Benchmarking Large Vision-Language Models on Fine-Grained Image Tasks: From Evaluation to Diagnosis
Pith reviewed 2026-06-26 21:34 UTC · model grok-4.3
The pith
Current large vision-language models remain inadequate fine-grained recognizers due to intertwined bottlenecks in visual representations, semantic grounding, modality alignment, and category-level knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
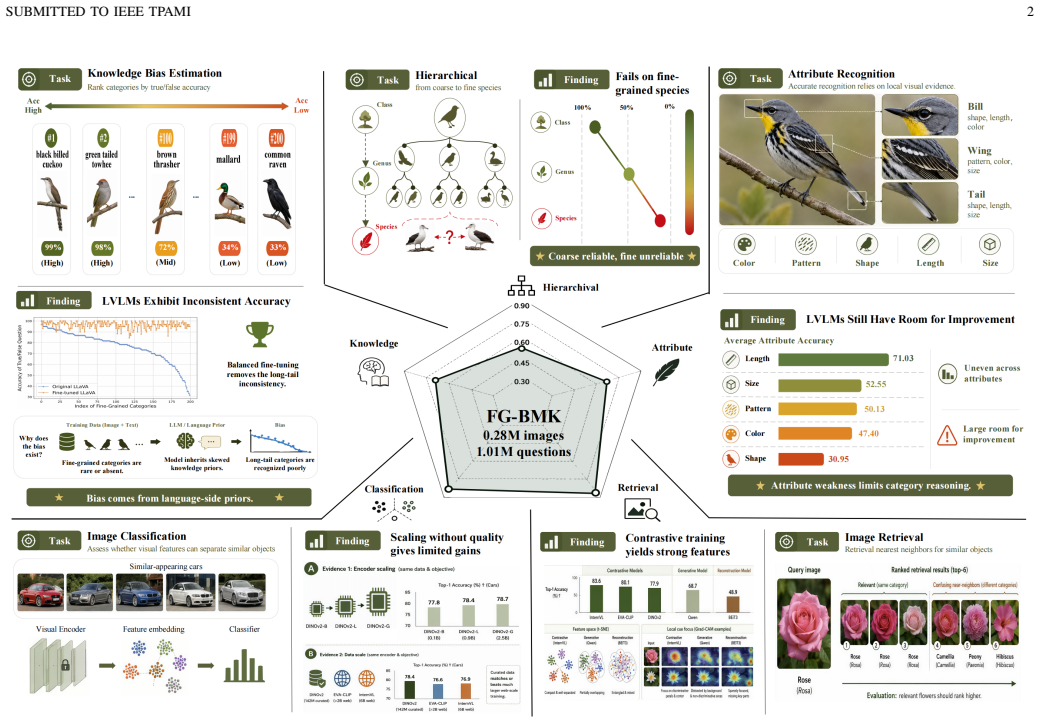
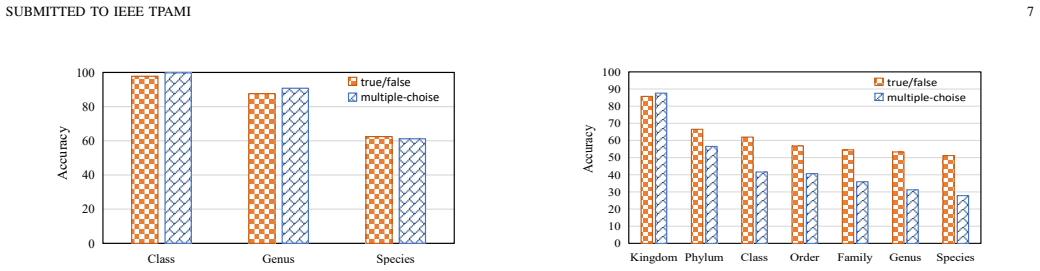
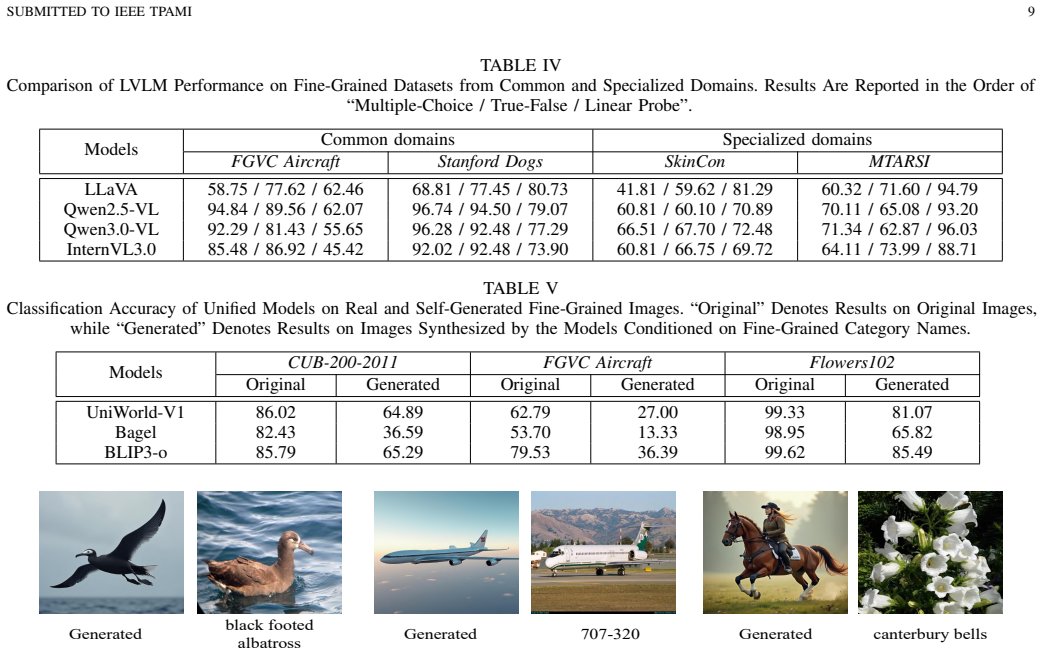
Through the FG-BMK benchmark, which contains 1.01 million questions and 0.28 million images, experiments on a diverse set of LVLMs show that current models remain inadequate fine-grained recognizers, with failures arising from intertwined bottlenecks in visual representations, semantic grounding, modality alignment, and category-level knowledge.
What carries the argument
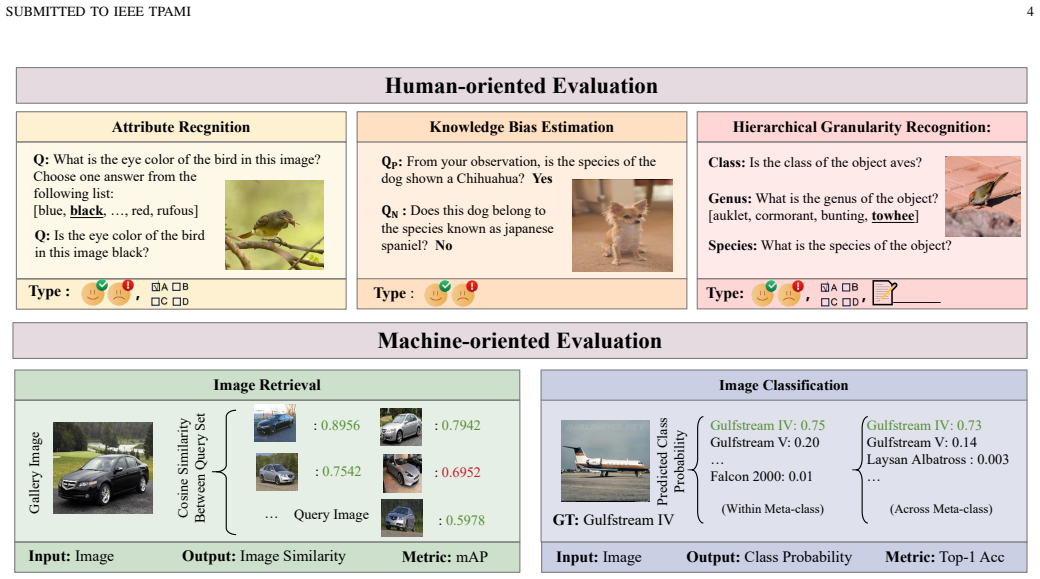
FG-BMK benchmark that jointly evaluates dialogue-level fine-grained semantic recognition and feature-level visual discriminability through human-oriented and machine-oriented paradigms to diagnose specific failure sources.
If this is right
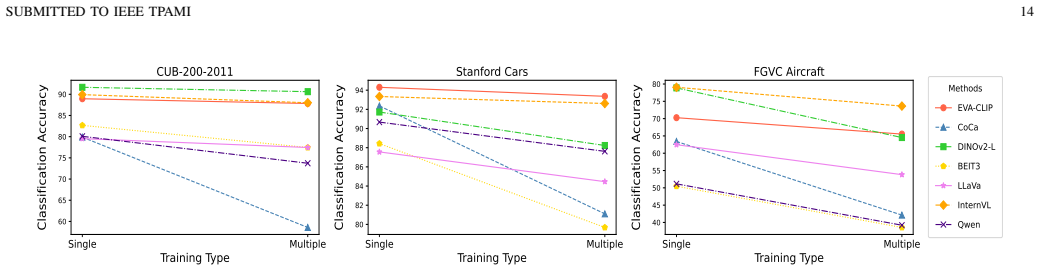
- Training design factors can be adjusted to improve fine-grained capabilities in LVLMs.
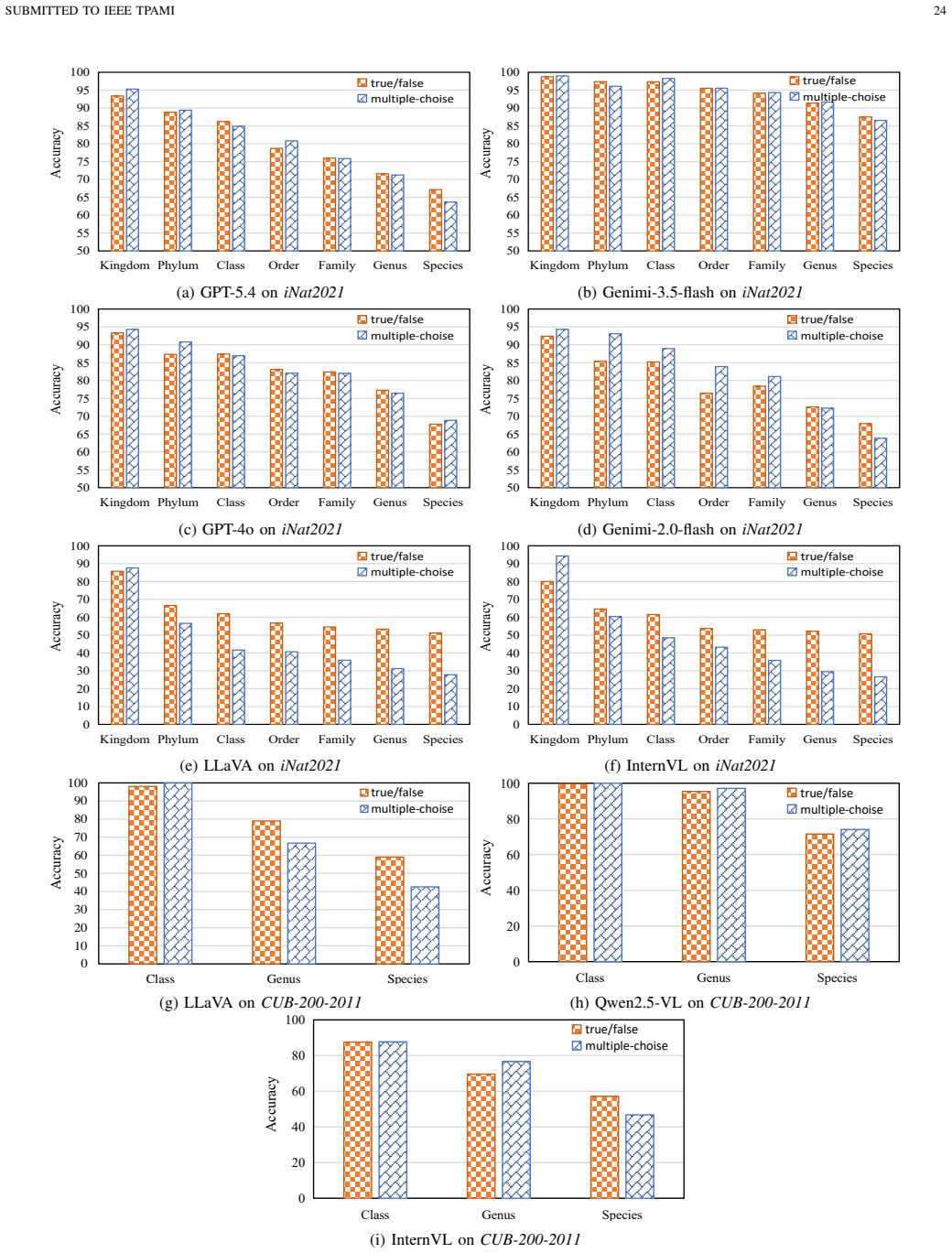
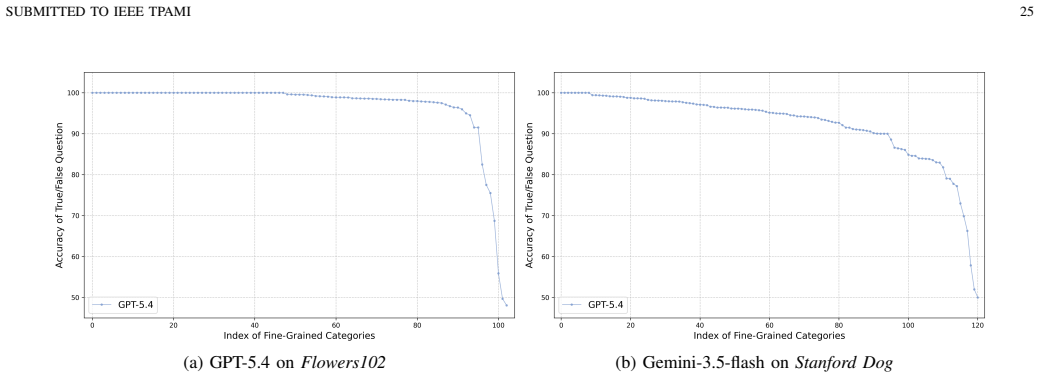
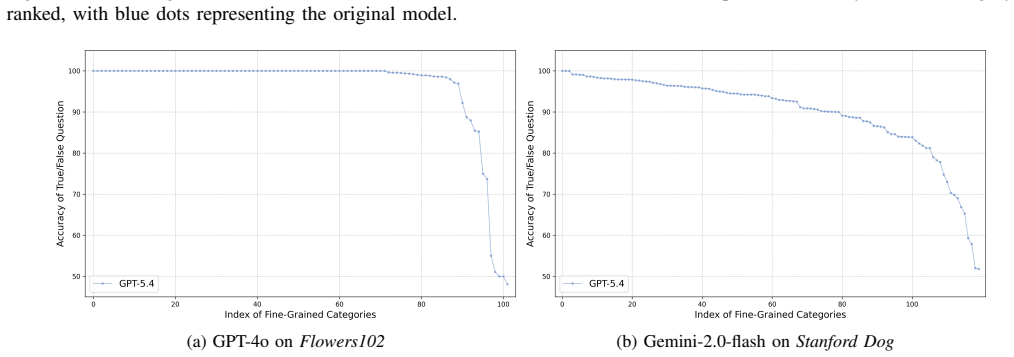
- Visual and linguistic perturbations produce measurable effects on LVLM predictions.
- Diagnostic insights from the benchmark guide future data construction and model design for more reliable fine-grained visual performance.
Where Pith is reading between the lines
- If the four bottlenecks dominate, then isolated fixes to one area such as visual encoders alone are unlikely to close the gap.
- The same evaluation approach could be applied to test whether other multimodal systems exhibit similar linked failure patterns.
- Extending the benchmark to video or real-time settings would reveal whether the identified issues persist beyond static images.
Load-bearing premise
The human-oriented and machine-oriented evaluation paradigms in FG-BMK accurately isolate and diagnose the specific failure sources without introducing measurement biases or overlooking other contributing factors.
What would settle it
A new LVLM architecture that scores high on FG-BMK while showing clear separation of the four bottlenecks would challenge the claim of inherent intertwined inadequacy.
Figures






read the original abstract
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable multimodal perception and reasoning capabilities. While numerous benchmarks have evaluated LVLMs from holistic or task-specific perspectives, their capabilities on fine-grained image tasks-fundamental to computer vision-remain insufficiently understood. To address this gap, we introduce FG-BMK, a comprehensive fine-grained evaluation benchmark containing 1.01 million questions and 0.28 million images, covering diverse scenarios from common object-centric domains to specialized domains. FG-BMK jointly evaluates dialogue-level fine-grained semantic recognition and feature-level visual discriminability through human-oriented and machine-oriented paradigms, enabling diagnostic analysis of whether LVLM failures arise from insufficient visual representations, weak visual-to-semantic grounding, or limited fine-grained knowledge. Through extensive experiments on a diverse set of representative LVLMs/VLMs, we find that current LVLMs remain inadequate fine-grained recognizers, with failures arising from intertwined bottlenecks in visual representations, semantic grounding, modality alignment, and category-level knowledge. We further analyze training design factors for improving fine-grained capabilities and examine how visual and linguistic perturbations affect LVLM predictions. These findings provide diagnostic insights into the limitations of current LVLMs and offer guidance for future data construction and model design in developing more reliable LVLMs for fine-grained visual tasks. Our code is open-source and available at https://fg-bmk.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FG-BMK, a benchmark with 1.01 million questions across 0.28 million images spanning common and specialized domains. It jointly evaluates LVLMs via human-oriented (dialogue-level semantic recognition) and machine-oriented (feature-level visual discriminability) paradigms to diagnose failures attributable to visual representations, semantic grounding, modality alignment, or category-level knowledge. Experiments on representative LVLMs conclude that current models remain inadequate fine-grained recognizers due to these intertwined bottlenecks; additional analyses cover training design factors and effects of visual/linguistic perturbations. Code is open-sourced.
Significance. If the diagnostic attributions are validated, the work supplies concrete guidance for improving LVLMs on fine-grained tasks and highlights data-construction priorities. The scale of FG-BMK and explicit open-sourcing of code and benchmark constitute clear strengths for reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim attributes LVLM failures to four specific intertwined bottlenecks and states that the dual paradigms 'enable diagnostic analysis' of their individual contributions. However, no ablations, controls, or isolation procedures are described that hold all but one factor fixed (e.g., varying only visual representation quality while fixing semantic labels and knowledge). Fine-grained discrimination tasks inherently couple these elements, so observed failures may reflect question design rather than separable sources; this directly undermines the attribution in the strongest claim.
- [Abstract] Abstract (data-construction paragraph): The manuscript reports extensive experiments yet supplies no details on question generation, statistical controls for category balance, inter-annotator validation of diagnostic labels, or safeguards against measurement bias in the 1.01 M questions. Without these, it is impossible to verify that the reported bottlenecks are not artifacts of the benchmark construction itself.
minor comments (2)
- [Abstract] Abstract: The enabling clause lists three diagnostic targets (visual representations, visual-to-semantic grounding, fine-grained knowledge) while the findings paragraph lists four (adding modality alignment and category-level knowledge). Standardize the enumerated set for consistency.
- [Experimental setup] The open-source link is provided, but the manuscript should include a brief reproducibility checklist (e.g., exact model versions, prompt templates, and hardware) in the experimental section to match the scale claimed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our diagnostic claims and benchmark construction details. We address each major comment below and outline planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes LVLM failures to four specific intertwined bottlenecks and states that the dual paradigms 'enable diagnostic analysis' of their individual contributions. However, no ablations, controls, or isolation procedures are described that hold all but one factor fixed (e.g., varying only visual representation quality while fixing semantic labels and knowledge). Fine-grained discrimination tasks inherently couple these elements, so observed failures may reflect question design rather than separable sources; this directly undermines the attribution in the strongest claim.
Authors: We agree that full isolation of the four bottlenecks through ablations holding all but one factor fixed is inherently difficult, given the coupled nature of fine-grained tasks. Our dual paradigms provide diagnostic value by contrasting human-oriented dialogue-level semantic recognition (probing grounding, alignment, and knowledge) against machine-oriented feature-level visual discriminability (probing representations). This comparative design reveals intertwined contributions without claiming complete separability. We will revise the abstract to more precisely articulate the diagnostic scope and limitations of the paradigms, and we will add supporting comparative analyses in the experiments section. revision: partial
-
Referee: [Abstract] Abstract (data-construction paragraph): The manuscript reports extensive experiments yet supplies no details on question generation, statistical controls for category balance, inter-annotator validation of diagnostic labels, or safeguards against measurement bias in the 1.01 M questions. Without these, it is impossible to verify that the reported bottlenecks are not artifacts of the benchmark construction itself.
Authors: We agree that explicit details on these aspects are essential to rule out construction artifacts. The full manuscript (Section 3) describes the multi-stage question generation pipeline, category balancing procedures, inter-annotator agreement for diagnostic labels, and bias mitigation steps including expert review for specialized domains. To address the concern, we will expand the abstract's data-construction description and include a concise summary of these controls in the main text, along with a reference to the open-sourced generation and validation code. revision: yes
Circularity Check
Empirical benchmark paper with no derivation chain or self-referential reductions
full rationale
The paper introduces FG-BMK as a new benchmark with 1.01M questions and evaluates LVLMs experimentally to diagnose failure modes. The central claims rest on observed performance gaps across human-oriented and machine-oriented paradigms rather than any mathematical derivation, fitted parameter renamed as prediction, or self-citation that reduces the result to its own inputs. No equations appear in the abstract or described methodology, and the attribution of intertwined bottlenecks follows directly from the benchmark results without circular redefinition. This is a standard empirical benchmarking study whose conclusions are falsifiable by external replication.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI, “GPT-4 technical report,” 2023, arXiv:2303.08774
Pith/arXiv arXiv 2023
-
[2]
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond,” 2023, arXiv:2308.12966
Pith/arXiv arXiv 2023
-
[3]
InternVL: Scaling up vision foundation models and aligning for generic visual- linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. li, P. Luo, T. Lu, Y . Qiao, and J. Dai, “InternVL: Scaling up vision foundation models and aligning for generic visual- linguistic tasks,” inProc. IEEE Conf. Comp. Vis. Patt. Recogn., 2024, pp. 24 185–24 198
2024
-
[4]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProc. IEEE Conf. Comp. Vis. Patt. Recogn., 2024, pp. 26 296–26 306. SUBMITTED TO IEEE TPAMI 16
2024
-
[5]
LVLM-eHub: A comprehensive evaluation benchmark for large vision-language models,
P. Xu, W. Shao, K. Zhang, P. Gao, S. Liu, M. Lei, F. Meng, S. Huang, Y . Qiao, and P. Luo, “LVLM-eHub: A comprehensive evaluation benchmark for large vision-language models,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 3, pp. 1877–1893, 2025
2025
-
[6]
MMBench: Is your multi-modal model an all-around player?
L. Yuan, H. Duan, Y . Zhang, B. Li, S. Zhang, W. Zhao, Y . Yuan, J. Wang, C. He, Z. Liu, K. Chen, and D. Lin, “MMBench: Is your multi-modal model an all-around player?” inProc. Eur. Conf. Comp. Vis., 2024, pp. 216–233
2024
-
[7]
DocVQA: A dataset for vqa on document images,
M. Mathew, D. Karatzas, and C. Jawahar, “DocVQA: A dataset for vqa on document images,” inProc. Winter Conf. Applications of Comp. Vis., 2021, pp. 2200–2209
2021
-
[8]
GQA: A new dataset for real-world visual reasoning and compositional question answering,
D. A. Hudson and C. D. Manning, “GQA: A new dataset for real-world visual reasoning and compositional question answering,” inProc. IEEE Conf. Comp. Vis. Patt. Recogn., 2019, pp. 6700–6709
2019
-
[9]
African or european swallow? benchmarking large vision-language models for fine-grained object classification,
G. Geigle, R. Timofte, and G. Glava ˇs, “African or european swallow? benchmarking large vision-language models for fine-grained object classification,” inProc. Conf. Empirical Methods in Natural Language Processing, 2024, pp. 2653–2669
2024
-
[10]
Why are visually-grounded language models bad at image classification?
Y . Zhang, A. Unell, X. Wang, D. Ghosh, Y . Su, L. Schmidt, and S. Yeung-Levy, “Why are visually-grounded language models bad at image classification?” inAdvances in Neural Inf. Process. Syst., 2024, pp. 51 727–51 753
2024
-
[11]
Vision llms are bad at hierarchical visual understanding, and llms are the bottleneck,
Y . Tan, Y . Qing, and B. Gong, “Vision llms are bad at hierarchical visual understanding, and llms are the bottleneck,” 2025, arXiv:2505.24840
arXiv 2025
-
[12]
Fine-grained image analysis with deep learning: A survey,
X.-S. Wei, Y .-Z. Song, O. M. Aodha, J. Wu, Y . Peng, J. Tang, J. Yang, and S. Belongie, “Fine-grained image analysis with deep learning: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 12, pp. 8927–8948, 2022
2022
-
[13]
Benchmarking large vision-language models on fine-grained image tasks: A comprehensive evaluation,
H.-T. Yu, Y . Peng, S. Belongie, and X.-S. Wei, “Benchmarking large vision-language models on fine-grained image tasks: A comprehensive evaluation,” inProc. Int. Conf. Learn. Representations, 2026
2026
-
[14]
BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inProc. Int. Conf. Mach. Learn., 2022, pp. 12 888–12 900
2022
-
[15]
BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inProc. Int. Conf. Mach. Learn., 2023, pp. 19 730–19 742
2023
-
[16]
InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models,
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, Y . Duan, H. Tian, W. Su, J. Shao, Z. Gao, E. Cui, X. Wang, Y . Cao, Y . Liu, X. Wei, H. Zhang, H. Wang, W. Xu, H. Li, J. Wang, N. Deng, S. Li, Y . He, T. Jiang, J. Luo, Y . Wang, C. He, B. Shi, X. Zhang, W. Shao, J. He, Y . Xiong, W. Qu, P. Sun, P. Jiao, H. Lv, L. Wu, K. Zhang, H. Deng, J. Ge, K. Chen, L. W...
Pith/arXiv arXiv 2025
-
[17]
Image as a foreign language: BEiT pretraining for vision and vision-language tasks,
W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som, and F. Wei, “Image as a foreign language: BEiT pretraining for vision and vision-language tasks,” in Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2023, pp. 19 175–19 186
2023
-
[18]
BLIP3-o: A family of fully open unified multimodal models-architecture, training and dataset,
J. Chen, Z. Xu, X. Pan, Y . Hu, C. Qin, T. Goldstein, L. Huang, T. Zhou, S. Xie, S. Savarese, L. Xue, C. Xiong, and R. Xu, “BLIP3-o: A family of fully open unified multimodal models-architecture, training and dataset,” 2025, arXiv:2505.09568
Pith/arXiv arXiv 2025
-
[19]
UniWorld-V1: High-resolution semantic encoders for unified visual understanding and generation,
B. Lin, Z. Li, X. Cheng, Y . Niu, Y . Ye, X. He, S. Yuan, W. Yu, S. Wang, Y . Geet al., “UniWorld-V1: High-resolution semantic encoders for unified visual understanding and generation,” 2025, arXiv:2506.03147
Pith/arXiv arXiv 2025
-
[20]
Emerging properties in unified multimodal pretraining,
C. Deng, D. Zhu, K. Li, C. Gou, F. Li, Z. Wang, S. Zhong, W. Yu, X. Nie, Z. Song, G. Shi, and H. Fan, “Emerging properties in unified multimodal pretraining,” 2025, arXiv:2505.14683
Pith/arXiv arXiv 2025
-
[21]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning,
A. Masry, D. X. Long, J. Q. Tan, S. Joty, and E. Hoque, “ChartQA: A benchmark for question answering about charts with visual and logical reasoning,” inProc. Conf. Association for Computational Linguistics, 2022, pp. 2263–2279
2022
-
[22]
Capability: A comprehensive visual caption benchmark for evaluating both correctness and thoroughness,
Z. Liu, C.-W. Xie, B. Wen, F. Yu, P. Li, B. Zhang, N. Yang, Z. Gao, Y . Zheng, and H. Xie, “Capability: A comprehensive visual caption benchmark for evaluating both correctness and thoroughness,” pp. 0–11, 2026
2026
-
[23]
OCRBench: On the hidden mystery of ocr in large multimodal models,
Y . Liu, Z. Li, M. Huang, B. Yang, W. Yu, C. Li, X.-C. Yin, C.-L. Liu, L. Jin, and X. Bai, “OCRBench: On the hidden mystery of ocr in large multimodal models,”Science China Information Sciences, vol. 67, no. 12, 2024
2024
-
[24]
MathVista: Evaluating mathematical reasoning of foundation models in visual contexts,
P. Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K.-W. Chang, M. Galley, and J. Gao, “MathVista: Evaluating mathematical reasoning of foundation models in visual contexts,” inProc. Int. Conf. Learn. Representations, 2024
2024
-
[25]
MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,
X. Yue, Y . Ni, T. Zheng, K. Zhang, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y . Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y . Liu, W. Huang, H. Sun, Y . Su, and W. Chen, “MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi,” inProc. IEEE Conf. Comp. Vis. Patt. Recogn., 2024, pp. 9556–9567
2024
-
[26]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inProc. Int. Conf. Learn. Representations, 2018
2018
-
[27]
Dual attention networks for few-shot fine-grained recognition,
S.-L. Xu, F. Zhang, X.-S. Wei, and J. Wang, “Dual attention networks for few-shot fine-grained recognition,” inProc. Conf. AAAI, 2022, pp. 2911–2919
2022
-
[28]
MECOM: A meta-completion network for fine-grained recognition with incomplete multi-modalities,
X.-S. Wei, H.-T. Yu, A. Xu, F. Zhang, and Y . Peng, “MECOM: A meta-completion network for fine-grained recognition with incomplete multi-modalities,”IEEE Trans. Image Process., vol. 33, pp. 3456–3469, 2024
2024
-
[29]
FSCIL-EACA: Few-Shot Class- Incremental learning network based on embedding augmentation and classifier adaptation for image classification,
R. Zhang, H. E, and M. Song, “FSCIL-EACA: Few-Shot Class- Incremental learning network based on embedding augmentation and classifier adaptation for image classification,”Chinese J. Electron., vol. 33, no. 1, pp. 139–152, 2024
2024
-
[30]
FineCLIP: Self-distilled region-based clip for better fine-grained understanding,
D. Jing, X. He, Y . Luo, N. Fei, G. Yang, W. Wei, H. Zhao, and Z. Lu, “FineCLIP: Self-distilled region-based clip for better fine-grained understanding,” inAdvances in Neural Inf. Process. Syst., 2024, pp. 27 896–27 918
2024
-
[31]
Expression complementary disentanglement network for facial expression recognition,
S. Wang, H. Shuai, L. Zhu, and Q. Liu, “Expression complementary disentanglement network for facial expression recognition,”Chinese J. Electron., vol. 33, no. 3, pp. 742–752, 2024
2024
-
[32]
Weighted linear loss large margin distribution machine for pattern classification,
L. Liu, M. Chu, R. Gong, L. Liu, and Y . Yang, “Weighted linear loss large margin distribution machine for pattern classification,”Chinese J. Electron., vol. 33, no. 3, pp. 753–765, 2024
2024
-
[33]
FGM-SPCL: Open-set recognition network for medical images based on fine-grained data mixture and spatial position constraint loss,
R. Zhang, H. E, L. Yuan, Y . Wang, L. Wang, and M. Song, “FGM-SPCL: Open-set recognition network for medical images based on fine-grained data mixture and spatial position constraint loss,”Chinese J. Electron., vol. 33, no. 4, pp. 1023–1033, 2024
2024
-
[34]
Animal- Bench: Benchmarking multimodal video models for animal-centric video understanding,
Y . Jing, R. Zhang, K. Liang, Y . Li, Z. He, Z. Ma, and J. Guo, “Animal- Bench: Benchmarking multimodal video models for animal-centric video understanding,” inAdvances in Neural Inf. Process. Syst., 2024, pp. 23 457–23 469
2024
-
[35]
SEMICON: A learning-to-hash solution for large-scale fine-grained image retrieval,
Y . Shen, X. Sun, X.-S. Wei, Q.-Y . Jiang, and J. Yang, “SEMICON: A learning-to-hash solution for large-scale fine-grained image retrieval,” in Proc. Eur. Conf. Comp. Vis., 2022, pp. 531–548
2022
-
[36]
RPC: A large-scale and fine-grained retail product checkout dataset,
X.-S. Wei, Q. Cui, L. Yang, P. Wang, L. Liu, and J. Yang, “RPC: A large-scale and fine-grained retail product checkout dataset,”Science China. Information Sciences, vol. 65, no. 9, p. 197101, 2022
2022
-
[37]
DINOv2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P.-Y . Huang, H. Xu, V . Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “DINOv2: Learning robust visual features withou...
Pith/arXiv arXiv 2023
-
[38]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agar- wal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskeverothers, “Learning transferable visual models from natural language supervision,” inProc. Int. Conf. Mach. Learn., 2021, pp. 8748– 8763
2021
-
[39]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,” 2025, arXiv:2502.13923
Pith/arXiv arXiv 2025
-
[40]
EV A-CLIP: Improved training techniques for clip at scale,
Q. Sun, Y . Fang, L. Wu, X. Wang, and Y . Cao, “EV A-CLIP: Improved training techniques for clip at scale,” 2023, arXiv:2303.15389
Pith/arXiv arXiv 2023
-
[41]
CoCa: Contrastive captioners are image-text foundation models,
J. Yu, Z. Wang, V . Vasudevan, L. Yeung, M. Seyedhosseini, and Y . Wu, “CoCa: Contrastive captioners are image-text foundation models,” Transactions on Machine Learning Research, 2022
2022
-
[42]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
G. Gemini Team, “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,” 2024, arXiv:2403.05530
Pith/arXiv arXiv 2024
-
[43]
The Caltech- UCSD birds-200-2011 dataset,
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The Caltech- UCSD birds-200-2011 dataset,” Technical report, California Institute of Technology, 2011
2011
-
[44]
MetaFormer: A unified meta framework for fine-grained recognition,
Q. Diao, Y . Jiang, B. Wen, J. Sun, and Z. Yuan, “MetaFormer: A unified meta framework for fine-grained recognition,” 2022, arXiv:2203.02751
arXiv 2022
-
[45]
SR-GNN: Spatial relation-aware graph neural network for fine-grained image categorization,
A. Bera, Z. Wharton, Y . Liu, N. Bessis, and A. Behera, “SR-GNN: Spatial relation-aware graph neural network for fine-grained image categorization,”IEEE Trans. Image Process., vol. 31, pp. 6017–6031, 2022
2022
-
[46]
Progressive multi-task anti-noise learning and distilling frame- works for fine-grained vehicle recognition,
D. Liu, “Progressive multi-task anti-noise learning and distilling frame- works for fine-grained vehicle recognition,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 9, pp. 10 667–10 678, 2024. SUBMITTED TO IEEE TPAMI 17
2024
-
[47]
Context-aware attentional pooling (cap) for fine-grained visual classification,
A. Behera, Z. Wharton, P. R. Hewage, and A. Bera, “Context-aware attentional pooling (cap) for fine-grained visual classification,” inProc. Conf. AAAI, 2021, pp. 929–937
2021
-
[48]
Interweaving insights: High-order feature interaction for fine-grained visual recognition,
A. Sikdar, Y . Liu, S. Kedarisetty, Y . Zhao, A. Ahmed, and A. Behera, “Interweaving insights: High-order feature interaction for fine-grained visual recognition,” inProc. IEEE Int. Conf. Comp. Vis., 2024, pp. 1755– 1779
2024
-
[49]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Citeseer, Tech. Rep., 2009
2009
-
[50]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” 2020, arXiv:2010.11929
Pith/arXiv arXiv 2020
-
[51]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” inProc. IEEE Conf. Comp. Vis. Patt. Recogn., 2009, pp. 248–255
2009
-
[52]
Bottled wine defect detection data set,
Tianchi, “Bottled wine defect detection data set,” 2021. [Online]. Available: https://tianchi.aliyun.com/dataset/dataDetail?dataId=110147
2021
-
[53]
A benchmark data set for aircraft type recognition from remote sensing images,
Z.-Z. Wu, S.-H. Wan, X.-F. Wang, M. Tan, L. Zou, X.-L. Li, and Y . Chen, “A benchmark data set for aircraft type recognition from remote sensing images,”Applied Soft Computing, vol. 89, pp. 106 132–106 142, 2020
2020
-
[54]
DeepFashion: Powering robust clothes recognition and retrieval with rich annotations,
Z. Liu, P. Luo, S. Qiu, X. Wang, and X. Tang, “DeepFashion: Powering robust clothes recognition and retrieval with rich annotations,” inProc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016, pp. 1096–1104
2016
-
[55]
SkinCon: A skin disease dataset densely annotated by domain experts for fine-grained debugging and analysis,
R. Daneshjou, M. Yuksekgonul, Z. R. Cai, R. Novoa, and J. Y . Zou, “SkinCon: A skin disease dataset densely annotated by domain experts for fine-grained debugging and analysis,” inAdvances in Neural Inf. Process. Syst., 2022, pp. 18 157–18 167
2022
-
[56]
Automated flower classification over a large number of classes,
M.-E. Nilsback and A. Zisserman, “Automated flower classification over a large number of classes,” inProc. IEEE Int. Conf. Comp. Vis., 2008, pp. 722–729
2008
-
[57]
Food-101–mining discriminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101–mining discriminative components with random forests,” inProc. Eur. Conf. Comp. Vis., 2014, pp. 446–461
2014
-
[58]
Fine-grained visual classification of aircraft,
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, “Fine-grained visual classification of aircraft,” 2013, arXiv:1306.5151
Pith/arXiv arXiv 2013
-
[59]
Novel dataset for fine-grained image categorization,
A. Khosla, N. Jayadevaprakash, B. Yao, and L. Fei-Fei, “Novel dataset for fine-grained image categorization,” inCVPR Workshop on Fine-Grained Visual Categorization, 2011, pp. 806–813
2011
-
[60]
3D object representations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3D object representations for fine-grained categorization,” inProc. IEEE Int. Conf. Comp. Vis., 2013, pp. 554–561
2013
-
[61]
VegFru: A domain-specific dataset for fine-grained visual categorization,
S. Hou, Y . Feng, and Z. Wang, “VegFru: A domain-specific dataset for fine-grained visual categorization,” inProc. IEEE Int. Conf. Comp. Vis., 2017, pp. 541–549
2017
-
[62]
Products-10K: A large-scale product recognition dataset,
Y . Bai, Y . Chen, W. Yu, L. Wang, and W. Zhang, “Products-10K: A large-scale product recognition dataset,” 2020, arXiv:2008.10545
arXiv 2020
-
[63]
Benchmarking representation learning for natural world image collections,
G. Van Horn, E. Cole, S. Beery, K. Wilber, S. Belongie, and O. Mac Aodha, “Benchmarking representation learning for natural world image collections,” inProc. IEEE Conf. Comp. Vis. Patt. Recogn., 2021, pp. 12 884–12 893. SUBMITTED TO IEEE TPAMI 18 Supplementary Material of Benchmarking Large Vision-Language Models on Fine-Grained Image Tasks: From Evaluati...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.