Don't Forget Your Embeddings: Robust Knowledge Erasure via Precise Editing of Embeddings
Pith reviewed 2026-06-28 10:35 UTC · model grok-4.3
The pith
Precise editing of token embeddings is necessary for robust erasure of concepts from language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
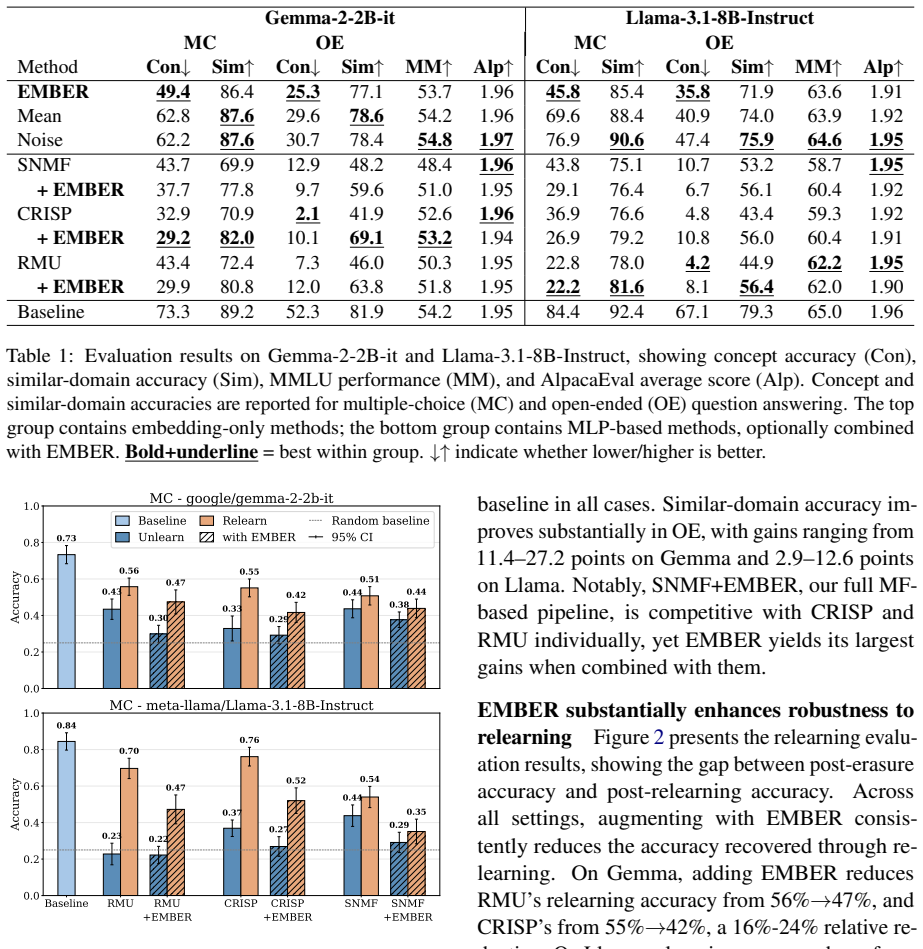
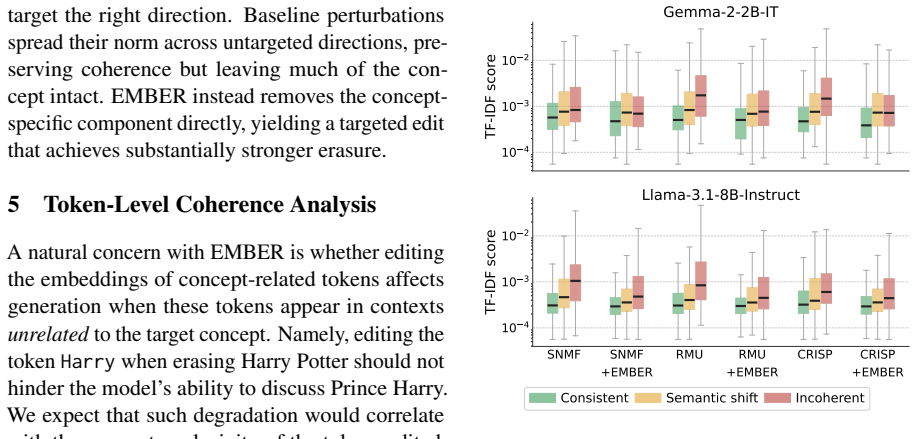
The paper establishes that precise embedding-level intervention is necessary for robust concept erasure. By augmenting existing parameter-update methods with a sparse matrix factorization module applied to token embeddings, erasure efficacy and specificity improve across task formats while coherence loss stays minimal. Robustness to relearning increases markedly, with regained accuracy dropping to as low as 35% on Llama-3.1-8B-Instruct compared to 70-76% without the embedding edit.
What carries the argument
EMBER, a plug-and-play erasure module that leverages Sparse Matrix Factorization to isolate and remove concept-related features from token embeddings.
If this is right
- Augmenting existing methods with EMBER consistently improves erasure efficacy and specificity.
- Relearning robustness improves, limiting regained accuracy to 35% on Llama versus 70-76% for prior methods.
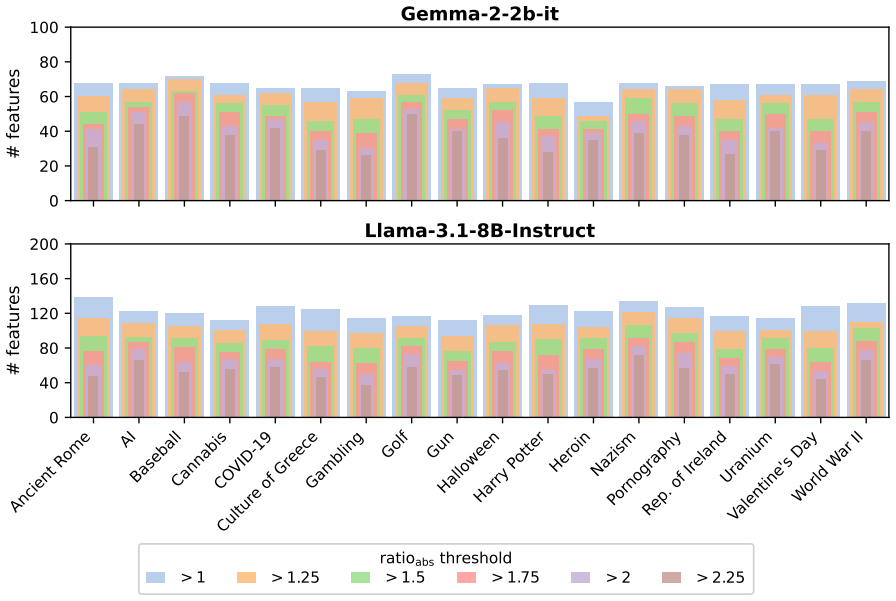
- Coherence cost is localized to a small set of concept-exclusive tokens.
- Results hold across diverse concepts evaluated on Gemma-2-2B-it and Llama-3.1-8B-Instruct.
Where Pith is reading between the lines
- Embedding representations may encode concepts in a way that is more directly editable than internal parameters.
- Relearning attacks might exploit retained embedding features even after higher-layer edits.
- Similar sparse factorization approaches could be tested on other model components for enhanced erasure.
Load-bearing premise
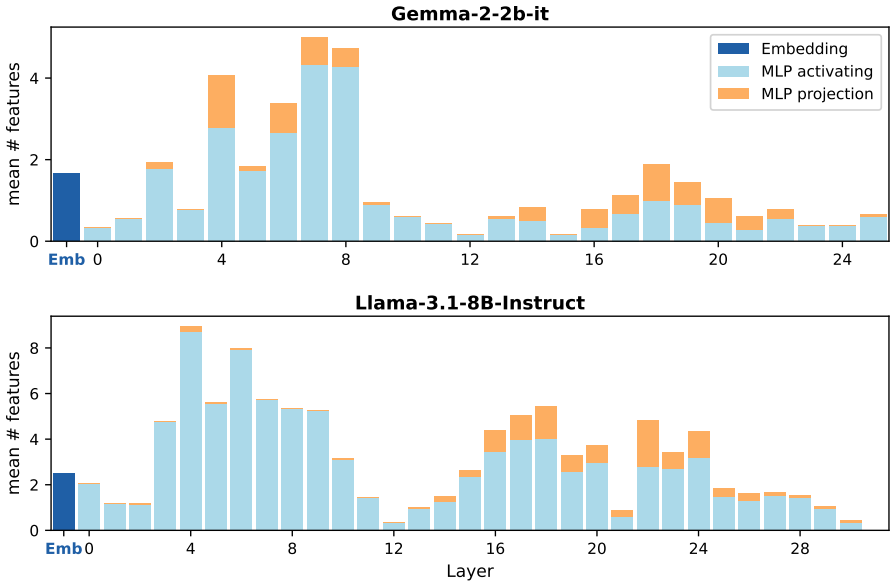
The features associated with a concept are sparse enough and linearly separable enough in the embedding space that they can be factored out without broadly impacting other concepts or model behavior.
What would settle it
Observing that models augmented with EMBER still regain high accuracy on erased concepts after relearning attempts, or that coherence degrades across many unrelated tokens, would indicate the embedding intervention does not provide the claimed robustness.
Figures



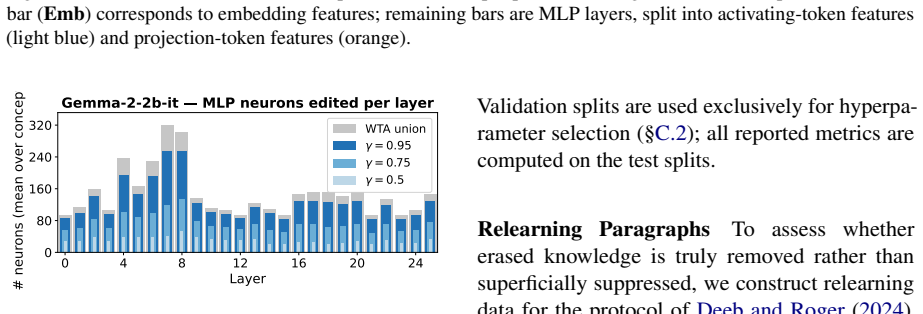


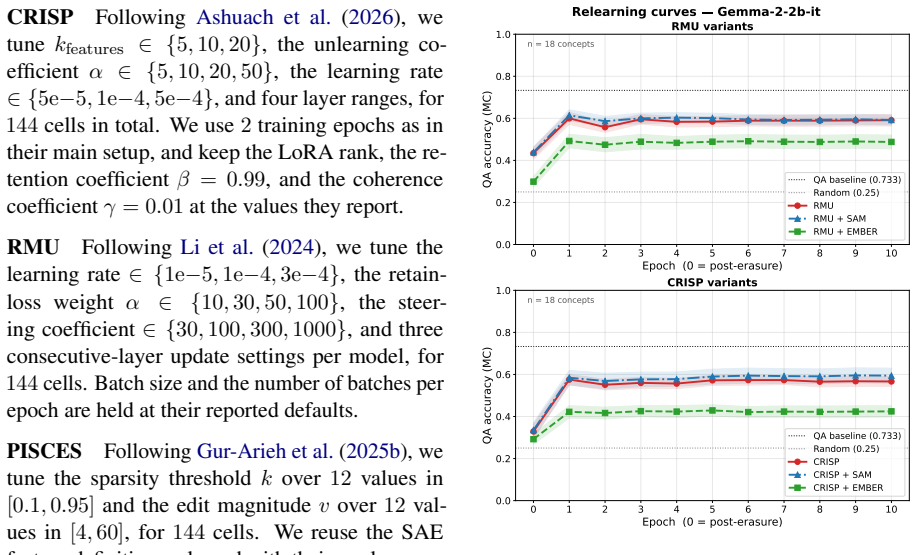
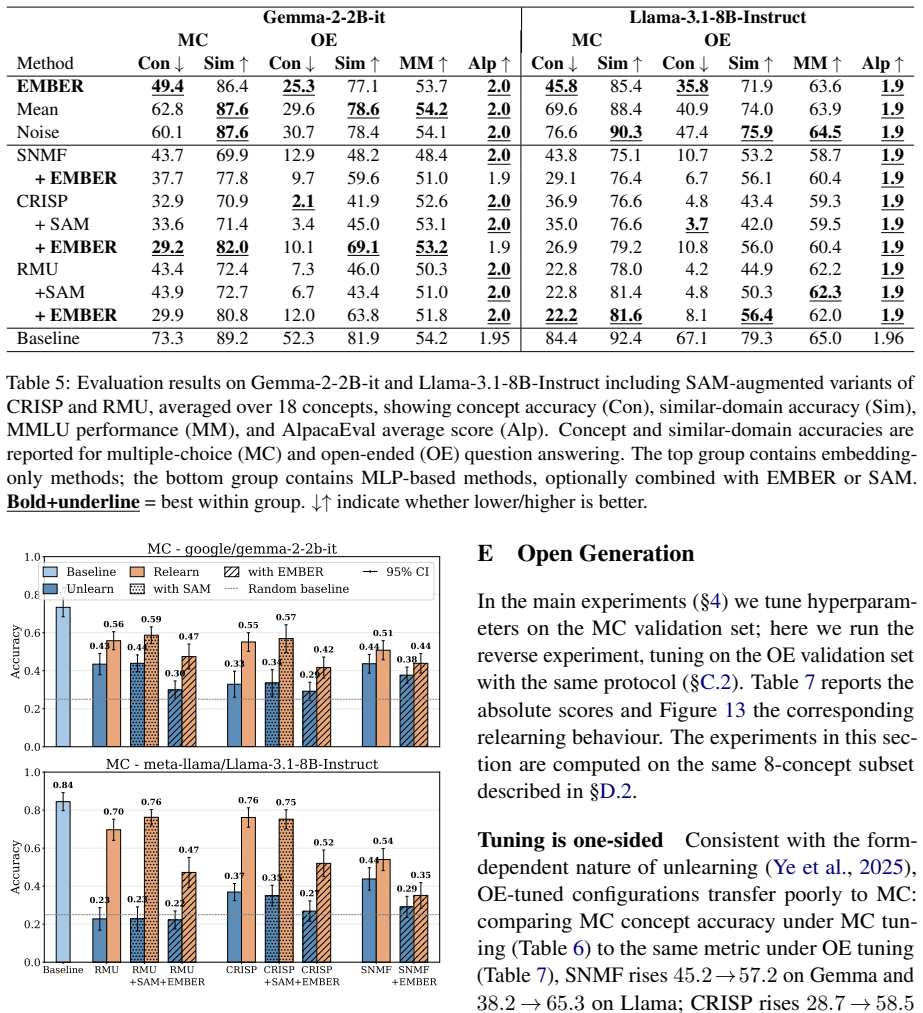
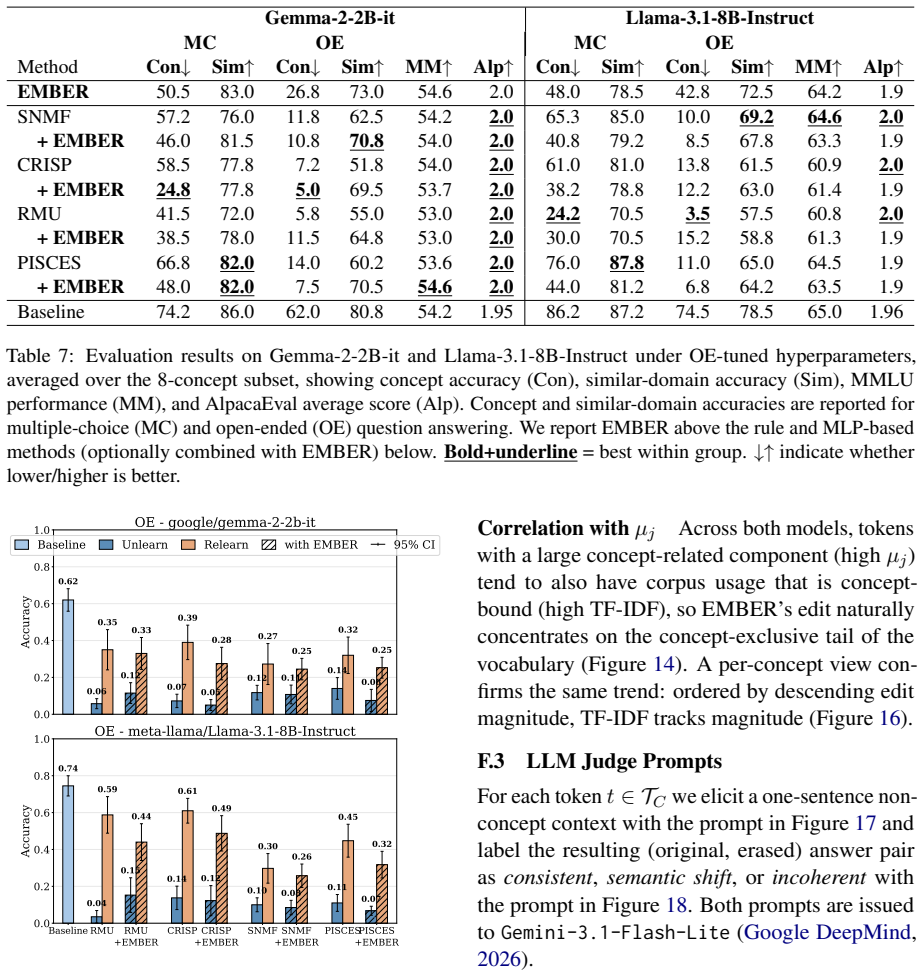
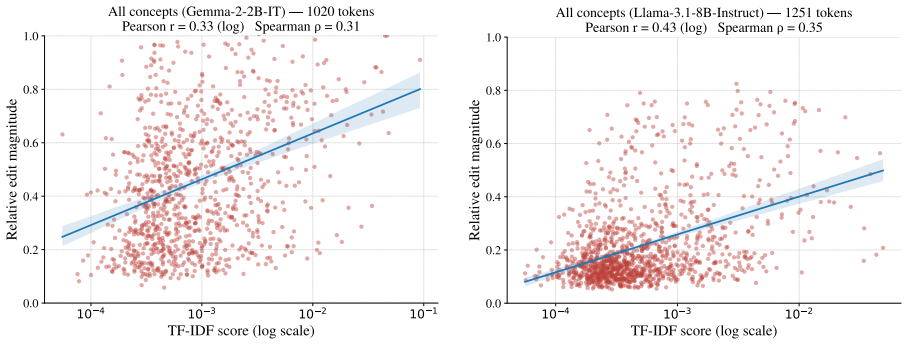
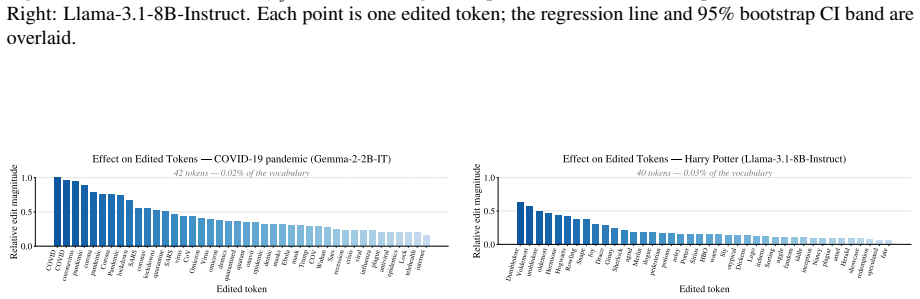
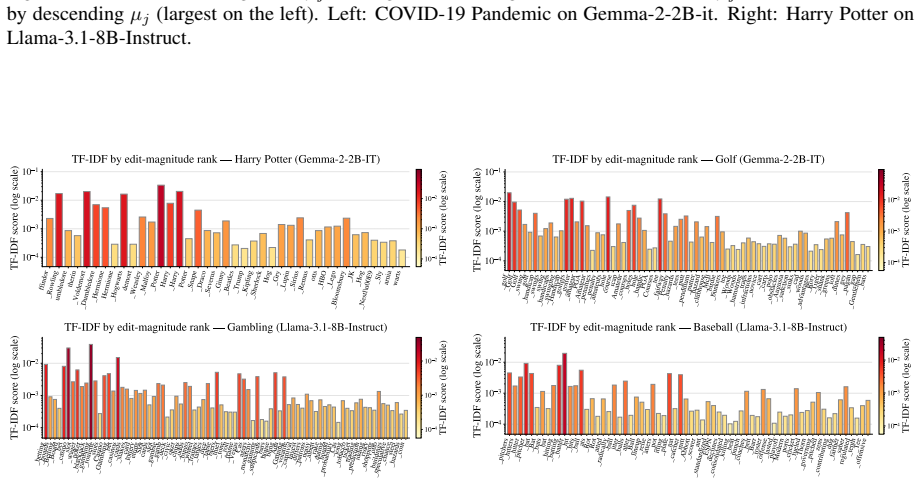


read the original abstract
As language models are increasingly deployed in real-world applications, the ability to erase specific knowledge from them becomes critical for safety and compliance. Prominent methods seek persistent removal by updating the model's parameters, yet the target knowledge often can be recovered through adversarial prompting or relearning. In this work, we hypothesize this limitation stems in part from existing methods overlooking the embedding layer. To address this, we introduce EMBedding ERasure (EMBER), a plug-n-play erasure module that leverages Sparse Matrix Factorization for precise erasure of concept-related features from token embeddings. Through comprehensive evaluations across diverse concepts on Gemma-2-2B-it and Llama-3.1-8B-Instruct, we find that augmenting existing methods with EMBER consistently improves erasure efficacy and specificity across task formats, with minimal coherence loss. Moreover, it dramatically improves robustness to relearning, reducing regained accuracy by up to 50%, limiting it to 35% on Llama compared to 70%-76% for prior methods. Further analysis shows that the coherence cost is localized, affecting only a small set of concept-exclusive tokens. Our work establishes that precise embedding-level intervention is necessary for robust concept erasure, and demonstrates that existing methods can benefit from such augmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EMBER, a plug-and-play module using Sparse Matrix Factorization (SMF) on token embeddings to erase concept-related features. It claims that augmenting existing parameter-update erasure methods with EMBER yields consistent gains in erasure efficacy and specificity across task formats on Gemma-2-2B-it and Llama-3.1-8B-Instruct, with minimal coherence loss that is localized to concept-exclusive tokens; crucially, it reports dramatically improved robustness to relearning (regained accuracy limited to 35% on Llama vs. 70-76% for prior methods) and concludes that precise embedding-level intervention is necessary for robust concept erasure.
Significance. If the empirical results hold after verification of the underlying assumptions, the work would be significant for AI safety and compliance applications by highlighting an overlooked component (the embedding layer) in knowledge erasure pipelines and showing that existing methods can be augmented for better persistence against relearning attacks.
major comments (3)
- [Method] The central claim that precise embedding-level intervention via SMF is necessary rests on the unverified assumption that concept-related features are sufficiently sparse and linearly separable in the token embedding space. No direct diagnostic is provided, such as the singular-value spectrum of the concept-token submatrix, overlap between learned factors and non-concept tokens, or ablation of factorization rank, to confirm this property holds for the evaluated concepts on Gemma-2 or Llama-3.1.
- [Experiments] The reported robustness gains (35% regained accuracy vs. 70-76% for baselines) and coherence results are presented without statistical tests, confidence intervals, or explicit controls for confounding factors such as prompt engineering variations or exact baseline re-implementations, undermining the strength of the cross-method comparison.
- [Analysis] The claim that coherence cost is localized (affecting only a small set of concept-exclusive tokens) is stated in the abstract and analysis but lacks quantitative support, such as the exact fraction or count of affected tokens and direct comparison against non-EMBER baselines.
minor comments (1)
- [Abstract] The abstract states 'reducing regained accuracy by up to 50%' but then specifies '35% on Llama'; aligning these figures with the exact baseline values and models would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Method] The central claim that precise embedding-level intervention via SMF is necessary rests on the unverified assumption that concept-related features are sufficiently sparse and linearly separable in the token embedding space. No direct diagnostic is provided, such as the singular-value spectrum of the concept-token submatrix, overlap between learned factors and non-concept tokens, or ablation of factorization rank, to confirm this property holds for the evaluated concepts on Gemma-2 or Llama-3.1.
Authors: We acknowledge that the manuscript does not provide direct diagnostics such as singular-value spectra or factor overlap analysis to verify the sparsity and separability assumptions. While the consistent empirical gains across models support the approach, we agree these diagnostics would strengthen the central claim. In revision we will add the singular-value spectrum of the concept-token submatrix, quantify overlap between learned factors and non-concept tokens, and include an ablation on factorization rank for the evaluated concepts on Gemma-2-2B-it and Llama-3.1-8B-Instruct. revision: yes
-
Referee: [Experiments] The reported robustness gains (35% regained accuracy vs. 70-76% for baselines) and coherence results are presented without statistical tests, confidence intervals, or explicit controls for confounding factors such as prompt engineering variations or exact baseline re-implementations, undermining the strength of the cross-method comparison.
Authors: We agree that the results would be more robust with statistical validation. The revised manuscript will add statistical tests, confidence intervals over multiple runs, and explicit details on baseline re-implementations together with controls for prompt variations. revision: yes
-
Referee: [Analysis] The claim that coherence cost is localized (affecting only a small set of concept-exclusive tokens) is stated in the abstract and analysis but lacks quantitative support, such as the exact fraction or count of affected tokens and direct comparison against non-EMBER baselines.
Authors: We concur that the localization claim requires quantitative backing. We will revise the analysis section to report the exact fraction and count of affected tokens and provide direct comparisons against non-EMBER baselines. revision: yes
Circularity Check
No circularity: empirical method proposal with independent experimental validation
full rationale
The paper introduces EMBER as a plug-in module using Sparse Matrix Factorization on token embeddings, then reports empirical gains in erasure robustness across Gemma-2 and Llama-3.1 models. No derivation chain, equations, or 'predictions' are present that reduce to fitted parameters or self-citations by construction. The central hypothesis (embedding layer overlooked by prior methods) is tested via augmentation experiments rather than assumed or redefined. Assumptions about sparsity/linear separability are unverified in the provided text but constitute an empirical premise, not a circular reduction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
free parameters (1)
- sparsity level / rank
axioms (1)
- domain assumption Sparse matrix factorization isolates concept-specific directions in embedding space
Reference graph
Works this paper leans on
-
[1]
Precise In-Parameter Concept Erasure in Large Language Models
Gur-Arieh, Yoav and Suslik, Clara Haya and Hong, Yihuai and Barez, Fazl and Geva, Mor. Precise In-Parameter Concept Erasure in Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.960
-
[2]
Intrinsic Test of Unlearning Using Parametric Knowledge Traces
Hong, Yihuai and Yu, Lei and Yang, Haiqin and Ravfogel, Shauli and Geva, Mor. Intrinsic Test of Unlearning Using Parametric Knowledge Traces. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.985
-
[3]
Knowledge Neurons in Pretrained Transformers
Dai, Damai and Dong, Li and Hao, Yaru and Sui, Zhifang and Chang, Baobao and Wei, Furu. Knowledge Neurons in Pretrained Transformers. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.581
-
[4]
Linguistic Regularities in Continuous Space Word Representations
Mikolov, Tomas and Yih, Wen-tau and Zweig, Geoffrey. Linguistic Regularities in Continuous Space Word Representations. Proceedings of the 2013 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013
2013
-
[5]
Pennington, Jeffrey and Socher, Richard and Manning, Christopher. G lo V e: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ). 2014. doi:10.3115/v1/D14-1162
-
[6]
Datasets: A Community Library for Natural Language Processing
Lhoest, Quentin and Villanova del Moral, Albert and Jernite, Yacine and Thakur, Abhishek and von Platen, Patrick and Patil, Suraj and Chaumond, Julien and Drame, Mariama and Plu, Julien and Tunstall, Lewis and Davison, Joe and S a s ko, Mario and Chhablani, Gunjan and Malik, Bhavitvya and Brandeis, Simon and Le Scao, Teven and Sanh, Victor and Xu, Canwen ...
-
[7]
doi: 10.18653/v1/2020.emnlp-demos.6
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[8]
2026 , publisher =
Ashuach, Tomer and Arad, Dana and Mueller, Aaron and Tutek, Martin and Belinkov, Yonatan , booktitle =. 2026 , publisher =
2026
-
[9]
Proceedings of the 41st International Conference on Machine Learning , pages=
The WMDP benchmark: measuring and reducing malicious use with unlearning , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[10]
Nature Machine Intelligence , volume=
Rethinking machine unlearning for large language models , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
2025
-
[11]
Advances in Neural Information Processing Systems , volume=
Large language model unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Towards safer large language models through machine unlearning , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[13]
arXiv preprint arXiv:2410.08827 , year=
Do unlearning methods remove information from language model weights? , author=. arXiv preprint arXiv:2410.08827 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Algorithmic capabilities of random transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv e-prints , pages=
Catastrophic Failure of LLM Unlearning via Quantization , author=. arXiv e-prints , pages=
-
[16]
Artificial Intelligence Review , volume=
Digital forgetting in large language models: A survey of unlearning methods , author=. Artificial Intelligence Review , volume=. 2025 , publisher=
2025
-
[17]
First Conference on Language Modeling , year=
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning , author=. First Conference on Language Modeling , year=
-
[18]
2024 , eprint=
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[20]
9th International Conference on Learning Representations,
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations,. 2021 , publisher =
2021
-
[21]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[22]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Dissecting recall of factual associations in auto-regressive language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[23]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Minimal, Local, and Robust: Embedding-Only Edits for Implicit Bias in T2I Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[24]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[25]
nature , volume=
Learning the parts of objects by non-negative matrix factorization , author=. nature , volume=. 1999 , publisher=
1999
-
[26]
Constructing Interpretable Features from Compositional Neuron Groups
Shafran, Or and Geiger, Atticus and Geva, Mor. Constructing Interpretable Features from Compositional Neuron Groups. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026). 2026
2026
-
[27]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
IEEE transactions on pattern analysis and machine intelligence , volume=
Convex and Semi-Nonnegative Matrix Factorizations , author=. IEEE transactions on pattern analysis and machine intelligence , volume=
-
[29]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[30]
The Eleventh International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations , year=
-
[31]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[32]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[33]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[34]
Advances in neural information processing systems , volume=
Man is to computer programmer as woman is to homemaker? debiasing word embeddings , author=. Advances in neural information processing systems , volume=
-
[35]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Null it out: Guarding protected attributes by iterative nullspace projection , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[36]
Proceedings 2025 Network and Distributed System Security Symposium , year=
Safety Misalignment Against Large Language Models , author=. Proceedings 2025 Network and Distributed System Security Symposium , year=
2025
-
[37]
arXiv preprint arXiv:2603.19302 , year=
Parameter-Efficient Token Embedding Editing for Clinical Class-Level Unlearning , author=. arXiv preprint arXiv:2603.19302 , year=
-
[38]
ArXiv , year=
LLM Unlearning Should Be Form-Independent , author=. ArXiv , year=
-
[39]
Chongyu Fan and Jinghan Jia and Yihua Zhang and Anil Ramakrishna and Mingyi Hong and Sijia Liu , booktitle=. Towards. 2025 , url=
2025
-
[40]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Knowledge unlearning for mitigating privacy risks in language models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
ArXiv , year=
Who's Harry Potter? Approximate Unlearning in LLMs , author=. ArXiv , year=
-
[42]
CoRR , volume=
Aengus Lynch and Phillip Guo and Aidan Ewart and Stephen Casper and Dylan Hadfield-Menell , title=. CoRR , volume=. 2024 , cdate=
2024
-
[43]
Transactions on Machine Learning Research , issn=
Open Problems in Mechanistic Interpretability , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[44]
Hyperpolyglot
Andrea W Wen-Yi and David Mimno , booktitle=. Hyperpolyglot. 2023 , url=
2023
-
[45]
Advances in Neural Information Processing Systems , volume=
Erasing conceptual knowledge from language models , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
ArXiv , year=
Word Meanings in Transformer Language Models , author=. ArXiv , year=
-
[47]
Thomas Fel and Agustin Martin Picard and Louis B. 2023 , pages =. doi:10.1109/CVPR52729.2023.00266 , url =
-
[48]
A Holistic Approach to Unifying Automatic Concept Extraction and Concept Importance Estimation , booktitle =
Thomas Fel and Victor Boutin and Louis B. A Holistic Approach to Unifying Automatic Concept Extraction and Concept Importance Estimation , booktitle =. 2023 , editor =
2023
-
[49]
Olshausen and Yann LeCun , title =
Zeyu Yun and Yubei Chen and Bruno A. Olshausen and Yann LeCun , title =. Proceedings of Deep Learning Inside Out: The 2nd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, DeeLIO@NAACL-HLT 2021, Online, June 10 2021 , year =. doi:10.18653/V1/2021.DEELIO-1.1 , url =
-
[50]
Deep Feature Factorization for Concept Discovery , booktitle =
Edo Collins and Radhakrishna Achanta and Sabine S. Deep Feature Factorization for Concept Discovery , booktitle =. 2018 , pages =. doi:10.1007/978-3-030-01264-9\_21 , url =
-
[51]
Scaling and evaluating sparse autoencoders , booktitle =
Leo Gao and Tom Dupr. Scaling and evaluating sparse autoencoders , booktitle =. 2025 , publisher =
2025
-
[52]
Frey , title =
Alireza Makhzani and Brendan J. Frey , title =. 2nd International Conference on Learning Representations,. 2014 , editor =
2014
-
[53]
Hoyer , title =
Patrik O. Hoyer , title =. J. Mach. Learn. Res. , year =
-
[54]
Zhang, Ruihan and Madumal, Prashan and Miller, Tim and Ehinger, Krista A. and Rubinstein, Benjamin I. P. , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =. doi:10.1609/aaai.v35i13.17389 , url =
-
[55]
ArXiv , year=
Open Problems in Machine Unlearning for AI Safety , author=. ArXiv , year=
-
[56]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Enhancing automated interpretability with output-centric feature descriptions , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[57]
2023 , doi =
Gemini: A Family of Highly Capable Multimodal Models , journal =. 2023 , doi =
2023
-
[58]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[59]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[60]
2026 , howpublished =
2026
-
[61]
Wikimedia Downloads , year =
-
[62]
Gemini (Version 3.1 Flash Lite) , year =
-
[63]
Advances in Neural Information Processing Systems 32 , pages =
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author =. Advances in Neural Information Processing Systems 32 , pages =. 2019 , publisher =
2019
-
[64]
2022 , howpublished =
TransformerLens , author =. 2022 , howpublished =
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.