Causal Representation Learning for Generalisable Recommendation
Pith reviewed 2026-06-29 15:39 UTC · model grok-4.3
The pith
An information-theoretic disentanglement criterion isolates causal components from confounded recommendation logs to improve generalization under distribution shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes an information-theoretic disentanglement criterion and proves that its optimum depends only on the causal components of the input. It derives a tractable variational lower bound that makes the criterion optimisable from finite observational data alone. The approach targets better generalisation under distribution shift without requiring full identification of all latent causal factors or knowledge of the causal graph.
What carries the argument
information-theoretic disentanglement criterion whose optimum depends only on the causal components of the input
If this is right
- The criterion can be optimized from existing confounded logs without interventions.
- It yields better out-of-distribution generalization in recommendation tasks.
- Production A/B tests show substantial gains in listener engagement.
- Similar patterns hold on public datasets and synthetic benchmarks with known causal structure.
Where Pith is reading between the lines
- This narrower focus on generalization rather than full causal identification makes causal methods practical for large-scale systems.
- The approach might extend to other supervised learning settings with policy-induced distribution shifts, such as search ranking or advertising.
- If the variational bound tightly approximates the criterion, it could inspire similar bounds for other information-theoretic objectives in representation learning.
Load-bearing premise
The observational recommendation logs contain identifiable causal components whose isolation via the proposed information-theoretic criterion yields better generalization, without requiring knowledge of the full causal graph or additional interventions.
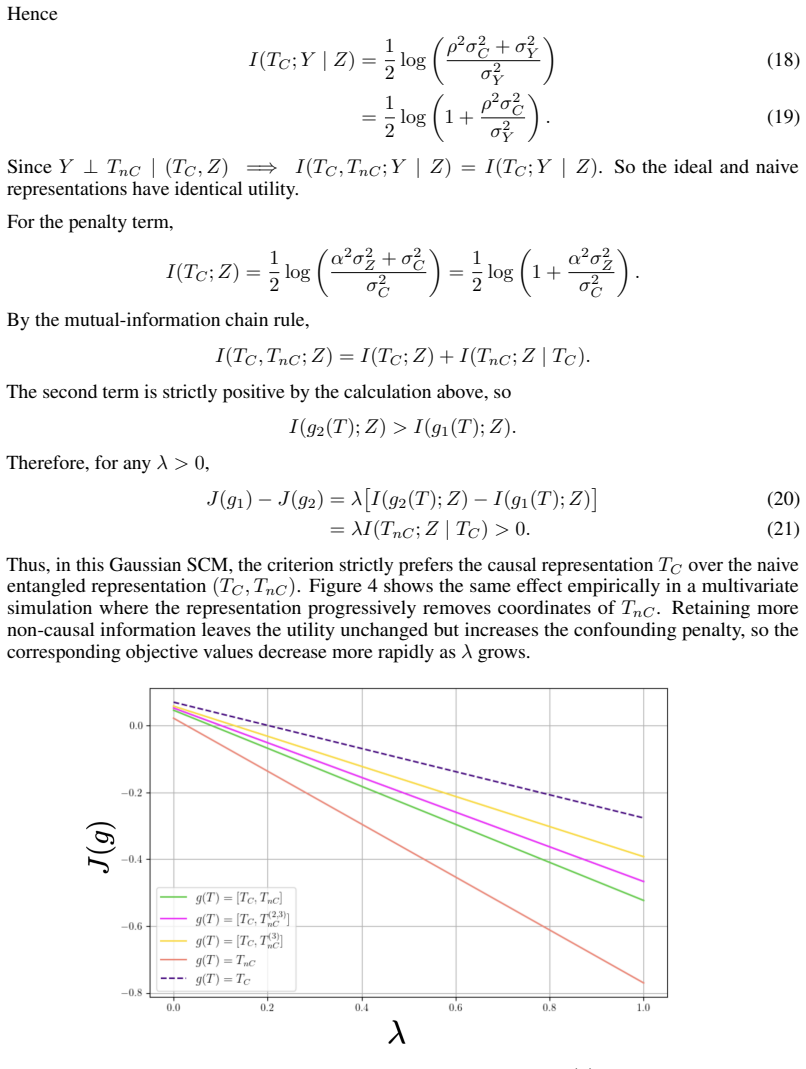
What would settle it
Apply the method to a synthetic benchmark with known causal structure and verify whether the learned representations depend only on the causal factors rather than confounders, or run production A/B tests that show no lift in engagement metrics.
Figures
read the original abstract
Predictive models trained on observational data often fail to generalise to the distributions they encounter when deployed, especially when the training data is a product of the system being optimised. Recommender systems are a canonical example: they are trained on interaction logs confounded by the deployed policy, past user behaviour, and platform filtering. As a result, the training distribution differs substantially from the candidate distribution scored at serving time, a gap that makes offline metrics unreliable predictors of online performance. We address the distribution shift problem with a method motivated by causal representation learning (CRL). We propose an information-theoretic disentanglement criterion and prove that its optimum depends only on the causal components of the input. We then derive a tractable variational lower bound that makes the criterion optimisable from finite observational data alone. The scope of our method is narrower than that of much of the CRL literature, in that we target better generalisation under distribution shift, not full identification of all latent causal factors. This narrower target is what makes the method practical, requiring only the existing confounded logs, applying to any standard supervised model, and adding no inference-time cost. Our headline evaluation is an A/B test with millions of users on Spotify, applied to a production ranker for personalised playlist generation. A capacity-matched CRL variant performed on par offline but delivered substantial online gains in listener engagement. Complementary evidence on the public KuaiRand recommendation dataset and a synthetic benchmark with known causal structure shows the same pattern: offline parity with baseline, gains under distribution shift. Across all three settings, adding our causal disentanglement objective yields meaningfully better out-of-distribution generalisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an information-theoretic disentanglement criterion for causal representation learning in recommender systems to address distribution shift from policy-confounded observational logs. It claims to prove that the optimum of this criterion depends only on the causal components of the input, derives a tractable variational lower bound optimizable from finite observational data alone without interventions or full causal graphs, and reports improved out-of-distribution generalization, including substantial online gains in an A/B test on Spotify's production playlist ranker alongside results on KuaiRand and a synthetic benchmark.
Significance. If the central theoretical claims hold, the work provides a practical, narrower-scope CRL method that augments standard supervised models for better generalization under recsys distribution shift while adding no inference cost. The large-scale A/B test with millions of users and the pattern of offline parity but online gains across settings constitute strong empirical evidence of utility; the explicit proof attempt and variational bound derivation are notable strengths if they withstand scrutiny on assumptions.
major comments (2)
- [Abstract and theoretical development (proof of optimality)] Abstract and theoretical development (proof of optimality): the claim that the criterion optimum depends only on causal components must be checked against the data-generating assumptions; if the derivation operates solely on a single confounded observational distribution without explicit multiple environments or interventions, it risks failing to separate non-causal factors that drive the policy-induced shift, contrary to standard CRL identifiability requirements.
- [Section deriving the variational lower bound] Section deriving the variational lower bound: the construction and optimization details are needed to verify that the bound remains independent of fitting choices in the observational data and does not embed circular dependence on quantities that could reintroduce non-causal components; without these, the tractability claim and generalization guarantee cannot be assessed.
minor comments (2)
- Clarify notation for the information-theoretic criterion and ensure all steps in the bound derivation are explicitly numbered and cross-referenced.
- In the evaluation sections, report exact effect sizes and confidence intervals for the online A/B metrics alongside the offline parity results for full transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the theoretical foundations of our approach. We address each point below and are prepared to revise the manuscript for greater clarity on assumptions and derivations while preserving the core claims, which we believe hold under the policy-confounded observational setting described in the paper.
read point-by-point responses
-
Referee: Abstract and theoretical development (proof of optimality): the claim that the criterion optimum depends only on causal components must be checked against the data-generating assumptions; if the derivation operates solely on a single confounded observational distribution without explicit multiple environments or interventions, it risks failing to separate non-causal factors that drive the policy-induced shift, contrary to standard CRL identifiability requirements.
Authors: The proof in Section 3.1 is derived under an explicit structural causal model for recommender systems in which the sole source of distribution shift is the deployed policy (modeled as a selection mechanism on observed interactions). In this setting the information-theoretic criterion is shown to be optimized precisely when non-causal factors that are functions of the policy are excluded from the representation; the proof does not invoke multiple environments because the invariance target is defined with respect to this single, well-specified shift. This narrower scope is stated explicitly in the abstract and introduction. We will add a dedicated paragraph in Section 2 clarifying the data-generating assumptions and contrasting them with the stronger identifiability conditions of general CRL. revision: partial
-
Referee: Section deriving the variational lower bound: the construction and optimization details are needed to verify that the bound remains independent of fitting choices in the observational data and does not embed circular dependence on quantities that could reintroduce non-causal components; without these, the tractability claim and generalization guarantee cannot be assessed.
Authors: Section 3.2 derives the variational lower bound directly from the observational joint distribution using a standard evidence lower bound with an auxiliary variational distribution over the latent representation; the resulting expression contains no explicit dependence on the policy or on any non-causal quantities beyond those present in the logged data. Optimization is performed end-to-end with the primary recommendation loss and does not require estimating the policy or any other auxiliary model. The explicit form of the bound, its gradient, and the training procedure appear in the appendix. To address the request for additional verification we will expand the main-text derivation with an intermediate step showing independence from policy-related terms and include a short proof sketch that no circular dependence is introduced. revision: yes
Circularity Check
No circularity: derivation introduces new criterion and bound without reducing to fitted inputs or self-citations
full rationale
The abstract and description present a new information-theoretic disentanglement criterion whose claimed optimum property is stated as a proof result, followed by derivation of a variational lower bound for optimization on observational data. No equations, self-citations, or prior author results are quoted that would make the optimum or bound equivalent to inputs by construction. The narrower scope (better generalization under shift, not full identification) is explicitly distinguished from broader CRL literature, and no load-bearing uniqueness theorem or ansatz from overlapping authors appears. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observational recommendation logs are generated by a causal structure containing identifiable causal components separate from policy confounders.
Reference graph
Works this paper leans on
-
[1]
URL https://www.nature.com/articles/ s44387-026-00105-2
doi: 10.1038/s44387-026-00105-2. URL https://www.nature.com/articles/ s44387-026-00105-2. Jianfeng Deng, Qingfeng Chen, Debo Cheng, Jiuyong Li, Lin Liu, and Xiaojing Du. Mitigating dual latent confounding biases in recommender systems.arXiv preprint arXiv:2410.12451, 2024. Introduces IViDR: instrumental-variable-based debiased recommendation. Yorgos Felek...
-
[2]
Deployed in Taobao display advertising production system since July 2022
doi: 10.1145/3583780.3615496. Deployed in Taobao display advertising production system since July 2022. Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. DeepFM: A factorization- machine based neural network for CTR prediction. InInternational Joint Conference on Artificial Intelligence (IJCAI), 2017. Shonosuke Harada and Hisashi Kashima...
-
[3]
Released as “NISE” in the authors’ code repository
doi: 10.1145/3640457.3688151. Released as “NISE” in the authors’ code repository. 10 Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. Unbiased learning-to-rank with biased feedback. InProceedings of the 10th ACM International Conference on Web Search and Data Mining (WSDM), 2017. Jean Kaddour, Yuchen Zhu, Qi Liu, Matt J. Kusner, and Ricardo Silv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.