Learning to Learn from Multimodal Experience
Pith reviewed 2026-05-19 21:02 UTC · model grok-4.3
The pith
Agents can substantially improve their performance on multimodal tasks by learning to dynamically construct and use memory from their experiences rather than depending on fixed designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By shifting memory design from a predefined component to an adaptive and learnable process, agents dynamically construct, organize, and utilize memory based on task requirements and interaction history, which substantially enhances performance and generalization across multimodal tasks.
What carries the argument
The adaptive and learnable memory construction process that responds to task requirements and interaction history.
If this is right
- Agent performance increases on multimodal tasks involving perception, reasoning, and action.
- Generalization across different multimodal tasks improves.
- Memory utilization becomes more effective through dynamic organization.
- Reliance on manual memory schema design decreases.
Where Pith is reading between the lines
- Such adaptive memory could support more autonomous operation in complex real-world environments like autonomous driving or robotics.
- Comparing the evolution of memory structures over extended interactions might reveal patterns in how agents prioritize different experience types.
- This method opens questions about scalability when the space of possible memory organizations grows large.
Load-bearing premise
The best way to structure and use multimodal experience is highly dependent on the task at hand and changes as interactions proceed, so fixed memory designs cannot suffice.
What would settle it
Demonstrating equivalent or superior results using a well-chosen fixed memory design across the same set of multimodal tasks and environments would challenge the necessity of the adaptive approach.
Figures








read the original abstract
Experience-driven learning has emerged as a promising paradigm for enabling agents to improve from interaction trajectories by accumulating and reusing past experience. However, existing approaches are predominantly developed in textual settings and rely on manually designed memory schemas, limiting their applicability to multimodal environments. In real-world scenarios, experience is inherently multimodal, involving heterogeneous signals across perception, reasoning, and action, which makes effective memory design significantly more challenging. In particular, the optimal way to structure and utilize multimodal experience is highly task-dependent and evolves over time, rendering fixed memory designs insufficient. In this work, we propose a new paradigm, learning to learn from multimodal experience, which shifts memory design from a predefined component to an adaptive and learnable process. Our framework enables agents to dynamically construct, organize, and utilize memory based on task requirements and interaction history, effectively learning how to structure experience for improved performance. Experiments demonstrate that adaptive memory design substantially enhances agent performance and generalization across multimodal tasks, highlighting the critical role of learning memory mechanisms in experience-driven learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a paradigm shift in experience-driven learning for multimodal agents. It argues that manually designed fixed memory schemas are insufficient because optimal structuring of multimodal experience (perception, reasoning, action) is task-dependent and evolves over time. The authors introduce an adaptive, learnable memory framework that enables agents to dynamically construct, organize, and utilize memory based on task requirements and interaction history, claiming this leads to improved performance and generalization as demonstrated in experiments.
Significance. If the adaptive memory mechanism can be shown to deliver measurable gains over fixed baselines, the work would meaningfully advance agent architectures by moving memory design from a static engineering choice to a learnable component. This addresses a practical limitation in scaling experience-driven methods beyond text-only settings and could influence future multimodal agent research.
major comments (2)
- Abstract: The claim that 'Experiments demonstrate that adaptive memory design substantially enhances agent performance and generalization across multimodal tasks' is presented without any description of methods, metrics, baselines, controls, tasks, or quantitative results. This is load-bearing for the central empirical claim and prevents evaluation of whether the adaptive design actually outperforms fixed schemas.
- Framework description (throughout): The motivation that 'the optimal way to structure and utilize multimodal experience is highly task-dependent and evolves over time' is asserted but not supported by concrete contrasts with specific fixed memory designs or by showing how the proposed adaptive process avoids the stated limitations in practice.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our empirical claims and motivation.
read point-by-point responses
-
Referee: Abstract: The claim that 'Experiments demonstrate that adaptive memory design substantially enhances agent performance and generalization across multimodal tasks' is presented without any description of methods, metrics, baselines, controls, tasks, or quantitative results. This is load-bearing for the central empirical claim and prevents evaluation of whether the adaptive design actually outperforms fixed schemas.
Authors: We agree that the abstract would benefit from additional specificity to substantiate the central empirical claim. In the revised manuscript, we will expand the abstract to briefly reference the multimodal tasks evaluated, the fixed memory schema baselines used for comparison, the primary metrics (e.g., task success rate and generalization gap), and the magnitude of observed improvements. This will allow readers to better assess the results without substantially increasing length. revision: yes
-
Referee: Framework description (throughout): The motivation that 'the optimal way to structure and utilize multimodal experience is highly task-dependent and evolves over time' is asserted but not supported by concrete contrasts with specific fixed memory designs or by showing how the proposed adaptive process avoids the stated limitations in practice.
Authors: We acknowledge that the motivation section would be strengthened by more explicit contrasts. We will revise the framework description to include concrete examples of fixed memory designs (such as static hierarchical or embedding-based schemas) drawn from prior multimodal agent work, along with targeted analysis illustrating how the adaptive mechanism learns task-specific organizations from interaction history and thereby circumvents the rigidity of fixed structures. revision: yes
Circularity Check
No significant circularity in framework proposal
full rationale
The manuscript is a high-level framework proposal for adaptive memory design in multimodal agent learning. It contains no equations, formal derivations, or first-principles results that could reduce to fitted parameters, self-citations, or input data by construction. Claims about performance gains are presented as experimental outcomes rather than mathematical predictions, and the text does not invoke uniqueness theorems, ansatzes, or renamed empirical patterns from prior self-work in a load-bearing manner. The derivation chain is therefore self-contained as an engineering paradigm rather than a closed deductive loop.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
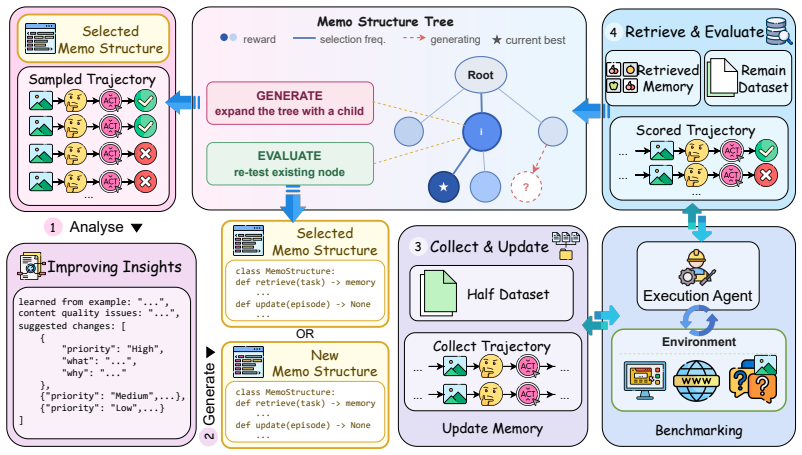
AUTOMMEMO represents each memory mechanism as an executable memo program... discovers effective memo programs through an iterative process of update-then-retrieve evaluation, reflection-guided mutation, and budget-aware tree search.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
**source_code** - A ‘MemoStructure‘ implementation coordinates memory; use private helpers or small inner abstractions for clarity. - **retrieve** / **update** are the only hooks the runtime calls. - code usage: Your memory structure will be used in the agent workflow: - ‘retrieve(recorder)‘: used **before** executing the task. It returns a “RetrievedMemo...
-
[2]
**examples** - **examples**: sampled retrieve trajectories, split into **FAILED TRAJECTORIES** and **SUCCESSFUL TRAJECTORIES**. - In each trajectory section below, every episode may include a text block starting with ‘retrieved_memory (JSON from retrieve before this episode):‘ — that is the serialized “RetrievedMemoryPayload“ from “retrieve“ (truncated in...
-
[3]
Need to use the score to analyze the performance and bottleneck of current memory structure
**benchmark_eval_score** - performance(success rate) of current memory stucture + general agent system. Need to use the score to analyze the performance and bottleneck of current memory structure. ### Your Task: You will analyze past suggestion examples(including past source code, suggestions, and the improve score it led to) and the current retrieved tra...
-
[4]
Look at the provided improve_score (positive → improvement, negative → degradation) and the single suggestion_example that produced that score
-
[5]
Step 2 — Inspect sampled trajectories and benchmark performance and decide which memories are useful
Explain why that suggestion led to improvement or degradation: - What pattern in the change made it succeed or fail? - Which behaviors, assumptions, or shortcuts in that suggestion were helpful? Which were harmful? - From these concrete cases, extract 2–5 general principles to adopt and 2–5 pitfalls to avoid when creating future suggestions. Step 2 — Insp...
-
[6]
For each episode, use the ‘retrieved_memory‘ JSON block when present (it is omitted when empty)
Review the sampled FAILED TRAJECTORIES first, then the SUCCESSFUL TRAJECTO- RIES. For each episode, use the ‘retrieved_memory‘ JSON block when present (it is omitted when empty)
-
[7]
Compare the two groups: identify which retrieved memories or retrieval patterns appear in successful runs, and which missing / noisy / misleading memories correlate with failed runs
-
[8]
For each retrieved memory item (or memory group) returned for the trajectory, label it as one of: - Useful & Relevant — clearly applies to the current situation and can guide action; - Potentially Useful — has value but needs reformatting, summarization, or indexing to be helpful; - Irrelevant / Confusing — not related to this trajectory or misleading; - ...
-
[9]
For each memory you mark Useful/Potentially Useful, say how it would help (e.g., provides a repeated subgoal, highlights a trap, identifies key object interactions)
-
[10]
Step 3 — Inspect memory source and produce concrete suggestions
For Irrelevant/Empty items, explain why they failed retrieval combine with the memory source code (e.g., wrong keying, over-specific content, missing summarization). Step 3 — Inspect memory source and produce concrete suggestions
-
[11]
Review the memory source code (retrieval keys, indexing, storage format, layers). Using Step 1 principles and Step 2 labels, propose specific changes to the memory system that address the observed issues
-
[12]
Combined the memory source code with your analysis in step 2, giving suggestions. For 30 each suggested change, include: - What to change (code-level or pipeline change, e.g., add summarization layer, change indexing key, normalize objects to noun-phrases). - Why it will help (link back to a principle or a concrete failing you observed)
-
[13]
Prioritize suggestions: label them High / Medium / Low priority and give an implementation order
-
[14]
Extra checks (quality & coherence)
Link Analysis to Benchmark Performance - Use benchmark_eval_score to identify which structural weaknesses correlate with poor performance. Extra checks (quality & coherence)
-
[15]
Flag obvious content issues: duplicates, empty entries, raw dumps, mis-typed fields, or numeric types that break JSON serialization
-
[16]
Check layer interaction: do layers pass structured outputs to each other, or only dump free-form text?
-
[17]
learned_from_suggestion_example
If retrieval returns empty lists or dicts, emphasize structural fixes (keying, ensure type consistency, avoid over-relying on try/except fallbacks). Goal: Combine reflection on past improvement signals with current system diagnosis to produce actionable, high-level suggestions that strengthen memory structure quality. ### Benchmark Information: {task\_des...
-
[22]
UTILITIES - G.copy(): Make a copy of the graph. - G.clear(): Remove all nodes and edges. - nx.to_dict_of_dicts(G): Convert graph to adjacency dict. - nx.to_numpy_array(G): Get adjacency matrix as a NumPy array. </GRAPH_DATABASE_INTERACTION> <CHROMA_DATABASE_INTERACTION> ## Initialize Chroma DB 35 Import: ‘from langchain_chroma import Chroma‘ Use ‘embedder...
-
[23]
You summarize browser trajectories
Multimodal Chat Client Class: MultimodalChatClient - Purpose: Asynchronous wrapper around OpenAI-compatible Chat Completions for text or multimodal user content. Use this when you need summarisation, synthesis, planning, or structured JSON output inside the memory code. - Initialization (memory structure code — **must** match the benchmark execution model...
-
[24]
")‘→‘{type:’text’, text:...}‘ - ‘embed_item_image_path(
Embedding Client Class: EmbeddingClient - Purpose: DashScope **qwen3-vl-embedding** (fixed model and fixed vector dimen- sion inside the class). Supports **fused** vectors for text-only, image(s), or text+image mixed inputs. Optional cosine similarity helpers. - Initialization (do **not** pass an embedding model name): from meta_self_evolve.llm.embedding ...
-
[29]
**Code Quality:** - Output clean, runnable Python code following PEP8. - Ensure ‘retrieve()‘ and ‘update()‘ accept ‘EpisodeRecorder‘ and orchestrate the pipeline end-to-end. - Initialize any stores or clients in ‘MemoStructure.__init__‘ as needed. - Define a module-level factory function exactly as ‘def build_memo() -> MemoStructure‘, and return an instan...
-
[30]
**Coherent Policy Logic:** - Avoid placeholders like pass or # TODO. - Avoid hard-coded if/else branches or enumerated case handling; instead, express the logic through modular policy functions, scoring mechanisms, or composable decision rules. - Instead of enumerating case-specific rules, express generalizable principles that could apply across different...
-
[33]
- G.adj[node]: Get dict of neighbors with edge data
TRA VERSAL / NEIGHBORHOOD - G.neighbors(node): Get neighbors of a node. - G.adj[node]: Get dict of neighbors with edge data. - nx.shortest_path(G, source, target): Find one shortest path between nodes. - nx.shortest_path_length(G, source, target): Get shortest path length. - nx.all_simple_paths(G, source, target, cutoff): Generate all simple paths up to a...
-
[34]
- G.degree(): Get degree for all nodes (DegreeView)
ANALYSIS / CENTRALITY - G.degree(node): Get degree (number of edges) for a single node. - G.degree(): Get degree for all nodes (DegreeView). - nx.degree_centrality(G): Compute degree centrality (dict of node -> score). - nx.betweenness_centrality(G): Compute betweenness centrality. - nx.pagerank(G): Compute PageRank scores for nodes. - nx.clustering(G): C...
-
[35]
UTILITIES - G.copy(): Make a copy of the graph. - G.clear(): Remove all nodes and edges. - nx.to_dict_of_dicts(G): Convert graph to adjacency dict. - nx.to_numpy_array(G): Get adjacency matrix as a NumPy array. </GRAPH_DATABASE_INTERACTION> <CHROMA_DATABASE_INTERACTION> ## Initialize Chroma DB Import: ‘from langchain_chroma import Chroma‘ Use ‘embedder = ...
-
[36]
You summarize browser trajectories
Multimodal Chat Client Class: MultimodalChatClient - Purpose: Asynchronous wrapper around OpenAI-compatible Chat Completions for text or multimodal user content. Use this when you need summarisation, synthesis, planning, or structured JSON output inside the memory code. - Initialization (memory structure code — **must** match the benchmark execution model...
-
[37]
")‘→‘{type:’text’, text:...}‘ - ‘embed_item_image_path(
Embedding Client Class: EmbeddingClient - Purpose: DashScope **qwen3-vl-embedding** (fixed model and fixed vector dimen- sion inside the class). Supports **fused** vectors for text-only, image(s), or text+image mixed inputs. Optional cosine similarity helpers. - Initialization (do **not** pass an embedding model name): from meta_self_evolve.llm.embedding ...
-
[38]
**Modular, clear design:** - Prefer a small, readable structure (private helpers, inner classes, or a single ‘MemoStructure‘ with well-named methods). Avoid unnecessary scaffolding. - If you use several stores (e.g. Chroma, graph), give each a clear role and data shape
-
[39]
- ‘retrieve()‘ can chain internal steps when that helps
**Retrieve / update orchestration:** - Implement ‘MemoStructure‘ with ‘retrieve‘ / ‘update‘. - ‘retrieve()‘ can chain internal steps when that helps. - ‘update()‘ should persist new evidence from the finished trajectory in a consistent order
-
[40]
**Out-of-the-Box Reasoning:** - Do not just mechanically call each layer one by one — think about the **semantic flow of information**. - Consider cases like: - what type of memory layer can be used according to the analysis result or task description, with the aim to better assist the agent to finish it’s task? - what order and input output should be bes...
-
[41]
The tools available will be listed in ‘TOOLS‘ section
**Integration with Utilities:** - Feel free to use any provided utility functions (e.g., similarity calculation, interaction with databases, hire new agent) if relevant. The tools available will be listed in ‘TOOLS‘ section. - You can also create your own tools if neccessary, think out of the box
-
[42]
**Code Quality:** - Output clean, runnable Python code following PEP8. - Ensure ‘retrieve()‘ and ‘update()‘ accept ‘EpisodeRecorder‘ and orchestrate the pipeline end-to-end. - Initialize any stores or clients in ‘MemoStructure.__init__‘ as needed. 46 - Define a module-level factory function exactly as ‘def build_memo() -> MemoStructure‘, and return an ins...
-
[43]
retrieve“ / “update“ pair; use private helpers or inner classes as needed
**Coherent Policy Logic:** - Avoid placeholders like pass or # TODO. - Avoid hard-coded if/else branches or enumerated case handling; instead, express the logic through modular policy functions, scoring mechanisms, or composable decision rules. - Instead of enumerating case-specific rules, express generalizable principles that could apply across different...
-
[44]
NODE OPERATIONS - G.add_node(node, **attrs): Add a single node with optional attributes. - G.add_nodes_from([n1, n2], **common_attrs): Add multiple nodes at once (shared attributes apply to all). - G.remove_node(node): Remove a node and all edges connected to it. - G.remove_nodes_from([n1, n2]): Remove multiple nodes. - node in G: Check if a node exists. ...
-
[45]
EDGE OPERATIONS - G.add_edge(u, v, **attrs): Add an edge between two nodes. - G.add_edges_from([(u, v), (x, y)], **attrs): Add multiple edges at once (shared attributes apply to all). - G.remove_edge(u, v): Remove a single edge. - G.remove_edges_from([(u, v), (x, y)]): Remove multiple edges. - G.has_edge(u, v): Check if an edge exists. - G.edges: Get all ...
-
[46]
- G.adj[node]: Get dict of neighbors with edge data
TRA VERSAL / NEIGHBORHOOD - G.neighbors(node): Get neighbors of a node. - G.adj[node]: Get dict of neighbors with edge data. - nx.shortest_path(G, source, target): Find one shortest path between nodes. - nx.shortest_path_length(G, source, target): Get shortest path length. - nx.all_simple_paths(G, source, target, cutoff): Generate all simple paths up to a...
-
[47]
- G.degree(): Get degree for all nodes (DegreeView)
ANALYSIS / CENTRALITY - G.degree(node): Get degree (number of edges) for a single node. - G.degree(): Get degree for all nodes (DegreeView). - nx.degree_centrality(G): Compute degree centrality (dict of node -> score). - nx.betweenness_centrality(G): Compute betweenness centrality. 49 - nx.pagerank(G): Compute PageRank scores for nodes. - nx.clustering(G)...
-
[48]
UTILITIES - G.copy(): Make a copy of the graph. - G.clear(): Remove all nodes and edges. - nx.to_dict_of_dicts(G): Convert graph to adjacency dict. - nx.to_numpy_array(G): Get adjacency matrix as a NumPy array. </GRAPH_DATABASE_INTERACTION> <CHROMA_DATABASE_INTERACTION> ## Initialize Chroma DB Import: ‘from langchain_chroma import Chroma‘ Use ‘embedder = ...
-
[49]
You summarize browser trajectories
Multimodal Chat Client Class: MultimodalChatClient - Purpose: Asynchronous wrapper around OpenAI-compatible Chat Completions for text or multimodal user content. Use this when you need summarisation, synthesis, planning, or structured JSON output inside the memory code. - Initialization (memory structure code — **must** match the benchmark execution model...
-
[50]
")‘→‘{type:’text’, text:...}‘ - ‘embed_item_image_path(
Embedding Client Class: EmbeddingClient - Purpose: DashScope **qwen3-vl-embedding** (fixed model and fixed vector dimen- sion inside the class). Supports **fused** vectors for text-only, image(s), or text+image mixed inputs. Optional cosine similarity helpers. - Initialization (do **not** pass an embedding model name): from meta_self_evolve.llm.embedding ...
-
[51]
Delete existing content in a textbox and then type content
-
[52]
Multiple scrolls are allowed to browse the webpage
Scroll up or down. Multiple scrolls are allowed to browse the webpage. Pay attention!! The default scroll is the whole window. If the scroll widget is located in a certain area of the webpage, then you have to specify a Web Element in that area. I would hover the mouse there and then scroll
-
[53]
Typically used to wait for unfinished webpage processes, with a duration of 5 seconds
Wait. Typically used to wait for unfinished webpage processes, with a duration of 5 seconds
-
[54]
Go back, returning to the previous webpage
-
[55]
When you can’t find information in some websites, try starting over with Google
Google, directly jump to the Google search page. When you can’t find information in some websites, try starting over with Google
-
[56]
This action should only be chosen when all questions in the task have been solved
Answer. This action should only be chosen when all questions in the task have been solved. Correspondingly, Action should STRICTLY follow the format: - Click [Numerical_Label] - Type [Numerical_Label]; [Content] - Scroll [Numerical_Label or WINDOW]; [up or down] - Wait - GoBack - Google - ANSWER; [content] Key Guidelines You MUST follow: * Action guidelines *
-
[57]
After typing, the system automatically hits ‘ENTER‘ key
To input text, NO need to click textbox first, directly type content. After typing, the system automatically hits ‘ENTER‘ key. Sometimes you should click the search button to apply search filters. Try to use simple language when searching
-
[58]
You must Distinguish between textbox and search button, don’t type content into the button! If no textbox is found, you may need to click the search button first before the textbox is displayed
-
[59]
Execute only one action per iteration
-
[60]
You may have selected the wrong web element or numerical label
STRICTLY Avoid repeating the same action if the webpage remains unchanged. You may have selected the wrong web element or numerical label. Continuous use of the Wait is also NOT allowed
-
[61]
Flexibly combine your own abilities 53 with the information in the web page
When a complex Task involves multiple questions or steps, select "ANSWER" only at the very end, after addressing all of these questions (steps). Flexibly combine your own abilities 53 with the information in the web page. Double check the formatting requirements in the task when ANSWER. * Web Browsing Guidelines *
-
[62]
Pay attention to Key Web Elements like search textbox and menu
Don’t interact with useless web elements like Login, Sign-in, donation that appear in Webpages. Pay attention to Key Web Elements like search textbox and menu
-
[63]
Clicking to download PDF is allowed and will be analyzed by the Assistant API
Vsit video websites like YouTube is allowed BUT you can’t play videos. Clicking to download PDF is allowed and will be analyzed by the Assistant API
-
[64]
Ensure you don’t mix them up with other numbers (e.g
Focus on the numerical labels in the TOP LEFT corner of each rectangle (element). Ensure you don’t mix them up with other numbers (e.g. Calendar) on the page
-
[65]
It may be necessary to find the correct year, month and day at calendar
Focus on the date in task, you must look for results that match the date. It may be necessary to find the correct year, month and day at calendar
-
[66]
Try your best to find the answer that best fits the task
Pay attention to the filter and sort functions on the page, which, combined with scroll, can help you solve conditions like ’highest’, ’cheapest’, ’lowest’, ’earliest’, etc. Try your best to find the answer that best fits the task. Your reply should strictly follow the format: Thought: {Your brief thoughts (briefly summarize the info that will help ANSWER...
-
[67]
Web Task Instruction: This is a clear and specific directive provided in natural lan- guage, detailing the online activity to be carried out. These requirements may include conducting searches, verifying information, comparing prices, checking availability, or any other action relevant to the specified web service (such as Amazon, Apple, ArXiv, BBC News, ...
-
[68]
It serves as visual proof of the actions taken in response to the instruction
Result Screenshots: This is a visual representation of the screen showing the result or intermediate state of performing a web task. It serves as visual proof of the actions taken in response to the instruction
-
[69]
Result Response: This is a textual response obtained after the execution of the web task. It serves as textual result in response to the instruction. – You DO NOT NEED to interact with web pages or perform actions such as booking flights or conducting searches on websites. – You SHOULD NOT make assumptions based on information not presented in the screens...
-
[70]
**Question**: {question}
-
[71]
**Ground Truth Answer**: {ground\_truth}
-
[72]
Output an integer score: 1 for correct, 0 for incorrect
**Model Predicted Answer**: {prediction} Evaluate the model’s prediction against the ground truth. Output an integer score: 1 for correct, 0 for incorrect. Respond using exactly: Score: 1 or Score: 0 Explanation: <your explanation> Prompt 9: AgentVista Visit Tool Summary Prompt 55 AgentVista Visit Tool Summary Prompt [SYSTEM] You are a helpful assistant t...
-
[73]
**Content Scanning**: Locate the **specific sections/data** directly related to the user’s goal within the webpage content
-
[74]
Never miss any important information
**Key Extraction**: Identify and extract the **most relevant information** from the content. Never miss any important information. Output the **full original context** as far as possible (can be more than three paragraphs)
-
[75]
**Summary Output**: Organize into a concise paragraph with logical flow, prioritizing clarity and judging the contribution of the information to the goal ## **Output Format** Please respond in JSON format with the following fields: { "evidence": "Key quotes or facts from the page that are directly relevant to the goal", "summary": "A concise summary of ho...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.