One-to-Two Acting: A Novel Framework for Single-arm Agent Action Expansion to Dual Arms
Pith reviewed 2026-06-26 17:13 UTC · model grok-4.3
The pith
ExS2D turns single-arm robot demonstrations into dual-arm executions that reduce steps by 54 percent with zero bimanual data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
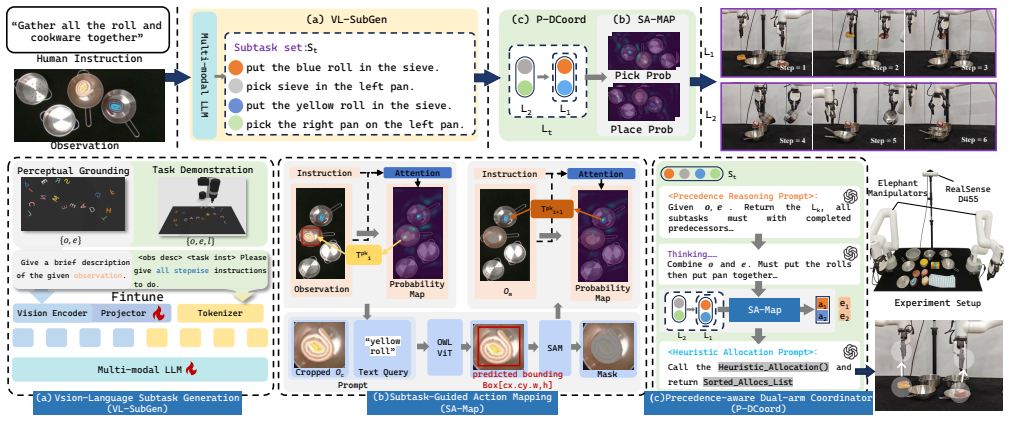
ExS2D first generates structured subtasks from textual instructions while explicitly capturing temporal precedence, then grounds each subtask into executable actions through subtask-guided action mapping in observation, and finally performs precedence-aware action allocation and synchronized planning by a multimodal large language model driven coordinator to select collision-free dual-arm executions from single-arm observations alone.
What carries the argument
multimodal large language model driven coordinator that performs precedence-aware action allocation and synchronized planning from single-arm observations
If this is right
- Dual-arm manipulation becomes possible using only single-arm demonstrations and textual instructions.
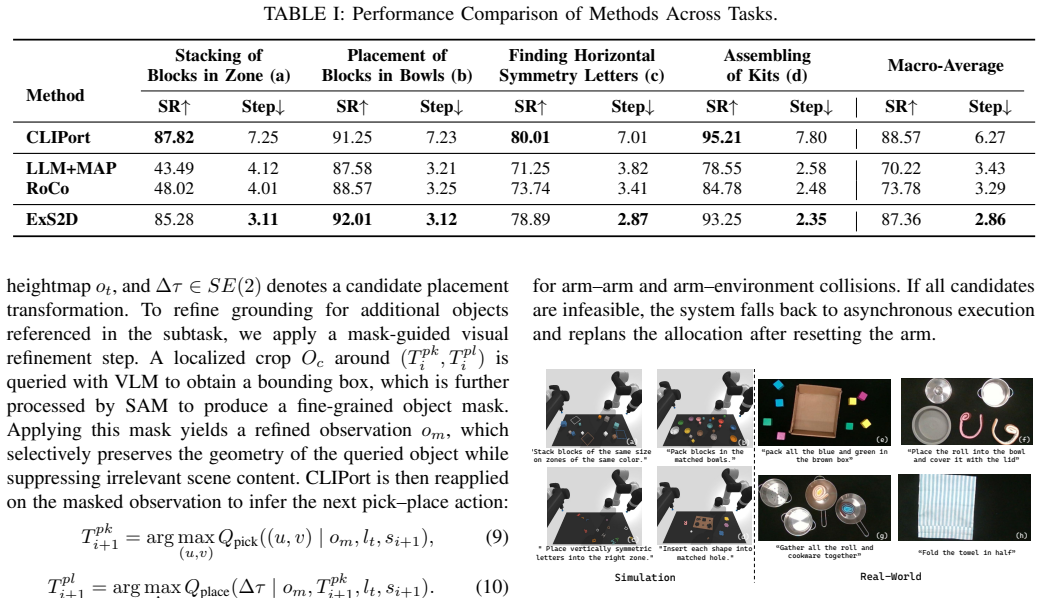
- Average execution steps drop by 54.4 percent compared to single-arm baselines while success rates stay comparable in simulation.
- The framework supports reliable dual-arm execution on four real-robot tasks with few-shot single-arm samples and no bimanual demonstrations.
Where Pith is reading between the lines
- The method could apply to other multi-arm or multi-robot settings where synchronized planning data is scarce.
- Integrating explicit geometric checks might further improve collision avoidance when the language model alone is insufficient.
- The reliance on language-model coordination suggests similar expansion techniques could transfer to non-manipulation robot skills.
Load-bearing premise
The multimodal large language model coordinator can reliably select collision-free dual-arm executions and perform synchronized planning from single-arm observations alone without any bimanual demonstration data or explicit collision models.
What would settle it
Real-robot trials on the reported tasks that show frequent collisions or desynchronization in dual-arm mode despite successful single-arm baselines would falsify the reliability of the coordinator.
Figures

read the original abstract
Dual-arm manipulation can improve throughput via parallel execution, but collecting bimanual demonstrations for training is costly and difficult. We present ExS2D, a hierarchical action expansion framework that enables dual-arm manipulation from single-arm supervision. ExS2D first generates structured subtasks from textual instructions while explicitly capturing temporal precedence. It then grounds each subtask into executable actions through subtask-guided action mapping in observation. Finally, precedence-aware action allocation and synchronized planning are performed by a multimodal large language model driven coordinator to select collision-free dual-arm executions. Simulation experiments demonstrate that ExS2D reduces the average execution steps by 54.4% while maintaining a comparable success rate to a single-arm baseline. Real-robot experiments on four tasks further demonstrate the reliability of ExS2D for dual-arm execution under few-shot single-arm samples, while using zero bimanual demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ExS2D, a hierarchical framework for single-to-dual arm action expansion. It generates structured subtasks from textual instructions that capture temporal precedence, performs subtask-guided action mapping from observations, and employs a multimodal LLM coordinator for precedence-aware allocation and synchronized planning to produce collision-free dual-arm executions. Simulation experiments report a 54.4% reduction in average execution steps with success rates comparable to a single-arm baseline; real-robot experiments on four tasks show reliable dual-arm performance using few-shot single-arm samples and zero bimanual demonstrations.
Significance. If the central claims hold, the work could meaningfully reduce the cost of acquiring bimanual data by leveraging single-arm supervision and LLM reasoning. The hierarchical decomposition plus LLM coordinator is a concrete attempt to address a practical robotics bottleneck, and the zero-bimanual-demo result, if reproducible, would be a notable data-efficiency outcome.
major comments (2)
- [Coordinator description (likely §4)] The abstract and experimental claims rest on the MLLM coordinator reliably inferring collision-free synchronized trajectories from single-arm observations and text alone. No explicit collision model, kinematic feasibility check, or verification step is described; success therefore depends entirely on the LLM's implicit world model. This is load-bearing for both the 54.4% step-reduction result and the real-robot reliability claim.
- [Abstract and Experiments] The quantitative headline results (54.4% step reduction, comparable success) are stated without reference to the precise simulation environment, number of trials, baseline implementations, or variance across runs. Given the dependence on external LLM components whose behavior can vary with prompting, these omissions prevent assessment of whether the reported gains are robust or post-hoc selected.
minor comments (2)
- [Framework overview] Notation for the subtask precedence graph and the action-allocation mapping could be formalized with a short diagram or pseudocode to improve clarity.
- [Real-robot experiments] The real-robot section would benefit from explicit listing of the four tasks and the exact few-shot sample counts used per task.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below, indicating planned revisions where appropriate to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Coordinator description (likely §4)] The abstract and experimental claims rest on the MLLM coordinator reliably inferring collision-free synchronized trajectories from single-arm observations and text alone. No explicit collision model, kinematic feasibility check, or verification step is described; success therefore depends entirely on the LLM's implicit world model. This is load-bearing for both the 54.4% step-reduction result and the real-robot reliability claim.
Authors: We agree that the MLLM coordinator does not employ an explicit collision model, kinematic feasibility checker, or post-hoc verification step; collision-free and synchronized behavior emerges from the LLM's reasoning over textual subtasks, precedence constraints, and visual observations. This reliance on the implicit world model is a deliberate design choice to avoid task-specific engineering. We will revise Section 4 to explicitly describe the coordinator's input construction, prompting template, and output parsing, and add a dedicated limitations paragraph discussing dependence on the LLM's world model and potential failure cases. revision: yes
-
Referee: [Abstract and Experiments] The quantitative headline results (54.4% step reduction, comparable success) are stated without reference to the precise simulation environment, number of trials, baseline implementations, or variance across runs. Given the dependence on external LLM components whose behavior can vary with prompting, these omissions prevent assessment of whether the reported gains are robust or post-hoc selected.
Authors: The Experiments section of the manuscript already specifies the simulation environment, task suite, number of evaluation episodes, baseline implementations, and success-rate comparisons. However, the abstract and result summaries do not restate these details or report run-to-run variance. We will revise the abstract to include the simulation platform and trial count, expand the experimental reporting to include standard deviations, and add a short paragraph on prompt consistency and LLM version used. These changes will make the quantitative claims self-contained. revision: yes
Circularity Check
No circularity: framework relies on external LLM and experimental validation
full rationale
The paper describes a hierarchical framework (ExS2D) that generates subtasks, maps actions via observation, and uses an external multimodal LLM coordinator for allocation and planning. No equations, fitted parameters, or self-referential derivations appear in the provided text. Performance metrics (54.4% step reduction, success rates) are reported from simulation and real-robot experiments rather than derived from the framework's own inputs by construction. The central claims rest on empirical results and the assumed capabilities of the cited LLM component, which is treated as an independent black box rather than a self-defined quantity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ExS2D hierarchical framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reinforcement learning-based scheduling of a job-shop process with distributedly controlled robotic manipulators for transport operations,
Simon et al., “Reinforcement learning-based scheduling of a job-shop process with distributedly controlled robotic manipulators for transport operations,”IF AC-PapersOnLine, vol. 55, no. 2, pp. 156–162, 2022
2022
-
[2]
VIMA: Robot Manipulation with Multimodal Prompts,
Yunfan Jiang, Agrim Gupta, Zichen Zhang, et al., “VIMA: Robot Manipulation with Multimodal Prompts,” inInternational Conference on Machine Learning, ICML, 2023, vol. 202, pp. 14975–15022
2023
-
[3]
Fast- UMI: A Scalable and Hardware-Independent Universal Manipulation Interface,
Ziniu Wu, Tianyu Wang, Chuyue Guan, Zhongjie Jia, et al., “Fast- UMI: A Scalable and Hardware-Independent Universal Manipulation Interface,”arXiv e-prints, pp. arXiv–2409, 2024
2024
-
[4]
TinyVLA: Toward Fast, Data-Efficient Vision- Language-Action Models for Robotic Manipulation,
Junjie Wen, Zhu, et al., “TinyVLA: Toward Fast, Data-Efficient Vision- Language-Action Models for Robotic Manipulation,”IEEE Robotics and Automation Letters (RAL), vol. 10, no. 4, pp. 3988–3995, 2025
2025
-
[5]
Learn- ing Fine-Grained Bimanual Manipulation with Low-Cost Hardware,
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn, “Learn- ing Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” in Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[6]
Kun Chu, Xufeng Zhao, Cornelius Weber, and Stefan Wermter, “LLM+MAP: Bimanual Robot Task Planning using Large Language Models and Planning Domain Definition Language,”ArXiv, vol. abs/2503.17309, 2025
arXiv 2025
-
[7]
Dynamic Mobile Manipulation via Whole-body Bilateral Teleoperation of a Wheeled Humanoid,
Purushottam et al., “Dynamic Mobile Manipulation via Whole-body Bilateral Teleoperation of a Wheeled Humanoid,”IEEE Robotics and Automation Letters (RAL), vol. 9, no. 2, pp. 1214–1221, 2024
2024
-
[8]
Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics,
Taowen Wang, Cheng Han, James Liang, Wenhao Yang, Dongfang Liu, Luna Xinyu Zhang, Qifan Wang, Jiebo Luo, and Ruixiang Tang, “Exploring the Adversarial Vulnerabilities of Vision-Language-Action Models in Robotics,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 6948–6958
2025
-
[9]
CLIPort: What and Where Path- ways for Robotic Manipulation,
Mohit Shridhar, Lucas Manuelli, et al., “CLIPort: What and Where Path- ways for Robotic Manipulation,” inProceedings of the 5th Conference on Robot Learning, CoRL. 2022, vol. 164, pp. 894–906, PMLR
2022
-
[10]
CoPAL: Corrective Planning of Robot Actions with Large Language Models,
Frank Joublin, Antonello Ceravola, Pavel Smirnov, et al., “CoPAL: Corrective Planning of Robot Actions with Large Language Models,” in2024 IEEE International Conference on Robotics and Automation, ICRA. May 2024, pp. 8664—-8670, IEEE
2024
-
[11]
OV A-Fields: Weakly Su- pervised Open-vocabulary Affordance Fields for Robot Operational Part Detection,
Heng Su, Mengying Xie, Nieqing Cao, et al., “OV A-Fields: Weakly Su- pervised Open-vocabulary Affordance Fields for Robot Operational Part Detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, 2025, pp. 6385–6395
2025
-
[12]
Synchronized Dual-arm Rearrangement via Coop- erative mTSP,
Wenhao Li, Shishun Zhang, Sisi Dai, Hui Huang, Ruizhen Hu, Xiaohong Chen, and Kai Xu, “Synchronized Dual-arm Rearrangement via Coop- erative mTSP,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 9242–9248
2024
-
[13]
Learning Dual-arm Object Rearrange- ment for Cartesian Robots,
Shishun Zhang, Qijin She, et al., “Learning Dual-arm Object Rearrange- ment for Cartesian Robots,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 7440–7446
2024
-
[14]
LoHoRavens: A Long-Horizon Language- Conditioned Benchmark for Robotic Tabletop Manipulation,
Shengqiang Zhang, Philipp Wicke, L ¨utfi Kerem Senel, Luis F. C. Figueredo, Abdeldjallil Naceri, Sami Haddadin, Barbara Plank, and Hinrich Sch ¨utze, “LoHoRavens: A Long-Horizon Language- Conditioned Benchmark for Robotic Tabletop Manipulation,”ArXiv, vol. abs/2310.12020, 2023
arXiv 2023
-
[15]
LLM+P: Empowering Large Language Models with Optimal Planning proficiency,
Bo Liu, Yuqian Jiang, Xiaohan Zhang, et al., “LLM+P: Empowering Large Language Models with Optimal Planning proficiency,”arXiv preprint arXiv:2304.11477, 2023
Pith/arXiv arXiv 2023
-
[16]
Language-Embedded 6D Pose Estimation for Tool Manipulation,
Yuyang Tu, Yunlong Wang, Hui Zhang, et al., “Language-Embedded 6D Pose Estimation for Tool Manipulation,”IEEE Robotics and Automation Letters (RAL), vol. 10, no. 9, pp. 8618–8625, 2025
2025
-
[17]
BestMan: A Modular Mobile Manipula- tor Platform for Embodied AI with Unified Simulation-hardware APIs,
Kui Yang, Nieqing Cao, et al., “BestMan: A Modular Mobile Manipula- tor Platform for Embodied AI with Unified Simulation-hardware APIs,” Frontiers of Computer Science, vol. 19, no. 9, pp. 199361, 2025
2025
-
[18]
On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning,
Changyu Liu, Yiyang Liu, Taowen Wang, et al., “On-the-Fly VLA Adaptation via Test-Time Reinforcement Learning,”arXiv preprint arXiv:2601.06748, 2026
Pith/arXiv arXiv 2026
-
[19]
Language-Conditioned Imitation Learning With Base Skill Priors Under Unstructured Data,
Hongkuan Zhou et al., “Language-Conditioned Imitation Learning With Base Skill Priors Under Unstructured Data,”IEEE Robotics and Automation Letters (RAL), vol. 9, no. 11, pp. 9805–9812, 2024
2024
-
[20]
CyberDemo: Augmenting Simulated Human Demon- stration for Real-World Dexterous Manipulation,
Jun Wang et al., “CyberDemo: Augmenting Simulated Human Demon- stration for Real-World Dexterous Manipulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 17952–17963
2024
-
[21]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song, “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[22]
BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning,
Eric Jang, Irpan, et al., “BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning,” inProceedings of the 5th Conference on Robot Learning. 08–11 Nov 2022, vol. 164 ofProceedings of Machine Learning Research (PMLR), pp. 991–1002, PMLR
2022
-
[23]
VideoDex: Learning Dexterity from Internet Videos,
Kenneth Shaw, Shikhar Bahl, and Deepak Pathak, “VideoDex: Learning Dexterity from Internet Videos,” inProceedings of The 6th Conference on Robot Learning. 14–18 Dec 2023, vol. 205 ofProceedings of Machine Learning Research (PMLR), pp. 654–665, PMLR
2023
-
[24]
GELLO: A General, Low- Cost, and Intuitive Teleoperation Framework for Robot Manipulators,
Philipp Wu, Yide Shentu, Zhongke Yi, et al., “GELLO: A General, Low- Cost, and Intuitive Teleoperation Framework for Robot Manipulators,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 12156–12163
2024
-
[25]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation,
Zipeng Fu, Tony Z. Zhao, and Chelsea Finn, “Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation,” inConference on Robot Learning (CoRL), 2024
2024
-
[26]
Twostep: Multi-agent Task Planning using Classical Planners and Large Language Models,
David Bai, Ishika Singh, David Traum, and Jesse Thomason, “Twostep: Multi-agent Task Planning using Classical Planners and Large Language Models,”arXiv preprint arXiv:2403.17246, 2024
arXiv 2024
-
[27]
RoCo: Dialectic Multi-Robot Collaboration with Large Language Models,
Mandi et al., “RoCo: Dialectic Multi-Robot Collaboration with Large Language Models,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 286–299
2024
-
[28]
Video OWL- ViT: Temporally-consistent Open-world Localization in Video,
Georg Heigold, Matthias Minderer, Gritsenko, et al., “Video OWL- ViT: Temporally-consistent Open-world Localization in Video,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 13802–13811
2023
-
[29]
Segment Anything,
Alexander Kirillov, Eric Mintun, Nikhila Ravi, et al., “Segment Anything,” inProceedings of the IEEE/CVF international conference on computer vision (ICCV), 2023, pp. 4015–4026
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.