-$\alpha$: Fast training of diffusion transformer for photorealistic text-to-image synthesis. In International Conference on Learning Representations, 2024. 2
2024
-
[6]
Anole: An open, autoregressive, native large multimodal models for interleaved image-text generation, 2024
Ethan Chern, Jiadi Su, Yan Ma, and Pengfei Liu. Anole: An open, autoregressive, native large multimodal models for interleaved image-text generation, 2024. 2
2024
-
[7]
Baking relightable nerf for real-time di- rect/indirect illumination rendering, 2024
Euntae Choi, Vincent Carpentier, Seunghun Shin, and Sungjoo Yoo. Baking relightable nerf for real-time di- rect/indirect illumination rendering, 2024. 1, 2, 6, 7, 8, 14, 16
2024
-
[8]
Accelerated diffusion models via speculative sampling
Valentin De Bortoli, Alexandre Galashov, Arthur Gretton, and Arnaud Doucet. Accelerated diffusion models via speculative sampling. InProceedings of International Conference on Machine Learning. JMLR.org, 2025. 3
2025
-
[9]
Inductive generative recommendation via retrieval-based spec- ulation
Yijie Ding, Jiacheng Li, Julian McAuley, and Yupeng Hou. Inductive generative recommendation via retrieval-based spec- ulation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 14675–14683, 2026. 3
2026
-
[10]
Vvs: Accelerating speculative decoding for visual autoregressive generation via partial verification skipping, 2026
Haotian Dong, Ye Li, Rongwei Lu, Chen Tang, Shu-Tao Xia, and Zhi Wang. Vvs: Accelerating speculative decoding for visual autoregressive generation via partial verification skipping, 2026. 3
2026
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions, 2021. 2
2021
-
[12]
On speculative de- coding for multimodal large language models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, and Christopher Lott. On speculative de- coding for multimodal large language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 8285–8289, 2024. 2
2024
-
[13]
CLIPScore: a reference-free evaluation met- ric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: a reference-free evaluation met- ric for image captioning. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 7514–7528, 2021. 2, 6, 13
2021
-
[14]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bern- hard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InProceedings of the International Conference on Neural Information Processing Systems, page 6629–6640. Curran Associates Inc., 2017. 6
2017
-
[15]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InProceedings of International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2020. Curran Associates Inc. 1
2020
-
[16]
Specvlm: Fast speculative decoding in vision-language models, 2025
Haiduo Huang, Fuwei Yang, Zhenhua Liu, Xuanwu Yin, Dong Li, Pengju Ren, and Emad Barsoum. Specvlm: Fast speculative decoding in vision-language models, 2025. 2
2025
-
[17]
Kaiyi Huang, Chengqi Duan, Kaiyue Sun, Enze Xie, Zhen- guo Li, and Xihui Liu. T2i-compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 47(5):3563–3579, 2025. 6
2025
-
[18]
Spec-llava: Accelerating vision-language models with dynamic tree-based speculative decoding, 2025
Mingxiao Huo, Jiayi Zhang, Hewei Wang, Jinfeng Xu, Zheyu Chen, Huilin Tai, and Yijun Chen. Spec-llava: Accelerating vision-language models with dynamic tree-based speculative decoding, 2025. 2
2025
-
[19]
Lantern: Accelerating visual autoregressive models with relaxed speculative decoding
Doohyuk Jang, Sihwan Park, June Yong Yang, Yeonsung Jung, Jihun Yun, Souvik Kundu, Sungyub Kim, and Eunho Yang. Lantern: Accelerating visual autoregressive models with relaxed speculative decoding. InInternational Confer- ence on Learning Representations, 2025. 1, 2, 15
2025
-
[20]
Sjd-pac: Accelerating speculative jacobi decoding via proactive drafting and adaptive continuation, 2026
Jialiang Kang, Han Shu, Wenshuo Li, Yingjie Zhai, and Xing- hao Chen. Sjd-pac: Accelerating speculative jacobi decoding via proactive drafting and adaptive continuation, 2026. 3
2026
-
[21]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InPro- ceedings of International Conference on Machine Learning, pages 19274–19286. PMLR, 2023. 1, 2, 13
2023
-
[22]
BLIP: Bootstrapping language-image pre-training for unified vision- language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision- language understanding and generation. InProceedings of the International Conference on Machine Learning, pages 12888–12900. PMLR, 2022. 6
2022
-
[23]
An- nealed relaxation of speculative decoding for faster autore- gressive image generation, 2026
Xingyao Li, Fengzhuo Zhang, Cunxiao Du, and Hui Ji. An- nealed relaxation of speculative decoding for faster autore- gressive image generation, 2026. 3
2026
-
[24]
EAGLE-2: Faster inference of language models with dynamic draft trees
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-2: Faster inference of language models with dynamic draft trees. InConference on Empirical Methods in Natu- ral Language Processing, pages 7421–7432, Miami, Florida, USA, 2024. Association for Computational Linguistics. 2
2024
-
[25]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bour- dev, Ross Girshick, James Hays, Pietro Perona, Deva Ra- manan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015. 6
2015
-
[26]
Lumina-mGPT: Illuminate flexible photorealistic text-to-image generation with multi- modal generative pretraining, 2025
Dongyang Liu, Shitian Zhao, Le Zhuo, Weifeng Lin, Yu Qiao, Hongsheng Li, and Peng Gao. Lumina-mGPT: Illuminate flexible photorealistic text-to-image generation with multi- modal generative pretraining, 2025. 1, 2, 6, 7, 8, 13, 16
2025
-
[27]
DAB-DETR: Dynamic anchor boxes are better queries for DETR
Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: Dynamic anchor boxes are better queries for DETR. InInternational Conference on Learning Representations, 2022. 6
2022
-
[28]
Specin- fer: Accelerating large language model serving with tree- based speculative inference and verification
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, 9 Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specin- fer: Accelerating large language model serving with tree- based speculative inference and verification. InProceedings of the ACM I...
2024
-
[29]
LANTERN++: Enhanced relaxed spec- ulative decoding with static tree drafting for visual auto- regressive models
Sihwan Park, Doohyuk Jang, Sung-Yub Kim, Souvik Kundu, and Eunho Yang. LANTERN++: Enhanced relaxed spec- ulative decoding with static tree drafting for visual auto- regressive models. InWorkshop on Scalable Optimization for Efficient and Adaptive Foundation Models, 2025. 1, 2, 7, 8, 13
2025
-
[30]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models . In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, Los Alamitos, CA, USA, 2022. IEEE Computer Society. 1
2022
-
[31]
Photorealistic text-to-image diffusion models with deep language under- standing
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language under- standing. InAdvances in Neural Information Processing Systems, pages 36479–...
2022
-
[32]
Sara Mahdavi, Raphael Gontijo-Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Lit, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Raphael Gontijo-Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. InPro- ceedings of the International Co...
2022
-
[33]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InAdvances in neural information processing systems, page 2234–2242. Curran Associates Inc., 2016. 6
2016
-
[34]
Accelerating transformer inference for translation via parallel decoding
Andrea Santilli, Silvio Severino, Emilian Postolache, Valentino Maiorca, Michele Mancusi, Riccardo Marin, and Emanuele Rodola. Accelerating transformer inference for translation via parallel decoding. InAnnual Meeting Of The Association For Computational Linguistics, pages 12336– 12355, 2023. 2, 7, 8
2023
-
[35]
Grouped speculative decoding for autoregressive image generation
Junhyuk So, Juncheol Shin, Hyunho Kook, and Eunhyeok Park. Grouped speculative decoding for autoregressive image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15375–15384, 2025. 1, 2, 3, 7, 8, 13, 15
2025
-
[36]
Speculative coupled decoding for training-free lossless acceleration of autoregressive visual generation, 2026
Junhyuk So, Hyunho Kook, Chaeyeon Jang, and Eunhyeok Park. Speculative coupled decoding for training-free lossless acceleration of autoregressive visual generation, 2026. 3
2026
-
[37]
Autoregressive model beats diffusion: Llama for scalable image generation, 2024
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation, 2024. 2
2024
-
[38]
Chameleon: Mixed-modal early-fusion foundation models, 2025
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models, 2025. 1
2025
-
[39]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupati- raju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, Nino Vieillard, Piotr Stanczyk, Sertan Girgin...
2024
-
[40]
Sjd++: Improved speculative jacobi decoding for training-free accel- eration of discrete auto-regressive text-to-image generation,
Yao Teng, Zhihuan Jiang, Han Shi, Xian Liu, Xuefei Ning, Guohao Dai, Yu Wang, Zhenguo Li, and Xihui Liu. Sjd++: Improved speculative jacobi decoding for training-free accel- eration of discrete auto-regressive text-to-image generation,
-
[41]
Accelerating auto- regressive text-to-image generation with training-free specu- lative jacobi decoding
Yao Teng, Han Shi, Xian Liu, Xuefei Ning, Guohao Dai, Yu Wang, Zhenguo Li, and Xihui Liu. Accelerating auto- regressive text-to-image generation with training-free specu- lative jacobi decoding. InInternational Conference on Learn- ing Representations, 2025. 2, 5, 6, 7, 8
2025
-
[42]
Speculative jacobi-denoising decoding for accelerating autoregressive text-to-image generation, 2025
Yao Teng, Fuyun Wang, Xian Liu, Zhekai Chen, Han Shi, Yu Wang, Zhenguo Li, Weiyang Liu, Difan Zou, and Xihui Liu. Speculative jacobi-denoising decoding for accelerating autoregressive text-to-image generation, 2025. 3
2025
-
[43]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InProceedings of International Conference on Neural Information Processing Systems, page 6309–6318, Red Hook, NY , USA, 2017. Curran Associates Inc. 2
2017
-
[44]
Specprune-vla: Accelerating vision-language- action models via action-aware self-speculative pruning, 2025
Hanzhen Wang, Jiaming Xu, Jiayi Pan, Yongkang Zhou, and Guohao Dai. Specprune-vla: Accelerating vision-language- action models via action-aware self-speculative pruning, 2025. 2
2025
-
[45]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Lumina-mgpt 2.0: Stand-alone autoregressive image model- ing, 2025
Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Ren- rui Zhang, Le Zhuo, Tiancheng Han, Xiaoqing Sun, Siqi Luo, Mengmeng Wang, Bin Fu, Yuewen Cao, Hongsheng Li, Guangtao Zhai, Xiaohong Liu, Yu Qiao, and Peng Gao. Lumina-mgpt 2.0: Stand-alone autoregressive image model- ing, 2025. 1, 2
2025
-
[47]
Scaling autoregressive models for content-rich text-to- image generation, 2022
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to- image generation, 2022. 6
2022
-
[48]
Learning harmonized representations for speculative sampling, 2024
Lefan Zhang, Xiaodan Wang, Yanhua Huang, and Ruiwen Xu. Learning harmonized representations for speculative sampling, 2024. 2
2024
-
[49]
Lookahead: An inference acceleration framework for large language model with lossless generation accuracy
Yao Zhao, Zhitian Xie, Chen Liang, Chenyi Zhuang, and Jinjie Gu. Lookahead: An inference acceleration framework for large language model with lossless generation accuracy. InACM SIGKDD Conference on Knowledge Discovery and Data Mining, page 6344–6355. Association for Computing Machinery, 2024. 2
2024
-
[50]
Sim- ple multi-dataset detection
Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl. Sim- ple multi-dataset detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7571–7580, 2022. 6 11 A. Proof of the Lossless Guarantees of PathEx- plore Theorem 1The token sequence accepted by the Parallel- Path Speculative Jacobi Decoding (PathExplore) sat...
2022
-
[51]
Acceptance ProbabilityAccording to the PathExplore method (and standard speculative decoding), a candidate tokenxfrom the draft tree is accepted with probability: p(ris true|x,J (j),J (j−1)) = min 1, p(x|J (j)) p(x|J (j−1)) , (9) where r is the boolean variable representing acceptance. The joint probability of a token x being sampled by the draft strategy...
-
[52]
Rejection and Resampling ProbabilityIf the token is rejected, we must account for the probability mass that was not covered by the acceptance step. The probability of rejection for the draft distribution is: p(ris false|J (j),J (j−1)) = 1− X x′ p(ris true, x ′|J (j),J (j−1)) = X x′ p(x′|J (j))− X x′ min{p(x′|J (j)), p(x′|J (j−1))} = X x′ max{0, p(x′|J (j)...
-
[53]
Total ProbabilityWe verify that the sum of prob- abilities from both cases recovers the target distribution p(x|J (j)). Using the identity a= min(a, b)+max(0, a−b) , we have: p(x|J (j)) = min{p(x|J (j)), p(x|J (j−1))}+ max{0, p(x|J (j))−p(x|J (j−1))} =p(ris true,x|J (j),J (j−1)) +p(ris false,x|J (j),J (j−1)). (14) According to Eq. 14, the conditional dist...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.