SFBench: The SciFy Scientific Feasibility Benchmark
Pith reviewed 2026-06-30 06:57 UTC · model grok-4.3
The pith
SFBench supplies 197 de novo materials science claims with expert feasibility scores to test AI assessment systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SFBench is a dataset of 197 materials science claims created de novo by subject matter experts, each paired with a ground-truth feasibility score on a five-point scale and an explanation. The claims are not drawn from existing publications, which reduces overlap with LLM training data, and the annotations originate from human specialists rather than artificial intelligence. The benchmark supports open-ended evaluation of systems that assess scientific feasibility rather than restricting responses to fixed formats.
What carries the argument
SFBench dataset of de novo expert-created claims with five-point feasibility scores and explanations for open-ended assessment.
If this is right
- Systems can be tested on a complex reasoning task involving claims that span a range of scientific feasibility levels.
- De novo creation enables evaluation without the confounding factor of potential training data overlap.
- Open-ended explanations allow assessment of model reasoning quality beyond binary or multiple-choice correctness.
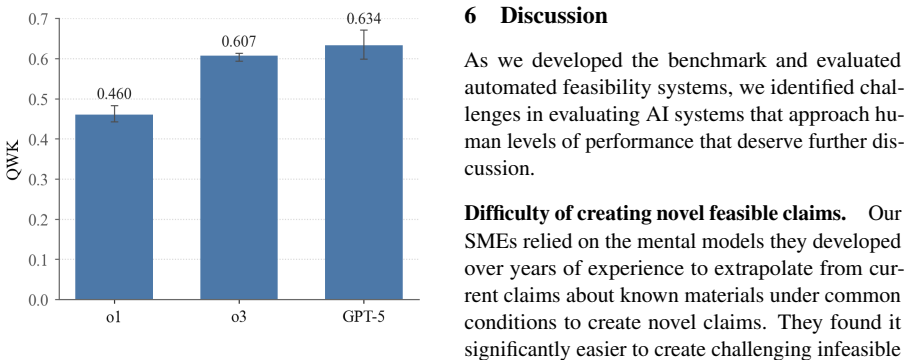
- Baseline GPT model results provide initial reference points for measuring future progress on feasibility judgment.
Where Pith is reading between the lines
- Similar expert-driven benchmark construction could be applied to feasibility assessment in scientific domains outside materials science.
- Model developers might adopt human validation steps when creating new test sets to preserve evaluation integrity.
- Detailed comparison of model-generated explanations against the expert ones could identify precise gaps in current reasoning capabilities.
- The benchmark design underscores the value of keeping evaluation data separate from the sources used to train the systems being tested.
Load-bearing premise
Subject matter experts can produce consistent and accurate feasibility scores and explanations that serve as reliable ground truth.
What would settle it
Independent experts assigning substantially different feasibility scores to a large portion of the same claims would undermine the stability of the provided annotations.
Figures
read the original abstract
We present SFBench, a benchmark dataset for evaluating systems that assess the feasibility of scientific claims. SFBench includes 197 claims in materials science, each annotated with a ground-truth feasibility score on a five-point scale along with an explanation of that assessment. The collection differs from previous collections in several important ways: 1) it defines a complex task that requires reasoning over claims of varying scientific feasibility; 2) its claims are not extracted from existing scientific publications but are created de novo, greatly reducing the chances that LLMs have trained on them; 3) claims and ground truth are established by subject matter experts, not by artificial intelligence; and 4) unlike many benchmarks that ask about question/answer pairs, provide multiple choice answers, or ask questions requiring short, fixed answers, SFBench explanations are completely open-ended. We describe the benchmark design, data creation process, and evaluation metrics, and we report baseline results using recent GPT models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SFBench, a benchmark of 197 materials-science claims created de novo by subject-matter experts. Each claim is annotated with a five-point feasibility score and an open-ended explanation. The work emphasizes four distinctions from prior collections (complex reasoning task, de-novo creation to reduce contamination, expert rather than AI annotation, and open-ended rather than fixed-format responses), describes the design and creation process, and supplies baseline GPT-model results.
Significance. If the expert annotations are shown to be reliable, SFBench would supply a useful, contamination-resistant resource for testing LLMs on scientific-feasibility reasoning. The de-novo expert construction and open-ended explanations address documented weaknesses in existing benchmarks that rely on extracted text or AI-generated labels.
major comments (1)
- [Data creation process] Data creation process section: the description of how claims and feasibility scores were produced supplies no information on the number of experts, annotation protocol, inter-expert agreement statistics, or any validation steps for the ground-truth scores. Because the benchmark's central claim rests on the quality of these expert annotations, the absence of these details prevents assessment of whether the ground truth supports the intended use.
minor comments (1)
- [Evaluation metrics] Evaluation metrics subsection: the precise definition of how open-ended model explanations are scored against the expert explanations is not stated explicitly enough to allow reproduction of the reported baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the data creation process. We agree that additional details are needed to allow proper assessment of the expert annotations and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Data creation process] Data creation process section: the description of how claims and feasibility scores were produced supplies no information on the number of experts, annotation protocol, inter-expert agreement statistics, or any validation steps for the ground-truth scores. Because the benchmark's central claim rests on the quality of these expert annotations, the absence of these details prevents assessment of whether the ground truth supports the intended use.
Authors: We agree that the current manuscript omits these details, which limits evaluation of annotation quality. In the revised manuscript we will expand the Data creation process section with the number of experts, the annotation protocol used, inter-expert agreement statistics, and validation steps performed. This revision will directly support the benchmark's central claim regarding expert ground truth. revision: yes
Circularity Check
No significant circularity in dataset presentation
full rationale
This is a benchmark dataset paper with no derivations, equations, fitted quantities, or predictions. The manuscript describes the de-novo creation of 197 expert-annotated materials-science claims, the annotation process, evaluation metrics, and GPT baselines. All central claims are descriptive statements about data construction and are self-contained; no step reduces by definition or self-citation to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Technical Report HR001124S0013, Defense Advanced Research Projects Agency (DARPA)
Broad Agency Announcement: Scientific Fea- sibility (SciFy). Technical Report HR001124S0013, Defense Advanced Research Projects Agency (DARPA). Accessed on October 8, 2025. Alexander R. Fabbri, Diego Mares, Jorge Flores, Meher Mankikar, Ernesto Hernandez, Dean Lee, Bing Liu, and Chen Xing. 2025. MultiNRC: A challenging and native multilingual reasoning ev...
-
[2]
R-Bench: Graduate-level multi-disciplinary benchmarks for LLM & MLLM complex reasoning evaluation.Preprint, arXiv:2505.02018. Wenhan Han, Yifan Zhang, Zhixun Chen, Binbin Liu, Haobin Lin, Bingni Zhang, Taifeng Wang, Mykola Pechenizkiy, Meng Fang, and Yin Zheng. 2025. MuBench: Assessment of multilingual capabilities of large language models across 61 langu...
-
[3]
Retrieval augmented scientific claim verifica- tion.JAMIA Open, 7(1):ooae021. Junteng Liu, Yuanxiang Fan, Zhuo Jiang, Han Ding, Yongyi Hu, Chi Zhang, Yiqi Shi, Shitong Weng, Aili Chen, Shiqi Chen, Yunan Huang, Mozhi Zhang, Pengyu Zhao, Junjie Yan, and Junxian He. 2025. Syn- Logic: Synthesizing verifiable reasoning data at scale for learning logical reason...
-
[4]
Long Phan, Alice Gatti, Nathaniel Li, Adam Khoja, Ryan Kim, and others
MDBench: A synthetic multi-document rea- soning benchmark generated with knowledge guid- ance.Preprint, arXiv:2506.14927. Long Phan, Alice Gatti, Nathaniel Li, Adam Khoja, Ryan Kim, and others. 2026. A benchmark of expert- level academic questions to assess AI capabilities. Nature, 649(8099):1139–1146. Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. K...
-
[5]
Can LLMs generate novel research ideas? a large-scale human study with 100+ NLP researchers. Preprint, arXiv:2409.04109. Koustuv Sinha, Shagun Sodhani, Jin Dong, Joelle Pineau, and William L. Hamilton. 2019. CLUTRR: A diagnostic benchmark for inductive reasoning from text. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Proce...
-
[6]
Evaluating Large Language Models in Scientific Discovery
Evaluating large language models in scientific discovery.Preprint, arXiv:2512.15567. Haoyang Su, Renqi Chen, Shixiang Tang, Zhenfei Yin, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi Wu, Hui Li, Wanli Ouyang, Philip Torr, Bowen Zhou, and Nanqing Dong. 2025. Many heads are better than one: Improved scientific idea generation by a LLM- based multi-agent system. In...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
FrontierScience: Evaluating AI’s Ability to Perform Expert-Level Scientific Tasks
Frontierscience: Evaluating ai’s ability to perform expert-level scientific tasks.Preprint, arXiv:2601.21165. Qingyun Wang, Doug Downey, Heng Ji, and Tom Hope. 2024a. SciMON: Scientific inspiration machines optimized for novelty. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 279–29...
-
[8]
Self-Preference Bias in LLM-as-a-Judge
Self-preference bias in LLM-as-a-judge. Preprint, arXiv:2410.21819. Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shen- gran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. 2025. The AI Scientist-v2: Workshop- level automated scientific discovery via agentic tree search.Preprint, arXiv:2504.08066. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- g...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
https://github.com/GAIR-NLP/ AIME-Preview
AIME-Preview: A rigorous and immedi- ate evaluation framework for advanced mathemat- ical reasoning. https://github.com/GAIR-NLP/ AIME-Preview. GitHub repository. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging ...
2023
-
[13]
(https://arxiv.org/pdf/2307.13067)
There are no known physical blockers at that pressure-temperature range. (https://arxiv.org/pdf/2307.13067)
-
[14]
Related materials in the lanthanum-hydride family have shown similar behavior. (https://arxiv.org/pdf/2308.02977, https://pubs.rsc.org/en/content/articlehtml/2025/tc/d5tc02600h, https://pubmed.ncbi.nlm.nih.gov/31118520/)
-
[15]
INPUT: Claim: Gallium dopant enhances fracture toughness of iron alloy
Based on the above evidence, La$_{4}$H$_{23}$ is scientifically feasible as a superconductor at 120 GPa. INPUT: Claim: Gallium dopant enhances fracture toughness of iron alloy. OUTPUT: Feasibility: -2 Explanation: 1. Gallium melts at 29.8$^{\circ}$C, so it will be a liquid at fabrication temperatures. (https://tsapps.nist.gov/srmext/certificates/archives/...
-
[16]
(https://www.sciencedirect.com/science/article/pii/S1359645404005543)
Liquids flow into microscopic crevices, especially along grain boundaries. (https://www.sciencedirect.com/science/article/pii/S1359645404005543)
-
[17]
(https://www.sciencedirect.com/science/article/abs/pii/S1359645408008495)
These boundaries become thin films of a Ga-rich phase. (https://www.sciencedirect.com/science/article/abs/pii/S1359645408008495)
-
[18]
This causes liquid-metal embrittlement which makes the alloy more susceptible to fracture. (https://link.springer.com/article/10.1007/s11661-021-06256-y, 14 https://www.osti.gov/pages/biblio/1479997)
-
[19]
type": "gold standard
Increased susceptibility to fracture is in direct disagreement with the enhanced fracture toughness claim. Therefore, this claim is infeasible. Now generate the output for: INPUT: Claim: {{claim}}. OUTPUT: 15 B Example Claims SFBench includes 197 claims in materials science. Each claim includes: • The text of the claim (a sentence or short paragraph) • Th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.