GenTS: A Comprehensive Benchmark Library for Generative Time Series Models
Pith reviewed 2026-05-20 13:11 UTC · model grok-4.3
The pith
GenTS provides a benchmark library built specifically for generative time series models rather than discriminative ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GenTS is a benchmark library that supplies a unified data preprocessing pipeline, a collection of versatile generative models, panoramic evaluation metrics, and a modular architecture so that researchers can run systematic assessments of models that learn time series distributions rather than direct mappings.
What carries the argument
The modular design that links a shared preprocessing stage, interchangeable generative models, and a wide set of distribution-aware metrics into one extensible workflow.
If this is right
- Evaluations of generative time series models become reproducible across synthesis, forecasting, and imputation tasks.
- Model selection decisions can rest on side-by-side results instead of isolated published numbers.
- Gaps in current generative approaches become visible when the same metrics are applied to many models.
- New models can be inserted into the pipeline without rebuilding the evaluation stack.
Where Pith is reading between the lines
- The same library structure could be adapted to other sequential data types such as event streams or spatial-temporal records.
- Standardized generative benchmarks may shorten the cycle from new model proposal to comparative testing.
- Industry teams working with irregular time series could adopt the preprocessing layer as a common starting point.
Load-bearing premise
The modular structure will let outside researchers add new datasets and models without friction and that the reported experiments will give stable guidance on model choice.
What would settle it
A follow-up study that adds several new datasets and models and finds the library requires major code changes or that the original benchmark rankings reverse under different random seeds or task definitions.
Figures





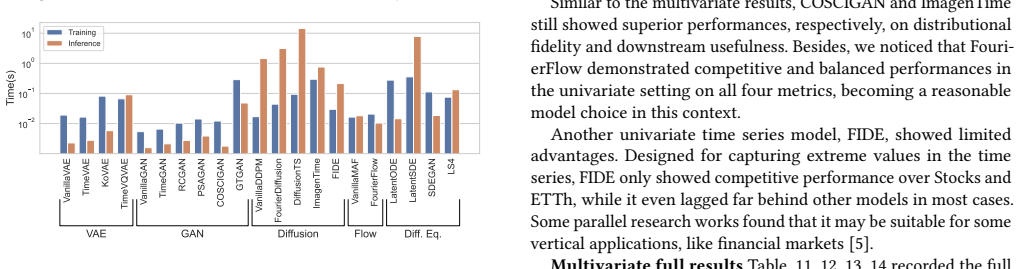
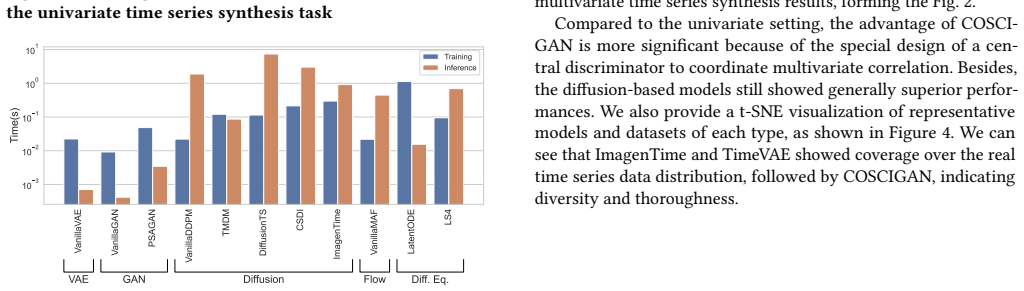
read the original abstract
Generative models have demonstrated remarkable potential in time series analysis tasks, like synthesis, forecasting, imputation, etc. However, offering limited coverage for generative models, existing time series libraries are mainly engineered for discriminative models, with standardized workflows for specific tasks, such as optimizing Mean Squared Errors for time series forecasting. This rigid structure is fundamentally incompatible with the distinct and often complex paradigms of generative models (e.g., adversarial training, diffusion processes), which learn the underlying data distribution rather than a direct input-output mapping. To this end, we proposed GenTS, a comprehensive and extensible benchmark library designed for systematic assessment on generative time series models. GenTS features a unified data preprocessing pipeline, a collection of versatile models, and panoramic evaluation metrics. Its modular design also enables the researchers to flexibly customize beyond our built-in datasets and models. Based on GenTS, we conducted benchmarking experiments under diverse tasks, accordingly offering suggestions for model selection and identifying potential directions for future research. Our codes are open-source at https://github.com/WillWang1113/GenTS. The official tutorials and document are available at https://willwang1113.github.io/GenTS/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GenTS, a comprehensive and extensible benchmark library for generative time series models. It features a unified data preprocessing pipeline, a collection of versatile models supporting paradigms such as adversarial training and diffusion processes, panoramic evaluation metrics, and a modular design for customization beyond built-in datasets and models. Based on the library, the authors conduct benchmarking experiments under diverse tasks (synthesis, forecasting, imputation) and provide model selection suggestions, with open-source code and tutorials available.
Significance. If the library's modular components are correctly implemented and the benchmarking experiments are executed with consistent training protocols and statistical rigor, GenTS could address a clear gap in existing time series libraries that focus primarily on discriminative models. It would offer a standardized, extensible framework for evaluating generative models that learn data distributions rather than direct mappings, potentially enabling more reliable comparisons and future research directions. The open-source release strengthens reproducibility.
major comments (2)
- [Benchmarking Experiments] Benchmarking experiments section: The manuscript describes the experimental setup at a high level but supplies no quantitative results, error analysis, ablation studies on hyperparameter sensitivity, multiple random seeds with significance testing, or explicit verification that the modular components preserve generative training dynamics (e.g., adversarial or diffusion processes) without hidden task-specific tweaks. This directly undermines the central claim that the experiments yield reliable suggestions for model selection, as identical data splits, comparable training budgets, and appropriate distribution-matching metrics are not demonstrated.
- [Library Design] Library design and evaluation metrics: While the unified preprocessing pipeline and panoramic metrics are presented as compatible with generative paradigms, the manuscript does not include concrete examples or validation showing that these metrics (rather than point-wise losses) are applied consistently across synthesis, imputation, and forecasting tasks, which is load-bearing for claims of systematic assessment.
minor comments (2)
- [Abstract] Abstract: The claim of 'panoramic evaluation metrics' would benefit from a brief enumeration of the specific metrics used (e.g., distribution divergence measures) to clarify their suitability for generative tasks.
- [Introduction] The GitHub link and documentation URL are provided but should be verified for accessibility and accompanied by a brief description of the repository structure in the main text for reader convenience.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below. Where the comments identify areas needing additional rigor or clarity, we have incorporated revisions into the next version of the manuscript.
read point-by-point responses
-
Referee: [Benchmarking Experiments] Benchmarking experiments section: The manuscript describes the experimental setup at a high level but supplies no quantitative results, error analysis, ablation studies on hyperparameter sensitivity, multiple random seeds with significance testing, or explicit verification that the modular components preserve generative training dynamics (e.g., adversarial or diffusion processes) without hidden task-specific tweaks. This directly undermines the central claim that the experiments yield reliable suggestions for model selection, as identical data splits, comparable training budgets, and appropriate distribution-matching metrics are not demonstrated.
Authors: We acknowledge that the current manuscript presents the benchmarking experiments primarily at a descriptive level to emphasize the library's modularity and extensibility. To strengthen the empirical foundation for our model selection suggestions, the revised manuscript will include comprehensive quantitative results across synthesis, forecasting, and imputation tasks. These additions will feature performance tables with distribution-matching metrics, error analysis, ablation studies on hyperparameter sensitivity, results aggregated over multiple random seeds with statistical significance testing, and explicit documentation of consistent data splits and training budgets. We will also add verification examples (including code references) confirming that the modular components preserve the core dynamics of adversarial and diffusion-based training without unintended task-specific alterations. These changes directly address the concerns about reliability and comparability. revision: yes
-
Referee: [Library Design] Library design and evaluation metrics: While the unified preprocessing pipeline and panoramic metrics are presented as compatible with generative paradigms, the manuscript does not include concrete examples or validation showing that these metrics (rather than point-wise losses) are applied consistently across synthesis, imputation, and forecasting tasks, which is load-bearing for claims of systematic assessment.
Authors: We agree that explicit validation is essential to substantiate the compatibility claims. The revised manuscript will include new concrete examples and validation subsections. These will demonstrate, with sample code snippets and illustrative outputs, how the panoramic metrics (focused on distribution matching) are applied uniformly across the three tasks, in contrast to point-wise losses. We will also show that the unified preprocessing pipeline supports generative paradigms without introducing inconsistencies. This addition will provide the necessary evidence for the systematic assessment framework. revision: yes
Circularity Check
No circularity: library and benchmarking claims are directly verifiable
full rationale
The paper introduces GenTS as an open-source benchmark library with unified preprocessing, models, metrics, and modular design, plus experimental results from diverse tasks. No mathematical derivations, equations, predictions, or first-principles results exist that could reduce to inputs by construction. Claims rest on the released code and described setup rather than self-referential definitions or self-citation chains. This matches the default non-circular case for software/benchmark contributions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GenTS features a unified data preprocessing pipeline, a collection of versatile models, and panoramic evaluation metrics. Its modular design also enables the researchers to flexibly customize beyond our built-in datasets and models.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we focus on three major and common time series generation tasks... Time Series Synthesis... Forecasting... Imputation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shya- mal Anadkat, et al . 2024. Gpt-4 technical report. arXiv:2303.08774 [cs.CL] https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Ahmed Alaa, Alex James Chan, and Mihaela van der Schaar. 2021. Genera- tive Time-series Modeling with Fourier Flows. In International Conference on Learning Representations. https://openreview.net/forum?id=PpshD0AXfA
work page 2021
-
[3]
Alexander Alexandrov, Konstantinos Benidis, Michael Bohlke-Schneider, Valentin Flunkert, Jan Gasthaus, Tim Januschowski, Danielle C. Maddix, Syama Ran- gapuram, David Salinas, Jasper Schulz, Lorenzo Stella, Ali Caner Türkmen, and Yuyang Wang. 2020. GluonTS: Probabilistic and Neural Time Series Mod- eling in Python. Journal of Machine Learning Research 21,...
work page 2020
-
[4]
Yihao Ang, Qiang Huang, Yifan Bao, Anthony K. H. Tung, and Zhiyong Huang
-
[5]
TSGBench: Time Series Generation Benchmark. Proc. VLDB Endow. 17, 3 (Nov. 2023), 305–318. doi:10.14778/3632093.3632097
- [6]
-
[7]
Nicolas Bonneel, Julien Rabin, Gabriel Peyré, and Hanspeter Pfister. 2015. Sliced and radon wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision 51, 1 (2015), 22–45
work page 2015
-
[8]
Andrew Brock, Jeff Donahue, and Karen Simonyan. 2019. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In International Conference on Learning Representations. https://openreview.net/forum?id=B1xsqj09Fm
work page 2019
-
[9]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud
-
[10]
Neural ordinary differential equations. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (Montréal, Canada) (NIPS’18). Curran Associates Inc., Red Hook, NY, USA, 6572–6583
-
[11]
Jonathan Crabbé, Nicolas Huynh, Jan Stanczuk, and Mihaela Van Der Schaar
-
[12]
In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria) (ICML’24)
Time series diffusion in the frequency domain. In Proceedings of the 41st International Conference on Machine Learning (Vienna, Austria) (ICML’24). JMLR.org, Article 374, 32 pages
- [13]
-
[14]
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. 2017. Density estimation using Real NVP. InInternational Conference on Learning Representations. https: //openreview.net/forum?id=HkpbnH9lx
work page 2017
-
[15]
Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs
Cristóbal Esteban, Stephanie L. Hyland, and Gunnar Rätsch. 2017. Real- valued (Medical) Time Series Generation with Recurrent Conditional GANs. arXiv:1706.02633 [stat.ML] https://arxiv.org/abs/1706.02633
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
2019.Unsupervised scalable representation learning for multivariate time series
Jean-Yves Franceschi, Aymeric Dieuleveut, and Martin Jaggi. 2019.Unsupervised scalable representation learning for multivariate time series. Curran Associates Inc., Red Hook, NY, USA
work page 2019
-
[17]
Asadullah Hill Galib, Pang-Ning Tan, and Lifeng Luo. 2024. Fide: Frequency- inflated conditional diffusion model for extreme-aware time series generation. Advances in Neural Information Processing Systems 37 (2024), 114434–114457
work page 2024
-
[18]
Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle
-
[19]
MADE: Masked Autoencoder for Distribution Estimation. In Proceedings of the 32nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 37), Fran- cis Bach and David Blei (Eds.). PMLR, Lille, France, 881–889. https: //proceedings.mlr.press/v37/germain15.html
-
[20]
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarial nets. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2 (Montreal, Canada) (NIPS’14). MIT Press, Cambridge, MA, USA, 2672–2680
work page 2014
-
[21]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature 645, 8081 (Sept. 2025), 633–638. doi:10.1038/s41586-025-09422-z
-
[22]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840– 6851
work page 2020
-
[23]
Paul Jeha, Michael Bohlke-Schneider, Pedro Mercado, Shubham Kapoor, Ra- jbir Singh Nirwan, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. 2022. PSA-GAN: Progressive self attention GANs for synthetic time series. InThe tenth international conference on learning representations
work page 2022
-
[24]
Jinsung Jeon, Jeonghak Kim, Haryong Song, Seunghyeon Cho, and Noseong Park
-
[25]
Advances in Neural Information Processing Systems 35 (2022), 36999– 37010
Gt-gan: General purpose time series synthesis with generative adversarial networks. Advances in Neural Information Processing Systems 35 (2022), 36999– 37010
work page 2022
-
[26]
Patrick Kidger, James Foster, Xuechen Li, and Terry Lyons. 2021. Efficient and accurate gradients for neural SDEs. In Proceedings of the 35th International Conference on Neural Information Processing Systems (NIPS ’21). Curran Asso- ciates Inc., Red Hook, NY, USA, Article 1433, 15 pages
work page 2021
-
[27]
Patrick Kidger, James Foster, Xuechen Li, and Terry J Lyons. 2021. Neural SDEs as Infinite-Dimensional GANs. In Proceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, 5453–5463. https: //proceedings.mlr.press/v139/kidger21b.html
work page 2021
-
[28]
Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling
Diederik P. Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling. 2016. Improved variational inference with inverse autoregressive flow. InProceedings of the 30th International Conference on Neural Information Processing Systems (Barcelona, Spain) (NIPS’16). Curran Associates Inc., Red Hook, NY, USA, 4743–4751
work page 2016
-
[29]
Diederik P Kingma and Max Welling. 2022. Auto-Encoding Variational Bayes. arXiv:1312.6114 [stat.ML] https://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Marcel Kollovieh, Abdul Fatir Ansari, Michael Bohlke-Schneider, Jasper Zschieg- ner, Hao Wang, and Yuyang Bernie Wang. 2023. Predict, refine, synthesize: Self-guiding diffusion models for probabilistic time series forecasting. Advances in Neural Information Processing Systems 36 (2023), 28341–28364
work page 2023
-
[31]
Daesoo Lee, Sara Malacarne, and Erlend Aune. 2023. Vector Quantized Time Series Generation with a Bidirectional Prior Model. In Proceedings of The 26th International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 206), Francisco Ruiz, Jennifer Dy, and Jan-Willem van de Meent (Eds.). PMLR, 7665–7693. ht...
work page 2023
-
[32]
Xuechen Li, Ting-Kam Leonard Wong, Ricky T. Q. Chen, and David Duvenaud
-
[33]
Scalable Gradients for Stochastic Differential Equations. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 108), Silvia Chiappa and Roberto Calandra (Eds.). PMLR, 3870–3882. https://proceedings.mlr.press/ v108/li20i.html
-
[34]
Yuxin Li, Wenchao Chen, Xinyue Hu, Bo Chen, Baolin Sun, and Mingyuan Zhou
-
[35]
In The Twelfth International Conference on Learning Representations
Transformer-modulated diffusion models for probabilistic multivariate time series forecasting. In The Twelfth International Conference on Learning Representations
-
[36]
Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. 2022. Non-stationary transformers: Exploring the stationarity in time series forecasting. Advances in neural information processing systems 35 (2022), 9881–9893
work page 2022
- [37]
-
[38]
Ilan Naiman, Nimrod Berman, Itai Pemper, Idan Arbiv, Gal Fadlon, and Omri Azencot. 2024. Utilizing image transforms and diffusion models for generative modeling of short and long time series. In Proceedings of the 38th International Conference on Neural Information Processing Systems (Vancouver, BC, Canada) (NIPS ’24). Curran Associates Inc., Red Hook, NY...
work page 2024
-
[39]
Benjamin Erichson, Pu Ren, Michael W
Ilan Naiman, N. Benjamin Erichson, Pu Ren, Michael W. Mahoney, and Omri Azencot. 2024. Generative Modeling of Regular and Irregular Time Series Data via Koopman VAEs. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=eY7sLb0dVF
work page 2024
-
[40]
Alexander Nikitin, Letizia Iannucci, and Samuel Kaski. 2024. TSGM: a flexible framework for generative modeling of synthetic time series. Advances in Neural Information Processing Systems 37 (2024), 129042–129061
work page 2024
-
[41]
George Papamakarios, Theo Pavlakou, and Iain Murray. 2017. Masked autore- gressive flow for density estimation. In Proceedings of the 31st International Conference on Neural Information Processing Systems (Long Beach, California, USA) (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 2335–2344
work page 2017
-
[42]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Transform- ers. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV). 4172–4182. doi:10.1109/ICCV51070.2023.00387
- [43]
-
[44]
Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland Vollgraf. 2021. Autore- gressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting. In Proceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, 8857–8868. https...
work page 2021
-
[45]
Ali Razavi, Aäron van den Oord, and Oriol Vinyals. 2019. Generating diverse high-fidelity images with VQ-VAE-2. Curran Associates Inc., Red Hook, NY, USA. Conference’17, July 2017, Washington, DC, USA Trovato et al
work page 2019
-
[46]
Yulia Rubanova, Ricky T. Q. Chen, and David Duvenaud. 2019. Latent ODEs for irregularly-sampled time series. Curran Associates Inc., Red Hook, NY, USA
work page 2019
-
[47]
Ali Seyfi, Jean-Francois Rajotte, and Raymond Ng. 2022. Generating multivariate time series with COmmon Source CoordInated GAN (COSCI-GAN). Advances in neural information processing systems 35 (2022), 32777–32788
work page 2022
-
[48]
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. 2021. Csdi: Con- ditional score-based diffusion models for probabilistic time series imputation. Advances in neural information processing systems 34 (2021), 24804–24816
work page 2021
-
[49]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Mil- lican, et al . 2025. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 [cs.CL] https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Aaron Van Den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu, et al . 2016. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 12 (2016), 1
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[51]
Chenxi Wang, Linxiao Yang, Zhixian Wang, Liang Sun, and Yi Wang. 2025. A Non-isotropic Time Series Diffusion Model with Moving Average Transi- tions. In Proceedings of the 42nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 267), Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Te...
work page 2025
-
[52]
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Chen Wang, Mingsheng Long, and Jianmin Wang. 2025. Deep Time Series Models: A Comprehensive Survey and Benchmark. arXiv:2407.13278 [cs.LG] https://arxiv.org/abs/2407.13278
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Jinsung Yoon, Daniel Jarrett, and Mihaela van der Schaar. 2019. Time-series Generative Adversarial Networks. InAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.), Vol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/ paper_files/paper/2019/file/c9efe5f26cd1...
work page 2019
-
[54]
Xinyu Yuan and Yan Qiao. 2024. Diffusion-TS: Interpretable Diffusion for General Time Series Generation. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=4h1apFjO99
work page 2024
-
[55]
Jiawen Zhang, Xumeng Wen, Zhenwei Zhang, Shun Zheng, Jia Li, and Jiang Bian
-
[56]
In NeurIPS Datasets and Benchmarks Track
ProbTS: Benchmarking Point and Distributional Forecasting across Diverse Prediction Horizons. In NeurIPS Datasets and Benchmarks Track
-
[57]
Linqi Zhou, Michael Poli, Winnie Xu, Stefano Massaroli, and Stefano Er- mon. 2023. Deep Latent State Space Models for Time-Series Generation. In Proceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jona...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.