MemTrain: Self-Supervised Context Memory Training
Pith reviewed 2026-06-28 10:48 UTC · model grok-4.3
The pith
MemTrain uses two self-supervised proxy tasks on Wikipedia to train LLM agents for better memory maintenance across long interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
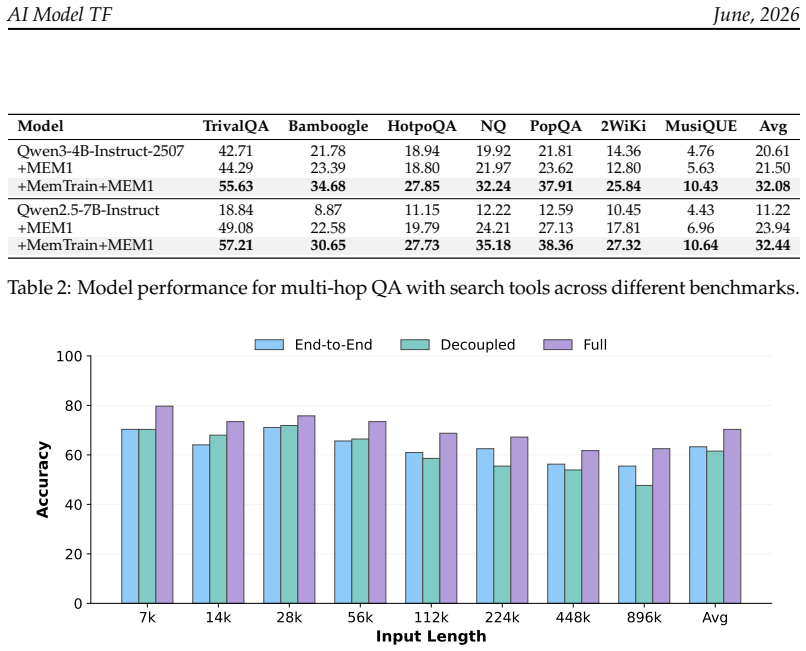
The central claim is that jointly optimizing an end-to-end masked reconstruction objective and an intermediate memory recall objective over unlabeled Wikipedia corpora produces memory maintenance and compression behaviors that transfer to downstream memory-intensive reasoning tasks, yielding higher performance than direct task-specific post-training.
What carries the argument
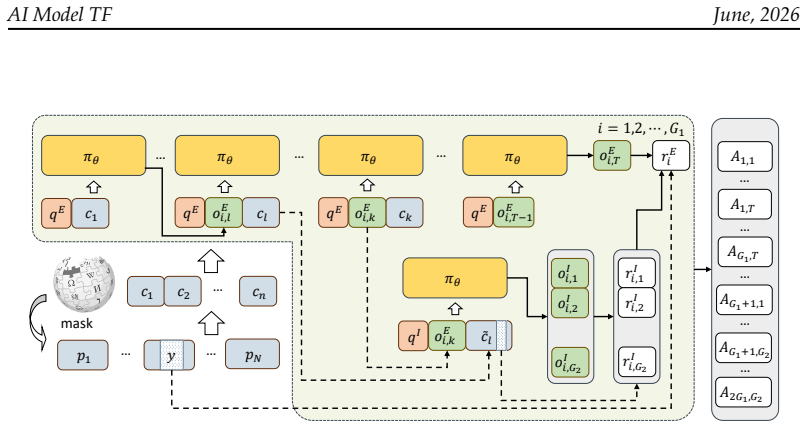
Two coupled proxy tasks over unlabeled Wikipedia corpora: (1) end-to-end masked reconstruction that requires recovering masked entities after multiple memory updates, and (2) intermediate memory recall that requires reconstructing historical information from intermediate states; the pair is optimized together with GRPO.
If this is right
- Downstream memory-intensive reasoning improves without the need to collect diverse annotated problems for each target task.
- The same pre-training procedure can be applied across different base models to raise their baseline memory capability before task-specific fine-tuning.
- Training cost and data-collection effort for long-horizon agents decrease because the memory objectives rely only on unlabeled text.
- Joint optimization of the two objectives encourages both outcome-level memory maintenance and step-by-step faithfulness during interactions.
Where Pith is reading between the lines
- The same proxy-task structure could be applied to other large unlabeled corpora to create domain-adapted memory models without new annotations.
- If the learned memory behaviors prove robust, the framework might shorten the amount of reinforcement learning needed when building agents for extended multi-turn scenarios.
- An ablation that removes one of the two objectives would show whether both compression faithfulness and end-to-end recovery are required for the observed transfer gains.
Load-bearing premise
The two proxy tasks built from Wikipedia will generate memory behaviors general enough to transfer to any downstream memory-intensive task.
What would settle it
A controlled test in which models trained with MemTrain show no improvement or a decline relative to direct post-training on a memory-intensive task whose required behaviors are unrelated to entity reconstruction or intermediate recall.
Figures
read the original abstract
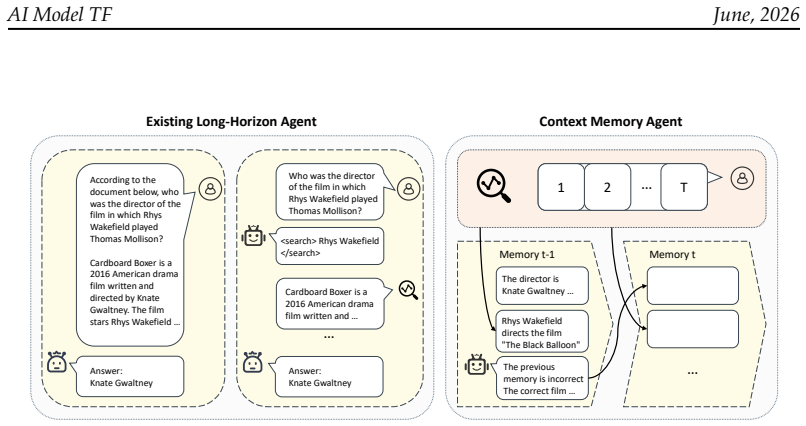
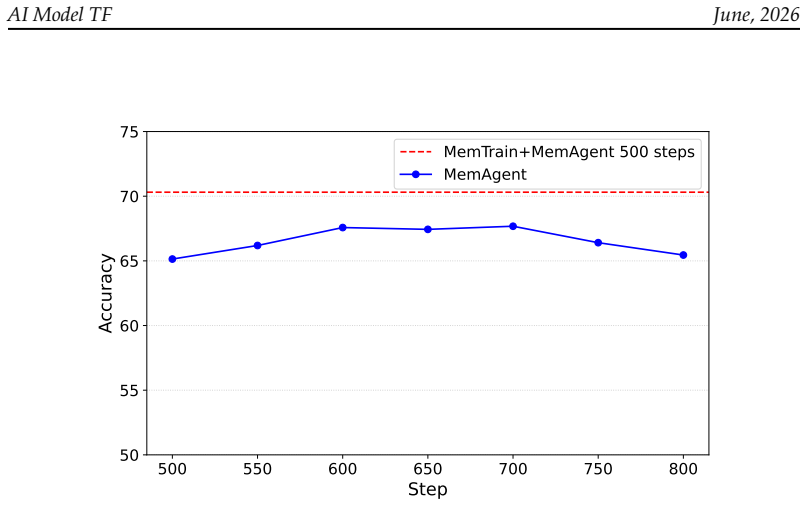
Memory is an indispensable capability for long-horizon LLM agents, enabling them to preserve and utilize information accumulated across extended interactions. Existing memory-agent approaches are typically trained end-to-end with reinforcement learning on downstream tasks. However, collecting high-quality annotated problems for memory-intensive scenarios is costly, and the resulting training data often lack sufficient diversity to cover general memory behaviors. In this work, we propose MemTrain, a self-supervised training framework for generally enhancing the context-memory capability of LLM agents for more effective downstream post-training. MemTrain introduces two coupled proxy tasks over unlabeled Wikipedia corpora: (1) an end-to-end masked reconstruction objective, which requires the model to recover masked entities after multiple rounds of memory updates, thereby encouraging memory maintenance from the final outcome perspective; and (2) an intermediate memory recall objective, which requires the model to reconstruct masked historical information using intermediate memory states, encouraging faithful compression and memory completeness throughout the interaction process. The two objectives are jointly optimized using GRPO. Extensive experiments on long-text QA and search-based QA benchmarks demonstrate that MemTrain consistently improves downstream memory-intensive reasoning performance across different models, achieving gains of up to 17.67 points over direct task-specific post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemTrain, a self-supervised framework for enhancing context memory in LLMs. It constructs two coupled proxy tasks on unlabeled Wikipedia corpora—an end-to-end masked reconstruction objective after multiple memory updates and an intermediate memory recall objective—jointly optimized with GRPO. The central claim is that this induces general memory maintenance and compression behaviors that transfer to improve downstream memory-intensive reasoning on long-text QA and search-based QA benchmarks, with gains of up to 17.67 points over direct task-specific post-training.
Significance. If the transfer from the proxy tasks is shown to be robust, the approach could offer a scalable alternative to RL-based end-to-end training on scarce annotated memory-intensive data, addressing a practical bottleneck for long-horizon LLM agents.
major comments (2)
- [Abstract] Abstract: the claim that the two proxy objectives 'encourage memory maintenance' and 'faithful compression' that transfer to arbitrary downstream tasks rests on untested intuition; the manuscript supplies no ablation, cross-domain validation, or argument showing these objectives cover the memory requirements of the cited benchmarks rather than Wikipedia-specific artifacts.
- [Abstract] Abstract: the reported gains of up to 17.67 points are presented without any description of the Wikipedia corpora used for proxy training, the downstream datasets, baseline implementations, controls for corpus exposure, or statistical tests, rendering the central empirical claim unevaluable.
minor comments (1)
- [Abstract] The acronym GRPO is used without expansion or citation on first appearance.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract. We address each point below and will make targeted revisions to strengthen the presentation of our claims and empirical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the two proxy objectives 'encourage memory maintenance' and 'faithful compression' that transfer to arbitrary downstream tasks rests on untested intuition; the manuscript supplies no ablation, cross-domain validation, or argument showing these objectives cover the memory requirements of the cited benchmarks rather than Wikipedia-specific artifacts.
Authors: The abstract summarizes the design intuition for the coupled proxy tasks. The full manuscript demonstrates transfer via consistent performance gains on long-text QA and search-based QA benchmarks that are distinct from the Wikipedia source. To directly address the concern, we will add ablations isolating the contribution of each objective and explicit arguments showing coverage of general memory requirements (maintenance across updates and faithful compression) rather than corpus artifacts. revision: yes
-
Referee: [Abstract] Abstract: the reported gains of up to 17.67 points are presented without any description of the Wikipedia corpora used for proxy training, the downstream datasets, baseline implementations, controls for corpus exposure, or statistical tests, rendering the central empirical claim unevaluable.
Authors: We agree the abstract is too concise on these elements. The body of the manuscript already specifies the Wikipedia corpora construction, the exact downstream long-text and search-based QA datasets, baseline implementations (including direct post-training controls), and corpus-exposure controls via held-out evaluation. We will revise the abstract to concisely include these details and report that statistical significance was evaluated across runs. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an empirical self-supervised training method using two proxy tasks on Wikipedia data, optimized via GRPO, followed by reported performance gains on downstream benchmarks. No mathematical derivation, first-principles result, or fitted quantity is claimed that reduces to its own inputs by construction. Claims rest on experimental comparisons rather than self-referential definitions, fitted predictions renamed as outputs, or load-bearing self-citations. The central premise (proxy tasks induce transferable memory behaviors) is an empirical hypothesis, not a closed definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. In Inˆes Lynce, Nello Murano, Mauro Vallati, Serena Villata, Federico Chesani, Michela Milano, Andrea Omicini, and Mehdi Dastani (eds.),ECAI 2025 - 28th European Conference on Artificial Intelli- gence, 25...
2025
-
[2]
doi: 10.3233/FAIA251160. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Z...
-
[3]
International Committee on Computational Linguistics. doi: 10.18653/v1/2020.coling-main.580. Wei Huang, Yizhe Xiong, Xin Ye, Zhijie Deng, Hui Chen, Zijia Lin, and Guiguang Ding. Fast Quiet-STaR: Thinking Without Thought Tokens. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Findings of the Association for Computat...
-
[4]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Association for Computational Linguistics. ISBN 979-8-89176-335-7. doi: 10.18653/v1/ 2025.findings-emnlp.1020. Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Regina Barzilay and Min-Yen Kan (eds.),Proceedings of the 55th Annual Meeting of the Associ...
-
[5]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Association for Computational Linguistics. doi: 10.18653/v1/P17-1147. Siheng Li, Kejiao Li, Zenan Xu, Guanhua Huang, Evander Yang, Kun Li, Haoyuan Wu, Jiajia Wu, Zihao Zheng, Chenchen Zhang, Kun Shi, Kyrierl Deng, Qi Yi, Ruibin Xiong, Tingqiang Xu, Yuhao Jiang, Jianfeng Yan, Yuyuan Zeng, Guanghui Xu, Jinbao Xue, Zhi- jiang Xu, Zheng Fang, Shuai Li, Qibin ...
-
[6]
Compressing Context to Enhance Inference Efficiency of Large Language Models
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. Compressing Context to Enhance Inference Efficiency of Large Language Models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 6342–6353, Singapore, December
2023
-
[7]
doi: 10.18653/v1/2023.emnlp-main.391
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.391. 11 AI Model TF June, 2026 Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-Zero-Like Training: A Critical Perspective, March
-
[8]
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.546. Hongjin Qian, Zhao Cao, and Zheng Liu. MemoBrain: Executive Memory as an Agentic Brain for Reasoning, January
-
[9]
Hybridflow: A flexible and efficient rlhf framework
doi: 10.1145/3689031.3696075. Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, A. J. Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker- Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexand...
-
[10]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, Ha...
2026
-
[11]
doi: 10.1162/tacl a 00475. Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Xinmiao Yu, Dingchu Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Minhao Cheng, Shuai Wang, Hong Cheng, and Jingren Zhou. ReSum: Unlocking Long-Horizon Search Intelli- gence via Context Summarization, March
work page internal anchor Pith review doi:10.1162/tacl
-
[12]
Pan, Hinrich Sch ¨utze, Volker Tresp, and Yunpu Ma
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Sch ¨utze, Volker Tresp, and Yunpu Ma. Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning. https://arxiv.org/abs/2508.19828v5, August
-
[13]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (eds.),Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processin...
2018
-
[14]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Association for Computational Linguistics. doi: 10.18653/v1/D18-1259. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models, March
-
[15]
CompAct: Compressing Retrieved Documents Actively for Question Answering
Chanwoong Yoon, Taewhoo Lee, Hyeon Hwang, Minbyul Jeong, and Jaewoo Kang. CompAct: Compressing Retrieved Documents Actively for Question Answering. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 21424–21439, Mi- ami, Florida, USA, November
2024
-
[16]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.1194. Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. MemAgent: Reshap- ing Long-Context LLM with Multi-Conv RL-based Memory Agent. InThe Fourteenth International Conference on Lea...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main.1194 2024
-
[17]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents. InThe Fourteenth International Conference on Learning Representations, October 2025a. Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Ru...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.