Music Playlist Captioning at Scale with Large Language Models
Pith reviewed 2026-06-26 10:00 UTC · model grok-4.3
The pith
Large language models generate captions for music playlists that increase user engagement through semantic framing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
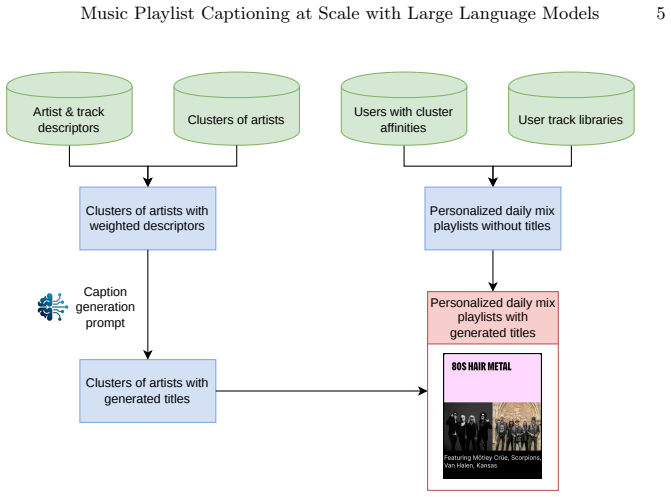
The paper claims that leveraging large language models to generate descriptive captions from diverse data sources for music playlists, when deployed on a streaming service, leads to significant improvements in user engagement. This demonstrates how the semantic framing of recommendations influences user perception in personalized online experiences.
What carries the argument
An LLM-based playlist captioning system that combines information from multiple sources to create controlled natural language descriptions.
If this is right
- Engagement metrics rise when playlists receive LLM-generated captions.
- Semantic descriptions help users understand and connect with algorithmic recommendations.
- The approach scales to handle large numbers of personalized playlists.
- Framing an unchanged recommendation with better language alters user behavior toward it.
Where Pith is reading between the lines
- Similar captioning techniques could enhance recommendations in other media types such as videos or articles.
- Integrating user feedback into the caption generation process might further refine the descriptions.
- The findings point to the potential for language models to serve as interpreters between complex recommendation algorithms and everyday users.
Load-bearing premise
The reported gains in user engagement result directly from the LLM-generated captions and not from other simultaneous modifications to the service or its users.
What would settle it
Running a randomized controlled experiment that isolates the effect of adding the captions while keeping the playlists and all other variables fixed would test whether the engagement increase holds.
Figures


read the original abstract
Music streaming services such as Deezer often recommend personalized playlists to users. Playlist captioning, which involves describing these playlists in natural language, is essential for helping users understand the content behind each recommendation, yet remains challenging at scale. This paper presents the automatic playlist captioning system deployed on Deezer in 2025 to address this challenge. Leveraging recent advances in large language models (LLMs) to generate descriptive captions from diverse data sources in a controlled manner, this system now powers the Daily Mix feature, used by millions of users. This deployment has led to significant improvements in user engagement, highlighting how the semantic framing of an unchanged recommendation shapes user perception in online personalized experiences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an automatic playlist captioning system deployed on Deezer in 2025 that uses large language models to generate natural-language descriptions for personalized playlists from diverse data sources. The system powers the Daily Mix feature and is claimed to have produced significant user-engagement gains by improving the semantic framing of recommendations.
Significance. A well-documented, large-scale deployment of LLM captioning with isolated evidence of engagement lift would be a useful case study for the cs.IR community on how textual framing affects perception of unchanged recommendations. The current manuscript supplies no such evidence, so the claimed result cannot yet be assessed for significance.
major comments (1)
- [Abstract] Abstract: the assertion that the 2025 deployment 'has led to significant improvements in user engagement' is presented without any metrics, A/B-test design, pre/post measurements, statistical tests, or controls for concurrent changes in the recommendation engine, user cohort, or instrumentation. This leaves the central causal claim unsupported.
Simulated Author's Rebuttal
We thank the referee for highlighting the lack of supporting evidence for the engagement claim. We agree this is a substantive issue and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the 2025 deployment 'has led to significant improvements in user engagement' is presented without any metrics, A/B-test design, pre/post measurements, statistical tests, or controls for concurrent changes in the recommendation engine, user cohort, or instrumentation. This leaves the central causal claim unsupported.
Authors: We acknowledge that the manuscript provides no metrics, A/B-test details, or controls to support the causal claim of significant engagement improvements. Such internal data cannot be released for proprietary reasons. We will therefore revise the abstract to remove any assertion of engagement gains or causal effects. The revised version will describe only the system deployment, its use of LLMs for captioning, and its adoption by millions of users for the Daily Mix feature, without referencing un evidenced outcomes. This directly addresses the unsupported claim while retaining the paper's core contribution as a case study of the deployed system. revision: yes
Circularity Check
No derivation chain or fitted model exists; paper is a system-deployment description
full rationale
The manuscript presents a deployed LLM-based playlist captioning system and asserts engagement gains from the 2025 rollout. No equations, parameters, ansatzes, or predictive models are defined or derived. The central claim is an observational statement about user metrics rather than a mathematical reduction. Because no derivation chain is present, no step can reduce to its own inputs by construction, self-citation, or renaming. The provided text contains zero instances of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: Proceedings of the 17th ACM Conference on Recommender Systems
Bendada, W., Bontempelli, T., Morlon, M., Chapus, B., Cador, T., Bouabça, T., Salha-Galvan, G.: Track Mix Generation on Music Streaming Services using Trans- formers. In: Proceedings of the 17th ACM Conference on Recommender Systems. pp. 112–115 (2023)
2023
-
[3]
In: Proceedings of the 14th ACM Conference on Recommender Systems
Bendada,W.,Salha,G.,Bontempelli,T.:Carouselpersonalizationinmusicstream- ing apps with contextual bandits. In: Proceedings of the 14th ACM Conference on Recommender Systems. pp. 420–425 (2020)
2020
-
[4]
In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval
Bendada, W., Salha-Galvan, G., Bouabça, T., Cazenave, T.: A scalable framework for automatic playlist continuation on music streaming services. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 464–474 (2023)
2023
-
[5]
Journal of Statistical Mechanics: Theory and Ex- periment2008(10), P10008 (2008) Music Playlist Captioning at Scale with Large Language Models 9
Blondel, V.D., Guillaume, J.L., Lambiotte, R., Lefebvre, E.: Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Ex- periment2008(10), P10008 (2008) Music Playlist Captioning at Scale with Large Language Models 9
2008
-
[6]
In: Proceedings of the 16th ACM Conference on Recommender Systems
Bontempelli, T., Chapus, B., Rigaud, F., Morlon, M., Lorant, M., Salha-Galvan, G.: Flow Moods: Recommending Music by Moods on Deezer. In: Proceedings of the 16th ACM Conference on Recommender Systems. pp. 452–455 (2022)
2022
-
[7]
In: Proceedings of the 46th European Conference on Information Retrieval
Briand, L., Bontempelli, T., Bendada, W., Morlon, M., Rigaud, F., Chapus, B., Bouabça, T., Salha-Galvan, G.: Let’s get it started: Fostering the discoverability of new releases on deezer. In: Proceedings of the 46th European Conference on Information Retrieval. pp. 286–291. Springer (2024)
2024
-
[8]
In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining
Briand, L., Salha-Galvan, G., Bendada, W., Morlon, M., Tran, V.A.: A Semi- Personalized System for User Cold Start Recommendation on Music Streaming Apps. In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining. pp. 2601–2609 (2021)
2021
-
[9]
arXiv preprint arXiv:2602.03023 (2026)
Bukey, I., Wang, Z., Donahue, C., Bryan, N.J.: Rethinking music captioning with music metadata llms. arXiv preprint arXiv:2602.03023 (2026)
-
[10]
In: Proceedings of the 21st Annual In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval
Carbonell, J., Goldstein, J.: The use of mmr, diversity-based reranking for reorder- ing documents and producing summaries. In: Proceedings of the 21st Annual In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 335–336 (1998)
1998
-
[11]
In: Proceedings of the 1st Workshop on NLP for Music and Audio
Choi, J., Khlif, A., Epure, E.: Prediction of user listening contexts for music playlists. In: Proceedings of the 1st Workshop on NLP for Music and Audio. pp. 23–27 (2020)
2020
-
[12]
In: Late-Breaking/Demo session of 17th International Society of Music Information Retrieval Conference (2016)
Choi, K., Fazekas, G., McFee, B., Cho, K., Sandler, M.: Towards music captioning: Generating music playlist descriptions. In: Late-Breaking/Demo session of 17th International Society of Music Information Retrieval Conference (2016)
2016
-
[13]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Deezer: https://www.deezer.com (2026)
2026
-
[15]
In: Findings of the Association for Computational Linguistics: NAACL 2024
Deng, Z., Ma, Y., Liu, Y., Guo, R., Zhang, G., Chen, W., Huang, W., Benetos, E.: Musilingo: Bridging music and text with pre-trained language models for music captioning and query response. In: Findings of the Association for Computational Linguistics: NAACL 2024. pp. 3643–3655 (2024)
2024
-
[16]
In: Proceedings of the 24th International Society for Music Information Retrieval Conference
Doh, S., Choi, K., Lee, J., Nam, J.: Lp-musiccaps: Llm-based pseudo music cap- tioning. In: Proceedings of the 24th International Society for Music Information Retrieval Conference. vol. 2023, pp. 409–416 (2023)
2023
-
[17]
In: Proceedings of the 2nd Workshop on NLP for Music and Spoken Audio
Doh, S., Lee, J., Nam, J.: Music playlist title generation: A machine-translation approach. In: Proceedings of the 2nd Workshop on NLP for Music and Spoken Audio. pp. 27–31 (2021)
2021
-
[18]
arXiv preprint arXiv:2511.16478 (2025)
Epure, E.V., Deldjoo, Y., Sguerra, B., Schedl, M., Moussallam, M.: Music recom- mendation with large language models: Challenges, opportunities, and evaluation. arXiv preprint arXiv:2511.16478 (2025)
-
[19]
In: Proceedings of the 31st Interna- tional Society for Music Information Retrieval Conference (2020)
Epure, E.V., Salha, G., Hennequin, R.: Multilingual music genre embeddings for effective cross-lingual music item annotation. In: Proceedings of the 31st Interna- tional Society for Music Information Retrieval Conference (2020)
2020
-
[20]
ACM Transactions on Intelligent Systems and Technology15(6), 1–68 (2024)
Gabbolini, G., Bridge, D.: Surveying more than two decades of music informa- tion retrieval research on playlists. ACM Transactions on Intelligent Systems and Technology15(6), 1–68 (2024)
2024
-
[21]
In: Proceedings of the 2022 Conference on Em- pirical Methods in Natural Language Processing
Gabbolini, G., Hennequin, R., Epure, E.: Data-efficient playlist captioning with musical and linguistic knowledge. In: Proceedings of the 2022 Conference on Em- pirical Methods in Natural Language Processing. pp. 11401–11415 (2022) 10 Mathieu Delcluze, et al
2022
-
[22]
In: Proceedings of the 18th Conference of the International Society of Music Information Retrieval
Hennequin, R., Royo-letelier, J., Moussallam, M.: Audio Based Disambiguation of Music Genre Tags. In: Proceedings of the 18th Conference of the International Society of Music Information Retrieval. pp. 645–653 (2018)
2018
-
[23]
Blog post on the Music Business Association (2016)
Jakobsen, L.: Playlists overtake albums in listenership, says loop study. Blog post on the Music Business Association (2016)
2016
-
[24]
In: AAAI 2023 Workshop on Creative AI Across Modalities (2023)
Kim, H., Doh, S., Lee, J., Nam, J.: Music playlist title generation using artist information. In: AAAI 2023 Workshop on Creative AI Across Modalities (2023)
2023
-
[25]
Recommender Systems Handbook pp
Koren, Y., Rendle, S., Bell, R.: Advances in collaborative filtering. Recommender Systems Handbook pp. 91–142 (2021)
2021
-
[26]
Journal of New Music Research37(2), 101–114 (2008)
Lamere, P.: Social tagging and music information retrieval. Journal of New Music Research37(2), 101–114 (2008)
2008
-
[27]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Li, D., Jiang, B., Huang, L., Beigi, A., Zhao, C., Tan, Z., Bhattacharjee, A., Jiang, Y., Chen, C., Wu, T., et al.: From generation to judgment: Opportunities and challenges of llm-as-a-judge. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 2757–2791 (2025)
2025
-
[28]
ACM Transactions on Information Systems43(2), 1–47 (2025)
Lin, J., Dai, X., Xi, Y., Liu, W., Chen, B., Zhang, H., Liu, Y., Wu, C., Li, X., Zhu, C., et al.: How can recommender systems benefit from large language models: A survey. ACM Transactions on Information Systems43(2), 1–47 (2025)
2025
-
[29]
In: Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing
Liu, S., Hussain, A.S., Sun, C., Shan, Y.: Music understanding llama: Advancing text-to-music generation with question answering and captioning. In: Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing. pp. 286–290. IEEE (2024)
2024
-
[30]
In: Proceed- ings of the 15th ACM Conference on Recommender Systems
Salha-Galvan, G., Hennequin, R., Chapus, B., Tran, V.A., Vazirgiannis, M.: Cold start similar artists ranking with gravity-inspired graph autoencoders. In: Proceed- ings of the 15th ACM Conference on Recommender Systems. pp. 443–452 (2021)
2021
-
[31]
International Journal of Multimedia In- formation Retrieval7(2), 95–116 (2018)
Schedl, M., Zamani, H., Chen, C.W., et al.: Current Challenges and Visions in Music Recommender Systems Research. International Journal of Multimedia In- formation Retrieval7(2), 95–116 (2018)
2018
-
[32]
Blog post on Elastic Search Labs (2025)
Strasser, P.: Diversifying search results with maximum marginal relevance. Blog post on Elastic Search Labs (2025)
2025
-
[33]
World Wide Web27(5), 60 (2024)
Wu, L., Zheng, Z., Qiu, Z., Wang, H., Gu, H., Shen, T., Qin, C., Zhu, C., Zhu, H., Liu, Q., et al.: A survey on large language models for recommendation. World Wide Web27(5), 60 (2024)
2024
-
[34]
arXiv preprint arXiv:2603.01590 (2026)
Zhang, Y., Xu, H., Salha-Galvan, G., Han, R., Xiao, F., Huang, Y., Lin, L., Luo, Y., Hu, Y.: Idproxy: Cold-start ctr prediction for ads and recommendation at xiaohongshu with multimodal llms. arXiv preprint arXiv:2603.01590 (2026)
-
[35]
IEEE Transactions on Knowledge and Data Engineering (2024)
Zhao, Z., Fan, W., Li, J., Liu, Y., Mei, X., Wang, Y., Wen, Z., Wang, F., Zhao, X., Tang, J., et al.: Recommender systems in the era of large language models (llms). IEEE Transactions on Knowledge and Data Engineering (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.