Multi-FRuGaL: Multimodal Flexible Redundancy-aware Decomposed Gated Learning for Cancer Diagnosis and Prognosis
Pith reviewed 2026-06-27 22:40 UTC · model grok-4.3
The pith
Multi-FRuGaL separates redundant signals from complementary ones in incomplete medical data using gated fusion to improve cancer prognosis accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
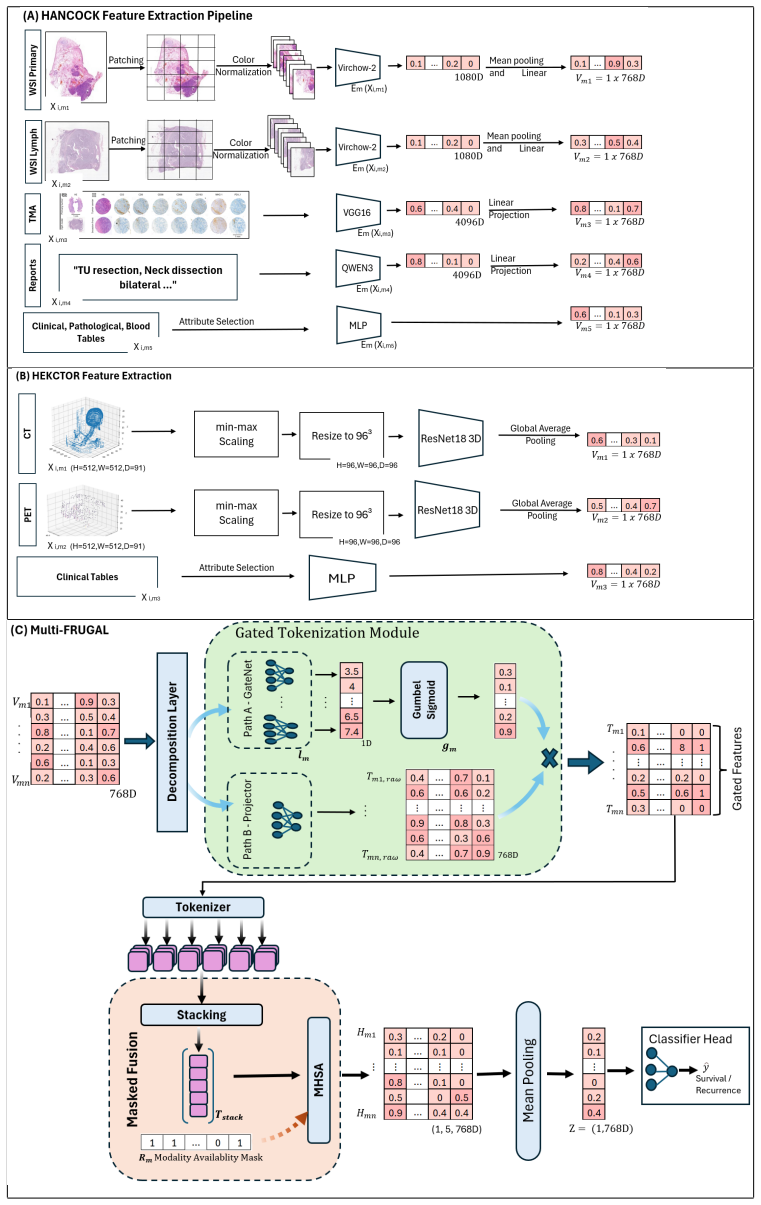
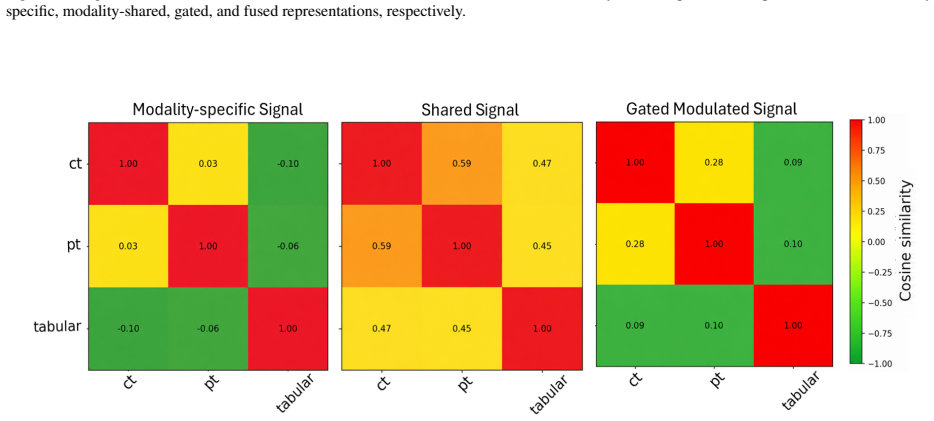
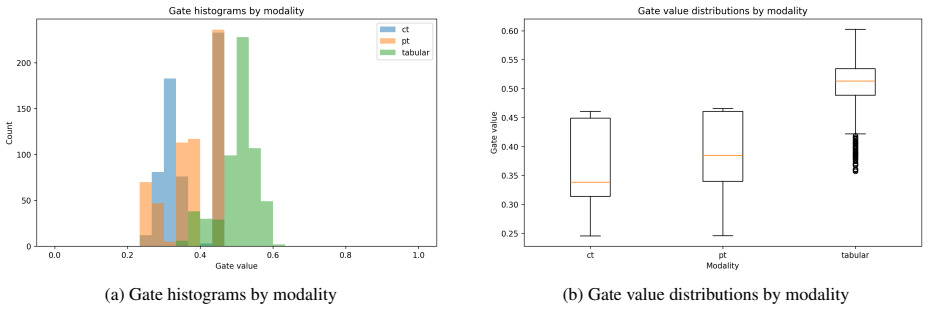
Multi-FRuGaL integrates per-modality encoders with a signal decomposition layer, an input-conditioned gating network, and an information-aware fusion objective to separate redundant from modality-specific complementary signals, selectively upweighting informative modalities and suppressing redundant or noisy inputs, and remaining well-defined even when multiple modalities are absent. Evaluated on HANCOCK (N=763, five modalities) and HECKTOR (N=588, three modalities), it improves mean performance across survival, recurrence, and HPV tasks.
What carries the argument
The input-conditioned gating network that, together with the signal decomposition layer, learns to weight modalities according to their contribution to the task.
If this is right
- It achieves a concordance index of 0.6814 for overall survival on HANCOCK.
- It reaches 0.975 AUC for HPV prediction on HECKTOR.
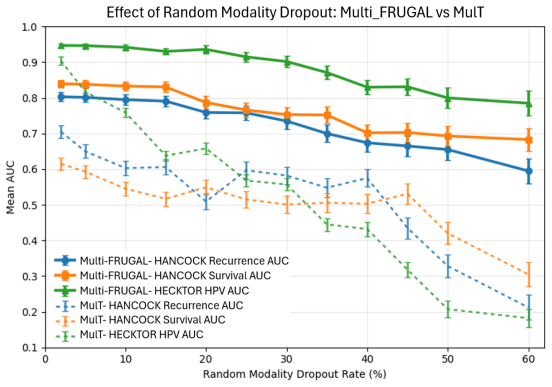
- Performance holds under severe missing-modality conditions.
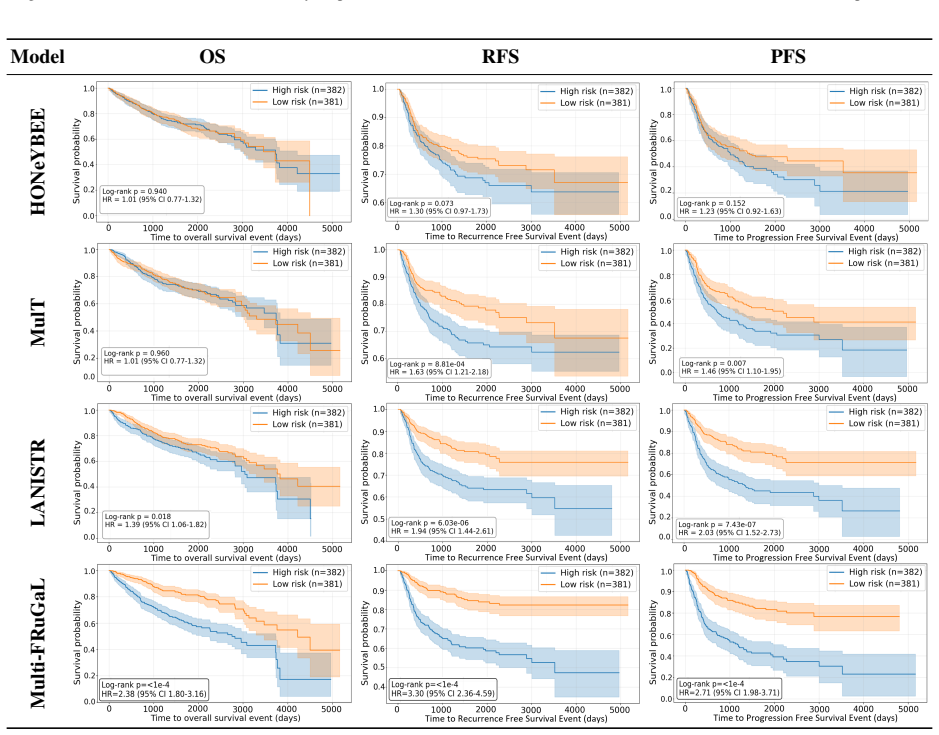
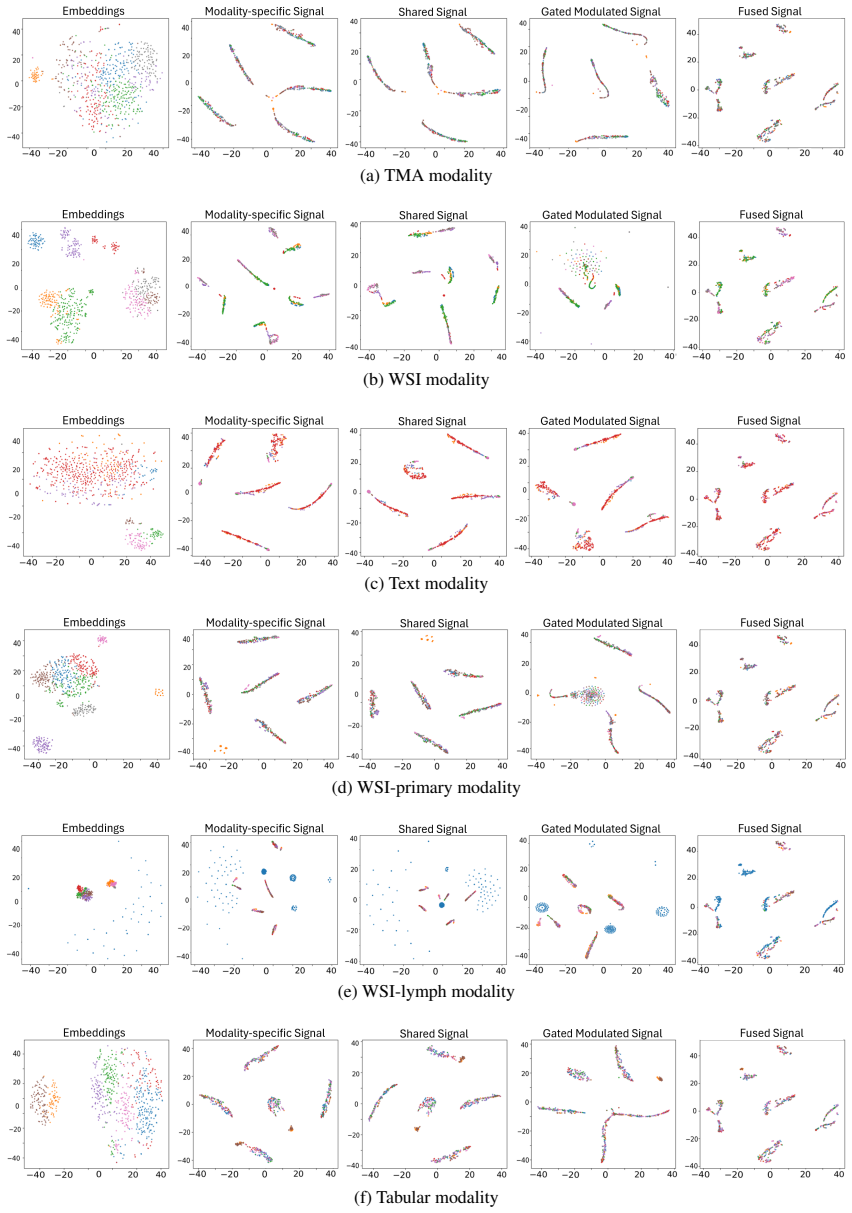
- The method produces discriminative multimodal representations.
- Results are reported for recurrence-free and progression-free survival as well.
Where Pith is reading between the lines
- Similar gating could help fusion models in other domains with incomplete sensor data, such as autonomous driving.
- Explicit signal decomposition might reduce the need for imputation techniques in medical AI.
- Testing on datasets with more than five modalities would reveal scalability limits.
- The approach may generalize to non-cancer tasks like predicting treatment response.
Load-bearing premise
The input-conditioned gating network and information-aware fusion objective can reliably separate redundant from modality-specific signals and remain effective when multiple modalities are absent.
What would settle it
A controlled experiment on HANCOCK where two modalities are randomly dropped in every sample and the survival AUC falls below 0.75 would indicate the gating does not reliably identify informative signals.
Figures
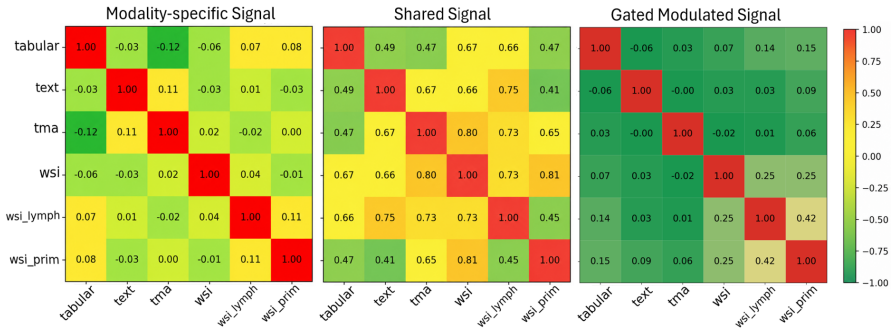
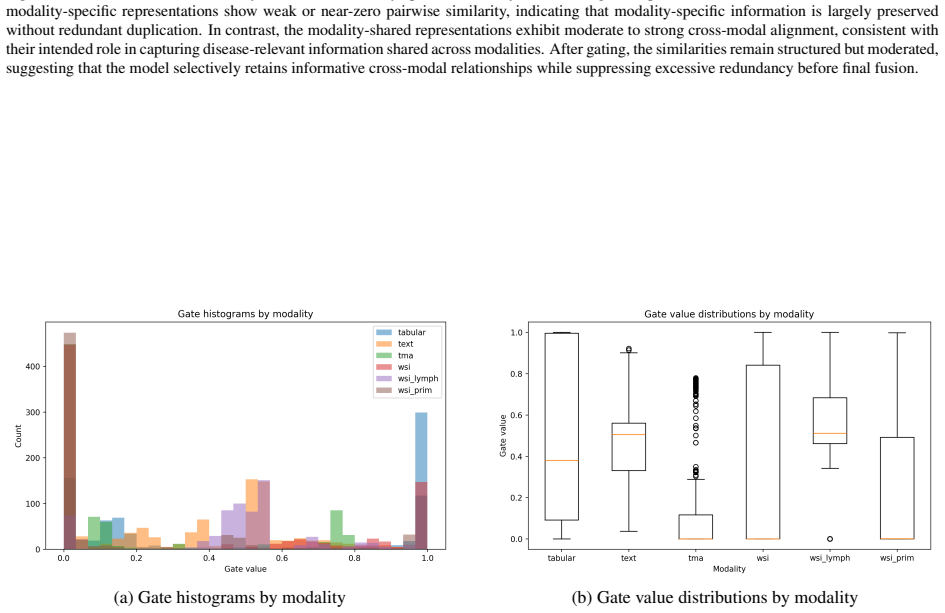
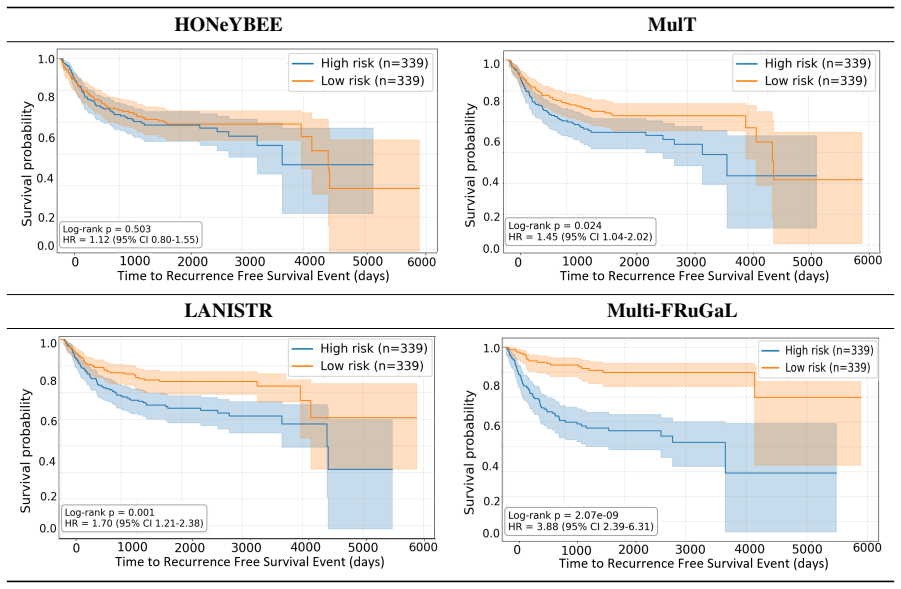
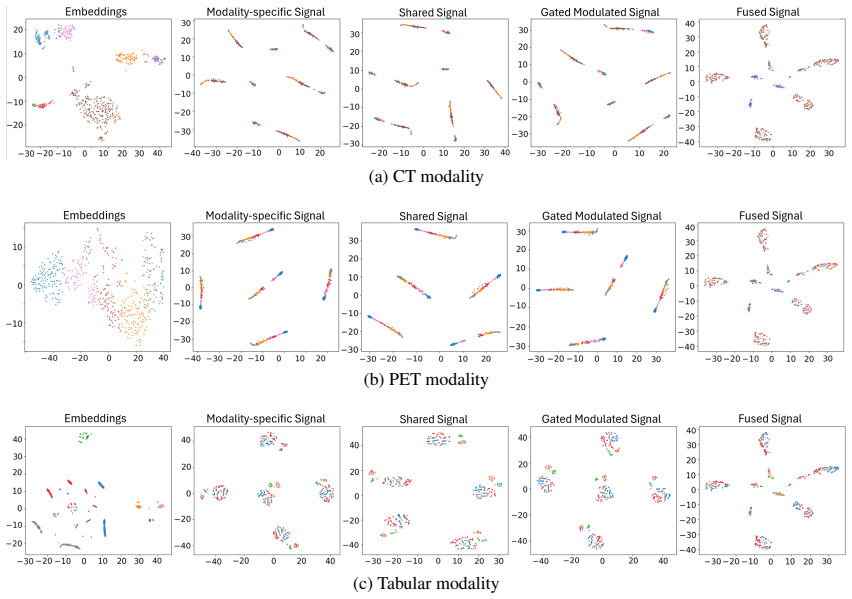
read the original abstract
Modern medicine relies on heterogeneous data sources spanning radiology, pathology, text reports, and structured clinical information. However, real-world patient data are frequently incomplete, with missing or sparsely acquired modalities, limiting the effectiveness of standard multimodal fusion approaches. To this end, we propose the Multimodal Flexible Redundancy-aware decomposed GAted Learning (Multi-FRuGaL) framework, a decomposition-aware, adaptive gated intermediate-fusion framework that performs modality-level representation learning under missing data. Multi-FRuGaL integrates per-modality encoders with a signal decomposition layer, an input-conditioned gating network, and an information-aware fusion objective to separate redundant from modality-specific complementary signals, selectively upweighting informative modalities and suppressing redundant or noisy inputs, and remaining well-defined even when multiple modalities are absent. We evaluate Multi-FRuGaL on two multimodal head and neck cancer cohorts: the HANCOCK challenge dataset (N = 763) comprising five modalities and two prognostic endpoints (5-year survival and 2-year recurrence), and the HECKTOR challenge dataset (N = 588) comprising three modalities for human papillomavirus (HPV) status classification. Multi-FRuGaL consistently achieves higher mean performance than the evaluated baselines across multiple tasks, improving AUC from 0.601 to 0.8496 for survival, from 0.672 to 0.8102 for recurrence, and achieving 0.975 AUC for HPV prediction on HECKTOR. For survival analysis, it further achieves a concordance index of 0.6814 for overall survival, 0.7421 for recurrence-free survival, and 0.7143 for progression-free survival on HANCOCK, and 0.7203 for recurrence-free survival on HECKTOR. Qualitative analyses further show that Multi-FRuGaL learns discriminative and robust multimodal representations, even under severe missing-modality conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-FRuGaL, a decomposition-aware adaptive gated intermediate-fusion framework for multimodal cancer diagnosis and prognosis under missing data. It combines per-modality encoders, a signal decomposition layer, an input-conditioned gating network, and an information-aware fusion objective to separate redundant from modality-specific signals and remain well-defined when modalities are absent. Evaluation is on HANCOCK (N=763, five modalities, survival and recurrence endpoints) and HECKTOR (N=588, three modalities, HPV status), reporting AUC gains from 0.601 to 0.8496 (survival), 0.672 to 0.8102 (recurrence), and 0.975 (HPV), plus concordance indices around 0.68-0.74.
Significance. If the input-conditioned gating and fusion objective demonstrably isolate informative signals under missing modalities with statistical rigor, the work could meaningfully advance robust multimodal fusion for incomplete clinical datasets, where standard approaches often degrade. The reported numerical improvements on two challenge cohorts would then represent a practical contribution to prognostic modeling in head and neck cancer.
major comments (3)
- [Abstract] Abstract: the headline AUC gains (0.601→0.8496 survival, 0.672→0.8102 recurrence) are attributed to the decomposition layer + gating network + fusion objective, yet the text supplies only aggregate means with no per-missing-rate performance curves, no controlled ablation isolating the gating network's contribution, and no statistical tests (e.g., paired t-tests or bootstrap CIs) comparing against baselines. This leaves open whether gains arise from the claimed redundancy-aware mechanism or from encoder capacity and dataset specifics.
- [Abstract] Abstract: the claim that the framework “remains well-defined” and yields “robust representations even under severe missing-modality conditions” is load-bearing for the central contribution, but no quantitative support (e.g., ablation tables varying the number of absent modalities or gating-weight statistics) is provided beyond the overall means; the weakest assumption—that the input-conditioned gating reliably separates signals when multiple modalities are absent—therefore lacks direct evidence.
- [Abstract] Abstract: no information is given on baseline fairness (identical encoders and training protocols), data splits, handling of missingness patterns, or multiple-run variance, making it impossible to assess whether the reported improvements are reproducible or confounded by implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional evidence and details would strengthen the presentation. We address each major comment below and commit to revisions that provide the requested quantitative support and reproducibility information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline AUC gains (0.601→0.8496 survival, 0.672→0.8102 recurrence) are attributed to the decomposition layer + gating network + fusion objective, yet the text supplies only aggregate means with no per-missing-rate performance curves, no controlled ablation isolating the gating network's contribution, and no statistical tests (e.g., paired t-tests or bootstrap CIs) comparing against baselines. This leaves open whether gains arise from the claimed redundancy-aware mechanism or from encoder capacity and dataset specifics.
Authors: We agree that the abstract reports only aggregate means and that stronger isolation of the proposed mechanisms is needed. In the revised manuscript we will add per-missing-rate performance curves, controlled ablations that isolate the gating network (and other components) while holding encoder capacity fixed, and statistical comparisons (paired t-tests and bootstrap CIs) against baselines. These additions will directly address whether the reported gains derive from the redundancy-aware decomposition and gating rather than other factors. revision: yes
-
Referee: [Abstract] Abstract: the claim that the framework “remains well-defined” and yields “robust representations even under severe missing-modality conditions” is load-bearing for the central contribution, but no quantitative support (e.g., ablation tables varying the number of absent modalities or gating-weight statistics) is provided beyond the overall means; the weakest assumption—that the input-conditioned gating reliably separates signals when multiple modalities are absent—therefore lacks direct evidence.
Authors: We acknowledge that direct quantitative evidence for behavior under multiple missing modalities is required to support the central claim. The revision will include ablation tables that systematically vary the number of absent modalities together with gating-weight statistics (means, variances, and distributions) across these conditions. This will provide concrete evidence that the input-conditioned gating continues to separate informative from redundant signals even when several modalities are absent. revision: yes
-
Referee: [Abstract] Abstract: no information is given on baseline fairness (identical encoders and training protocols), data splits, handling of missingness patterns, or multiple-run variance, making it impossible to assess whether the reported improvements are reproducible or confounded by implementation details.
Authors: We agree that these implementation and experimental details are essential for assessing reproducibility. The revised manuscript will explicitly document that all baselines used identical encoders and training protocols, describe the data-splitting procedure (including stratification by missingness patterns), explain how missing modalities were simulated and handled during training and inference, and report performance variance across multiple independent runs with different random seeds. revision: yes
Circularity Check
No circularity: empirical architecture evaluated on external benchmarks
full rationale
The manuscript describes a multimodal gated fusion framework evaluated via standard train/test splits on two independent challenge datasets (HANCOCK N=763, HECKTOR N=588). Reported AUC gains (0.601→0.8496 survival, 0.672→0.8102 recurrence, 0.975 HPV) are measured quantities on held-out data, not quantities defined by the same fitted parameters. No equations appear that equate any performance metric to an input by construction, no self-citation chain is invoked to justify uniqueness of the gating or decomposition layer, and no ansatz is smuggled via prior work. The central claims rest on empirical comparison rather than self-referential definitions, satisfying the self-contained criterion against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shilo, H
S. Shilo, H. Rossman, E. Segal, Axes of a rev- olution: challenges and promises of big data in healthcare, Nature medicine 26 (2020) 29–38
2020
-
[2]
M. K. Niazi, A. V . Parwani, M. N. Gurcan, Digital pathology and artificial intelligence, The Lancet Oncology 20 (2019) e253–e261. doi:10.1016/ S1470-2045(19)30154-8
2019
-
[3]
C. L. Srinidhi, O. Ciga, A. L. Martel, Deep neu- ral network models for computational histopathol- ogy: A survey, Medical image analysis 67 (2021) 101813
2021
-
[4]
M. Chandrasekaran, S. Kachole, J. Francik, D. Makris, Pgcgan: Pathological gait-conditioned gan for human gait synthesis, arXiv preprint arXiv:2603.14409 (2026)
arXiv 2026
-
[5]
J. R. Sempionatto, I. Jeerapan, J. Wang, Wear- able and implantable sensors for biomedical appli- cations, Nature Reviews Bioengineering 1 (2022) 69–84. doi:10.1038/s44222-022-00007-3
-
[6]
Castiglioni, L
I. Castiglioni, L. Rundo, M. Codari, Artifi- cial intelligence applications in medical imag- ing: Current perspectives, European Radiol- ogy Experimental 5 (2021) 35. doi:10.1186/ s41747-021-00234-8
2021
-
[7]
Kachole, H
S. Kachole, H. Sajwani, F. B. Naeini, D. Makris, Y . Zweiri, Asynchronous bioplausible neuron for spiking neural networks for event-based vision, in: European Conference on Computer Vision, Springer, 2024, pp. 399–415
2024
-
[8]
Steyaert, C
S. Steyaert, C. Van Neste, et al., Integrative multi- omics approaches in precision oncology, Nature Reviews Genetics 24 (2023) 389–405. doi:10. 1038/s41576-023-00578-9
2023
-
[9]
Rehman, H
U. Rehman, H. Hudson, C.-Y . Hao, Y . Ahn, S. Ka- chole, J. Liu, S. Patel, M. J. Xu, M. J. Rouhani, P. O’Flynn, et al., Lifetime prevalence of betel nut chewing in india and taiwan: Raising awareness of oral cancer risks and the urgent call for regulation, Cancers 18 (2026) 1074
2026
-
[10]
Z. Wang, R. Lin, Y . Li, J. Zeng, Y . Chen, W. Ouyang, H. Li, X. Jia, Z. Lai, Y . Yu, et al., Deep learning-based multi-modal data integration enhancing breast cancer disease-free survival pre- diction, Precision clinical medicine 7 (2024) pbae012
2024
-
[11]
H. Rosenblum, R. Glynne-Jones, et al., Multidis- ciplinary tumor boards in oncology: An overview and future directions, The Oncologist 27 (2022) 95–104. doi:10.1093/oncolo/oyab039. 16
-
[12]
Rajpurkar, E
P. Rajpurkar, E. Chen, I. Banerjee, E. J. Topol, Ai in health and medicine, Nature Medicine 28 (2022) 31–38
2022
-
[13]
S. Li, H. Tang, Multimodal alignment and fu- sion: A survey, arXiv preprint arXiv:2411.17040 (2024)
arXiv 2024
-
[14]
Kachole, X
S. Kachole, X. Huang, F. B. Naeini, R. Muthusamy, D. Makris, Y . Zweiri, Bi- modal segnet: Fused instance segmentation using events and rgb frames, Pattern Recognition 149 (2024) 110215
2024
-
[15]
T. M. Schouten, Y . Zhao, M. de Rooij, et al., A scoping review of multimodal ai in medicine, Medical Image Analysis 97 (2025) 103123. doi:10.1016/j.media.2025.103123
-
[16]
Lipkova, R
J. Lipkova, R. J. Chen, B. Chen, M. Y . Lu, M. Bar- bieri, D. Shao, A. J. Vaidya, C. Chen, L. Zhuang, D. F. Williamson, et al., Artificial intelligence for multimodal data integration in oncology, Cancer cell 40 (2022) 1095–1110
2022
-
[17]
Huang, A
S.-C. Huang, A. Pareek, S. Seyyedi, I. Banerjee, M. P. Lungren, Fusion of medical imaging and electronic health records using deep learning: a systematic review and implementation guidelines, NPJ Digital Medicine 3 (2020) 136
2020
-
[18]
Baltrušaitis, C
T. Baltrušaitis, C. Ahuja, L.-P. Morency, Multi- modal machine learning: A survey and taxonomy, IEEE Transactions on Pattern Analysis and Ma- chine Intelligence 41 (2019) 423–443
2019
-
[19]
J. Li, T. Zhou, G. Yang, Adaptive modality gat- ing for robust multimodal learning in healthcare, Medical Image Analysis 84 (2023) 102699
2023
-
[20]
R. J. Chen, M. Y . Lu, J. Wang, D. F. Williamson, S. J. Rodig, F. Mahmood, Pathomic fusion: An in- tegrated framework for fusing histopathology and genomic features for cancer diagnosis and prog- nosis, IEEE Transactions on Medical Imaging 41 (2020) 757–770
2020
-
[21]
L. R. Soenksen, Y . Ma, C. Zeng, D. Bertsimas, In- tegrated multimodal artificial intelligence frame- work for healthcare applications, NPJ Digital Medicine 5 (2022) 149
2022
-
[22]
Suter, A
Y . Suter, A. Roesch, H. Koeppl, P. J. Schueffler, Missing-modality robust multimodal learning for medical imaging, Medical Image Analysis 87 (2023) 102832
2023
-
[23]
Zhang, Q
Y . Zhang, Q. Zhao, X. Hu, Missing modal- ity imagination network for multimodal classifica- tion, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 8645–8654
2021
-
[24]
H. Chen, Y . Li, J. Zhang, L. Yang, Y . Sun, Y . Chen, S. Zhou, Z. Li, X. Qian, Q. Xu, et al., An align- ment and imputation network (ainet) for breast cancer diagnosis with multimodal multi-view ul- trasound images, IEEE Transactions on Medical Imaging (2025)
2025
- [25]
- [26]
-
[27]
Y . Zhao, X. Wu, D. N. Metaxas, Moddrop++: Adaptive modality dropping for robust multimodal learning, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recogni- tion (CVPR), 2023, pp. 12345–12355
2023
-
[28]
Y .-H. H. Tsai, S. Bai, P. P. Liang, A. Zadeh, L.-P. Morency, R. Salakhutdinov, Multimodal transformer for unaligned multimodal language sequences, in: Proceedings of the Association for Computational Linguistics (ACL), 2019, pp. 6558–6569
2019
-
[29]
X. Wang, H. Wang, Y . Chen, Y . Xu, Self- supervised multimodal representation learning with missing modalities for medical imaging, Na- ture Communications 15 (2024) 3412
2024
-
[30]
Dörrich, M
M. Dörrich, M. Balk, T. Heusinger, S. Beyer, H. Mirbagheri, D. J. Fischer, H. Kanso, C. Matek, A. Hartmann, H. Iro, et al., A multimodal dataset for precision oncology in head and neck cancer, Nature Communications 16 (2025) 7163
2025
-
[31]
V . Andréarczyk, V . Oreiller, S. Boughdad, et al., Overview of the hecktor challenge at miccai 2022: Automatic head and neck tumor segmentation and outcome prediction in pet/ct, in: Head and Neck Tumor Segmentation and Outcome Prediction — Third 3D Head and Neck Tumor Segmentation 17 in PET/CT Challenge (HECKTOR 2022), vol- ume 13626 ofLecture Notes in C...
- [32]
-
[33]
Nikolaou, D
N. Nikolaou, D. Salazar, H. RaviPrakash, M. Gonçalves, R. Mulla, N. Burlutskiy, N. Marku- zon, E. Jacob, A machine learning approach for multimodal data fusion for survival prediction in cancer patients, NPJ Precision Oncology 9 (2025) 128
2025
-
[34]
Guarrasi, F
V . Guarrasi, F. Aksu, C. M. Caruso, F. Di Feola, A. Rofena, F. Ruffini, P. Soda, A systematic re- view of intermediate fusion in multimodal deep learning for biomedical applications, Image and Vision Computing (2025) 105509
2025
-
[35]
Huang, S
X. Huang, S. Kachole, A. Ayyad, F. B. Naeini, D. Makris, Y . Zweiri, A neuromorphic dataset for tabletop object segmentation in indoor cluttered environment, Scientific data 11 (2024) 127
2024
-
[36]
Ramanathan, T
V . Ramanathan, T. Xu, P. Pati, F. Ahmed, M. Goubran, A. L. Martel, Modaltune: Fine- tuning slide-level foundation models with multi- modal information for multi-task learning in digi- tal pathology, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 23912–23923
2025
-
[37]
Ramanathan, P
V . Ramanathan, P. Pati, M. McNeil, A. L. Martel, Ensemble of prior-guided expert graph models for survival prediction in digital pathology, in: Inter- national Conference on Medical Image Comput- ing and Computer-Assisted Intervention, Springer, 2024, pp. 262–272
2024
-
[38]
J. Chen, A. L. Martel, Head and neck tumor segmentation with 3d unet and survival predic- tion with multiple instance neural network, in: 3D head and neck tumor segmentation in PET/CT challenge, Springer, 2022, pp. 221–229
2022
-
[39]
F. B. Naeini, S. Kachole, R. Muthusamy, D. Makris, Y . Zweiri, Event augmentation for con- tact force measurements, IEEE Access 10 (2022) 123651–123660
2022
-
[40]
Kachole, Y
S. Kachole, Y . Alkendi, F. B. Naeini, D. Makris, Y . Zweiri, Asynchronous events-based panoptic segmentation using graph mixer neural network, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4083–4092
2023
-
[41]
Kachole, O
S. Kachole, O. Duran, A computer vision ap- proach to monitoring the activity and well-being of honeybees., 2020
2020
-
[42]
S. Kim, R. Xiao, M. I. Georgescu, S. Alaniz, Z. Akata, Cosmos: Cross-modality self- distillation for vision–language pre-training, arXiv preprint arXiv:2412.01814 (2024)
arXiv 2024
-
[43]
Y . Chen, D. Xu, Y . Huang, S. Zhan, H. Wang, D. Chen, X. Wang, M. Qiu, H. Li, Mimo: A med- ical vision–language model with visual referring multimodal input and pixel grounding multimodal output, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[44]
B. Zhou, Z. Gao, Z. Wang, B. Zhang, Y . Wang, Z. Chen, H. Xie, Syntab-llava: Enhancing mul- timodal table understanding with decoupled syn- thesis, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 24796–24806
2025
-
[45]
S. Du, X. Luo, D. P. O’Regan, C. Qin, Stil: Semi- supervised tabular-image learning for comprehen- sive task-relevant information exploration in mul- timodal classification, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 15549– 15559
2025
-
[46]
H. Yin, G. Si, Z. Wang, Clearsight: Visual signal enhancement for object hallucination mitigation in multimodal large language models, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 14625–14634
2025
-
[47]
L. Yang, Z. Zheng, B. Chen, Z. Zhao, C. Lin, C. Shen, Nullu: Mitigating object hallucinations in large vision-language models via halluspace projection, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recogni- tion (CVPR), 2025, pp. 14635–14645
2025
-
[48]
H. Zeng, X. Wang, Y . Chen, J. Su, J. Liu, Vision- language gradient descent-driven all-in-one deep unfolding networks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and 18 Pattern Recognition (CVPR), 2025, pp. 7524– 7533
2025
-
[49]
Kachole, B
S. Kachole, B. Nayak, J. Brouner, Y . Liu, L. Guo, D. Makris, Posture estimation from tactile signals using a masked forward diffusion model, Sensors 25 (2025) 4926
2025
-
[50]
Kachole, Object segmentation: from neuro- morphic sensing to neuromorphic machine learn- ing (2026)
S. Kachole, Object segmentation: from neuro- morphic sensing to neuromorphic machine learn- ing (2026)
2026
-
[51]
O. Troyanskaya, M. Cantor, G. Sher- lock, P. Brown, T. Hastie, R. Tibshirani, D. Botstein, R. B. Altman, Missing value estimation methods for dna microar- rays, Bioinformatics 17 (2001) 520–525. doi:10.1093/bioinformatics/17.6.520
-
[52]
D. J. Stekhoven, P. Bühlmann, missforest—non- parametric missing value imputation for mixed- type data, Bioinformatics 28 (2012) 112–118. doi:10.1093/bioinformatics/btr597
-
[53]
J. Josse, F. Husson, missmda: A package for han- dling missing values in multivariate data analy- sis, Journal of Statistical Software 70 (2016) 1–31. doi:10.18637/jss.v070.i01
-
[54]
Benkirane, Y
H. Benkirane, Y . Pradat, S. Michiels, P.-H. Cournède, Customics: A versatile deep-learning based strategy for multi-omics integration, PLOS Computational Biology 19 (2023) e1010921
2023
-
[55]
S. You, C. Pitarch-Abaigar, S. Kachole, S. Son- awane, J. Ha, A. S. Gada, D. Crandall, R. Shiradkar, S. Bakas, Profuseme: Prostate cancer biochemical recurrence prediction via fused multi-modal embeddings, arXiv preprint arXiv:2509.14051 (2025)
arXiv 2025
-
[56]
M. Wang, S. Fan, Y . Li, Z. Xie, H. Chen, Missing- modality enabled multi-modal fusion architecture for medical data, Journal of Biomedical Informat- ics 164 (2025) 104796
2025
-
[57]
C. Cui, Z. Asad, W. F. Dean, I. T. Smith, C. Mad- den, S. Bao, B. A. Landman, J. T. Roland, L. A. Coburn, K. T. Wilson, et al., Multi-modal learn- ing with missing data for cancer diagnosis using histopathological and genomic data, in: Medical Imaging 2022: Computer-Aided Diagnosis, vol- ume 12033, SPIE, 2022, pp. 371–378
2022
-
[58]
C. Cui, H. Yang, Y . Wang, S. Zhao, Z. Asad, L. A. Coburn, K. T. Wilson, B. A. Landman, Y . Huo, Deep multimodal fusion of image and non-image data in disease diagnosis and progno- sis: a review, Progress in Biomedical Engineering 5 (2023) 022001
2023
-
[59]
Yeghaian, Z
M. Yeghaian, Z. Bodalal, D. van den Broek, J. B. Haanen, R. G. Beets-Tan, S. Trebeschi, M. A. van Gerven, Multimodal integration of longitudi- nal noninvasive diagnostics for survival prediction in immunotherapy using deep learning, Journal of the American Medical Informatics Association (2025) ocaf074
2025
-
[60]
Y . Xu, F. Zhou, C. Zhao, Y . Wang, C. Yang, H. Chen, Distilled prompt learning for incomplete multimodal survival prediction, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5102–5111
2025
-
[61]
Pooja, S
S. Pooja, S. Gupta, Y . Zhao, X. Zhang, Reducing modality redundancy for effective multimodal fu- sion, IEEE Transactions on Neural Networks and Learning Systems 33 (2022) 5301–5313
2022
-
[62]
M. Y . Lu, D. F. Williamson, T. Y . Chen, R. J. Chen, M. Barbieri, F. Mahmood, Data-efficient and weakly supervised computational pathology on whole-slide images, Nature biomedical engi- neering 5 (2021) 555–570
2021
-
[63]
O. Ciga, T. Xu, A. L. Martel, Self supervised con- trastive learning for digital histopathology, Ma- chine learning with applications 7 (2022) 100198
2022
-
[64]
E. Zimmermann, E. V orontsov, J. Viret, A. Cas- son, M. Zelechowski, G. Shaikovski, N. Tenen- holtz, J. Hall, D. Klimstra, R. Yousfi, et al., Virchow2: Scaling self-supervised mixed mag- nification models in pathology, arXiv preprint arXiv:2408.00738 (2024)
arXiv 2024
-
[65]
Neidlinger, O
P. Neidlinger, O. S. El Nahhas, H. S. Muti, T. Lenz, M. Hoffmeister, H. Brenner, M. van Treeck, R. Langer, B. Dislich, H. M. Behrens, et al., Benchmarking foundation models as fea- ture extractors for weakly supervised computa- tional pathology, Nature biomedical engineering (2025) 1–11
2025
-
[66]
K. Simonyan, A. Zisserman, Very deep convolu- tional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556 (2014). 19
Pith/arXiv arXiv 2014
-
[67]
K. Hara, H. Kataoka, Y . Satoh, Can spatiotem- poral 3d cnns retrace the history of 2d cnns and imagenet?, in: Proceedings of the IEEE con- ference on Computer Vision and Pattern Recog- nition (CVPR), 2018, pp. 6546–6555. doi:10. 1109/CVPR.2018.00685
arXiv 2018
-
[68]
Dörrich, M
M. Dörrich, M. Balk, T. Heusinger, S. Beyer, H. Kanso, C. Matek, A. Hartmann, H. Iro, M. Eck- stein, A.-O. Gostian, et al., A multimodal dataset for precision oncology in head and neck cancer, medRxiv (2024) 2024–05
2024
-
[69]
Y . Bai, S. Chen, L. Dong, W. Zhou, Z. Zhang, S. Liu, F. Wei, Qwen: A foundation model for multilingual understanding and generation, arXiv preprint arXiv:2309.16609 (2023)
Pith/arXiv arXiv 2023
-
[70]
C. J. Maddison, A. Mnih, Y . W. Teh, The concrete distribution: A continuous relaxation of discrete random variables, arXiv preprint arXiv:1611.00712 (2016)
Pith/arXiv arXiv 2016
-
[71]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszko- reit, L. Jones, A. N. Gomez, L. u. Kaiser, I. Polosukhin, Attention is all you need, in: I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, R. Garnett (Eds.), Advances in Neural Information Processing Sys- tems, volume 30, Curran Associates, Inc., 2017. URL:https://proceedings.neurips....
2017
-
[72]
Tripathi, A
A. Tripathi, A. Waqas, M. B. Schabath, Y . Yilmaz, G. Rasool, Honeybee: enabling scalable multi- modal ai in oncology through foundation model- driven embeddings, npj Digital Medicine 8 (2025) 622
2025
-
[73]
S. Ebrahimi, S. O. Arik, Y . Dong, T. Pfis- ter, Lanistr: Multimodal learning from struc- tured and unstructured data, arXiv preprint arXiv:2305.16556 (2023)
arXiv 2023
-
[74]
M. Tan, Q. Le, Efficientnet: Rethinking model scaling for convolutional neural networks, in: Proceedings of the International Conference on Machine Learning (ICML), 2019, pp. 6105–6114. URL:https://arxiv.org/abs/1905.11946
Pith/arXiv arXiv 2019
-
[75]
Huang, Z
G. Huang, Z. Liu, L. van der Maaten, K. Q. Weinberger, Densely connected convolutional networks, in: Proceedings of the IEEE Con- ference on Computer Vision and Pattern Recog- nition (CVPR), 2017, pp. 4700–4708. doi:10. 1109/CVPR.2017.243
2017
-
[76]
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in: Proceedings of the IEEE Con- ference on Computer Vision and Pattern Recog- nition (CVPR), 2018, pp. 7132–7141. doi:10. 1109/CVPR.2018.00745
arXiv 2018
-
[77]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weis- senborn, et al., An image is worth 16x16 words: Transformers for image recognition at scale, In- ternational Conference on Learning Represen- tations (ICLR) (2021). URL:https://arxiv. org/abs/2010.11929
Pith/arXiv arXiv 2021
-
[78]
L. Cai, X. Liang, T. Zhang, J. Huang, T. Tan, Y . Yin, Less is more: Efficient pet/ct segmenta- tion and multimodal prediction of recurrence-free survival and hpv status in head and neck cancer, in: Fourth Head and Neck Cancer Tumor Lesion Segmentation, Diagnosis and Prognosis, ????
-
[79]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778. doi:10.1109/CVPR.2016.90. 20 Figure 1: Overview of the proposed Multimodal Flexible Redundancy-aware decomposed Gated Learning (Multi-FRuGaL) framework.(A)Data processin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.