Transformer-Enhanced Reinforcement Learning: Fundamentals and Applications in Communication Networks
Pith reviewed 2026-06-29 16:12 UTC · model grok-4.3
The pith
The self-attention mechanism in Transformers allows RL to model long-range dependencies and global correlations in communication networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that integrating the Transformer with RL overcomes limitations in interaction count, long-term relationship modeling, and partial observability by using self-attention to capture long-range dependencies and global correlations efficiently while accelerating training and managing multiple data modalities in network tasks.
What carries the argument
Self-attention mechanism, which computes pairwise relationships across an entire input sequence to model long-range dependencies and global correlations.
If this is right
- Resource allocation and computation offloading decisions require fewer environment samples.
- Routing and trajectory control perform better under partial observability.
- Network security tasks gain from handling heterogeneous data modalities.
- Overall training time for RL agents in networks decreases.
Where Pith is reading between the lines
- The method could extend to large-scale dynamic networks where standard RL fails to converge quickly.
- Combining the approach with semantic communication may create new optimization objectives beyond bit-level metrics.
- Real-time deployment in live network testbeds would test whether the reported efficiency gains hold outside simulation.
Load-bearing premise
That the self-attention mechanism of Transformers directly resolves the interaction volume, long-term modeling, and partial observability problems that limit traditional RL in communication network settings.
What would settle it
An experiment in which a Transformer-augmented RL agent requires the same number of environment interactions as a standard RL agent to reach target performance in a resource allocation or routing task would falsify the central claim.
Figures
read the original abstract
Reinforcement Learning (RL) has long been a powerful solution to various problems in communication networks. However, traditional RL models still face with several limitations. Not only do they rely on large numbers of interactions with the environment, but they are also limited in terms of modeling long-term relationships and tackling partial observability. In recent years, the Transformer model has demonstrated the ability to enhance RL models, allowing them to overcome these issues. Particularly, the self-attention mechanism within the Transformer enables efficient modeling of long-range dependencies and global correlations, as well as accelerates training processes and handles heterogeneous data modalities. In this paper, we present a comprehensive survey of Transformer-based RL algorithms and their applications in communication networks. Specifically, the paper provides the mathematical background of RL and Transformer architectures, along with insights into key issues such as resource allocation, computation offloading, routing, and trajectory control, and network security. We conclude the paper by discussing challenges, open issues, and notable future research directions, including Transformer-enhanced DRL algorithms for semantic communication and network optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey presenting the mathematical background of reinforcement learning and Transformer architectures, reviewing Transformer-enhanced RL algorithms, and surveying their applications to communication network problems including resource allocation, computation offloading, routing, trajectory control, and network security; it concludes with challenges, open issues, and future directions such as semantic communication.
Significance. As a compilation and organization of existing literature on integrating self-attention mechanisms with RL to address sample inefficiency, long-range dependencies, and partial observability in communication networks, the survey can serve as a useful reference point for the field when coverage is representative.
minor comments (2)
- [Abstract] Abstract: the statement that self-attention 'accelerates training processes' is presented without a supporting citation or concrete example from the surveyed works; a brief pointer to a key reference would strengthen the claim.
- The survey structure would benefit from an explicit table or taxonomy that maps specific Transformer-RL variants to the listed application areas (resource allocation, offloading, etc.) to improve navigability.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and for recommending minor revision. The report does not enumerate specific major comments, so we have no points requiring detailed rebuttal or revision at this stage. We will incorporate any minor editorial suggestions during the revision process and confirm that the survey coverage remains representative of the literature.
Circularity Check
No significant circularity; survey of external literature
full rationale
The paper is explicitly a survey compiling mathematical background and applications from prior external work on RL and Transformers. No novel derivations, predictions, or fitted parameters are advanced whose validity reduces to self-referential logic or unverified self-citations. Standard properties of self-attention are cited from the established Transformer literature rather than derived here.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. Al Sallab, S. Yo- gamani, and P. Pérez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 6, pp. 4909–4926, 2021
2021
-
[2]
Rein- forcement learning for mobile robotics exploration: A survey,
L. C. Garaffa, M. Basso, A. A. Konzen, and E. P. de Freitas, “Rein- forcement learning for mobile robotics exploration: A survey,”IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 8, pp. 3796–3810, 2021
2021
-
[3]
Reinforcement learning based recommender systems: A survey,
M. M. Afsar, T. Crump, and B. Far, “Reinforcement learning based recommender systems: A survey,”ACM Comput. Surv., vol. 55, no. 7, pp. 1–38, 2022
2022
-
[4]
A. Alwarafy, M. Abdallah, B. S. Ciftler, A. Al-Fuqaha, and M. Hamdi, “Deep reinforcement learning for radio resource allocation and man- agement in next generation heterogeneous wireless networks: A sur- vey,”arXiv preprint arXiv:2106.00574, 2021
-
[5]
Multi-agent deep reinforcement learning-based task scheduling and resource sharing for o-ran-empowered multi-uav-assisted wireless sensor networks,
M. L. Betalo, S. Leng, H. N. Abishu, F. A. Dharejo, A. M. Seid, A. Erbad, R. A. Naqvi, L. Zhou, and M. Guizani, “Multi-agent deep reinforcement learning-based task scheduling and resource sharing for o-ran-empowered multi-uav-assisted wireless sensor networks,”IEEE Trans. Veh. Technol., vol. 73, no. 7, pp. 9247–9261, 2023
2023
-
[6]
Toward autonomous multi-uav wireless network: A survey of reinforcement learning-based approaches,
Y . Bai, H. Zhao, X. Zhang, Z. Chang, R. Jäntti, and K. Yang, “Toward autonomous multi-uav wireless network: A survey of reinforcement learning-based approaches,”IEEE Commun. Surveys Tuts., vol. 25, no. 4, pp. 3038–3067, 2023
2023
-
[7]
Applications of deep reinforcement learning in communications and networking: A survey,
N. C. Luong, D. T. Hoang, S. Gong, D. Niyato, P. Wang, Y .-C. Liang, and D. I. Kim, “Applications of deep reinforcement learning in communications and networking: A survey,”IEEE Commun. Surveys Tuts., vol. 21, no. 4, pp. 3133–3174, 2019
2019
-
[8]
Transformers in reinforcement learning: a survey,
P. Agarwal, A. A. Rahman, P.-L. St-Charles, S. J. Prince, and S. E. Kahou, “Transformers in reinforcement learning: a survey,”arXiv preprint arXiv:2307.05979, 2023
-
[9]
Transdreamer: Rein- forcement learning with transformer world models,
C. Chen, Y .-F. Wu, J. Yoon, and S. Ahn, “Transdreamer: Rein- forcement learning with transformer world models,”arXiv preprint arXiv:2202.09481, 2022
-
[10]
Deep transformer q-networks for partially observable reinforcement learning,
K. Esslinger, R. Platt, and C. Amato, “Deep transformer q-networks for partially observable reinforcement learning,”arXiv preprint arXiv:2206.01078, 2022
-
[11]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Adv. Neural Inf. Process. Syst., vol. 30, 2017
2017
-
[12]
Autonomous link control in digital twin aided mobile network: From virtual channel generation to intelligent power allocation,
C. Che, G. Liang, K. Zheng, L. Xiang, J. Hu, K. Yang, Q. H. Abbasi, J. Cooper, and M. A. Imran, “Autonomous link control in digital twin aided mobile network: From virtual channel generation to intelligent power allocation,”IEEE Internet Things J., vol. 12, no. 19, pp. 39 745– 39 761, 2025
2025
-
[13]
Dsaf-former: Drl based sub-channel assignment framework using transformer in mmwave iabn,
Z. Ma, Z. Liu, G. Han, J. Li, T. Li, and Q. Guo, “Dsaf-former: Drl based sub-channel assignment framework using transformer in mmwave iabn,”IEEE Internet Things J., vol. 12, no. 19, pp. 40 576– 40 591, 2025
2025
-
[14]
Tpto: A transformer-ppo based task offloading solution for edge computing environments,
N. Gholipour, M. D. de Assuncao, P. Agarwal, J. Gascon-Samson, and R. Buyya, “Tpto: A transformer-ppo based task offloading solution for edge computing environments,” inIEEE 29th ICPADS, 2023, pp. 1115–1122
2023
-
[15]
Transformer- based distributed task offloading and resource management in cloud- edge computing networks,
M. Han, X. Sun, X. Wang, W. Zhan, and X. Chen, “Transformer- based distributed task offloading and resource management in cloud- edge computing networks,”IEEE J. Sel. Areas. Commun., vol. 43, no. 9, pp. 2938–2953, 2025
2025
-
[16]
From perception to action: Transformer-enhanced deep reinforcement learning for autonomous robot navigation,
B. Abdelkader, N. Emira, and E. Nadjib, “From perception to action: Transformer-enhanced deep reinforcement learning for autonomous robot navigation,” inIEEE 7th PAIS, 2025, pp. 1–6
2025
-
[17]
Transformer based collaborative reinforcement learning for fluid antenna system (fas)-enabled 3d uav positioning,
X. Xu, H. Xu, D. Wei, W. Saad, M. Bennis, and M. Chen, “Transformer based collaborative reinforcement learning for fluid antenna system (fas)-enabled 3d uav positioning,”IEEE J. Sel. Areas. Commun., vol. 44, pp. 1128–1143, 2026
2026
-
[18]
Anti-jamming task schedul- ing in mec-o-ran with hierarchical drl and transformer-based control,
G. Asemian, M. Amini, and B. Kantarci, “Anti-jamming task schedul- ing in mec-o-ran with hierarchical drl and transformer-based control,” IEEE Internet Things J., vol. 13, no. 4, pp. 7714–7729, 2026
2026
-
[19]
Radar: Robust drl-based resource allocation against adversarial attacks in intelligent o-ran,
Y . A. Ergu and V .-L. Nguyen, “Radar: Robust drl-based resource allocation against adversarial attacks in intelligent o-ran,”IEEE Trans. Green Commun. Netw., vol. 9, no. 4, pp. 2305–2318, 2025
2025
-
[20]
Enhancing iot intelligence: A transformer-based reinforcement learn- ing methodology,
G. Rjoub, S. Islam, J. Bentahar, M. A. Almaiah, and R. Alrawashdeh, “Enhancing iot intelligence: A transformer-based reinforcement learn- ing methodology,” inIEEE IWCMC, 2024, pp. 1418–1423
2024
-
[21]
A comparison of neural networks for wireless channel prediction,
O. Stenhammar, G. Fodor, and C. Fischione, “A comparison of neural networks for wireless channel prediction,”IEEE Wirel. Commun., vol. 31, no. 3, pp. 235–241, 2024
2024
-
[22]
Machine learning for future wire- less communications: Channel prediction perspectives,
H. Kim, J. Choi, and D. J. Love, “Machine learning for future wire- less communications: Channel prediction perspectives,”arXiv preprint arXiv:2502.18196, 2025
-
[23]
Generative ai for deep reinforcement learning: Framework, analysis, and use cases,
G. Sun, W. Xie, D. Niyato, F. Mei, J. Kang, H. Du, and S. Mao, “Generative ai for deep reinforcement learning: Framework, analysis, and use cases,”IEEE Wirel. Commun., vol. 32, no. 3, pp. 186–195, 2025
2025
-
[24]
Dueling network architectures for deep reinforcement learning,
Z. Wang, T. Schaul, M. Hessel, H. Hasselt, M. Lanctot, and N. Freitas, “Dueling network architectures for deep reinforcement learning,” in ICML, 2016, pp. 1995–2003
2016
-
[25]
On transforming reinforcement learning with transformers: The development trajectory,
S. Hu, L. Shen, Y . Zhang, Y . Chen, and D. Tao, “On transforming reinforcement learning with transformers: The development trajectory,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 8580–8599, 2024
2024
-
[26]
Mastering atari, go, chess and shogi by planning with a learned model,
J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T. Graepelet al., “Mastering atari, go, chess and shogi by planning with a learned model,”Nature, vol. 588, no. 7839, pp. 604–609, 2020
2020
-
[27]
Mastering Atari with Discrete World Models
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba, “Mastering atari with discrete world models,”arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
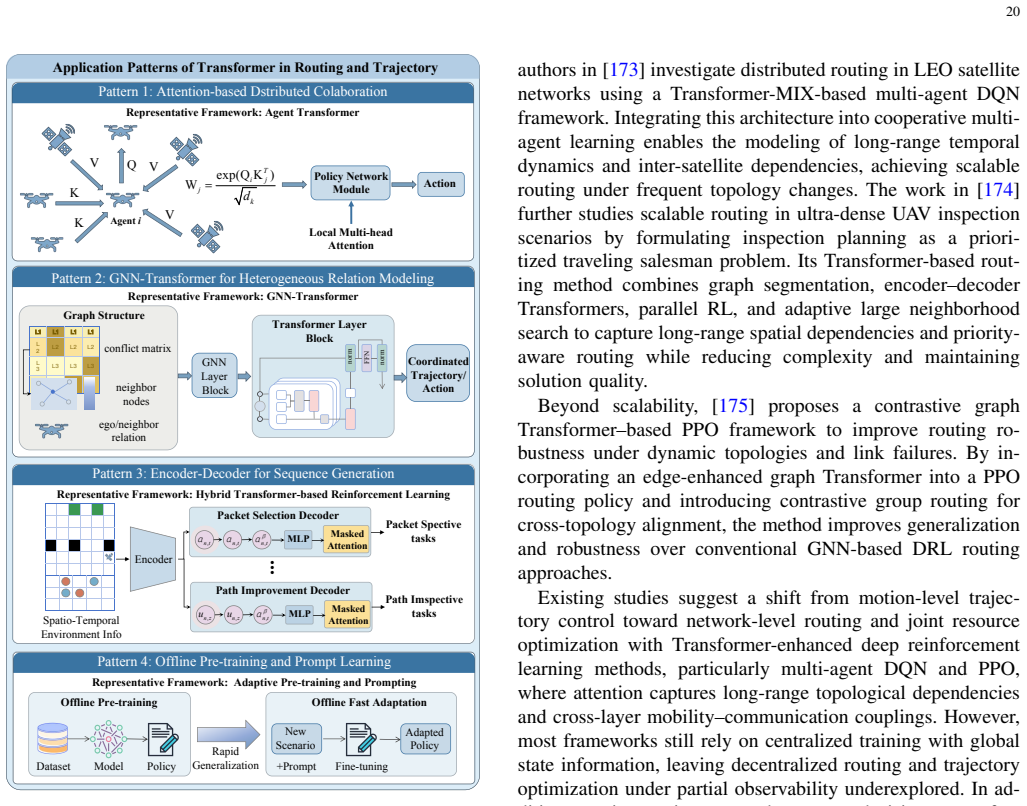
S. Mohanty, J. Poonganam, A. Gaidon, A. Kolobov, B. Wulfe, D. Chakraborty, G. Šemetulskis, J. Schapke, J. Kubilius, J. Pašukonis et al., “Measuring sample efficiency and generalization in reinforce- ment learning benchmarks: Neurips 2020 procgen benchmark,”arXiv preprint arXiv:2103.15332, 2021
-
[29]
A survey on trans- formers in reinforcement learning,
W. Li, H. Luo, Z. Lin, C. Zhang, Z. Lu, and D. Ye, “A survey on trans- formers in reinforcement learning,”arXiv preprint arXiv:2301.03044, 2023
-
[30]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforce- ment learning,”arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduc- tion. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[32]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu, “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,”arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[33]
Diaformer: Automatic diagnosis via symptoms sequence generation,
J. Chen, D. Li, Q. Chen, W. Zhou, and X. Liu, “Diaformer: Automatic diagnosis via symptoms sequence generation,” inAAAI, vol. 36, no. 4, 2022, pp. 4432–4440
2022
-
[34]
Addressing optimism bias in sequence modeling for reinforcement learning,
A. R. Villaflor, Z. Huang, S. Pande, J. M. Dolan, and J. Schneider, “Addressing optimism bias in sequence modeling for reinforcement learning,” inICML, 2022, pp. 22 270–22 283
2022
-
[35]
Iris: Implicit reinforcement without interaction at scale for learning control from offline robot manipulation data,
A. Mandlekar, F. Ramos, B. Boots, S. Savarese, L. Fei-Fei, A. Garg, and D. Fox, “Iris: Implicit reinforcement without interaction at scale for learning control from offline robot manipulation data,” inIEEE In. Conf. Robot. Autom., 2020, pp. 4414–4420. 27
2020
-
[36]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778
2016
-
[37]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Deep Learning using Rectified Linear Units (ReLU)
A. F. Agarap, “Deep learning using rectified linear units (relu),”ArXiv, vol. abs/1803.08375, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Gaussian error linear units (gelus),
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),” arXiv: Learning, 2016
2016
-
[40]
A survey of transformers,
T. Lin, Y . Wang, X. Liu, and X. Qiu, “A survey of transformers,”AI open, vol. 3, pp. 111–132, 2022
2022
-
[41]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, and I. Sutskever, “Generating long sequences with sparse transformers,”arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[42]
Transformers are rnns: Fast autoregressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention,” in ICLR, 2020, pp. 5156–5165
2020
-
[43]
Rethinking attention with performers,
K. M. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Q. Davis, A. Mohiuddin, L. Kaiser, D. B. Belanger, L. J. Colwell, and A. Weller, “Rethinking attention with performers,” inICLR, 2021, pp. 1–14
2021
-
[44]
Linear transformers are secretly fast weight programmers,
I. Schlag, K. Irie, and J. Schmidhuber, “Linear transformers are secretly fast weight programmers,” inICML, 2021, pp. 9355–9366
2021
-
[45]
Generating wikipedia by summarizing long sequences,
P. J. Liu*, M. Saleh*, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer, “Generating wikipedia by summarizing long sequences,” inICLR, 2018, pp. 1–18
2018
-
[46]
Fast transformers with clustered attention,
A. Vyas, A. Katharopoulos, and F. Fleuret, “Fast transformers with clustered attention,”Adv. Neural Inf. Process. Syst., vol. 33, pp. 21 665– 21 674, 2020
2020
-
[47]
Poolingformer: Long document modeling with pooling attention,
H. Zhang, Y . Gong, Y . Shen, W. Li, J. Lv, N. Duan, and W. Chen, “Poolingformer: Long document modeling with pooling attention,” in ICML, 2021, pp. 12 437–12 446
2021
-
[48]
Compressed self-attention for deep metric learning with low-rank approximation,
Z. Chen, M. Gong, L. Ge, and B. Du, “Compressed self-attention for deep metric learning with low-rank approximation,” inIJCAI, 2021, pp. 2058–2064
2021
-
[49]
Nyströmformer: A nyström-based algorithm for approximat- ing self-attention,
Y . Xiong, Z. Zeng, R. Chakraborty, M. Tan, G. Fung, Y . Li, and V . Singh, “Nyströmformer: A nyström-based algorithm for approximat- ing self-attention,” inAAAI, vol. 35, no. 16, 2021, pp. 14 138–14 148
2021
-
[50]
Masked language modeling for proteins via linearly scalable long- context transformers,
K. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, D. Belanger, L. Colwellet al., “Masked language modeling for proteins via linearly scalable long- context transformers,”arXiv preprint arXiv:2006.03555, 2020
-
[51]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”J. Mach. Learn. Res., vol. 21, no. 140, pp. 1–67, 2020
2020
-
[52]
Rethinking positional encoding in language pre-training,
G. Ke, D. He, and T. Liu, “Rethinking positional encoding in language pre-training,” inICLR, 2021, pp. 1–14
2021
-
[53]
Modeling localness for self-attention networks,
B. Yang, Z. Tu, D. F. Wong, F. Meng, L. S. Chao, and T. Zhang, “Modeling localness for self-attention networks,” inProc. Conf. Empir. Methods Nat. Lang. Process., 2018, pp. 4449–4458
2018
-
[54]
Multi-head attention with disagreement regularization,
J. Li, Z. Tu, B. Yang, M. R. Lyu, and T. Zhang, “Multi-head attention with disagreement regularization,” inEMNLP, 2018, pp. 2897–2903
2018
-
[55]
Revealing the dark secrets of bert,
O. Kovaleva, A. Romanov, A. Rogers, and A. Rumshisky, “Revealing the dark secrets of bert,” inProc. Conf. Empir. Methods Nat. Lang. Process., 2019, pp. 4365–4374
2019
-
[56]
Adaptive attention span in transformers,
S. Sukhbaatar, E. Grave, P. Bojanowski, and A. Joulin, “Adaptive attention span in transformers,” inACL, 2019, pp. 331–335
2019
-
[57]
Multi-scale self- attention for text classification,
Q. Guo, X. Qiu, P. Liu, X. Xue, and Z. Zhang, “Multi-scale self- attention for text classification,” inAAAI, vol. 34, no. 05, 2020, pp. 7847–7854
2020
-
[58]
Information aggregation for multi-head attention with routing-by-agreement,
J. Li, B. Yang, Z.-Y . Dou, X. Wang, M. R. Lyu, and Z. Tu, “Information aggregation for multi-head attention with routing-by-agreement,” in NAACL. Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 3566–3575
2019
-
[59]
Improving multi-head attention with capsule networks,
S. Gu and Y . Feng, “Improving multi-head attention with capsule networks,” inProc. CCF Int. Conf. Nat. Lang. Process. Chin. Comput. Springer, 2019, pp. 314–326
2019
-
[60]
An image is worth16×16words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth16×16words: Transformers for image recognition at scale,” inICLR, 2021, pp. 1–21
2021
-
[61]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inICCV, 2021, pp. 9992–10 002
2021
-
[62]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in Proc. Eur. Conf. Comput. Vis.Springer, 2020, pp. 213–229
2020
-
[63]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProc. IEEE Int. Conf. Comput. Vis., 2023, pp. 4015–4026
2023
-
[64]
Graph Attention Networks,
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y . Bengio, “Graph Attention Networks,”ICLR, 2018
2018
-
[65]
Graph transformer networks,
S. Yun, M. Jeong, R. Kim, J. Kang, and H. J. Kim, “Graph transformer networks,”Adv. Neural Inf. Process. Syst., vol. 32, 2019
2019
-
[66]
Heterogeneous graph trans- former,
Z. Hu, Y . Dong, K. Wang, and Y . Sun, “Heterogeneous graph trans- former,” inProc. Web Conf., 2020, pp. 2704–2710
2020
-
[67]
Do transformers really perform badly for graph representation?
C. Ying, T. Cai, S. Luo, S. Zheng, G. Ke, D. He, Y . Shen, and T.-Y . Liu, “Do transformers really perform badly for graph representation?” Adv. Neural Inf. Process. Syst., vol. 34, pp. 28 877–28 888, 2021
2021
-
[68]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[69]
Multimodal Learning With Transformers: A Survey ,
P. Xu, X. Zhu, and D. A. Clifton, “ Multimodal Learning With Transformers: A Survey ,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 10, pp. 12 113–12 132, October 2023
2023
-
[70]
Multi-game decision transformers,
K.-H. Lee, O. Nachum, M. Yang, L. Y . Lee, D. Freeman, W. Xu, S. Guadarrama, I. S. Fischer, E. Jang, H. Michalewski, and I. Mordatch, “Multi-game decision transformers,”ArXiv, vol. abs/2205.15241, 2022
-
[71]
Q-learning,
C. J. Watkins and P. Dayan, “Q-learning,”Mach. Learn., vol. 8, no. 3, pp. 279–292, 1992
1992
-
[72]
Playing Atari with Deep Reinforcement Learning
V . Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,”arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[73]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[74]
Monotonic value function factorisation for deep multi- agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi- agent reinforcement learning,”J. Mach. Learn. Res., vol. 21, no. 178, pp. 1–51, 2020
2020
-
[75]
M. Gallici, M. Martin, and I. Masmitja, “Transfqmix: Transformers for leveraging the graph structure of multi-agent reinforcement learning problems,”arXiv preprint arXiv:2301.05334, 2023
-
[76]
A transformer-based thermal surrogate model for cooling control in data centers,
H. Zhou, N. Mu, and Q.-S. Jia, “A transformer-based thermal surrogate model for cooling control in data centers,”IEEE Robot. Autom. Lett., vol. 10, no. 1, pp. 644–651, 2025
2025
-
[77]
Trandrl: A transformer-driven deep reinforcement learning enabled prescriptive maintenance framework,
Y . Zhao, J. Yang, W. Wang, H. Yang, and D. Niyato, “Trandrl: A transformer-driven deep reinforcement learning enabled prescriptive maintenance framework,”IEEE Internet Things J., vol. 11, no. 21, pp. 35 432–35 444, 2024
2024
-
[78]
A deep reinforcement learning with transformer integration for directed acyclic graph scheduling in edge networks,
X. Song, J. Feng, L. Liu, Q. Pei, F. R. Yu, and N. Zhang, “A deep reinforcement learning with transformer integration for directed acyclic graph scheduling in edge networks,”IEEE Trans. Wireless Commun, vol. 25, pp. 5506–5520, 2026
2026
-
[79]
Robust downlink data transmission in leo satellite-terrestrial networks: A rate- splitting multiple access approach,
X. Zhang, X. Qin, Y . Wang, Y . Xu, H. Zhou, and W. Zhuang, “Robust downlink data transmission in leo satellite-terrestrial networks: A rate- splitting multiple access approach,”IEEE Internet Things J., vol. 12, no. 14, pp. 27 364–27 378, 2025
2025
-
[80]
Learning-based task-centric multi-user semantic communication solu- tion for vehicle networks,
Y . Yuan, J. Zhang, X. Xu, B. Wang, S. Han, M. Sun, and P. Zhang, “Learning-based task-centric multi-user semantic communication solu- tion for vehicle networks,”IEEE Trans. Veh. Technol., vol. 74, no. 6, pp. 9328–9342, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.