Database Context Compression for Text-to-SQL on Real-World Large Databases
Pith reviewed 2026-06-30 00:46 UTC · model grok-4.3
The pith
A query-agnostic offline compression of database schemas and documentation cuts input size by up to 75 times and lifts Text-to-SQL execution accuracy by 1.8-1.9 percent on large real-world benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
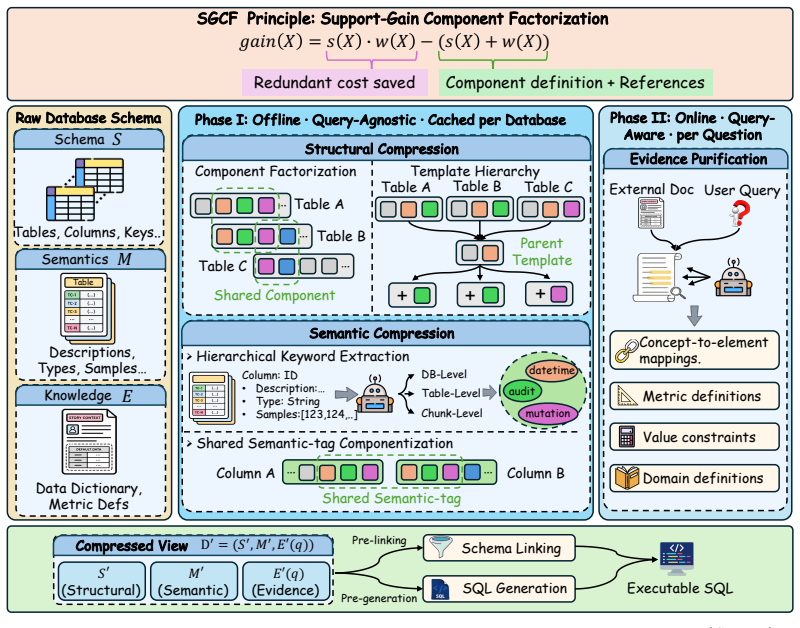
The central claim is that database context compression, formalized through the Support-Gain Component Factorization principle, unifies repeated-column removal, table templating, semantic componentization, and evidence purification into a single coverage objective; performing this transformation offline produces a compact representation that preserves query-relevant information and yields higher schema-linking recall and execution accuracy when the compressed context is supplied to existing Text-to-SQL systems.
What carries the argument
DBCC, a model-agnostic middleware that performs offline structural and semantic compression of schemas, descriptions, and external documentation according to the SGCF coverage objective, followed by lightweight online evidence purification.
If this is right
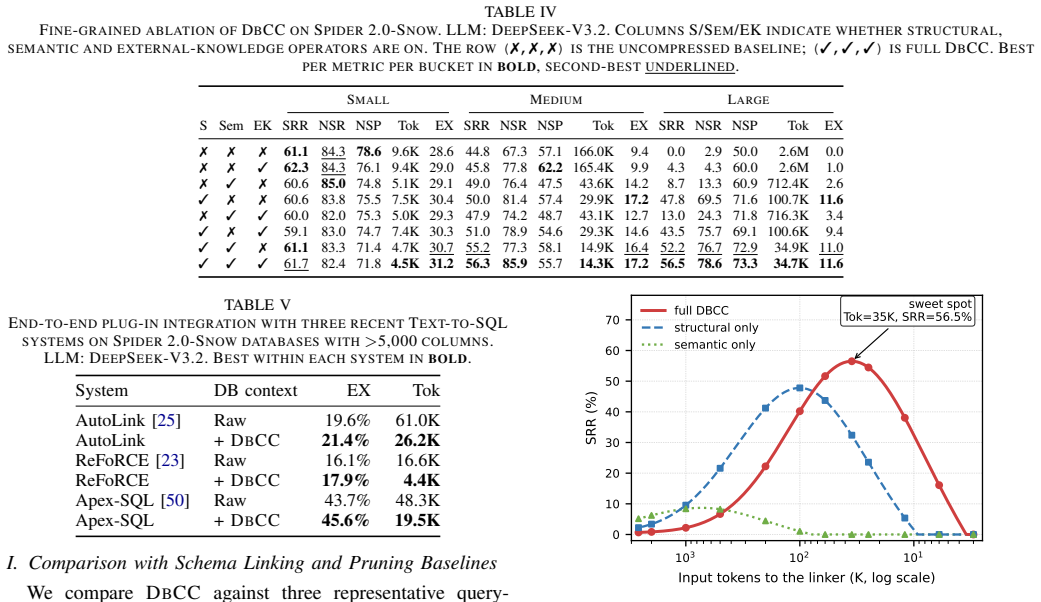
- Input token counts fall from 2.6 million to 34.7 thousand on the largest Spider 2.0-Snow subset.
- Schema-linking strict recall rises from 0 percent to 56.5 percent under DeepSeek-V3.2 and 63.1 percent under Claude Opus 4.7.
- End-to-end execution accuracy increases by 1.8-1.9 percent over three recent Text-to-SQL systems on Spider 2.0-Snow and BIRD.
- The compressed representation can be inserted into any existing Text-to-SQL pipeline without retraining the language model.
Where Pith is reading between the lines
- Databases intended for AI use could be redesigned with compressibility as an explicit design goal rather than treating documentation as an afterthought.
- The same offline rewrite technique may apply to other LLM tasks that ingest large structured repositories, such as code generation over enterprise codebases.
- If the compression preserves coverage, it opens the possibility of maintaining a single compressed database view that serves many downstream models simultaneously.
Load-bearing premise
The compression step, performed without seeing future queries, never discards information that later turns out to be required for generating correct SQL.
What would settle it
Run the same set of previously unseen queries on both the original full context and the DBCC-compressed context; if any query produces a correct execution result only on the full context, the compression has lost necessary information.
Figures


read the original abstract
Recent progress in Text-to-SQL has been driven by stronger language models and prompting strategies, yet performance on real enterprise benchmarks such as Spider 2.0 and BIRD remains far below that on classical academic datasets. We argue that the main bottleneck is no longer reasoning, but database representation. Real databases contain repeated audit columns, large groups of similar tables, opaque identifiers whose meanings are stored only in documentation, and extensive data dictionaries with little query-relevant information. Existing query-aware methods, including schema linking and retrieval-based schema selection, filter this raw context but still operate on redundant and verbose representations. We reformulate the problem as database context compression, a query-agnostic transformation that rewrites schemas, semantic descriptions, and external documentation into a compact representation. We formalize this transformation with the SGCF (Support-Gain Component Factorization) principle, which unifies repeated column extraction, isomorphic table templating, semantic componentization, and evidence purification under a single coverage objective. Based on SGCF, we propose DBCC, a database-side middleware that performs offline structural and semantic compression together with lightweight online evidence purification. DBCC is model-agnostic and can be integrated into existing Text-to-SQL pipelines. On Spider 2.0-Snow and BIRD, DBCC reduces input context by up to two orders of magnitude (from 2.6M to 34.7K tokens on the largest Spider 2.0-Snow subset), improves schema-linking strict recall from 0% to 56.5% under DeepSeek-V3.2 (63.1% under Claude Opus 4.7), and consistently increases end-to-end execution accuracy by 1.8-1.9% over three recent Text-to-SQL systems. Our code is open-sourced at https://github.com/MrBlankness/SchemaCompression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a query-agnostic database context compression technique called DBCC, based on the SGCF principle, can reduce the input context for Text-to-SQL by up to two orders of magnitude (from 2.6M to 34.7K tokens) on large databases, improve schema-linking strict recall from 0% to 56.5%, and increase end-to-end execution accuracy by 1.8-1.9% over three recent systems on Spider 2.0-Snow and BIRD benchmarks.
Significance. If the results hold, this work has significant practical implications for Text-to-SQL on real-world large databases by addressing the context length bottleneck through offline compression. The model-agnostic design and open-sourced code at https://github.com/MrBlankness/SchemaCompression are strengths that enhance the contribution's value.
major comments (2)
- [Abstract] The abstract reports concrete token-reduction and accuracy numbers, but provides no derivation of SGCF, no error bars, no ablation of the compression steps, and no discussion of how query-agnosticism was validated; evaluation details are absent.
- [SGCF definition] The SGCF principle unifies repeated column extraction, isomorphic table templating, semantic componentization, and evidence purification under a coverage objective but supplies no explicit invariant or completeness argument for low-frequency documentation entries or opaque identifiers whose meanings appear only in external docs; this is load-bearing for the claim that the offline pass preserves everything required for unseen queries.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the practical value of addressing the context-length bottleneck in real-world Text-to-SQL. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] The abstract reports concrete token-reduction and accuracy numbers, but provides no derivation of SGCF, no error bars, no ablation of the compression steps, and no discussion of how query-agnosticism was validated; evaluation details are absent.
Authors: The abstract is written to be concise. The full manuscript contains the SGCF derivation (Section 3), ablations of the individual compression steps (Section 5.3), and explicit validation of query-agnosticism via experiments on queries unseen during the offline pass (Section 4.2). We will revise the manuscript to add error bars to all reported metrics, include a short pointer to the evaluation protocol in the abstract, and ensure all numerical claims are cross-referenced to the relevant sections and tables. revision: yes
-
Referee: [SGCF definition] The SGCF principle unifies repeated column extraction, isomorphic table templating, semantic componentization, and evidence purification under a coverage objective but supplies no explicit invariant or completeness argument for low-frequency documentation entries or opaque identifiers whose meanings appear only in external docs; this is load-bearing for the claim that the offline pass preserves everything required for unseen queries.
Authors: We agree that an explicit completeness argument would strengthen the formalization. The coverage objective is intended to retain every semantic component present in the original context, with low-frequency documentation entries kept verbatim and opaque identifiers preserved in the compressed schema; online purification is applied only at query time. The current version does not supply a formal invariant. In revision we will add a dedicated paragraph in Section 3.2 that states the preservation property, provides concrete examples from Spider 2.0-Snow and BIRD involving external documentation, and clarifies the boundary between offline retention and online filtering. revision: yes
Circularity Check
No circularity: SGCF is presented as a new unifying principle with empirical outcomes
full rationale
The paper defines SGCF as a coverage objective that unifies several compression operations and reports DBCC's effects as measured improvements on Spider 2.0-Snow and BIRD (context reduction, recall lift, accuracy gains). No equations, fitted parameters, or self-citations are exhibited that reduce the claimed results to inputs by construction; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
SGCF principle
no independent evidence
-
DBCC middleware
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constructing an interactive natural language interface for relational databases,
F. Li and H. V . Jagadish, “Constructing an interactive natural language interface for relational databases,” inProceedings of the VLDB Endow- ment, vol. 8, no. 1, 2014, pp. 73–84
2014
-
[2]
SQLizer: Query synthesis from natural language,
N. Yaghmazadeh, Y . Wang, I. Dillig, and T. Dillig, “SQLizer: Query synthesis from natural language,”Proc. ACM Program. Lang., vol. 1, no. OOPSLA, pp. 1–26, 2017
2017
-
[3]
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task,
T. Yu, R. Zhang, K. Yang, M. Yasunaga, D. Wang, Z. Li, J. Ma, I. Li, Q. Yao, S. Roman, Z. Zhang, and D. Radev, “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task,” inProc. EMNLP, 2018, pp. 3911–3921
2018
-
[4]
ATHENA: An ontology-driven system for natural language querying over relational data stores,
D. Saha, A. Floratou, K. Sankaranarayanan, U. F. Minhas, A. R. Mittal, and F. ¨Ozcan, “ATHENA: An ontology-driven system for natural language querying over relational data stores,”Proc. VLDB Endow., vol. 9, no. 12, pp. 1209–1220, 2016
2016
-
[5]
Bridging the semantic gap with SQL query logs in natural language interfaces to databases,
C. Baik, H. V . Jagadish, and Y . Li, “Bridging the semantic gap with SQL query logs in natural language interfaces to databases,” inProc. IEEE Int. Conf. Data Engineering (ICDE), 2019, pp. 374–385
2019
-
[6]
Duoquest: A dual-specification system for expressive SQL queries,
C. Baik, Z. Jin, M. J. Cafarella, and H. V . Jagadish, “Duoquest: A dual-specification system for expressive SQL queries,” inProc. ACM SIGMOD Int. Conf. Management of Data, 2020, pp. 2319–2329
2020
-
[7]
A survey of text-to-SQL in the era of LLMs: Where are we, and where are we going?
X. Liu, S. Shen, B. Li, P. Ma, R. Jiang, Y . Luo, Y . Zhang, J. Fan, G. Li, and N. Tang, “A survey of text-to-SQL in the era of LLMs: Where are we, and where are we going?”IEEE Trans. Knowl. Data Eng., 2025
2025
-
[8]
Next-generation database interfaces: A survey of LLM-based text-to- SQL,
Z. Hong, Z. Yuan, Q. Zhang, H. Chen, J. Dong, F. Huang, and X. Huang, “Next-generation database interfaces: A survey of LLM-based text-to- SQL,”IEEE Trans. Knowl. Data Eng., 2025
2025
-
[9]
RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers,
B. Wang, R. Shin, X. Liu, O. Polozov, and M. Richardson, “RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers,” inProc. ACL, 2020, pp. 7567–7578
2020
-
[10]
RESDSQL: Decoupling schema linking and skeleton parsing for text-to-SQL,
H. Li, J. Zhang, C. Li, and H. Chen, “RESDSQL: Decoupling schema linking and skeleton parsing for text-to-SQL,” inProc. AAAI, vol. 37, no. 11, 2023, pp. 13 067–13 075
2023
-
[11]
DIN-SQL: Decomposed in-context learning of text-to-SQL with self-correction,
M. Pourreza and D. Rafiei, “DIN-SQL: Decomposed in-context learning of text-to-SQL with self-correction,”Adv. Neural Inf. Process. Syst., vol. 36, pp. 36 339–36 348, 2023
2023
-
[12]
CHESS: Contextual Harnessing for Efficient SQL Synthesis
S. Talaei, M. Pourreza, Y .-C. Chang, A. Mirhoseini, and A. Saberi, “CHESS: Contextual harnessing for efficient SQL synthesis,”arXiv preprint arXiv:2405.16755, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
arXiv preprint arXiv:2410.01943
M. Pourreza, H. Li, R. Sun, Y . Chung, S. Talaeiet al., “CHASE-SQL: Multi-path reasoning and preference optimized candidate selection in text-to-SQL,”arXiv preprint arXiv:2410.01943, 2024
-
[14]
Text-to- SQL empowered by large language models: A benchmark evaluation,
D. Gao, H. Wang, Y . Li, X. Sun, Y . Qian, B. Ding, and J. Zhou, “Text-to- SQL empowered by large language models: A benchmark evaluation,” Proc. VLDB Endow., vol. 17, no. 5, pp. 1132–1145, 2024
2024
-
[15]
Can LLM already serve as a database interface? A big bench for large-scale database grounded text-to-SQLs,
J. Li, B. Hui, G. Qu, J. Yang, B. Li, B. Li, B. Wang, B. Qin, R. Geng, N. Huoet al., “Can LLM already serve as a database interface? A big bench for large-scale database grounded text-to-SQLs,”Adv. Neural Inf. Process. Syst., vol. 36, pp. 42 330–42 357, 2023
2023
-
[16]
F. Lei, J. Chen, Y . Yeet al., “Spider 2.0: Evaluating language mod- els on real-world enterprise text-to-SQL workflows,”arXiv preprint arXiv:2411.07763, 2024
-
[17]
Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing,
X. V . Lin, R. Socher, and C. Xiong, “Bridging textual and tabular data for cross-domain text-to-SQL semantic parsing,” inFindings of EMNLP, 2020, pp. 4870–4888
2020
-
[18]
arXiv preprint arXiv:2411.00073 , year=
Z. Cao, Y . Zheng, Z. Fan, X. Zhang, W. Chen, and X. Bai, “RSL- SQL: Robust schema linking in text-to-SQL generation,”arXiv preprint arXiv:2411.00073, 2024
-
[19]
CRUSH4SQL: Collective retrieval using schema hallucination for Text2SQL,
M. Kothyari, D. Dhingra, S. Sarawagi, and S. Chakrabarti, “CRUSH4SQL: Collective retrieval using schema hallucination for Text2SQL,” inProc. EMNLP, 2023, pp. 14 054–14 066
2023
-
[20]
LinkAlign: Scalable schema linking for real-world large-scale multi-database text-to-SQL,
Y . Wang, P. Liu, and X. Yang, “LinkAlign: Scalable schema linking for real-world large-scale multi-database text-to-SQL,” inProc. EMNLP, 2025, pp. 977–991
2025
-
[21]
CodeS: Towards building open-source language models for text-to-SQL,
H. Li, J. Zhang, H. Liu, J. Fan, X. Zhang, J. Zhu, R. Wei, H. Pan, C. Li, and H. Chen, “CodeS: Towards building open-source language models for text-to-SQL,”Proc. ACM Manag. Data, vol. 2, no. 3, pp. 1–28, 2024
2024
-
[22]
DB-Explore: Automated database exploration and instruction synthesis for text-to-SQL,
H. Ma, Y . Shen, H. Liuet al., “DB-Explore: Automated database exploration and instruction synthesis for text-to-SQL,”arXiv preprint arXiv:2503.04959, 2025
-
[23]
ReFoRCE: A text-to-SQL agent with self-refinement, format restriction, and column exploration,
M. Deng, A. Ramachandran, C. Xu, L. Hu, Z. Yao, A. Datta, and H. Zhang, “ReFoRCE: A text-to-SQL agent with self-refinement, format restriction, and column exploration,” inICLR Workshop on VerifAI, 2025
2025
-
[24]
MAC-SQL: A multi-agent collaborative framework for text-to- SQL,
B. Wang, C. Ren, J. Yang, X. Liang, J. Bai, Q.-W. Zhang, Z. Yan, and Z. Li, “MAC-SQL: A multi-agent collaborative framework for text-to- SQL,” inProc. COLING, 2025, pp. 540–557
2025
-
[25]
AutoLink: Autonomous schema exploration and expansion for scalable schema linking in text-to-SQL at scale,
Z. Wang, Y . Zheng, Z. Caoet al., “AutoLink: Autonomous schema exploration and expansion for scalable schema linking in text-to-SQL at scale,” inProc. AAAI Conf. Artificial Intelligence, 2026, to appear
2026
-
[26]
LGESQL: Line graph enhanced text-to-SQL model with mixed local and non-local relations,
R. Cao, L. Chen, Z. Chen, Y . Zhao, S. Zhu, and K. Yu, “LGESQL: Line graph enhanced text-to-SQL model with mixed local and non-local relations,” inProc. ACL-IJCNLP, 2021, pp. 2541–2555
2021
-
[27]
GraPPa: Grammar-augmented pre-training for table semantic parsing,
T. Yu, C.-S. Wu, X. V . Lin, B. Wang, Y . C. Tan, X. Yang, D. Radev, R. Socher, and C. Xiong, “GraPPa: Grammar-augmented pre-training for table semantic parsing,” inProc. ICLR, 2021
2021
-
[28]
Structure-grounded pretraining for text-to-SQL,
X. Deng, A. H. Awadallah, C. Meek, O. Polozov, H. Sun, and M. Richardson, “Structure-grounded pretraining for text-to-SQL,” in Proc. NAACL, 2021, pp. 1337–1350
2021
-
[29]
PICARD: Parsing in- crementally for constrained auto-regressive decoding from language models,
T. Scholak, N. Schucher, and D. Bahdanau, “PICARD: Parsing in- crementally for constrained auto-regressive decoding from language models,” inProc. EMNLP, 2021, pp. 9895–9901
2021
-
[30]
To- wards complex text-to-SQL in cross-domain database with intermediate representation,
J. Guo, Z. Zhan, Y . Gao, Y . Xiao, J.-G. Lou, T. Liu, and D. Zhang, “To- wards complex text-to-SQL in cross-domain database with intermediate representation,” inProc. ACL, 2019, pp. 4524–4535
2019
-
[31]
arXiv preprint arXiv:2307.07306 , year=
X. Dong, C. Zhang, Y . Ge, Y . Mao, Y . Gao, J. Lin, D. Lou et al., “C3: Zero-shot text-to-SQL with ChatGPT,”arXiv preprint arXiv:2307.07306, 2023
-
[32]
ACT-SQL: In-context learning for text-to-SQL with automatically-generated chain-of-thought,
H. Zhang, R. Cao, L. Chen, H. Xu, and K. Yu, “ACT-SQL: In-context learning for text-to-SQL with automatically-generated chain-of-thought,” arXiv preprint arXiv:2310.17342, 2023
-
[33]
PET-SQL: A prompt- enhanced two-stage text-to-SQL framework with cross-consistency,
Z. Li, X. Wang, J. Zhao, S. Yanget al., “PET-SQL: A prompt- enhanced two-stage text-to-SQL framework with cross-consistency,” arXiv preprint arXiv:2403.09732, 2024
-
[34]
PURPLE: Making a large language model a better SQL writer,
T. Ren, Y . Fan, Z. He, R. Huang, J. Dai, C. Huang, Y . Jing, K. Zhang, Y . Yang, and X. S. Wang, “PURPLE: Making a large language model a better SQL writer,” inProc. IEEE Int. Conf. Data Engineering (ICDE), 2024, pp. 15–28
2024
-
[35]
AID-SQL: Adaptive in-context learning of text-to-SQL with difficulty-aware instruction and retrieval-augmented generation,
X. Li, Q. Cai, Y . Shu, C. Guo, and B. Yang, “AID-SQL: Adaptive in-context learning of text-to-SQL with difficulty-aware instruction and retrieval-augmented generation,” inProc. IEEE Int. Conf. Data Engi- neering (ICDE), 2025, pp. 3945–3957
2025
-
[36]
Gar: A generate-and-rank approach for natural language to SQL translation,
Y . Fan, Z. He, T. Ren, D. Guo, L. Chen, R. Zhu, G. Chen, Y . Jing, K. Zhang, and X. S. Wang, “Gar: A generate-and-rank approach for natural language to SQL translation,” inProc. IEEE Int. Conf. Data Engineering (ICDE), 2023, pp. 110–122
2023
-
[37]
Metasql: A generate-then-rank framework for natural language to SQL translation,
Y . Fan, Z. He, T. Ren, C. Huang, Y . Jing, K. Zhang, and X. S. Wang, “Metasql: A generate-then-rank framework for natural language to SQL translation,” inProc. IEEE Int. Conf. Data Engineering (ICDE), 2024, pp. 1765–1778
2024
-
[38]
An in-depth benchmarking of text-to-SQL systems,
O. Gkini, T. Belmpas, G. Koutrika, and Y . E. Ioannidis, “An in-depth benchmarking of text-to-SQL systems,” inProc. ACM SIGMOD Int. Conf. Management of Data, 2021, pp. 632–644
2021
-
[39]
Semantic enhanced text-to-SQL parsing via iteratively learning schema linking graph,
A. Liu, X. Hu, L. Lin, and L. Wen, “Semantic enhanced text-to-SQL parsing via iteratively learning schema linking graph,” inProc. ACM SIGKDD Conf. Knowledge Discovery and Data Mining, 2022, pp. 1021– 1030
2022
-
[40]
Schema matching using pre-trained language models,
Y . Zhang, A. Floratou, J. Cahoon, S. Krishnan, A. C. M ¨uller, D. Banda, F. Psallidas, and J. M. Patel, “Schema matching using pre-trained language models,” inProc. IEEE Int. Conf. Data Engineering (ICDE), 2023, pp. 1558–1571
2023
-
[41]
CLEAR: A parser-independent disambiguation framework for NL2SQL,
M. Zhang, K. Ma, L. Xu, K. Zhang, Y . Peng, and R. Jin, “CLEAR: A parser-independent disambiguation framework for NL2SQL,” inProc. IEEE Int. Conf. Data Engineering (ICDE), 2025, pp. 1–14
2025
-
[42]
LLMLingua: Com- pressing prompts for accelerated inference of large language models,
H. Jiang, Q. Wu, C.-Y . Lin, Y . Yang, and L. Qiu, “LLMLingua: Com- pressing prompts for accelerated inference of large language models,” inProc. EMNLP, 2023, pp. 13 358–13 376
2023
-
[43]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Trans. Assoc. Comput. Linguist., vol. 12, pp. 157–173, 2024
2024
-
[44]
Generating succinct descriptions of database schemata for cost-efficient prompting of large language models,
I. Trummer, “Generating succinct descriptions of database schemata for cost-efficient prompting of large language models,”Proc. VLDB Endow., vol. 17, no. 11, 2024
2024
-
[45]
FinSQL: Model-agnostic LLMs-based text-to-SQL framework for financial analysis,
C. Zhang, Y . Mao, Y . Fan, Y . Mi, Y . Gao, L. Chen, D. Lou, and J. Lin, “FinSQL: Model-agnostic LLMs-based text-to-SQL framework for financial analysis,” inCompanion of the ACM SIGMOD Int. Conf. Management of Data, 2024, pp. 93–105
2024
-
[46]
Combining small language models and large language models for zero-shot NL2SQL,
J. Fan, Z. Gu, S. Zhang, Y . Zhang, Z. Chen, L. Cao, G. Li, S. Madden, X. Du, and N. Tang, “Combining small language models and large language models for zero-shot NL2SQL,”Proc. VLDB Endow., vol. 17, no. 11, pp. 2750–2763, 2024
2024
-
[47]
Is long context all you need? Leveraging LLM’s extended context for NL2SQL,
Y . Chung, G. T. Kakkar, Y . Gan, B. Milne, and F. Ozcan, “Is long context all you need? Leveraging LLM’s extended context for NL2SQL,”Proc. VLDB Endow., vol. 18, no. 8, pp. 2735–2747, 2025
2025
-
[48]
Robertson and H
S. Robertson and H. Zaragoza,The Probabilistic Relevance Framework: BM25 and Beyond. Now Publishers Inc., 2009, vol. 4
2009
-
[49]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” inProc. EMNLP-IJCNLP, 2019, pp. 3982–3992
2019
-
[50]
APEX-SQL: Talking to the data via agentic exploration for Text-to-SQL,
B. Cao, W. Liao, Y . Sun, D. Fang, H. Li, and W. Lam, “APEX-SQL: Talking to the data via agentic exploration for Text-to-SQL,” inProc. ACM SIGKDD Conf. Knowledge Discovery and Data Mining (KDD), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.