Breaking the Likelihood Trap: Variance-Calibrated Modulation for Large Language Model Decoding
Pith reviewed 2026-06-26 10:29 UTC · model grok-4.3
The pith
Variance-Calibrated Modulation reshapes LLM output probabilities before truncation to reduce repetition and dullness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Variance-Calibrated Modulation mitigates the likelihood trap by applying a pre-decoding reshape that combines PMI-based contextual searchlight to suppress stopwords and elevate context tokens with adaptive self-debiasing that uses real-time logit standard deviation for scale-invariant penalization, yielding higher diversity, coherence, and reasoning accuracy especially at elevated temperatures.
What carries the argument
Variance-Calibrated Modulation (VCM), a pre-decoding intervention that applies Contextual Searchlight via PMI and Adaptive Self-Debiasing driven by logit standard deviation.
If this is right
- Existing truncation methods such as Top-p or Min-p receive a pre-adjusted distribution that reduces over-sampling from the uncalibrated head.
- Fixed scalar repetition penalties become unnecessary because the adaptive term already accounts for varying logit scales across steps.
- Reasoning accuracy at higher temperatures improves because the modulation maintains coherence while still allowing exploration.
- The intervention adds negligible overhead and therefore can be inserted into any existing decoding pipeline without retraining.
Where Pith is reading between the lines
- The same logit-variance signal might be usable in other calibration settings such as length-controlled generation or safety filtering.
- Because the method is scale-invariant it could transfer across model families that differ in logit magnitude without retuning.
- If logit variance correlates with uncertainty, VCM may incidentally reduce hallucination rates on factual tasks.
Load-bearing premise
Real-time logit standard deviation supplies a reliable scale-invariant signal for penalization that preserves semantic coherence without task-specific tuning.
What would settle it
A controlled comparison on open-ended generation benchmarks at temperature 1.2 that measures whether adding VCM to Top-p decoding raises both diversity metrics and human coherence ratings relative to the same baseline without VCM.
Figures

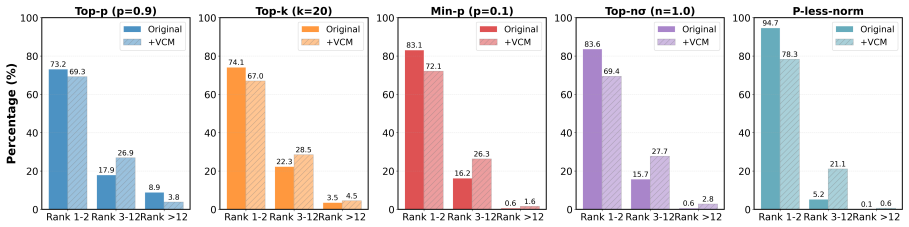
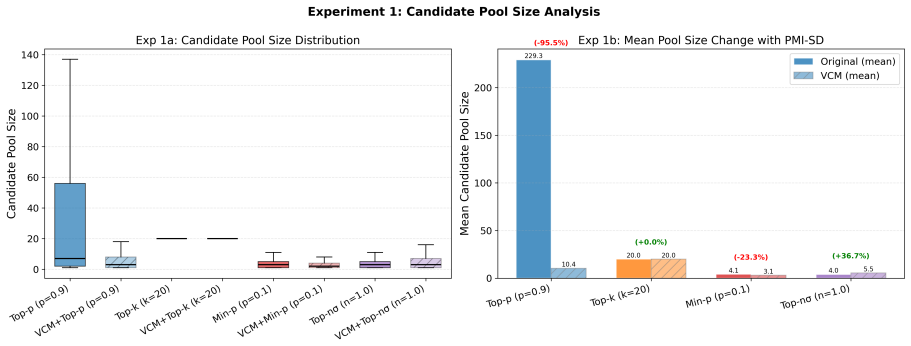
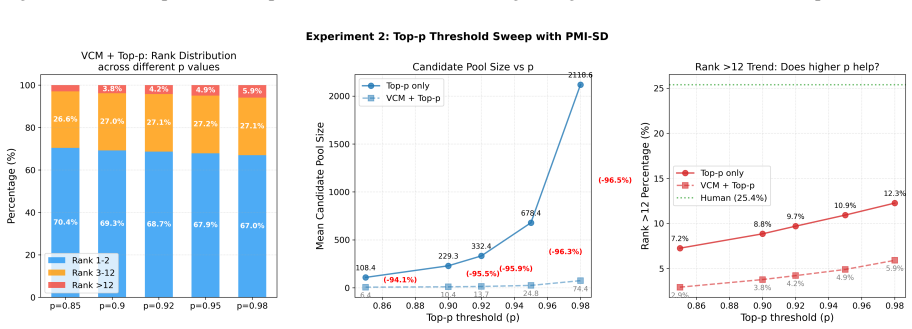
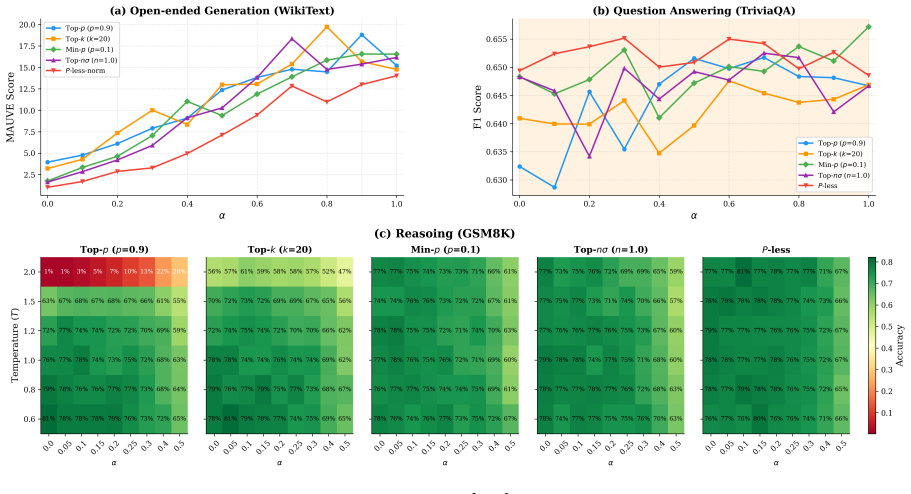
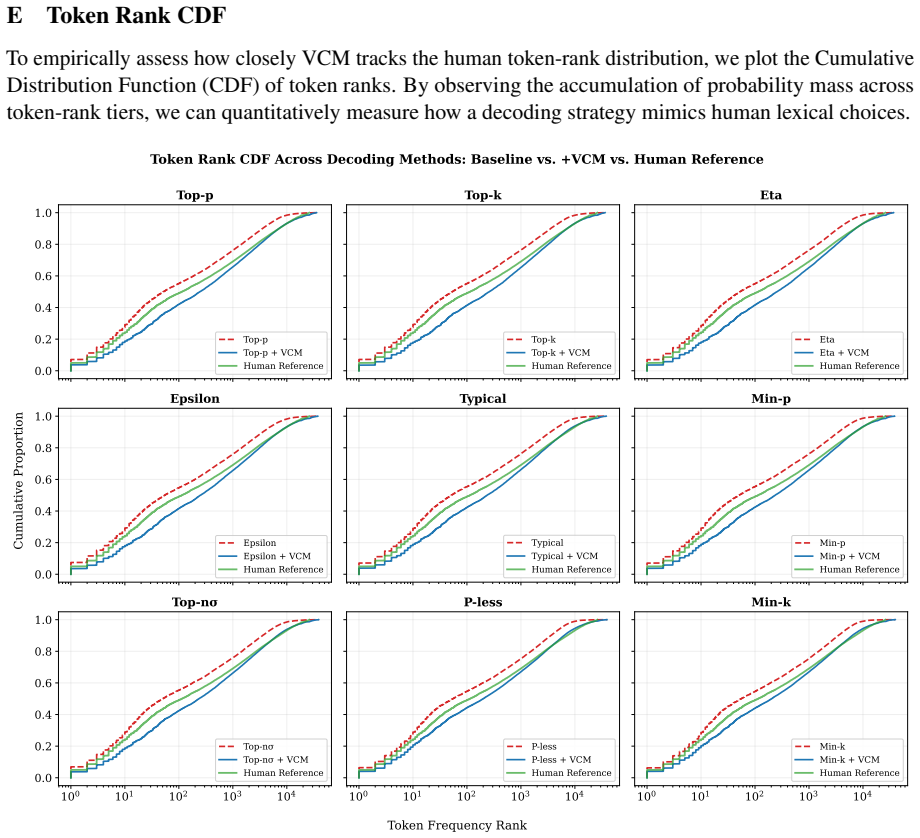
read the original abstract
In open-ended generation, LLMs frequently fall into the "likelihood trap", marked by repetitive degeneration and vocabulary dullness, creating a discrepancy between machine-generated and human-written text. While post-hoc tail truncation (e.g., Top-$p$, Min-$p$) avoids sampling from the unreliable tail, it can over-sample from the uncalibrated head and misalign generation with human lexical preferences; fixed scalar repetition penalties likewise ignore variation in logit scale across inference steps, potentially disrupting semantic coherence. To address both limitations, we propose Variance-Calibrated Modulation (VCM), a training-free pre-decoding intervention that reshapes the probability distribution before truncation through two dynamic mechanisms: (1) Contextual Searchlight via PMI, which suppresses global stopwords while elevating context-evoked tokens, and (2) Adaptive Self-Debiasing, which uses real-time logit standard deviation for scale-invariant penalization. Across open-ended generation, factual QA, and mathematical reasoning, VCM consistently mitigates the likelihood trap. With negligible computational overhead, VCM integrates with existing decoding strategies, improving diversity, coherence, and, particularly at higher decoding temperatures, reasoning accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Variance-Calibrated Modulation (VCM), a training-free pre-decoding intervention to mitigate the 'likelihood trap' in LLMs, where generation exhibits repetitive degeneration and vocabulary dullness. VCM reshapes the distribution before truncation via two mechanisms: Contextual Searchlight, which uses PMI to suppress global stopwords while elevating context-evoked tokens, and Adaptive Self-Debiasing, which applies penalization based on real-time logit standard deviation. The authors claim that VCM improves diversity, coherence, and reasoning accuracy (especially at higher temperatures) across open-ended generation, factual QA, and mathematical reasoning when integrated with existing strategies, at negligible computational cost.
Significance. If the empirical results hold with proper controls, VCM would offer a practical, parameter-free addition to the decoding toolkit that addresses shortcomings of fixed repetition penalties and tail-truncation methods. The training-free design and compatibility with existing strategies are strengths that could see adoption in production generation systems.
major comments (2)
- [Adaptive Self-Debiasing] Adaptive Self-Debiasing section: the central assumption that real-time logit standard deviation supplies a reliable scale-invariant penalization signal (preserving coherence without task-specific tuning) is stated without derivation, invariance proof, or sensitivity analysis to temperature, context length, or model scale. This assumption is load-bearing for the claim that the method requires no post-hoc adjustments.
- [Abstract] Abstract and results overview: the manuscript asserts 'consistent' improvements in diversity, coherence, and high-temperature reasoning accuracy but supplies no quantitative metrics, baseline comparisons, statistical significance tests, or implementation details in the abstract or high-level description, preventing evaluation of the central empirical claim.
minor comments (1)
- Notation for the PMI-based modulation and the exact form of the std-dev penalization should be formalized with equations to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Adaptive Self-Debiasing] Adaptive Self-Debiasing section: the central assumption that real-time logit standard deviation supplies a reliable scale-invariant penalization signal (preserving coherence without task-specific tuning) is stated without derivation, invariance proof, or sensitivity analysis to temperature, context length, or model scale. This assumption is load-bearing for the claim that the method requires no post-hoc adjustments.
Authors: We acknowledge the absence of a formal derivation or invariance proof for using logit standard deviation as the penalization signal. In revision we will add a dedicated sensitivity analysis subsection reporting performance across temperatures (0.5–2.0), context lengths (128–2048 tokens), and model scales (7B–70B). This empirical validation will support the claim of no task-specific tuning. A closed-form proof is not currently available and would require additional theoretical work beyond the scope of the present study. revision: partial
-
Referee: [Abstract] Abstract and results overview: the manuscript asserts 'consistent' improvements in diversity, coherence, and high-temperature reasoning accuracy but supplies no quantitative metrics, baseline comparisons, statistical significance tests, or implementation details in the abstract or high-level description, preventing evaluation of the central empirical claim.
Authors: The abstract follows standard length constraints and defers quantitative detail to the experimental sections. To address the concern we will revise the abstract to include concrete metrics (e.g., relative diversity gains and high-temperature accuracy improvements) together with a brief statement that all comparisons include statistical significance testing. revision: yes
Circularity Check
No circularity: VCM mechanisms defined from standard PMI and logit std dev quantities
full rationale
The paper defines Variance-Calibrated Modulation directly via two mechanisms—Contextual Searchlight via PMI and Adaptive Self-Debiasing using real-time logit standard deviation—without any fitting of parameters to data subsets, self-citations that bear the central claim, or reductions where an output is constructed as its own input. These are presented as training-free interventions built from pre-existing statistical quantities, with no equations or steps that rename or derive the result from itself. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Logit standard deviation at each step provides a meaningful scale for repetition penalization that does not harm coherence
- domain assumption PMI can be computed on-the-fly to reliably distinguish context-evoked tokens from global stopwords
Reference graph
Works this paper leans on
-
[1]
Hierarchical Neural Story Generation
Fan, Angela and Lewis, Mike and Dauphin, Yann. Hierarchical Neural Story Generation. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1082
-
[2]
International Conference on Learning Representations(ICLR 2020) , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations(ICLR 2020) , year=
2020
-
[3]
International Conference on Learning Representations(ICLR 2025) , year=
Turning up the heat: Min-p sampling for creative and coherent llm outputs , author=. International Conference on Learning Representations(ICLR 2025) , year=
2025
-
[4]
Top- n : Eliminating Noise in Logit Space for Robust Token Sampling of LLM
Tang, Chenxia and Liu, Jianchun and Xu, Hongli and Huang, Liusheng. Top- n : Eliminating Noise in Logit Space for Robust Token Sampling of LLM. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.528
-
[5]
Alpacaeval: An automatic evaluator of instruction-following models , author=
-
[6]
DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention , author=
-
[7]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[8]
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems
Ling, Wang and Yogatama, Dani and Dyer, Chris and Blunsom, Phil. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1015
-
[9]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[10]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[11]
The Twelfth International Conference on Learning Representations (ICLR 2024) , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations (ICLR 2024) , year=
2024
-
[12]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[13]
Truncation Sampling as Language Model Desmoothing
Hewitt, John and Manning, Christopher and Liang, Percy. Truncation Sampling as Language Model Desmoothing. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.249
-
[14]
International Conference on Learning Representations (ICLR 2021) , year=
Mirostat: A neural text decoding algorithm that directly controls perplexity , author=. International Conference on Learning Representations (ICLR 2021) , year=
2021
-
[15]
Accessed: 2024-03-17 , year=
Is there an optimal temperature and top-p for code generation with paid LLM APIs? , author=. Accessed: 2024-03-17 , year=
2024
-
[16]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[17]
Cognitive science , volume=
A learning algorithm for Boltzmann machines , author=. Cognitive science , volume=. 1985 , publisher=
1985
-
[18]
Chen, Honghua and Ding, Nai. Probing the ``Creativity'' of Large Language Models: Can models produce divergent semantic association?. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.858
-
[19]
arXiv preprint arXiv:2405.13012 , year=
Divergent creativity in humans and large language models , author=. arXiv preprint arXiv:2405.13012 , year=
-
[20]
2025 , url=
Openai api documentation , author=. 2025 , url=
2025
-
[21]
arXiv e-prints , pages=
Estimating llm uncertainty with logits , author=. arXiv e-prints , pages=
-
[22]
2024 , journal=
Haw-Shiuan Chang and Nanyun Peng and Mohit Bansal and Anil Ramakrishna and Tagyoung Chung , title=. 2024 , journal=
2024
-
[23]
Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation
Garces Arias, Esteban and Rodemann, Julian and Li, Meimingwei and Heumann, Christian and A enmacher, Matthias. Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.885
-
[24]
Ding, Yuanhao and Garces Arias, Esteban and Li, Meimingwei and Rodemann, Julian and A enmacher, Matthias and Chen, Danlu and Fan, Gaojuan and Heumann, Christian and Zhang, Chongsheng. GUARD : Glocal Uncertainty-Aware Robust Decoding for Effective and Efficient Open-Ended Text Generation. Findings of the Association for Computational Linguistics: EMNLP 202...
-
[25]
Zhou, Yuxuan and Keuper, Margret and Fritz, Mario. Balancing Diversity and Risk in LLM Sampling: How to Select Your Method and Parameter for Open-Ended Text Generation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1278
-
[26]
G2: Guided Generation for Enhanced Output Diversity in LLM s
Ruan, Zhiwen and Li, Yixia and Liu, Yefeng and Chen, Yun and Luo, Weihua and Li, Peng and Liu, Yang and Chen, Guanhua. G2: Guided Generation for Enhanced Output Diversity in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.713
-
[27]
Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation
Garces Arias, Esteban and Li, Meimingwei and Heumann, Christian and Assenmacher, Matthias. Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[28]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[29]
International Conference on Learning Representations (ICLR 2020) , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations (ICLR 2020) , year=
2020
-
[30]
Forty-first International Conference on Machine Learning (ICML 2024) , year=
Improving Open-Ended Text Generation via Adaptive Decoding , author=. Forty-first International Conference on Machine Learning (ICML 2024) , year=
2024
-
[31]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=
-
[32]
2026 , eprint=
Min- k Sampling: Decoupling Truncation from Temperature Scaling via Relative Logit Dynamics , author=. 2026 , eprint=
2026
-
[33]
Advances in Neural Information Processing Systems , volume=
A contrastive framework for neural text generation , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
International Conference on Learning Representations (ICLR) , year=
The Curious Case of Neural Text Degeneration , author=. International Conference on Learning Representations (ICLR) , year=
-
[35]
Contrastive Decoding: Open-ended Text Generation as Optimization
Li, Xiang Lisa and Holtzman, Ari and Fried, Daniel and Liang, Percy and Eisner, Jason and Hashimoto, Tatsunori and Zettlemoyer, Luke and Lewis, Mike. Contrastive Decoding: Open-ended Text Generation as Optimization. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.a...
-
[36]
Relating Neural Text Degeneration to Exposure Bias
Chiang, Ting-Rui and Chen, Yun-Nung. Relating Neural Text Degeneration to Exposure Bias. Proceedings of the Fourth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. 2021. doi:10.18653/v1/2021.blackboxnlp-1.16
-
[37]
Forty-first International Conference on Machine Learning , year=
Improving Open-Ended Text Generation via Adaptive Decoding , author=. Forty-first International Conference on Machine Learning , year=
-
[38]
Li, Wenhao and Yi, Xiaoyuan and Hu, Jinyi and Sun, Maosong and Xie, Xing. Evade the Trap of Mediocrity: Promoting Diversity and Novelty in Text Generation via Concentrating Attention. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.745
-
[39]
Look-back Decoding for Open-Ended Text Generation
Xu, Nan and Zhou, Chunting and Celikyilmaz, Asli and Ma, Xuezhe. Look-back Decoding for Open-Ended Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.66
-
[40]
Penalty Decoding: Well Suppress the Self-Reinforcement Effect in Open-Ended Text Generation
Zhu, Wenhong and Hao, Hongkun and Wang, Rui. Penalty Decoding: Well Suppress the Self-Reinforcement Effect in Open-Ended Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.78
-
[41]
Understanding the Repeat Curse in Large Language Models from a Feature Perspective
Yao, Junchi and Yang, Shu and Xu, Jianhua and Hu, Lijie and Li, Mengdi and Wang, Di. Understanding the Repeat Curse in Large Language Models from a Feature Perspective. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.406
-
[42]
Runyan Tan and Shuang Wu and Phillip Howard , booktitle=. \ p. 2026 , url=
2026
-
[43]
TruthfulQA: Measuring how models mimic human falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[44]
T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[45]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[46]
Freitag, Markus and Ghorbani, Behrooz and Fernandes, Patrick. Epsilon Sampling Rocks: Investigating Sampling Strategies for Minimum B ayes Risk Decoding for Machine Translation. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.617
-
[47]
Meister, Clara and Pimentel, Tiago and Wiher, Gian and Cotterell, Ryan. Locally Typical Sampling. Transactions of the Association for Computational Linguistics. 2023. doi:10.1162/tacl_a_00536
-
[48]
Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation
Garces Arias, Esteban and Li, Meimingwei and Heumann, Christian and A enmacher, Matthias. Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[49]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[50]
Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =
Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
2021
-
[51]
International Conference on Learning Representations , year=
Neural Text Generation With Unlikelihood Training , author=. International Conference on Learning Representations , year=
-
[52]
A diversity-promoting objective function for neural conversation models
Li, Jiwei and Galley, Michel and Brockett, Chris and Gao, Jianfeng and Dolan, Bill. A Diversity-Promoting Objective Function for Neural Conversation Models. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. doi:10.18653/v1/N16-1014
-
[53]
Forty-first International Conference on Machine Learning , year=
Stay on Topic with Classifier-Free Guidance , author=. Forty-first International Conference on Machine Learning , year=
-
[54]
Nandwani, Yatin and Kumar, Vineet and Raghu, Dinesh and Joshi, Sachindra and Lastras, Luis. Pointwise Mutual Information Based Metric and Decoding Strategy for Faithful Generation in Document Grounded Dialogs. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.639
-
[55]
2024 , eprint=
REAL Sampling: Boosting Factuality and Diversity of Open-Ended Generation via Asymptotic Entropy , author=. 2024 , eprint=
2024
-
[56]
2019 , eprint=
CTRL: A Conditional Transformer Language Model for Controllable Generation , author=. 2019 , eprint=
2019
-
[57]
Luo, Wen and Song, Feifan and Li, Wei and Peng, Guangyue and Wei, Shaohang and Wang, Houfeng. Odysseus Navigates the Sirens' Song: Dynamic Focus Decoding for Factual and Diverse Open-Ended Text Generation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1320
-
[58]
Proceedings of the National Academy of Sciences , volume =
Alex Reinhart and Ben Markey and Michael Laudenbach and Kachatad Pantusen and Ronald Yurko and Gordon Weinberg and David West Brown , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.2422455122 , abstract =
-
[59]
D. AI Argues Differently: Distinct Argumentative and Linguistic Patterns of LLM s in Persuasive Contexts. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1755
-
[60]
Zanotto, Sergio E. and Aroyehun, Segun. Linguistic and Embedding-Based Profiling of Texts Generated by Humans and Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1163
-
[61]
Learn-to-Distance: Distance Learning for Detecting
Hongyi Zhou and Jin Zhu and Kai Ye and Ying Yang and Erhan Xu and Chengchun Shi , booktitle=. Learn-to-Distance: Distance Learning for Detecting. 2026 , url=
2026
-
[62]
Proceedings of the 20th Workshop of Young Researchers' Roundtable on Spoken Dialogue Systems. 2024
2024
-
[63]
Conversational XAI and Explanation Dialogues
Feldhus, Nils. Conversational XAI and Explanation Dialogues. 2024
2024
-
[64]
Enhancing Emotion Recognition in Spoken Dialogue Systems through Multimodal Integration and Personalization
Kaneko, Takumasa. Enhancing Emotion Recognition in Spoken Dialogue Systems through Multimodal Integration and Personalization. 2024
2024
-
[65]
Towards Personalisation of User Support Systems
Higuchi, Tomoya. Towards Personalisation of User Support Systems. 2024
2024
-
[66]
Social Agents for Positively Influencing Human Psychological States
Baihaqi, Muhammad Yeza. Social Agents for Positively Influencing Human Psychological States. 2024
2024
-
[67]
Personalized Topic Transition for Dialogue System
Yoshida, Kai. Personalized Topic Transition for Dialogue System. 2024
2024
-
[68]
Elucidation of Psychotherapy and Development of New Treatment Methods Using AI
Maeda, Shio. Elucidation of Psychotherapy and Development of New Treatment Methods Using AI. 2024
2024
-
[69]
Assessing Interactional Competence with Multimodal Dialog Systems
Saeki, Mao. Assessing Interactional Competence with Multimodal Dialog Systems. 2024
2024
-
[70]
Faithfulness of Natural Language Generation
Schmidtova, Patricia. Faithfulness of Natural Language Generation. 2024
2024
-
[71]
Knowledge-Grounded Dialogue Systems for Generating Interesting and Engaging Responses
Onozeki, Hiroki. Knowledge-Grounded Dialogue Systems for Generating Interesting and Engaging Responses. 2024
2024
-
[72]
Towards a Dialogue System That Can Take Interlocutors ' Values into Account
Zenimoto, Yuki. Towards a Dialogue System That Can Take Interlocutors ' Values into Account. 2024
2024
-
[73]
Multimodal Spoken Dialogue System with Biosignals
Katada, Shun. Multimodal Spoken Dialogue System with Biosignals. 2024
2024
-
[74]
Timing Sensitive Turn-Taking in Spoken Dialogue Systems Based on User Satisfaction
Yoshikawa, Sadahiro. Timing Sensitive Turn-Taking in Spoken Dialogue Systems Based on User Satisfaction. 2024
2024
-
[75]
Towards Robust and Multilingual Task-Oriented Dialogue Systems
Ohashi, Atsumoto. Towards Robust and Multilingual Task-Oriented Dialogue Systems. 2024
2024
-
[76]
Toward Faithful Dialogs: Evaluating and Improving the Faithfulness of Dialog Systems
Huang, Sicong. Toward Faithful Dialogs: Evaluating and Improving the Faithfulness of Dialog Systems. 2024
2024
-
[77]
Cognitive Model of Listener Response Generation and Its Application to Dialogue Systems
Mori, Taiga. Cognitive Model of Listener Response Generation and Its Application to Dialogue Systems. 2024
2024
-
[78]
Topological Deep Learning for Term Extraction
Ruppik, Benjamin Matthias. Topological Deep Learning for Term Extraction. 2024
2024
-
[79]
Dialogue Management with Graph-structured Knowledge
Walker, Nicholas Thomas. Dialogue Management with Graph-structured Knowledge. 2024
2024
-
[80]
Towards a Co-creation Dialogue System
Zhou, Xulin. Towards a Co-creation Dialogue System. 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.