HVPNet: A Bio-Inspired Network for General Salient and Camouflaged Object Detection
Pith reviewed 2026-07-01 06:07 UTC · model grok-4.3
The pith
A bio-inspired network modeled on retinal integration and cortical decoding detects salient and camouflaged objects accurately across modalities with simpler structure than complex fusion methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
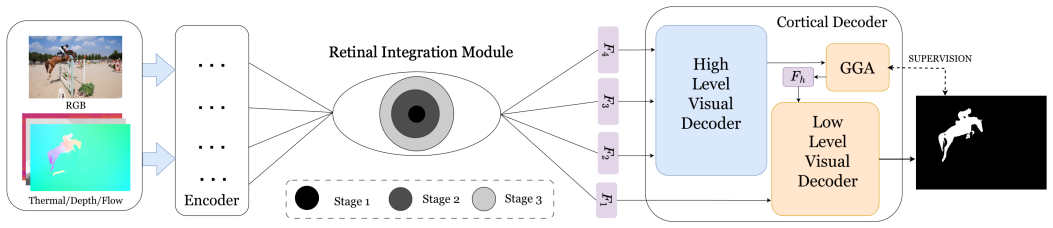
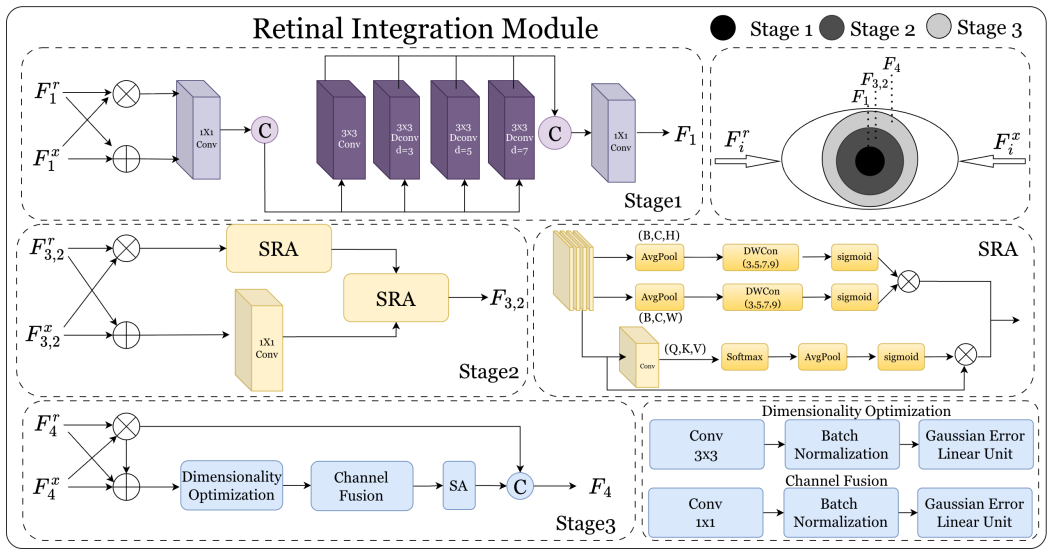
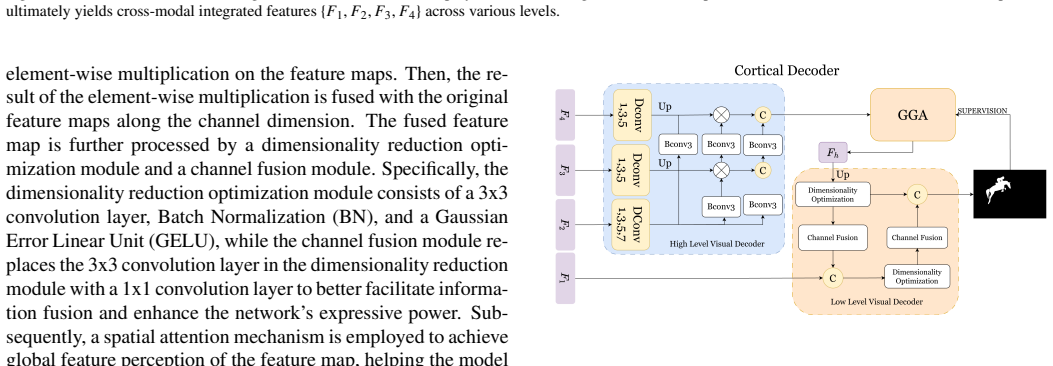
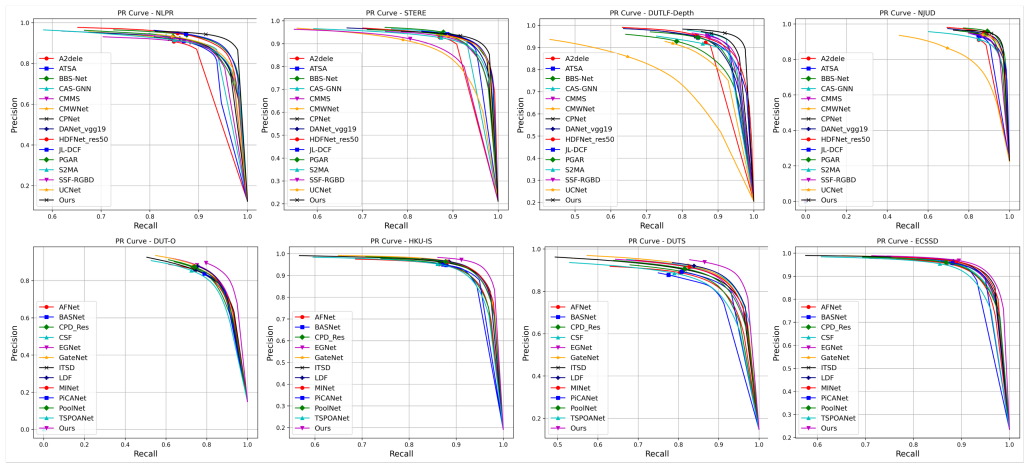
HVPNet is built around a Retinal Integration Module that fuses multimodal features via level-specific multi-stage integration and a cortical decoder that splits decoding into low- and high-level stages. This pair of components lets the single architecture extend directly to seven tasks across four modalities and deliver competitive accuracy with lower complexity on 22 datasets without extra fusion modules or task-specific tuning.
What carries the argument
Retinal Integration Module (RIM) that applies level-specific multi-stage integration to multimodal features, paired with a cortical decoder (CD) that separates low- and high-level visual processing stages.
If this is right
- The single architecture applies unchanged to seven distinct detection tasks spanning four input modalities.
- Accuracy-efficiency trade-offs hold across all 22 evaluated datasets for both salient and camouflaged object detection.
- Structural redundancy is reduced by replacing explicit cross-modal fusion blocks with staged retinal-style integration.
- No task-specific redesign or additional modules are required to reach the reported performance levels.
Where Pith is reading between the lines
- The staged integration pattern could be tested on other multimodal vision problems such as semantic segmentation or instance segmentation.
- Efficiency gains may prove especially useful in embedded or mobile settings where parameter count directly limits deployment.
- Further work might check whether the low/high-level split in the decoder aligns with measurable differences in feature complexity at those stages.
Load-bearing premise
That modeling retinal multi-stage integration and cortical hierarchy produces simpler yet equally or more accurate detection by avoiding the redundancy of conventional cross-modal fusion.
What would settle it
Direct comparison on one of the 22 multimodal datasets where a standard complex fusion model records both higher detection accuracy and lower runtime or parameter count than HVPNet.
Figures




read the original abstract
In recent years, most research on multimodal salient object detection (SOD) and camouflaged object detection (COD) typically aims to improve performance through complex cross-modal feature fusion and decoding structures. However, this approach leads to an excessively large model parameter scale and often fails to deliver satisfactory detection performance due to structural redundancy. In contrast, the human visual process is able to efficiently perform salient and camouflaged object identification without such complex structures. This contrast raises an important question: Can we draw conceptual inspiration from the human visual process to achieve a simpler modeling strategy, and still realize accurate and efficient object detection? To answer this question, we propose HVPNet, a simple yet general bio-inspired computational architecture. Drawing on the multi-layered information integration of the retina as a conceptual metaphor, we designed a Retinal Integration Module (RIM), which effectively integrates multimodal features through a level-specific multi-stage integration strategy. To fully exploit these features, we further design a cortical decoder (CD) that breaks down the decoding process into low- and high-level visual stages, abstracting the hierarchical processing in the human visual cortex. Benefiting from these designs, HVPNet can readily extend to seven tasks across four modalities. Without bells and whistles, it establishes an excellent accuracy-efficiency trade-off across 22 datasets spanning these seven tasks. Our code is available at https://github.com/jiaweiXu1029/HVPNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HVPNet, a bio-inspired architecture for salient object detection (SOD) and camouflaged object detection (COD). It introduces a Retinal Integration Module (RIM) that performs level-specific multi-stage integration of multimodal features, modeled on retinal processing, and a cortical decoder (CD) that decomposes decoding into low- and high-level stages, modeled on cortical hierarchy. The central claim is that this simpler design avoids structural redundancy of conventional cross-modal fusion, extends readily to seven tasks across four modalities, and delivers an excellent accuracy-efficiency trade-off on 22 datasets without bells and whistles.
Significance. If the quantitative results and ablations hold, the work would demonstrate that a bio-inspired, non-redundant architecture can match or exceed the performance of more complex fusion-based models while remaining lightweight, offering a practical template for general multimodal detection across modalities and tasks.
major comments (1)
- [Abstract] Abstract: the central claim of performance gains and an 'excellent accuracy-efficiency trade-off' across 22 datasets is asserted without any tables, ablation studies, statistical tests, or implementation details visible in the manuscript text, rendering it impossible to assess whether the empirical results support the claim or are affected by post-hoc choices.
Simulated Author's Rebuttal
We thank the referee for their review. The manuscript contains extensive experimental validation supporting the abstract claims; we address the specific concern below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of performance gains and an 'excellent accuracy-efficiency trade-off' across 22 datasets is asserted without any tables, ablation studies, statistical tests, or implementation details visible in the manuscript text, rendering it impossible to assess whether the empirical results support the claim or are affected by post-hoc choices.
Authors: The full manuscript text includes Section 4 (Experiments) with 22 datasets, seven tasks, and four modalities. It reports quantitative tables comparing HVPNet against state-of-the-art methods on all benchmarks, ablation studies isolating RIM and CD contributions, efficiency metrics (parameters, FLOPs, FPS), and implementation details (training protocol, hyperparameters). Consistent gains across diverse datasets provide the empirical basis summarized in the abstract; no post-hoc selection is involved as all reported results follow the same protocol. revision: no
Circularity Check
No significant circularity
full rationale
The paper's central claim is an empirical performance result: a bio-inspired architecture (RIM + hierarchical cortical decoder) achieves strong accuracy-efficiency trade-offs when evaluated on 22 external public datasets across seven tasks and four modalities. No equations, fitted parameters, or self-citations are presented that reduce the reported metrics to algebraic identities or inputs introduced within the same paper. The design motivation draws on biological metaphors but does not define the evaluation quantities in terms of themselves, and the quantitative claims rest on measured benchmark numbers rather than internal construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Architecture hyperparameters and training schedule
axioms (1)
- domain assumption The human visual system performs multimodal object identification via layered retinal integration followed by hierarchical cortical decoding.
invented entities (2)
-
Retinal Integration Module (RIM)
no independent evidence
-
Cortical decoder (CD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Z. Luo, N. Liu, W. Zhao, X. Yang, D. Zhang, D.-P. Fan, F. Khan, J. Han, Vscode: General visual salient and cam- ouflaged object detection with 2d prompt learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 17169–17180
2024
-
[2]
Lysova, Intersecting perspectives: Video surveillance in urban spaces through surveillance society and security state frameworks, Cities 156 (2025) 105544
T. Lysova, Intersecting perspectives: Video surveillance in urban spaces through surveillance society and security state frameworks, Cities 156 (2025) 105544
2025
-
[3]
Y . Yu, C. Wang, Q. Fu, R. Kou, F. Huang, B. Yang, T. Yang, M. Gao, Techniques and challenges of image segmentation: A review, Electronics 12 (5) (2023) 1199
2023
-
[4]
Z. Zou, K. Chen, Z. Shi, Y . Guo, J. Ye, Object detection in 20 years: A survey, Proceedings of the IEEE 111 (3) (2023) 257–276
2023
-
[5]
Apostolidis, E
E. Apostolidis, E. Adamantidou, A. I. Metsai, V . Mezaris, I. Patras, Video summarization using deep neural networks: A survey, Proceedings of the IEEE 109 (11) (2021) 1838–1863
2021
-
[6]
C. Yang, L. Zhang, H. Lu, X. Ruan, M.-H. Yang, Saliency detection via graph-based manifold ranking, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 3166–3173
2013
-
[7]
Y . Niu, Y . Geng, X. Li, F. Liu, Leveraging stereopsis for saliency analysis, in: 2012 IEEE conference on com- puter vision and pattern recognition, IEEE, 2012, pp. 454–461
2012
-
[8]
G. Wang, C. Li, Y . Ma, A. Zheng, J. Tang, B. Luo, Rgb-t saliency detection benchmark: Dataset, baselines, anal- ysis and a novel approach, in: Image and graphics tech- nologies and applications: 13th conference on image and graphics technologies and applications, IGTA 2018, Bei- jing, China, April 8–10, 2018, revised selected papers 13, Springer, 2018, p...
2018
-
[9]
F. Li, T. Kim, A. Humayun, D. Tsai, J. M. Rehg, Video segmentation by tracking many figure-ground segments, in: Proceedings of the IEEE international conference on computer vision, 2013, pp. 2192–2199
2013
-
[10]
T.-N. Le, T. V . Nguyen, Z. Nie, M.-T. Tran, A. Sugi- moto, Anabranch network for camouflaged object seg- mentation, Computer vision and image understanding 184 (2019) 45–56
2019
-
[11]
Bideau, E
P. Bideau, E. Learned-Miller, It’s moving! a probabilistic model for causal motion segmentation in moving camera videos, in: Computer Vision–ECCV 2016: 14th Euro- pean Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VIII 14, Springer, 2016, pp. 433–449
2016
-
[12]
X. Fang, M. Jiang, J. Zhu, X. Shao, H. Wang, Group- transnet: Group transformer network for rgb-d salient object detection, Neurocomputing 594 (2024) 127865
2024
-
[13]
K. Wang, Z. Tu, C. Li, C. Zhang, B. Luo, Learning adap- tive fusion bank for multi-modal salient object detection, IEEE Transactions on Circuits and Systems for Video Technology 34 (8) (2024) 7344–7358
2024
-
[14]
B. Yin, X. Zhang, D.-P. Fan, S. Jiao, M.-M. Cheng, L. Van Gool, Q. Hou, Camoformer: Masked separable attention for camouflaged object detection, IEEE Trans- actions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[15]
Z. Wu, D. P. Paudel, D.-P. Fan, J. Wang, S. Wang, C. De- monceaux, R. Timofte, L. Van Gool, Source-free depth for object pop-out, in: ICCV , 2023
2023
-
[16]
H. Wen, K. Song, L. Huang, H. Wang, Y . Yan, Cross- modality salient object detection network with univer- sality and anti-interference, Knowledge-Based Systems 264 (2023) 110322
2023
-
[17]
H. Gao, Y . Su, F. Wang, H. Li, Heterogeneous fusion and integrity learning network for rgb-d salient object de- tection, ACM Transactions on Multimedia Computing, Communications and Applications 20 (7) (2024) 1–24
2024
-
[18]
G. Chen, Q. Wang, B. Dong, R. Ma, N. Liu, H. Fu, Y . Xia, Em-trans: Edge-aware multimodal transformer for rgb-d salient object detection, IEEE Transactions on Neural Networks and Learning Systems 36 (2) (2024) 3175–3188
2024
-
[19]
J. Xu, Q. Zhou, J. Yu, C. Liao, D. Zhu, Semantic- orthogonal multi-modal attention network for rgb-d salient object detection, The Visual Computer (2025) 1– 13
2025
-
[20]
J. Zhu, X. Qin, A. Elsaddik, Dc-net: Divide-and-conquer for salient object detection, Pattern Recognition 157 (2025) 110903
2025
-
[21]
F. Sun, P. Ren, B. Yin, F. Wang, H. Li, Catnet: A cascaded and aggregated transformer network for rgb-d salient object detection, IEEE Transactions on Multime- dia 26 (2023) 2249–2262
2023
-
[22]
X. Hu, F. Sun, J. Sun, F. Wang, H. Li, Cross-modal fu- sion and progressive decoding network for rgb-d salient object detection, International Journal of Computer Vi- sion 132 (8) (2024) 3067–3085. 13
2024
-
[23]
Gollisch, M
T. Gollisch, M. Meister, Eye smarter than scientists be- lieved: neural computations in circuits of the retina, Neu- ron 65 (2) (2010) 150–164
2010
-
[24]
D. C. Van Essen, C. H. Anderson, D. J. Felleman, Infor- mation processing in the primate visual system: an in- tegrated systems perspective, Science 255 (5043) (1992) 419–423
1992
-
[25]
Zhang, Z.-F
Y .-J. Zhang, Z.-F. Yu, J. K. Liu, T.-J. Huang, Neural decoding of visual information across different neural recording modalities and approaches, Machine Intelli- gence Research 19 (5) (2022) 350–365
2022
- [26]
-
[27]
Z. Wu, L. Su, Q. Huang, Cascaded partial decoder for fast and accurate salient object detection, in: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[28]
J.-J. Liu, Q. Hou, Z.-A. Liu, M.-M. Cheng, Poolnet+: Exploring the potential of pooling for salient object de- tection, IEEE Transactions on Pattern Analysis and Ma- chine Intelligence 45 (1) (2023) 887–904
2023
-
[29]
X. Zhou, K. Shen, Z. Liu, Admnet: Attention-guided densely multi-scale network for lightweight salient ob- ject detection, IEEE Transactions on Multimedia 26 (2024) 10828–10841
2024
-
[30]
B.-W. Yin, Z. Lin, Exploring salient object detection with adder neural networks, in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 39, 2025, pp. 9490–9498
2025
-
[31]
Zhuge, D.-P
M. Zhuge, D.-P. Fan, N. Liu, D. Zhang, D. Xu, L. Shao, Salient object detection via integrity learning, IEEE Transactions on Pattern Analysis and Machine Intelli- gence 45 (3) (2023) 3738–3752
2023
-
[32]
Y . K. Yun, W. Lin, Towards a complete and detail- preserved salient object detection, IEEE Transactions on Multimedia 26 (2023) 4667–4680
2023
-
[33]
Y . Wang, R. Wang, X. Fan, T. Wang, X. He, Pixels, re- gions, and objects: Multiple enhancement for salient ob- ject detection, in: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2023, pp. 10031–10040
2023
-
[34]
N. Liu, N. Zhang, K. Wan, L. Shao, J. Han, Visual saliency transformer, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 4722–4732
2021
-
[35]
J. Xu, Q. Zhou, D. Zhu, Y . Chen, Y . Yi, X. Zhao, Tp- seg: Task-prototype framework for unified medical le- sion segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2026, pp. 5452–5462
2026
-
[36]
Q. Zhou, J. Xu, Y . Chen, D. Zhu, Y . Yi, X. Zhao, Dif- ferseg: Towards diverse multimodal binary segmentation via differential perception and frequency guidance, IEEE Transactions on Circuits and Systems for Video Technol- ogy (2026)
2026
-
[37]
Zhong, J
M. Zhong, J. Sun, P. Ren, F. Wang, F. Sun, Magnet: multi-scale awareness and global fusion network for rgb- d salient object detection, Knowledge-Based Systems 299 (2024) 112126
2024
-
[38]
H. Chen, F. Shen, D. Ding, Y . Deng, C. Li, Disentangled cross-modal transformer for rgb-d salient object detec- tion and beyond, IEEE Transactions on Image Process- ing (2024)
2024
-
[39]
N. Liu, Z. Luo, N. Zhang, J. Han, Vst++: Efficient and stronger visual saliency transformer, IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[40]
F. Sun, W. Zhou, W. Yan, Y . Zhang, Hfenet: Hybrid fea- ture encoder network for detecting salient objects in rgb- thermal images, Digital Signal Processing 148 (2024) 104439
2024
-
[41]
S. Duan, X. Yang, N. Wang, X. Gao, Lightweight rgb-d salient object detection from a speed-accuracy tradeoffperspective, IEEE Transactions on Image Pro- cessingEarly Access (2025)
2025
-
[42]
B. Xu, Q. Jiang, X. Zhao, C. Lu, H. Liang, R. Liang, Multidimensional exploration of segment any- thing model for weakly supervised video salient object detection, IEEE Transactions on circuits and systems for video technology (2024)
2024
-
[43]
M. Lee, S. Cho, S. Lee, C. Park, S. Lee, Unsupervised video object segmentation via prototype memory net- work, in: Proceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, 2023, pp. 5924–5934
2023
-
[44]
N. Liu, K. Nan, W. Zhao, X. Yao, J. Han, Learning complementary spatial–temporal transformer for video salient object detection, IEEE Transactions on Neural Networks and Learning Systems 35 (8) (2023) 10663– 10673
2023
-
[45]
Y . Piao, C. Lu, M. Zhang, H. Lu, Semi-supervised video salient object detection based on uncertainty- guided pseudo labels, Advances in Neural Information Processing Systems 35 (2022) 5614–5627
2022
-
[46]
Y . Su, J. Deng, R. Sun, G. Lin, Q. Wu, A uni- fied transformer framework for group-based segmenta- tion: Co-segmentation, co-saliency detection and video salient object detection, IEEE Transactions on Multime- dia (2023). 14
2023
-
[47]
Q. Jia, S. Yao, Y . Liu, X. Fan, R. Liu, Z. Luo, Segment, magnify and reiterate: Detecting camouflaged objects the hard way, in: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2022, pp. 4713–4722
2022
-
[48]
Y . Sun, C. Xu, J. Yang, H. Xuan, L. Luo, Frequency- spatial entanglement learning for camouflaged object de- tection (2024) 343–360
2024
-
[49]
Y . Liu, C. Li, X. Dong, L. Li, D. Zhang, S. Xu, J. Han, Seamless detection: Unifying salient object detection and camouflaged object detection, Expert Systems with Applications 274 (2025) 126912
2025
-
[50]
Z. Yu, X. Zhang, L. Zhao, Y . Bin, G. Xiao, Explor- ing deeper! segment anything model with depth percep- tion for camouflaged object detection, in: Proceedings of the 32nd ACM international conference on multimedia, 2024, pp. 4322–4330
2024
-
[51]
R. Cong, Q. Lin, C. Zhang, C. Li, X. Cao, Q. Huang, Y . Zhao, Cir-net: Cross-modality interaction and refine- ment for rgb-d salient object detection, IEEE Transac- tions on Image Processing 31 (2022) 6800–6815
2022
-
[52]
Y . Lv, J. Zhang, Y . Dai, A. Li, B. Liu, N. Barnes, D.- P. Fan, Simultaneously localize, segment and rank the camouflaged objects, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11591–11601
2021
-
[53]
Y . Liu, S. Chen, H. Tang, S. Wang, Lightweight hybrid attention rgb-d networks for accurate camouflaged object detection, The Visual Computer (2025) 1–17
2025
-
[54]
H. Bi, Y . Tong, J. Zhang, C. Zhang, J. Tong, W. Jin, Depth alignment interaction network for camouflaged object detection, Multimedia Systems 30 (1) (2024) 51
2024
-
[55]
Huang, H
Z. Huang, H. Dai, T.-Z. Xiang, S. Wang, H.-X. Chen, J. Qin, H. Xiong, Feature shrinkage pyramid for camou- flaged object detection with transformers, in: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 5557–5566
2023
-
[56]
C. He, K. Li, Y . Zhang, L. Tang, Y . Zhang, Z. Guo, X. Li, Camouflaged object detection with feature decom- position and edge reconstruction, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22046–22055
2023
- [57]
-
[58]
L. Itti, C. Koch, E. Niebur, A model of saliency-based visual attention for rapid scene analysis, IEEE Trans- actions on Pattern Analysis and Machine Intelligence 20 (11) (1998) 1254–1259
1998
-
[59]
Simonyan, A
K. Simonyan, A. Zisserman, Two-stream convolutional networks for action recognition in videos, in: Advances in Neural Information Processing Systems, 2014, pp. 568–576
2014
-
[60]
W. Wang, J. Shen, X. Dong, A. Borji, Salient object de- tection driven by fixation prediction, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 1711–1720
2018
-
[61]
W. Zhai, Y . Cao, J. Zhang, Z.-J. Zha, Exploring figure- ground assignment mechanism in perceptual organiza- tion, Advances in Neural Information Processing Sys- tems 35 (2022) 17030–17042
2022
-
[62]
Yan, T.-N
J. Yan, T.-N. Le, K.-D. Nguyen, M.-T. Tran, T.-T. Do, T. V . Nguyen, Mirrornet: Bio-inspired camouflaged ob- ject segmentation, IEEE access 9 (2021) 43290–43300
2021
-
[63]
W. Zhai, Y . Cao, H. Xie, Z.-J. Zha, Deep texton- coherence network for camouflaged object detection, IEEE Transactions on Multimedia 25 (2022) 5155–5165
2022
-
[64]
L. Xu, X. You, F. Jia, K. Liu, Bicod: a camouflaged object detection method directed by cognitive attention, IEEE Sensors Journal 24 (4) (2023) 4711–4721
2023
-
[65]
Z. Chen, J. Zhang, D. Tao, Recurrent glimpse-based de- coder for detection with transformer, in: Proceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, 2022, pp. 5260–5269
2022
-
[66]
F. Yang, Q. Zhai, X. Li, R. Huang, A. Luo, H. Cheng, D.-P. Fan, Uncertainty-guided transformer reasoning for camouflaged object detection, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 4146–4155
2021
-
[67]
Zhang, M
Z. Zhang, M. Sabuncu, Generalized cross entropy loss for training deep neural networks with noisy labels, Advances in neural information processing systems 31 (2018)
2018
-
[68]
Rezatofighi, N
H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, S. Savarese, Generalized intersection over union: A met- ric and a loss for bounding box regression, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[69]
L. Wang, H. Lu, Y . Wang, M. Feng, D. Wang, B. Yin, X. Ruan, Learning to detect salient objects with image- level supervision, in: Proceedings of the IEEE confer- ence on computer vision and pattern recognition, 2017, pp. 136–145
2017
-
[70]
G. Li, Y . Yu, Visual saliency based on multiscale deep features, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 5455–5463. 15
2015
-
[71]
Q. Yan, L. Xu, J. Shi, J. Jia, Hierarchical saliency detec- tion, in: Proceedings of the IEEE conference on com- puter vision and pattern recognition, 2013, pp. 1155– 1162
2013
-
[72]
W. Liu, X. Shen, C.-M. Pun, X. Cun, Explicit visual prompting for low-level structure segmentations, in: Pro- ceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, 2023, pp. 19434–19445
2023
-
[73]
C. Cen, F. Li, Z. Li, Y . Wang, Towards salient object detection via parallel dual-decoder network, Engineer- ing Applications of Artificial Intelligence 139 (2025) 109638
2025
-
[74]
H. Peng, B. Li, W. Xiong, W. Hu, R. Ji, Rgbd salient ob- ject detection: A benchmark and algorithms, in: Com- puter Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceed- ings, Part III 13, Springer, 2014, pp. 92–109
2014
-
[75]
R. Ju, L. Ge, W. Geng, T. Ren, G. Wu, Depth saliency based on anisotropic center-surround difference, in: 2014 IEEE international conference on image process- ing (ICIP), IEEE, 2014, pp. 1115–1119
2014
-
[76]
Y . Piao, W. Ji, J. Li, M. Zhang, H. Lu, Depth-induced multi-scale recurrent attention network for saliency de- tection, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7254–7263
2019
-
[77]
W. Zhou, Y . Zhu, J. Lei, R. Yang, L. Yu, Lsnet: Lightweight spatial boosting network for detecting salient objects in rgb-thermal images, IEEE Transactions on Image Processing 32 (2023) 1329–1340
2023
-
[78]
Z. Zeng, H. Liu, F. Chen, X. Tan, Airsod: A lightweight network for rgb-d salient object detection, IEEE Trans- actions on Circuits and Systems for Video Technology 34 (3) (2024) 1656–1669
2024
-
[79]
Y . Zhan, Z. Zeng, H. Liu, X. Tan, Y . Tian, Mambasod: Dual mamba-driven cross-modal fusion network for rgb- d salient object detection, Neurocomputing 631 (2025) 129718
2025
-
[80]
Z. Tu, T. Xia, C. Li, X. Wang, Y . Ma, J. Tang, Rgb-t im- age saliency detection via collaborative graph learning, IEEE Transactions on Multimedia 22 (1) (2019) 160– 173
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.