Robust Trajectory Distillation: Hybrid Reweighting Meets Teacher-Inspired Targets
Pith reviewed 2026-06-30 06:51 UTC · model grok-4.3
The pith
A trajectory-based distillation method reweights samples by forgetting patterns and adds teacher-derived auxiliary targets to handle noisy labels without clean data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
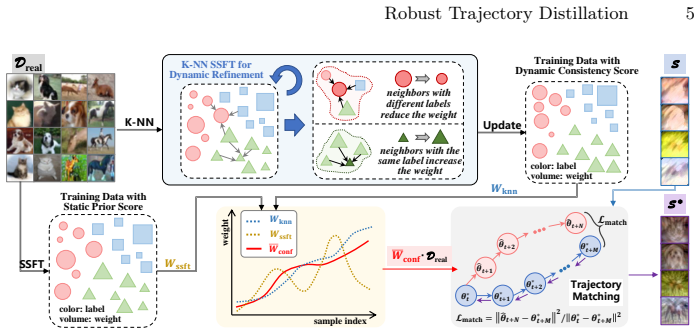
The paper establishes that Selective Guidance Reweighting fuses second-split forgetting patterns with neighborhood consistency to progressively prioritize clean supervision along the teacher trajectory, while Teacher-Inspired Auxiliary Targets supply residual guidance from intermediate teacher dynamics; together these components yield distilled datasets whose representations remain cleaner and more informative under noisy supervision without relabeling or clean anchors.
What carries the argument
Selective Guidance Reweighting (SGR) combined with Teacher-Inspired Auxiliary Targets (TIAT) applied to the teacher trajectory.
If this is right
- Distilled subsets preserve more transferable knowledge even when original labels contain symmetric or asymmetric noise.
- The approach remains effective on real-world noisy collections without needing clean reference data.
- Training costs stay low because the method adds only lightweight reweighting and auxiliary signals during distillation.
- Original labels are kept unchanged, avoiding confirmation bias from iterative correction steps.
Where Pith is reading between the lines
- The trajectory analysis could be adapted to distill from web-scale scraped data where noise is common but unknown.
- Similar forgetting-based reweighting might improve robustness in continual learning or federated settings with label noise.
- Testing the method on non-image modalities would show whether trajectory reweighting generalizes beyond vision tasks.
Load-bearing premise
Global forgetting patterns and local consistency checks along a single teacher trajectory can separate clean from noisy samples reliably enough to guide reweighting and auxiliary targets.
What would settle it
If distilled datasets produced by this method yield no accuracy gain over standard distillation baselines when trained on the same noisy data and evaluated on clean test sets, the central claim would not hold.
Figures
read the original abstract
Dataset distillation (DD) condenses large corpora into compact, information-rich subsets for efficient training and reuse. However, under noisy supervision, DD risks condensing corrupted associations together with useful signals, degrading robustness. Conventional noisy-label remedies (sample selection, loss weighting, label correction) tightly couple noise estimation with model optimization, often require clean anchors, and can amplify confirmation bias-assumptions that are misaligned with DD's goal of compact, plug-and-play supervision. We therefore propose a trajectory-based DD framework that jointly suppresses noise and preserves transferable knowledge without relabeling or clean subsets. It comprises two complementary components: Selective Guidance Reweighting (SGR), which fuses global forgetting patterns (second-split forgetting) with local neighborhood consistency into a progressive reweighting scheme that prioritizes clean supervision along the teacher trajectory; and Teacher-Inspired Auxiliary Targets (TIAT), which inject auxiliary residual guidance distilled from intermediate teacher dynamics to reinforce informative signals while remaining internally consistent. Together, SGR and TIAT produce distilled datasets with cleaner and richer representations under noisy supervision. The framework is robust, label-preserving, computationally lightweight, and broadly applicable, yielding consistent gains over state-of-the-art DD baselines across symmetric, asymmetric, and real-world noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Robust Trajectory Distillation, a framework for dataset distillation under noisy supervision. It introduces Selective Guidance Reweighting (SGR), which fuses second-split forgetting patterns with neighborhood consistency into a progressive reweighting scheme along the teacher trajectory, and Teacher-Inspired Auxiliary Targets (TIAT), which injects auxiliary residual guidance from intermediate teacher dynamics. The method claims to suppress noise while preserving transferable knowledge without relabeling or clean anchors, producing cleaner distilled datasets and yielding consistent gains over state-of-the-art DD baselines across symmetric, asymmetric, and real-world noise.
Significance. If the empirical claims hold and the reweighting reliably isolates clean signals, the work addresses a misalignment between standard noisy-label techniques and the goals of dataset distillation, offering a lightweight, label-preserving approach applicable to real-world noisy data in computer vision. This could enable more robust plug-and-play supervision from condensed datasets.
major comments (2)
- [SGR description (method section)] The central claim that SGR's fusion of global second-split forgetting with local neighborhood consistency produces a reweighting scheme monotonic in cleanliness (prioritizing clean supervision) is load-bearing but unsupported by any derivation or bound. In asymmetric noise, forgetting trajectories for noisy labels can overlap with clean ones after the first split, and TIAT's residual guidance from the same corrupted teacher does not resolve this dependence; no section provides a formal argument or test isolating this separation.
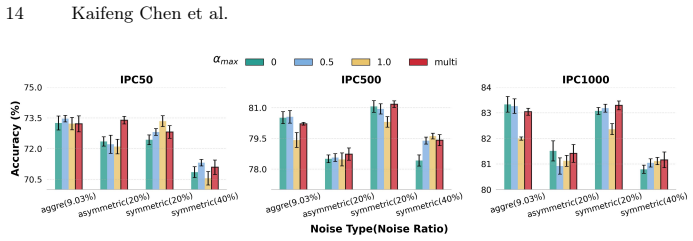
- [Experimental results] Experiments report consistent gains over DD baselines, but without ablations that hold the teacher fixed while varying noise asymmetry or that measure correlation between the combined SGR score and ground-truth cleanliness, it is unclear whether gains stem from the claimed mechanism or from other factors; this directly affects the robustness claim under asymmetric and real-world noise.
minor comments (2)
- [Abstract] The abstract states the framework is 'computationally lightweight' without quantifying training overhead or memory relative to baselines; add a table or paragraph with these metrics.
- [Method] Notation for 'second-split forgetting' and 'neighborhood consistency' should be defined with explicit formulas or pseudocode in the method section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications on the empirical foundations of our approach and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [SGR description (method section)] The central claim that SGR's fusion of global second-split forgetting with local neighborhood consistency produces a reweighting scheme monotonic in cleanliness (prioritizing clean supervision) is load-bearing but unsupported by any derivation or bound. In asymmetric noise, forgetting trajectories for noisy labels can overlap with clean ones after the first split, and TIAT's residual guidance from the same corrupted teacher does not resolve this dependence; no section provides a formal argument or test isolating this separation.
Authors: We acknowledge that the manuscript does not include a formal derivation or theoretical bound establishing that the SGR reweighting is strictly monotonic in label cleanliness. The design of SGR is motivated by empirical patterns observed in forgetting trajectories and neighborhood consistency under noise, as described in the method section, rather than a closed-form proof. Deriving such a bound is non-trivial given the dependence on teacher trajectory dynamics and would require assumptions that may not hold across all noise regimes; we view this as beyond the current scope. We will revise the method section to explicitly note the empirical motivation, potential overlaps in asymmetric noise, and the reliance on experimental validation rather than theoretical guarantees. revision: partial
-
Referee: [Experimental results] Experiments report consistent gains over DD baselines, but without ablations that hold the teacher fixed while varying noise asymmetry or that measure correlation between the combined SGR score and ground-truth cleanliness, it is unclear whether gains stem from the claimed mechanism or from other factors; this directly affects the robustness claim under asymmetric and real-world noise.
Authors: The reported experiments already evaluate performance across symmetric, asymmetric, and real-world noise settings, with the teacher trained on the corresponding noisy data. However, we agree that an ablation fixing the teacher while varying noise asymmetry would more directly isolate SGR's contribution. Similarly, while we have not reported Pearson or Spearman correlations between SGR scores and ground-truth cleanliness (as real-world settings lack such labels), this can be computed on the synthetic noise benchmarks. We will add these targeted ablations and correlation analyses to the experimental section in the revision to better substantiate the mechanism. revision: yes
Circularity Check
No circularity; derivation uses external training observables
full rationale
The framework defines SGR via second-split forgetting and neighborhood consistency, and TIAT via residual teacher dynamics; both are computed from observable training trajectories rather than fitted to or defined by the final distilled dataset quality. No equations reduce the reweighting or targets to the target result by construction, no self-citation chain is load-bearing for the central claim, and no ansatz or uniqueness theorem is smuggled in. The approach remains falsifiable against external noise benchmarks without internal redefinition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Global forgetting patterns (second-split forgetting) fused with local neighborhood consistency can prioritize clean supervision along the teacher trajectory without clean anchors.
- domain assumption Auxiliary residual guidance distilled from intermediate teacher dynamics reinforces informative signals while remaining internally consistent.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Machine Learning
Bahri, D., Jiang, H., Gupta, M.: Deep k-nn for noisy labels. In: International Conference on Machine Learning. pp. 540–550. PMLR (2020)
2020
- [2]
-
[3]
Chen, X., Yang, Y., Wang, Z., Mirzasoleiman, B.: Data distillation can be like vodka: Distilling more times for better quality (2023),https://arxiv. org/abs/2310.06982
-
[4]
arXiv preprint arXiv:2411.11924 (2024)
Cheng, L., Chen, K., Li, J., Tang, S., Zhang, S., Wang, M.: Dataset distillers are good label denoisers in the wild. arXiv preprint arXiv:2411.11924 (2024)
- [5]
- [6]
-
[7]
arXiv preprint arXiv:2408.14358 (2024)
Di Salvo, F., Doerrich, S., Rieger, I., Ledig, C.: An embedding is worth a thousand noisy labels. arXiv preprint arXiv:2408.14358 (2024)
- [8]
-
[9]
In: ICLR 2024-The Twelfth International Conference on Learning Representations, Messe Wien Exhibition and Congress Center, Vienna, Austria, May 7-11t, 2024 (2024)
Englesson, E., Azizpour, H.: Robust classification via regression for learning with noisy labels. In: ICLR 2024-The Twelfth International Conference on Learning Representations, Messe Wien Exhibition and Congress Center, Vienna, Austria, May 7-11t, 2024 (2024)
2024
-
[10]
IEEE Transactions on Neural Networks and Learning Systems35(11), 16036–16048 (2023)
Fang, C., Cheng, L., Mao, Y., Zhang, D., Fang, Y., Li, G., Qi, H., Jiao, L.: Separating noisy samples from tail classes for long-tailed image classifica- tion with label noise. IEEE Transactions on Neural Networks and Learning Systems35(11), 16036–16048 (2023)
2023
-
[11]
IEEE Transactions on Medical Imaging42(6), 1720– 1734 (2023)
Fang, C., Wang, Q., Cheng, L., Gao, Z., Pan, C., Cao, Z., Zheng, Z., Zhang, D.: Reliable mutual distillation for medical image segmentation under im- perfect annotations. IEEE Transactions on Medical Imaging42(6), 1720– 1734 (2023)
2023
- [12]
-
[13]
Advances in neural information processing systems31(2018)
Han, B., Yao, Q., Yu, X., Niu, G., Xu, M., Hu, W., Tsang, I., Sugiyama, M.: Co-teaching: Robust training of deep neural networks with extremely noisy labels. Advances in neural information processing systems31(2018)
2018
- [14]
-
[15]
2022 ieee
Iscen, A., Valmadre, J., Arnab, A., Schmid, C.: Learning with neighbor consistency for noisy labels. 2022 ieee. In: CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4662–4671 (2022) Robust Trajectory Distillation 17
2022
-
[16]
In: International conference on machine learning
Jiang, L., Zhou, Z., Leung, T., Li, L.J., Fei-Fei, L.: Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In: International conference on machine learning. pp. 2304–2313. PMLR (2018)
2018
-
[17]
Krizhevsky, A.: Learning multiple layers of features from tiny images (2009), https://api.semanticscholar.org/CorpusID:18268744
2009
-
[18]
CS 231N7(7), 3 (2015)
Le, Y., Yang, X.: Tiny imagenet visual recognition challenge. CS 231N7(7), 3 (2015)
2015
- [19]
-
[20]
In: European Conference on Computer Vision
Li, J., Li, G., Liu, F., Yu, Y.: Neighborhood collective estimation for noisy label identification and correction. In: European Conference on Computer Vision. pp. 128–145. Springer (2022)
2022
-
[21]
arXiv preprint arXiv:2002.07394 , year=
Li, J., Socher, R., Hoi, S.C.: Dividemix: Learning with noisy labels as semi- supervised learning. arXiv preprint arXiv:2002.07394 (2020)
-
[22]
WebVision Database: Visual Learning and Understanding from Web Data
Li, W., Wang, L., Li, W., Agustsson, E., Gool, L.V.: Webvision database: Visual learning and understanding from web data (2017),https://arxiv. org/abs/1708.02862
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Advances in neural information processing systems33, 20331–20342 (2020)
Liu, S., Niles-Weed, J., Razavian, N., Fernandez-Granda, C.: Early-learning regularization prevents memorization of noisy labels. Advances in neural information processing systems33, 20331–20342 (2020)
2020
-
[24]
In: International conference on machine learning
Liu, Y., Guo, H.: Peer loss functions: Learning from noisy labels without knowing noise rates. In: International conference on machine learning. pp. 6226–6236. PMLR (2020)
2020
- [25]
-
[26]
arXiv preprint arXiv:1905.10045 (2019)
Lyu, Y., Tsang, I.W.: Curriculum loss: Robust learning and generalization against label corruption. arXiv preprint arXiv:1905.10045 (2019)
-
[27]
Advances in Neural Information Processing Systems 35, 30044–30057 (2022)
Maini, P., Garg, S., Lipton, Z., Kolter, J.Z.: Characterizing datapoints via second-split forgetting. Advances in Neural Information Processing Systems 35, 30044–30057 (2022)
2022
-
[28]
when to update
Malach, E., Shalev-Shwartz, S.: Decoupling" when to update" from" how to update". Advances in neural information processing systems30(2017)
2017
-
[29]
CoRRabs/2107.13034(2021),https:// arxiv.org/abs/2107.13034
Nguyen, T., Novak, R., Xiao, L., Lee, J.: Dataset distillation with infinitely wide convolutional networks. CoRRabs/2107.13034(2021),https:// arxiv.org/abs/2107.13034
-
[30]
Training Deep Neural Networks on Noisy Labels with Bootstrapping
Reed, S., Lee, H., Anguelov, D., Szegedy, C., Erhan, D., Rabinovich, A.: Training deep neural networks on noisy labels with bootstrapping. arXiv preprint arXiv:1412.6596 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [31]
-
[32]
Advances in neural information processing systems32(2019) 18 Kaifeng Chen et al
Shu, J., Xie, Q., Yi, L., Zhao, Q., Zhou, S., Xu, Z., Meng, D.: Meta-weight- net: Learning an explicit mapping for sample weighting. Advances in neural information processing systems32(2019) 18 Kaifeng Chen et al
2019
-
[33]
In: International conference on machine learning
Song,H.,Kim,M.,Lee,J.G.:Selfie:Refurbishinguncleansamplesforrobust deep learning. In: International conference on machine learning. pp. 5907–
-
[34]
IEEE transactions on neural networks and learning systems34(11), 8135–8153 (2022)
Song, H., Kim, M., Park, D., Shin, Y., Lee, J.G.: Learning from noisy labels with deep neural networks: A survey. IEEE transactions on neural networks and learning systems34(11), 8135–8153 (2022)
2022
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Sun, P., Shi, B., Yu, D., Lin, T.: On the diversity and realism of dis- tilled dataset: An efficient dataset distillation paradigm. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[36]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tu, Y., Zhang, B., Li, Y., Liu, L., Li, J., Wang, Y., Wang, C., Zhao, C.R.: Learning from noisy labels with decoupled meta label purifier. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19934–19943 (2023)
2023
- [37]
-
[38]
In: 2018 IEEE 30th international conference on tools with artificial intelligence (ICTAI)
Wang, T., Huan, J., Li, B.: Data dropout: Optimizing training data for convolutional neural networks. In: 2018 IEEE 30th international conference on tools with artificial intelligence (ICTAI). pp. 39–46. IEEE (2018)
2018
-
[39]
Wang, T., Zhu, J., Torralba, A., Efros, A.A.: Dataset distillation. CoRR abs/1811.10959(2018),http://arxiv.org/abs/1811.10959
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
In: European Conference on Computer Vision
Wang, Y., Cheng, L., Duan, M., Wang, Y., Feng, Z., Kong, S.: Improv- ing knowledge distillation via regularizing feature direction and norm. In: European Conference on Computer Vision. pp. 20–37. Springer (2024)
2024
- [41]
-
[42]
Zhang, H., Li, S., Lin, F., Wang, W., Qian, Z., and Ge, S
Zhang, H., Li, S., Lin, F., Wang, W., Qian, Z., Ge, S.: Dance: Dual-view distribution alignment for dataset condensation (2024),https://arxiv. org/abs/2406.01063
- [43]
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, T., Xue, M., Zhang, J., Zhang, H., Wang, Y., Cheng, L., Song, J., Song, M.: Generalization matters: Loss minima flattening via parameter hybridization for efficient online knowledge distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20176–20185 (2023)
2023
-
[45]
Advances in neural information process- ing systems31(2018)
Zhang, Z., Sabuncu, M.: Generalized cross entropy loss for training deep neural networks with noisy labels. Advances in neural information process- ing systems31(2018)
2018
- [46]
- [47]
-
[48]
In: International Conference on Learning Representations (2021)
Zhou, T., Wang, S., Bilmes, J.: Robust curriculum learning: from clean label detection to noisy label self-correction. In: International Conference on Learning Representations (2021)
2021
- [49]
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, Y., Li, X., Liu, F., Wei, Q., Chen, X., Yu, L., Xie, C., Lungren, M.P., Xing, L.: L2b: Learning to bootstrap robust models for combating label noise. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23523–23533 (2024)
2024
-
[51]
In: International conference on machine learning
Zhu, Z., Dong, Z., Liu, Y.: Detecting corrupted labels without training a model to predict. In: International conference on machine learning. pp. 27412–27427. PMLR (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.