Distill on a Diet: Efficient Knowledge Distillation via Learnable Data Pruning
Pith reviewed 2026-06-25 21:28 UTC · model grok-4.3
The pith
IF-Beta prunes distillation data so students on subsets outperform those on the full dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IF-Beta pairs influence-function estimates of sample impact with a two-parameter Beta sampling policy that is optimized in a bilevel loop; the inner objective is a KD-aligned proxy trained in teacher feature space, and the outer loop tunes the policy to maximize final student performance, yielding subsets that produce higher-accuracy students than the full dataset at lower cost.
What carries the argument
IF-Beta: influence functions as sample-impact estimators combined with a learnable Beta-distribution sampling policy, optimized via bilevel objective whose inner loop uses KD-aligned proxy training in teacher feature space.
Load-bearing premise
Influence functions can reliably estimate how much each training sample contributes to the final student model even when only the pretrained teacher is available and no student training dynamics are computed.
What would settle it
If repeated ImageNet runs show that the highest-accuracy student obtained from an IF-Beta-pruned subset has lower top-1 accuracy than the student distilled on the full dataset, the central performance claim is falsified.
Figures



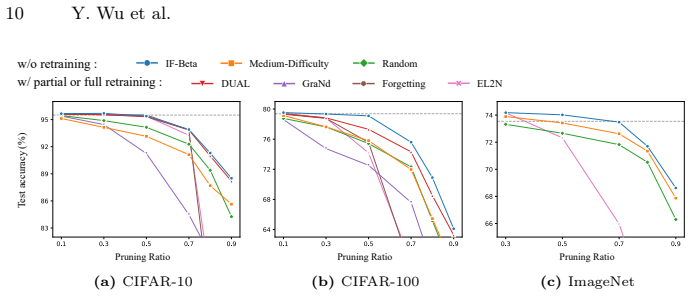
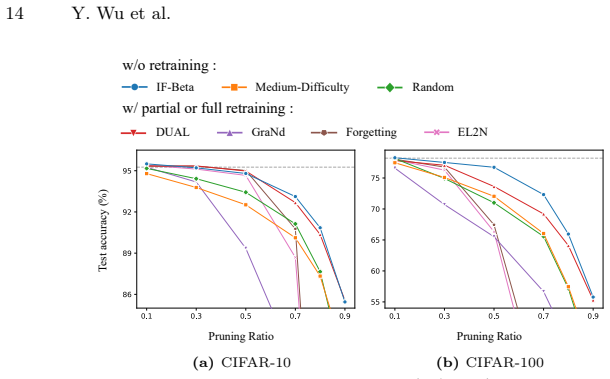

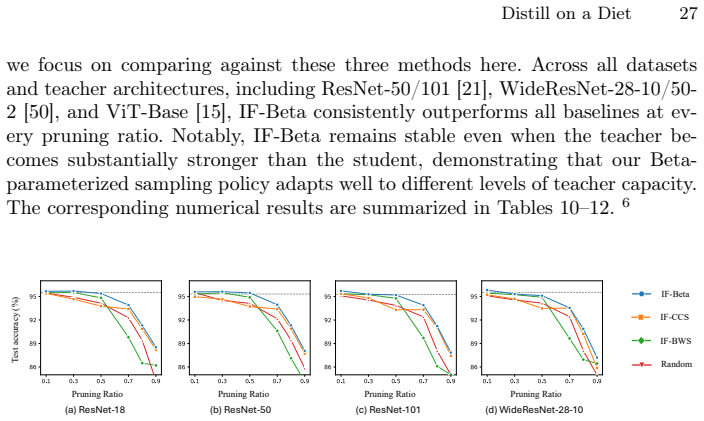

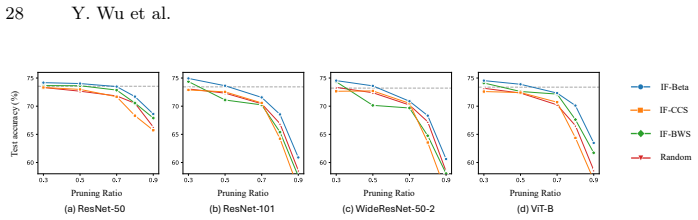

read the original abstract
Knowledge Distillation (KD) is widely used to obtain compact models for efficient inference in resource-constrained environments. Yet the computational overhead of the distillation process itself is often overlooked, raising the question of whether a better student model can be obtained with less data and less compute via data pruning. However, existing data pruning methods are not designed for KD: some introduce substantial overhead, such as obtaining training dynamics through retraining, while others rely on heuristic selection rules that fail to capture what KD actually requires, often resulting in suboptimal subsets. To address these issues, we propose IF-Beta, an efficient data pruning framework that combines influence functions with a learnable sampling policy. Empirically, we first demonstrate that influence functions can serve as an effective and efficient estimator of sample impact in KD settings, where only a pretrained teacher is available. Building on this, our sampling policy is specifically parameterized by a Beta distribution, whose highly flexible two-parameter family allows the policy to adapt to diverse pruning regimes rather than being tied to fixed heuristic forms. Next, we formulate KD pruning as optimizing this policy through a bilevel objective, where the inner loop operates in the teacher feature space with a KD-aligned objective, enabling fast proxy training, while the outer loop updates the policy parameters to maximize distillation performance. This design ensures that IF-Beta is both computationally efficient and inherently aligned with the goals of KD. Extensive experiments on CIFAR-10/100 and ImageNet show that IF-Beta consistently outperforms other baselines across a wide range of pruning ratios. Remarkably, IF-Beta enables students trained on less data and less compute to surpass the performance of students distilled on the full dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IF-Beta, a data pruning framework for knowledge distillation that estimates sample importance via influence functions and parameterizes a learnable sampling policy with a Beta distribution. The policy is optimized via bilevel optimization, with an inner loop performing fast proxy training in the teacher feature space using a KD-aligned objective and an outer loop updating the Beta parameters to maximize distillation performance. Experiments on CIFAR-10/100 and ImageNet report that the method outperforms baselines across pruning ratios and that students trained on the pruned subsets can exceed the performance of those trained on the full dataset.
Significance. If the empirical claims hold with proper validation, this work could meaningfully reduce the compute required for knowledge distillation while maintaining or improving student performance, which is practically relevant for resource-constrained deployment. The bilevel formulation that keeps the teacher frozen and aligns the proxy with KD objectives, together with the flexible two-parameter Beta policy, represents a coherent technical contribution over heuristic pruning methods.
major comments (3)
- [§3.1] §3.1: The claim that influence functions serve as an effective estimator of sample impact for KD (with only a pretrained teacher available) is load-bearing for the entire pipeline, yet the manuscript provides no quantitative validation such as Spearman correlation between influence scores and actual leave-one-out changes in the KD loss; without this, the subsequent Beta-parameterized bilevel optimization may be optimizing a misaligned proxy.
- [Experiments] Experiments (tables reporting CIFAR/ImageNet accuracies): No error bars, standard deviations across random seeds, or statistical significance tests are supplied for the accuracy comparisons, including the headline result that pruned subsets surpass full-dataset KD performance; this omission prevents reliable assessment of whether observed gains are robust.
- [§3.3] §3.3 (bilevel objective): The inner-loop proxy is stated to use a 'KD-aligned objective' in teacher feature space, but the precise loss (combination of hard labels and soft targets, temperature, weighting) relative to the outer-loop student KD loss is not specified, making it impossible to verify that the policy optimization is truly aligned with the claimed goal.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the range of pruning ratios tested and the exact baselines compared against.
- [§3] Notation for the Beta distribution parameters (α, β) and how they map to the sampling probabilities should be introduced earlier and used consistently in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify key aspects of the manuscript. We address each major point below and commit to revisions that strengthen the empirical validation, statistical reporting, and methodological transparency without altering the core contributions.
read point-by-point responses
-
Referee: [§3.1] §3.1: The claim that influence functions serve as an effective estimator of sample impact for KD (with only a pretrained teacher available) is load-bearing for the entire pipeline, yet the manuscript provides no quantitative validation such as Spearman correlation between influence scores and actual leave-one-out changes in the KD loss; without this, the subsequent Beta-parameterized bilevel optimization may be optimizing a misaligned proxy.
Authors: We agree that direct quantitative validation of influence functions as estimators would strengthen the foundation of the pipeline. The current manuscript relies on end-to-end performance gains as indirect evidence of their utility in the KD setting. In revision, we will add a targeted analysis (e.g., Spearman rank correlation between IF scores and leave-one-out KD loss changes on a held-out subset of CIFAR-10) to Section 3.1, confirming alignment before the bilevel optimization. revision: yes
-
Referee: [Experiments] Experiments (tables reporting CIFAR/ImageNet accuracies): No error bars, standard deviations across random seeds, or statistical significance tests are supplied for the accuracy comparisons, including the headline result that pruned subsets surpass full-dataset KD performance; this omission prevents reliable assessment of whether observed gains are robust.
Authors: This is a valid observation; the reported tables lack measures of variability. We will rerun all main experiments across at least three random seeds, report mean accuracies with standard deviations, and add statistical significance tests (e.g., paired t-tests against baselines) for key comparisons. Updated tables will appear in the revised experimental section. revision: yes
-
Referee: [§3.3] §3.3 (bilevel objective): The inner-loop proxy is stated to use a 'KD-aligned objective' in teacher feature space, but the precise loss (combination of hard labels and soft targets, temperature, weighting) relative to the outer-loop student KD loss is not specified, making it impossible to verify that the policy optimization is truly aligned with the claimed goal.
Authors: We acknowledge the need for explicit formulation. The inner-loop proxy uses a feature-space KD loss that mirrors the outer-loop objective (soft targets from the frozen teacher with temperature scaling and a small hard-label term). In the revision we will insert the exact loss equation, including temperature value, weighting coefficients, and how it differs from the student KD loss, directly into §3.3. revision: yes
Circularity Check
No circularity; empirical optimization with independent performance claims
full rationale
The paper presents an empirical method (IF-Beta) that optimizes a Beta-parameterized sampling policy via bilevel optimization to maximize KD performance on a proxy objective, then reports comparative results on CIFAR/ImageNet showing pruned subsets can outperform full-dataset KD. No derivation, theorem, or closed-form prediction is claimed that reduces by construction to the fitted parameters or to self-citations. The influence-function estimator is presented as an empirical observation rather than a derived identity, and the headline performance claim is a direct experimental comparison, not a tautological output of the fit. The method is self-contained against external benchmarks with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
free parameters (1)
- Beta distribution parameters (alpha, beta)
axioms (1)
- domain assumption Influence functions can serve as an effective and efficient estimator of sample impact in KD settings, where only a pretrained teacher is available.
Reference graph
Works this paper leans on
-
[1]
Agarwal, N., Bullins, B., Hazan, E.: Second-order stochastic optimization for ma- chine learning in linear time. J. Mach. Learn. Res.18, 116:1–116:40 (2017)
2017
-
[2]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019
Ahn, S., Hu, S.X., Damianou, A.C., Lawrence, N.D., Dai, Z.: Variational informa- tion distillation for knowledge transfer. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. pp. 9163–9171. Computer Vision Foundation / IEEE (2019)
2019
-
[3]
In: Precup, D., Teh, Y.W
Arpit, D., Jastrzebski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M.S., Ma- haraj, T., Fischer, A., Courville, A.C., Bengio, Y., Lacoste-Julien, S.: A closer look at memorization in deep networks. In: Precup, D., Teh, Y.W. (eds.) Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 201...
2017
-
[4]
Bae, J., Ng, N., Lo, A., Ghassemi, M., Grosse, R.B.: If influence functions are the answer, then what is the question? In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, Nove...
2022
-
[5]
In: Forty-second International Conference on Machine Learning (2025)
Baruch,E.B.,Botach,A.,Kviatkovsky,I.,Aggarwal,M.,Medioni,G.:Distillingthe knowledge in data pruning. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[6]
In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021
Basu, S., Pope, P., Feizi, S.: Influence functions in deep learning are fragile. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net (2021)
2021
-
[7]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022
Beyer, L., Zhai, X., Royer, A., Markeeva, L., Anil, R., Kolesnikov, A.: Knowledge distillation: A good teacher is patient and consistent. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 10915–10924. IEEE (2022)
2022
-
[8]
In: Dy, J.G., Krause, A
Campbell, T., Broderick, T.: Bayesian coreset construction via greedy iterative geodesic ascent. In: Dy, J.G., Krause, A. (eds.) Proceedings of the 35th Inter- national Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stock- holm,Sweden,July10-15,2018.ProceedingsofMachineLearningResearch,vol.80, pp. 697–705. PMLR (2018)
2018
-
[9]
In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
Chen, Y., Xu, X., de Hoog, F., Liu, J., Wang, S.: Medium-difficulty samples con- stitute smoothed decision boundary for knowledge distillation on pruned datasets. In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net (2025)
2025
-
[10]
In: Proceedings of the 42th International Conference on Machine Learning, ICML
Cho, Y., Shin, B., Kang, C., Yun, C.: Lightweight dataset pruning without full training via example difficulty and prediction uncertainty. In: Proceedings of the 42th International Conference on Machine Learning, ICML. Proceedings of Ma- chine Learning Research, PMLR (2025)
2025
-
[11]
In: Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
Choi, H., Ki, N., Chung, H.W.: BWS: best window selection based on sample scores for data pruning across broad ranges. In: Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net (2024)
2024
-
[12]
ACM Trans
Clarkson, K.L.: Coresets, sparse greedy approximation, and the frank-wolfe algo- rithm. ACM Trans. Algorithms6(4), 63:1–63:30 (2010)
2010
-
[13]
Technometrics22(4), 495–508 (1980)
Cook, R.D., Weisberg, S.: Characterizations of an empirical influence function for detecting influential cases in regression. Technometrics22(4), 495–508 (1980)
1980
-
[14]
In: 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA
Deng, J., Dong, W., Socher, R., Li, L., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA. pp. 248–255. IEEE Computer Society (2009)
2009
-
[15]
In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. O...
2021
-
[16]
In: 9th International Conference on Learn- ing Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021
Foret, P., Kleiner, A., Mobahi, H., Neyshabur, B.: Sharpness-aware minimization for efficiently improving generalization. In: 9th International Conference on Learn- ing Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenRe- view.net (2021)
2021
-
[17]
Inter- national journal of computer vision129(6), 1789–1819 (2021)
Gou, J., Yu, B., Maybank, S.J., Tao, D.: Knowledge distillation: A survey. Inter- national journal of computer vision129(6), 1789–1819 (2021)
2021
-
[18]
In: Moens, M., Huang, X., Specia, L., Yih, S.W
Guo, H., Rajani, N., Hase, P., Bansal, M., Xiong, C.: Fastif: Scalable influence functions for efficient model interpretation and debugging. In: Moens, M., Huang, X., Specia, L., Yih, S.W. (eds.) Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Distill on a Diet 17 Cana, Dominican Re...
2021
-
[19]
Journal of the american statistical association69(346), 383–393 (1974)
Hampel, F.R.: The influence curve and its role in robust estimation. Journal of the american statistical association69(346), 383–393 (1974)
1974
-
[20]
In: Babai, L
Har-Peled, S., Mazumdar, S.: On coresets for k-means and k-median clustering. In: Babai, L. (ed.) Proceedings of the 36th Annual ACM Symposium on Theory of Computing, Chicago, IL, USA, June 13-16, 2004. pp. 291–300. ACM (2004)
2004
-
[21]
In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. pp. 770–778. IEEE Computer Society (2016)
2016
-
[22]
In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion,CVPR2024-Workshops,Seattle,WA,USA,June17-18,2024.pp.7713–7722
He, M., Yang, S., Huang, T., Zhao, B.: Large-scale dataset pruning with dynamic uncertainty. In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion,CVPR2024-Workshops,Seattle,WA,USA,June17-18,2024.pp.7713–7722. IEEE (2024)
2024
-
[23]
Distilling the Knowledge in a Neural Network
Hinton, G.E., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. CoRRabs/1503.02531(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., An- dreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRRabs/1704.04861(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
In: Cohn, T., He, Y., Liu, Y
Jiao,X.,Yin,Y.,Shang,L.,Jiang,X.,Chen,X.,Li,L.,Wang,F.,Liu,Q.:Tinybert: Distilling BERT for natural language understanding. In: Cohn, T., He, Y., Liu, Y. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020. Findings of ACL, vol. EMNLP 2020, pp. 4163–4174. Association for Computational Linguistics (2020)
2020
-
[26]
In: Precup, D., Teh, Y.W
Koh, P.W., Liang, P.: Understanding black-box predictions via influence functions. In: Precup, D., Teh, Y.W. (eds.) Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017. Proceedings of Machine Learning Research, vol. 70, pp. 1885–1894. PMLR (2017)
2017
-
[27]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
2009
-
[28]
In: Bartlett, P.L., Pereira, F.C.N., Burges, C.J.C., Bottou, L., Weinberger, K.Q
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep con- volutional neural networks. In: Bartlett, P.L., Pereira, F.C.N., Burges, C.J.C., Bottou, L., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems
-
[29]
Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States. pp. 1106–1114 (2012)
2012
-
[30]
In: The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Kwon, Y., Wu, E., Wu, K., Zou, J.: Datainf: Efficiently estimating data influence in lora-tuned llms and diffusion models. In: The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net (2024)
2024
-
[31]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Li, T., Zhou, P., He, Z., Cheng, X., Huang, X.: Friendly sharpness-aware minimiza- tion. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 5631–5640. IEEE (2024)
2024
-
[32]
In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T
Liang, J., Li, L., Bing, Z., Zhao, B., Tang, Y., Lin, B., Fan, H.: Efficient one pass self-distillation with zipf’s label smoothing. In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XI. Lecture Notes in Computer Sci...
2022
-
[33]
Wu et al
Moser, B.B., Shanbhag, A.S., Frolov, S., Raue, F., Folz, J., Dengel, A.: A coreset selection of coreset selection literature: Introduction and recent advances (2025) 18 Y. Wu et al
2025
-
[34]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019
Park, W., Kim, D., Lu, Y., Cho, M.: Relational knowledge distillation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. pp. 3967–3976. Computer Vision Foundation / IEEE (2019)
2019
-
[35]
In: Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin,Z.,Gimelshein,N.,Antiga,L.,Desmaison,A.,Köpf,A.,Yang,E.Z.,DeVito,Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library. In: Wallach, H.M., Larochelle, H., Beygelz...
2019
-
[36]
In: Ranzato, M., Beygelzimer, A., Dauphin, Y.N., Liang, P., Vaughan, J.W
Paul, M., Ganguli, S., Dziugaite, G.K.: Deep learning on a data diet: Finding important examples early in training. In: Ranzato, M., Beygelzimer, A., Dauphin, Y.N., Liang, P., Vaughan, J.W. (eds.) Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtua...
2021
-
[37]
In: Handbook of discrete and computational geometry, pp
Phillips, J.M.: Coresets and sketches. In: Handbook of discrete and computational geometry, pp. 1269–1288. Chapman and Hall/CRC (2017)
2017
-
[38]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Pleiss, G., Zhang, T., Elenberg, E.R., Weinberger, K.Q.: Identifying mislabeled data using the area under the margin ranking. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virt...
2020
-
[39]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Pruthi, G., Liu, F., Kale, S., Sundararajan, M.: Estimating training data influence by tracing gradient descent. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems 33: An- nual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual (2020)
2020
-
[40]
In: Bengio, Y., LeCun, Y
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets. In: Bengio, Y., LeCun, Y. (eds.) 3rd International Con- ference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings (2015)
2015
-
[41]
In: Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022
Schioppa, A., Zablotskaia, P., Vilar, D., Sokolov, A.: Scaling up influence functions. In: Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022. pp. 8179–
2022
-
[42]
In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T
Shen, Z., Xing, E.P.: A fast knowledge distillation framework for visual recogni- tion. In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision - ECCV 2022: 17th European Conference, Tel Aviv, Israel, Oc- tober 23-27, 2022, Proceedings, Part XXIV. Lecture Notes in Computer Science, vol. 13684, pp. 673–690. Springer (2022)
2022
-
[43]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Sun, S., Ren, W., Li, J., Wang, R., Cao, X.: Logit standardization in knowledge distillation. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 15731–15740. IEEE (2024)
2024
-
[44]
In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R
Sun, Z., Yu, H., Song, X., Liu, R., Yang, Y., Zhou, D.: Mobilebert: a compact task- agnostic BERT for resource-limited devices. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020. pp. 2158–2170. Association for Computati...
2020
-
[45]
In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019
Toneva, M., Sordoni, A., des Combes, R.T., Trischler, A., Bengio, Y., Gordon, G.J.: An empirical study of example forgetting during deep neural network learning. In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net (2019)
2019
-
[46]
In: Koenig, S., Jenkins, C., Taylor, M.E
Wu, Y., Jiang, J., Ye, X., Wang, Y., Zhou, C., Xu, Y., Chen, J., Hu, H., Zhang, W., Jin, C., Yuan, J., Li, Y.: Investigating data pruning for pretraining biological foundation models at scale. In: Koenig, S., Jenkins, C., Taylor, M.E. (eds.) Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innova- tive Applications of Artif...
2026
-
[47]
In: Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
Xia, M., Malladi, S., Gururangan, S., Arora, S., Chen, D.: LESS: selecting influen- tial data for targeted instruction tuning. In: Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net (2024)
2024
-
[48]
In: The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
Yang, S., Xie, Z., Peng, H., Xu, M., Sun, M., Li, P.: Dataset pruning: Reducing training data by examining generalization influence. In: The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[49]
OpenReview.net (2023)
2023
-
[50]
In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023
Yang, Z., Zeng, A., Li, Z., Zhang, T., Yuan, C., Li, Y.: From knowledge distillation to self-knowledge distillation: A unified approach with normalized loss and cus- tomized soft labels. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 17139–17148. IEEE (2023)
2023
-
[51]
In: Proceedings of the 42th International Conference on Machine Learning, ICML
Ye, X., Wu, Y., Zhang, W., Jin, C., Chen, Y.: Towards robust influence functions with flat validation minima. In: Proceedings of the 42th International Conference on Machine Learning, ICML. Proceedings of Machine Learning Research, PMLR (2025)
2025
-
[52]
In: British Machine Vision Conference 2016
Zagoruyko, S., Komodakis, N.: Wide residual networks. In: British Machine Vision Conference 2016. British Machine Vision Association (2016)
2016
-
[53]
In: 5th In- ternational Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In: 5th In- ternational Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net (2017)
2017
-
[54]
In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition
Zhao, B., Cui, Q., Song, R., Qiu, Y., Liang, J.: Decoupled knowledge distillation. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 11953–11962 (2022)
2022
-
[55]
In: The Eleventh International Conference on Learning Representa- tions, ICLR 2023, Kigali, Rwanda, May 1-5, 2023
Zheng, H., Liu, R., Lai, F., Prakash, A.: Coverage-centric coreset selection for high pruning rates. In: The Eleventh International Conference on Learning Representa- tions, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net (2023)
2023
-
[56]
Distill on a Diet: Efficient Knowledge Distillation via Learnable Data Pruning
Zhou, X., Pi, R., Zhang, W., Lin, Y., Chen, Z., Zhang, T.: Probabilistic bilevel coreset selection. In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvári, C., Niu, G., Sabato, S. (eds.) International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA. Proceedings of Machine Learning Research, vol. 162, pp. 27287–27302. PML...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.