Quantum Annealing Enhanced Reinforcement Learning for Accurate Remaining Useful Lifetime Prediction
Pith reviewed 2026-06-27 01:08 UTC · model grok-4.3
The pith
Encoding Q-value updates as QUBOs solved by quantum annealing supplies stochastic exploration that improves remaining useful life estimates on nonlinear degradation data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
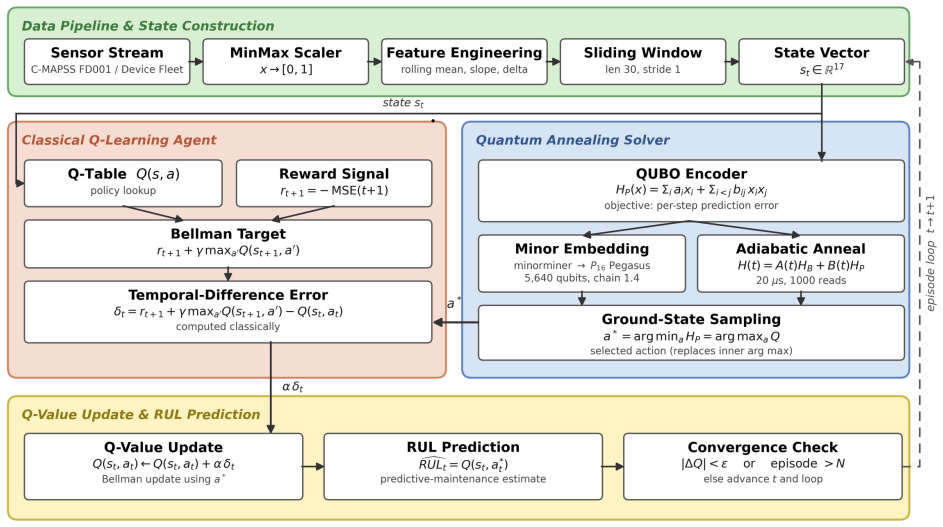
The central claim is that framing each Q-value update as a QUBO solved on a quantum annealer lets the distribution of near-optimal solutions supply the exploration needed in reinforcement learning, thereby curbing premature convergence on nonlinear degradation paths and yielding more accurate remaining useful life predictions than classical or other quantum baselines.
What carries the argument
The QUBO encoding of the Q-value update, solved on a quantum annealer so that its distribution over near-ground states drives stochastic action selection inside the reinforcement learning loop.
If this is right
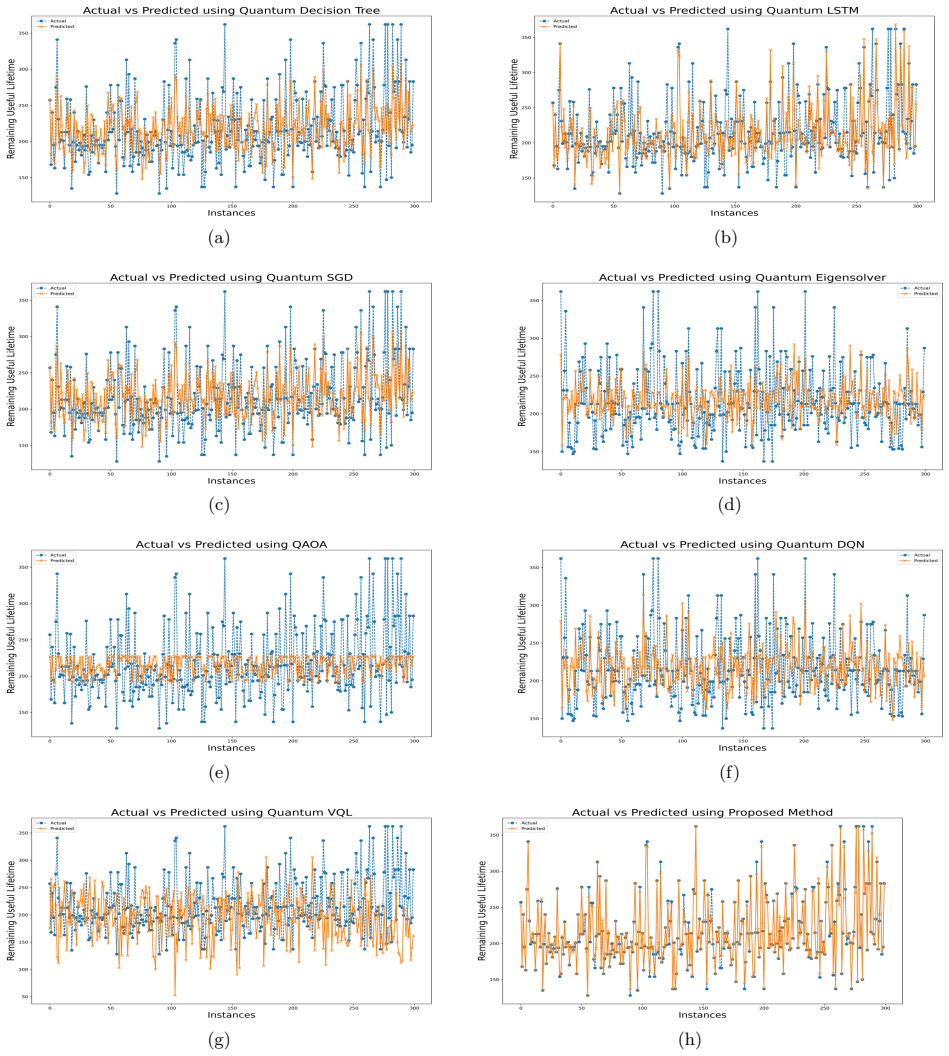
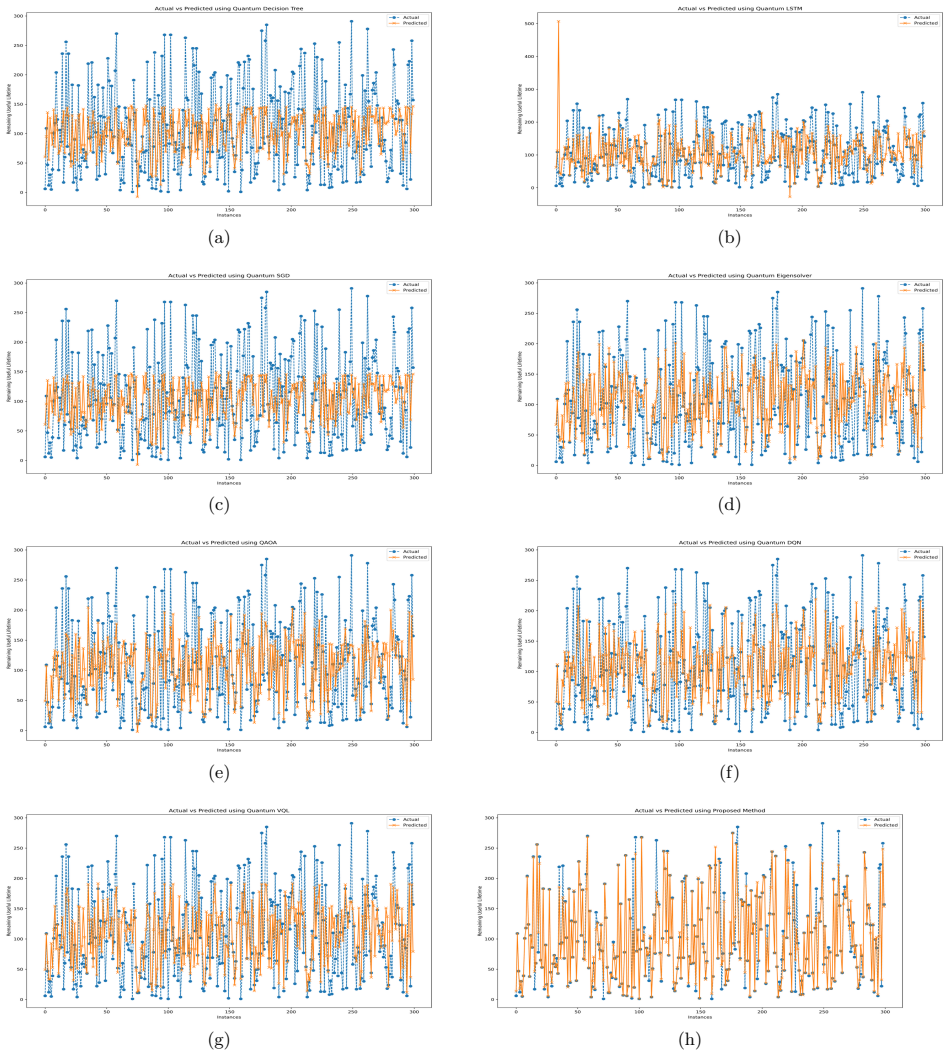
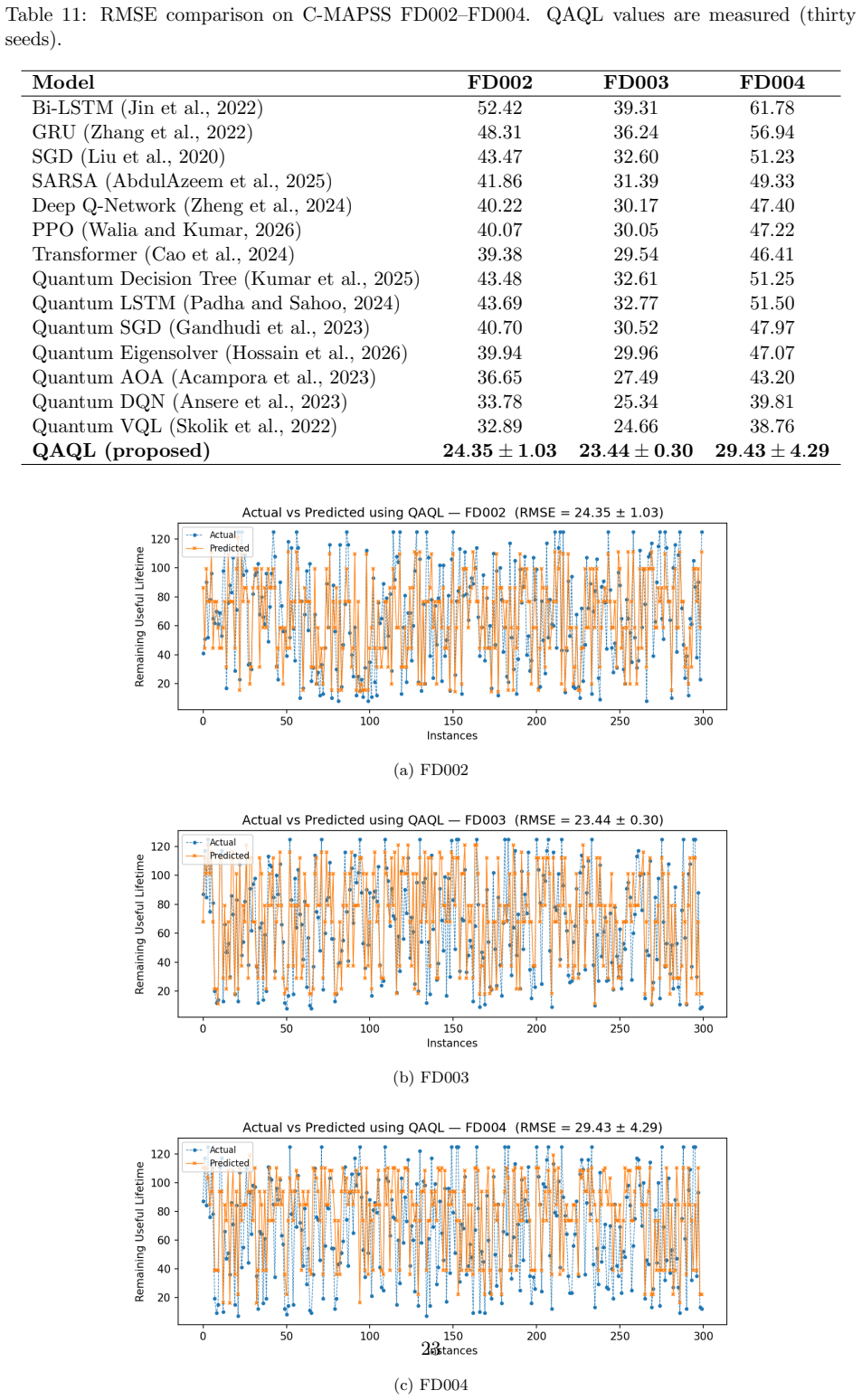
- QAQL produces statistically significant improvements over classical and quantum baselines on the NASA C-MAPSS turbofan engine datasets across six error metrics.
- It also outperforms the same baselines on a device-fleet predictive maintenance dataset.
- The annealer is embedded inside the reinforcement learning training loop rather than applied after training.
- The results indicate quantum annealing can function as a practical optimizer for industrial predictive maintenance applications.
Where Pith is reading between the lines
- The same QUBO-based exploration mechanism could be tested on other reinforcement learning problems that involve high-dimensional nonlinear dynamics.
- A controlled comparison against classical methods that inject equivalent randomness would clarify whether the quantum hardware itself is required for the observed gains.
- The approach's behavior on state spaces substantially larger than those in the current benchmarks remains untested and would require scalable embedding strategies.
Load-bearing premise
That the distribution of near-optimal solutions returned by the annealer supplies beneficial exploration without being distorted by embedding or hardware effects.
What would settle it
Replacing the annealer with a classical exact solver that always returns the single greedy action and checking whether error rates on the turbofan and fleet datasets become comparable or lower.
Figures
read the original abstract
Remaining useful life (RUL) estimation is central to predictive maintenance, where an unplanned failure can cost far more than the asset itself. Statistical degradation models miss the strong nonlinearity of real systems, and data-driven models often converge to suboptimal solutions in high-dimensional, non-convex search spaces. We propose a Quantum Annealing enhanced Q-Learning (QAQL) framework that couples the sampling behaviour of quantum annealing with the sequential decision making of Q-learning. Each Q-value update is encoded as a small quadratic unconstrained binary optimization (QUBO) whose ground state is the greedy action; rather than acting as a deterministic optimizer, the annealer returns a distribution over near-optimal actions across many reads, and this stochastic action selection supplies the exploration that curbs premature convergence on nonlinear degradation trajectories. The QUBO is solved on the D-Wave Advantage system using minor embedding, with the annealer woven into the reinforcement-learning loop rather than bolted on after training. We validate QAQL on two public benchmarks: the NASA C-MAPSS turbofan engine datasets and a device-fleet predictive maintenance dataset. Averaged over many independent runs and across six error metrics, QAQL outperforms the classical and quantum baselines considered in this study, with statistically significant improvements. The results indicate that quantum annealing is a usable, not merely theoretical, optimizer inside a reinforcement-learning loop for industrial predictive-maintenance applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Quantum Annealing enhanced Q-Learning (QAQL) for remaining useful life (RUL) prediction. Each Q-value update is cast as a QUBO whose ground state encodes the greedy action; the D-Wave Advantage annealer (with minor embedding) supplies a distribution over near-optimal actions that is used for exploration inside the RL loop. On the NASA C-MAPSS turbofan datasets and a device-fleet predictive-maintenance benchmark, QAQL is reported to outperform classical and quantum baselines across six error metrics with statistical significance when averaged over many independent runs.
Significance. If the performance advantage survives explicit controls for embedding-induced bias and hardware noise, the work would supply concrete evidence that quantum annealing hardware can be usefully embedded inside an RL training loop for nonlinear regression tasks. The choice to interleave annealing with every Q-update rather than apply it only at inference time is a methodological strength, as is the reliance on public benchmarks and multi-metric evaluation.
major comments (2)
- [Methods (QUBO encoding and minor embedding)] The central empirical claim rests on the premise that the distribution returned by the annealer after minor embedding supplies unbiased exploration equivalent to the intended greedy-plus-stochastic mechanism. The methods section describing the QUBO construction and embedding provides no quantitative verification (e.g., KL divergence between observed and theoretical action distributions, or an ablation replacing the annealer with a classical sampler matched for entropy) that would confirm the sampled actions remain faithful to the RL update rule.
- [Results and statistical analysis] Results section (tables/figures reporting the six error metrics): while statistical significance is asserted, the manuscript supplies no description of the precise train/validation/test splits used on C-MAPSS, the method for computing error bars, or the number of independent runs per baseline. Without these details the reported outperformance cannot be reproduced or assessed for robustness.
minor comments (2)
- [Methods] Notation for the QUBO coefficients and the mapping from Q-values to binary variables is introduced without an explicit equation; adding a numbered equation would improve clarity.
- [Results] The abstract states 'statistically significant improvements' but the main text does not indicate the exact hypothesis test or correction for multiple comparisons; a brief statement would suffice.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and indicate the revisions that will be incorporated in the next version of the manuscript.
read point-by-point responses
-
Referee: [Methods (QUBO encoding and minor embedding)] The central empirical claim rests on the premise that the distribution returned by the annealer after minor embedding supplies unbiased exploration equivalent to the intended greedy-plus-stochastic mechanism. The methods section describing the QUBO construction and embedding provides no quantitative verification (e.g., KL divergence between observed and theoretical action distributions, or an ablation replacing the annealer with a classical sampler matched for entropy) that would confirm the sampled actions remain faithful to the RL update rule.
Authors: We agree that explicit quantitative verification of the action distribution would strengthen the methods. In the revised manuscript we will add (i) KL-divergence measurements between the empirical action distributions obtained from the D-Wave Advantage (after minor embedding) and the theoretical distribution implied by the QUBO ground-state-plus-temperature model, and (ii) an ablation that replaces the annealer with a classical Boltzmann sampler whose entropy is matched to the hardware output. These additions will directly demonstrate that the exploration mechanism remains faithful to the intended Q-learning update rule. revision: yes
-
Referee: [Results and statistical analysis] Results section (tables/figures reporting the six error metrics): while statistical significance is asserted, the manuscript supplies no description of the precise train/validation/test splits used on C-MAPSS, the method for computing error bars, or the number of independent runs per baseline. Without these details the reported outperformance cannot be reproduced or assessed for robustness.
Authors: We acknowledge that the current manuscript lacks sufficient detail for full reproducibility. The revised version will contain a new subsection "Experimental Protocol" that explicitly states: the precise train/validation/test splits employed for each C-MAPSS subset (FD001–FD004), following the standard benchmark partitioning; that error bars are computed as mean ± one standard deviation across 50 independent runs with distinct random seeds; and that statistical significance is assessed via two-sided paired t-tests with Bonferroni correction (p < 0.05). The corresponding code and split indices will be released with the camera-ready version. revision: yes
Circularity Check
No significant circularity; empirical validation stands independently.
full rationale
The paper's core contribution is an empirical comparison of QAQL against classical and quantum baselines on public NASA C-MAPSS and device-fleet datasets, reporting statistically significant improvements across six error metrics. No equations or derivations are presented that reduce claimed performance gains to quantities defined by the method itself, fitted parameters renamed as predictions, or load-bearing self-citations. The QUBO encoding and annealing-based exploration are described as a mechanism, but results are externally falsifiable on benchmarks without requiring the target outcome to hold by construction. This is the normal case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Each Q-value update can be encoded as a QUBO whose ground state is the greedy action, and the annealer's distribution over near-optimal solutions supplies useful exploration.
Reference graph
Works this paper leans on
-
[1]
N., Chasparis, G
Abbas, A. N., Chasparis, G. C., and Kelleher, J. D. (2024). Hierarchical framework for interpretable and specialized deep reinforcement learning-based predictive maintenance.Data & Knowledge Engineering, 149:102240
2024
-
[2]
M., Bamaqa, A., Badawy, M., and Elhosseini, M
AbdulAzeem, Y., Balaha, H. M., Bamaqa, A., Badawy, M., and Elhosseini, M. A. (2025). Esarsa- mrfo-fs: optimizing manta-ray foraging optimizer using expected-sarsa reinforcement learning for features selection.Knowledge-Based Systems, 321:113695
2025
-
[3]
Acampora, G., Chiatto, A., and Vitiello, A. (2023). Genetic algorithms as classical optimizer for the quantum approximate optimization algorithm.Applied Soft Computing, 142:110296
2023
-
[4]
A., Gyamfi, E., Sharma, V., Shin, H., Dobre, O
Ansere, J. A., Gyamfi, E., Sharma, V., Shin, H., Dobre, O. A., and Duong, T. Q. (2023). Quantum deep reinforcement learning for dynamic resource allocation in mobile edge computing-based iot systems.IEEE Transactions on Wireless Communications, 23(6):6221–6233. 26
2023
-
[5]
R., Roberts, M
Birkl, C. R., Roberts, M. R., McTurk, E., Bruce, P. G., and Howey, D. A. (2017). Degradation diagnostics for lithium ion cells.Journal of Power Sources, 341:373–386
2017
-
[6]
Cao, W., Meng, Z., Li, J., Wu, J., and Fan, F. (2024). A remaining useful life prediction method for rolling bearing based on tcn-transformer.IEEE Transactions on Instrumentation and Mea- surement, 74:1–9
2024
-
[7]
and Peng, K
Cao, X. and Peng, K. (2023). Stochastic uncertain degradation modeling and remaining useful life prediction considering aleatory and epistemic uncertainty.IEEE Transactions on Instrumentation and Measurement, 72:1–12
2023
-
[8]
D., and Tzovaras, D
Evangelidis, A., Dimitriou, N., Charalampous, P., Mastos, T. D., and Tzovaras, D. (2024). Efficient deep q-learning for industrial equipment calibration in elevator manufacturing.IEEE Transactions on Industrial Informatics
2024
-
[9]
and Gon¸ calves, G
Ferreira, C. and Gon¸ calves, G. (2022). Remaining useful life prediction and challenges: A literature review on the use of machine learning methods.Journal of Manufacturing Systems, 63:550–562
2022
-
[10]
and Gangadharan, G
Gandhudi, M. and Gangadharan, G. (2026). Dynamic quantum annealing optimized quantum neural networks for remaining useful lifetime prediction.Engineering Applications of Artificial Intelligence, 167:113856
2026
-
[11]
Gandhudi, M., Gangadharan, G., Alphonse, P., Velayudham, V., and Nagineni, L. (2023). Causal aware parameterized quantum stochastic gradient descent for analyzing marketing advertisements and sales forecasting.Information Processing & Management, 60(5):103473
2023
-
[12]
K., and Kim, J
Ghosh, N., Garg, A., Panigrahi, B. K., and Kim, J. (2023). An evolving quantum fuzzy neural network for online state-of-health estimation of li-ion cell.Applied Soft Computing, 143:110263
2023
-
[13]
Glover, F., Kochenberger, G., and Du, Y. (2019). Quantum bridge analytics i: a tutorial on formulating and using qubo models.4OR, 17(4):335–371
2019
-
[14]
Hao, Y., Lu, Q., Wang, X., and Jiang, B. (2024). Adaptive model-based reinforcement learning for fast-charging optimization of lithium-ion batteries.IEEE Transactions on Industrial Informatics, 20(1):127–137
2024
-
[15]
M., Lee, S.-C., and Bhattacharjee, S
Hossain, S. M., Lee, S.-C., and Bhattacharjee, S. (2026). Quantum simulations of battery elec- trolytes using variational quantum eigensolver, equation-of-motion, and sample-based diagonal- ization methods: Active-space design, dissociation, and excited states of lipf 6\rmlipf 6, napf 6 \rmnapf 6, and fsi salts.Advanced Quantum Technologies, 9(2):e00871
2026
-
[16]
H., and Loo, K.-H
Hou, Y., Lu, C., Xia, Q., Abbas, W., Lee, H. H., and Loo, K.-H. (2026). Lvdacnn: A lightweight variable dependency aware cnn for remaining useful life prediction.IEEE Transactions on In- strumentation and Measurement
2026
-
[17]
Hu, Y., Miao, X., Zhang, J., Liu, J., and Pan, E. (2021). Reinforcement learning-driven maintenance strategy: A novel solution for long-term aircraft maintenance decision optimization.Computers & industrial engineering, 153:107056
2021
-
[18]
Jiao, Z., Wang, H., Xing, J., Yang, Q., Yang, M., Zhou, Y., and Zhao, J. (2023). Lightgbm-based framework for lithium-ion battery remaining useful life prediction under driving conditions.IEEE Transactions on Industrial Informatics, 19(11):11353–11362
2023
-
[19]
Jin, R., Chen, Z., Wu, K., Wu, M., Li, X., and Yan, R. (2022). Bi-lstm-based two-stream net- work for machine remaining useful life prediction.IEEE Transactions on Instrumentation and Measurement, 71:1–10. 27
2022
-
[20]
Jin, Y., Gummadi, R., Zhou, Z., and Blanchet, J. (2024). Feasibleq-learning for average reward reinforcement learning. InInternational Conference on Artificial Intelligence and Statistics, pages 1630–1638. PMLR
2024
-
[21]
Khan, T. M. and Robles-Kelly, A. (2020). Machine learning: Quantum vs classical.IEEE Access, 8:219275–219294
2020
-
[22]
E., Khorasani, K., and Saif, M
Kordestani, M., Orchard, M. E., Khorasani, K., and Saif, M. (2023). An overview of the state of the art in aircraft prognostic and health management strategies.IEEE Transactions on Instru- mentation and Measurement, 72:1–15
2023
-
[23]
Kumar, N., Yalovetzky, R., Li, C., Minssen, P., and Pistoia, M. (2025). Des-q: a quantum algorithm to provably speedup retraining of decision trees.Quantum, 9:1588
2025
-
[24]
Landau, D., de Pater, I., Mitici, M., and Saurabh, N. (2026). Federated learning framework for collaborative remaining useful life prognostics: An aircraft engine case study.Future Generation Computer Systems, 174:107945
2026
-
[25]
Liu, T., Li, Y., Hu, Z., Fu, C., and Song, G. (2026). Remaining useful life prediction of bearings based on small-sample enhanced and interpretable transfer learning.Advanced Engineering Informatics, 69:103938
2026
-
[26]
Liu, X., Cheng, W., Xing, J., Chen, X., Zhao, Z., Gao, L., Ding, B., Zhou, K., Zhi, Y., and Zhang, R. (2024). Optimized online remaining useful life prediction for nuclear circulating water pump considering time-varying degradation mechanism.IEEE Transactions on Industrial Informatics
2024
-
[27]
Liu, Y., Gao, Y., and Yin, W. (2020). An improved analysis of stochastic gradient descent with momentum.Advances in Neural Information Processing Systems, 33:18261–18271
2020
-
[28]
Lucas, A. (2014). Ising formulations of many np problems.Frontiers in Physics, 2:5. Magad´ an, L., Granda, J. C., and Su´ arez, F. J. (2024). Robust prediction of remaining useful lifetime of bearings using deep learning.Engineering Applications of Artificial Intelligence, 130:107690
2014
-
[29]
K., Dorneanu, B., Nolasco, E., Vassiliadis, V
Mappas, V. K., Dorneanu, B., Nolasco, E., Vassiliadis, V. S., and Arellano-Garcia, H. (2025). Towards scalable quantum annealing for pooling and blending problems: a methodological proof- of-concept.Chemical Engineering Research and Design
2025
-
[30]
and Sahoo, A
Padha, A. and Sahoo, A. (2024). Qclr: Quantum-lstm contrastive learning framework for continuous mental health monitoring.Expert Systems with Applications, 238:121921
2024
-
[31]
Pan, D., Li, H., and Wang, S. (2022). Transfer learning-based hybrid remaining useful life prediction for lithium-ion batteries under different stresses.IEEE Transactions on Instrumentation and Measurement, 71:1–10
2022
-
[32]
Peng, Z., Huang, X., Tang, D., and Quan, Q. (2023). Health indicator construction based on multisensors for intelligent remaining useful life prediction: A reinforcement learning approach. IEEE Transactions on Instrumentation and Measurement, 72:1–13. P´ erez Armas, L. F., Creemers, S., and Deleplanque, S. (2024). Solving the resource constrained project ...
2023
-
[33]
K., Pillai, G., and Chakrabarty, S
Shakya, A. K., Pillai, G., and Chakrabarty, S. (2023). Reinforcement learning algorithms: A brief survey.Expert Systems with Applications, 231:120495
2023
-
[34]
Skolik, A., Jerbi, S., and Dunjko, V. (2022). Quantum agents in the gym: a variational quantum algorithm for deep q-learning.Quantum, 6:720. 28
2022
-
[35]
Sun, S., Liu, J., Wang, J., Chen, F., Wei, S., and Gao, H. (2022). Remaining useful life prediction for ac contactor based on mmpe and lstm with dual attention mechanism.IEEE Transactions on Instrumentation and Measurement, 71:1–13
2022
-
[36]
Sutton, R. S. and Barto, A. G. (2018).Reinforcement Learning: An Introduction. MIT Press,
2018
-
[37]
Tang, A., Pan, H., Zhang, X., Tong, J., Zheng, J., and Cheng, J. (2026). Physics-informed multi- projection regression for roller bearing remaining useful life prediction.Reliability Engineering & System Safety, page 112708
2026
-
[38]
Tian, J., Jiang, Y., Zhang, J., Wu, S., and Luo, H. (2023). A novel transfer ensemble learning frame- work for remaining useful life prediction under multiple working conditions.IEEE Transactions on Instrumentation and Measurement, 72:1–11
2023
- [39]
-
[40]
Walia, G. K. and Kumar, M. (2026). Uncertainty-aware remaining useful life prediction and ppo based optimal maintenance scheduling in industrial iot.Reliability Engineering & System Safety, page 112356
2026
-
[41]
Wang, K., He, A., Liu, J., Zhou, Q., and Hu, Z. (2025). An online learning framework for aero-engine sensor fault detection isolation and recovery.Aerospace Science and Technology, 162:110241
2025
-
[42]
Wilberforce, T., Alaswad, A., Garcia-Perez, A., Xu, Y., Ma, X., and Panchev, C. (2023). Remaining useful life prediction for proton exchange membrane fuel cells using combined convolutional neural network and recurrent neural network.International Journal of Hydrogen Energy, 48(1):291–303
2023
-
[43]
Xu, Z., Zhang, Y., Miao, J., and Miao, Q. (2023). Global attention mechanism based deep learning for remaining useful life prediction of aero-engine.Measurement, 217:113098
2023
-
[44]
Yang, W., Wang, Y., Li, J., Hao, J., and Gao, J. (2025). Failure analysis of the premature fan blade-off in aeroengine containment test.Engineering Failure Analysis, page 109888
2025
-
[45]
Yarkoni, S., Raponi, E., B¨ ack, T., and Schmitt, S. (2022). Quantum annealing for industry appli- cations: Introduction and review.Reports on Progress in Physics, 85(10):104001
2022
-
[46]
Zhang, J., Huang, C., Chow, M.-Y., Li, X., Tian, J., Luo, H., and Yin, S. (2023). A data-model interactive remaining useful life prediction approach of lithium-ion batteries based on pf-bigru- tsam.IEEE Transactions on Industrial Informatics, 20(2):1144–1154
2023
-
[47]
Zhang, L., Wang, B., Yuan, X., and Liang, P. (2022). Remaining useful life prediction via im- proved cnn, gru and residual attention mechanism with soft thresholding.IEEE Sensors Journal, 22(15):15178–15190
2022
-
[48]
Zheng, G., Li, Y., Zhou, Z., and Yan, R. (2024). A remaining useful life prediction method of rolling bearings based on deep reinforcement learning.IEEE Internet of Things Journal, 11(13):22938– 22949. 29
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.