Towards a Hybrid Quantum Enhanced Solution for Densest k-Subgraph Problem
Pith reviewed 2026-06-28 09:56 UTC · model grok-4.3
The pith
Gaussian Boson Sampling paired with classical post-processing reaches near-optimal densest k-subgraphs while sampling four times more efficiently on community-structured graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
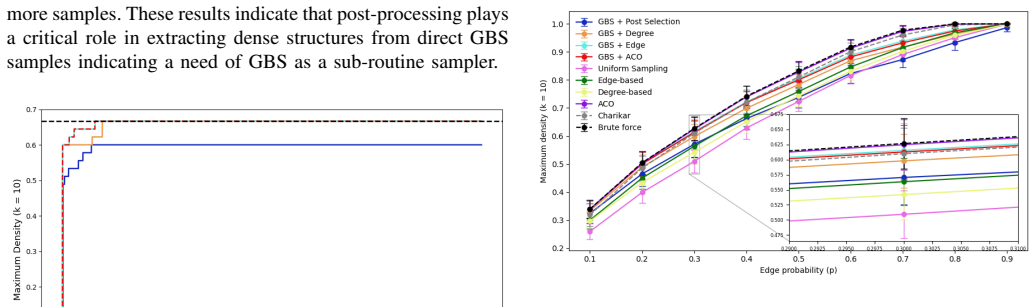
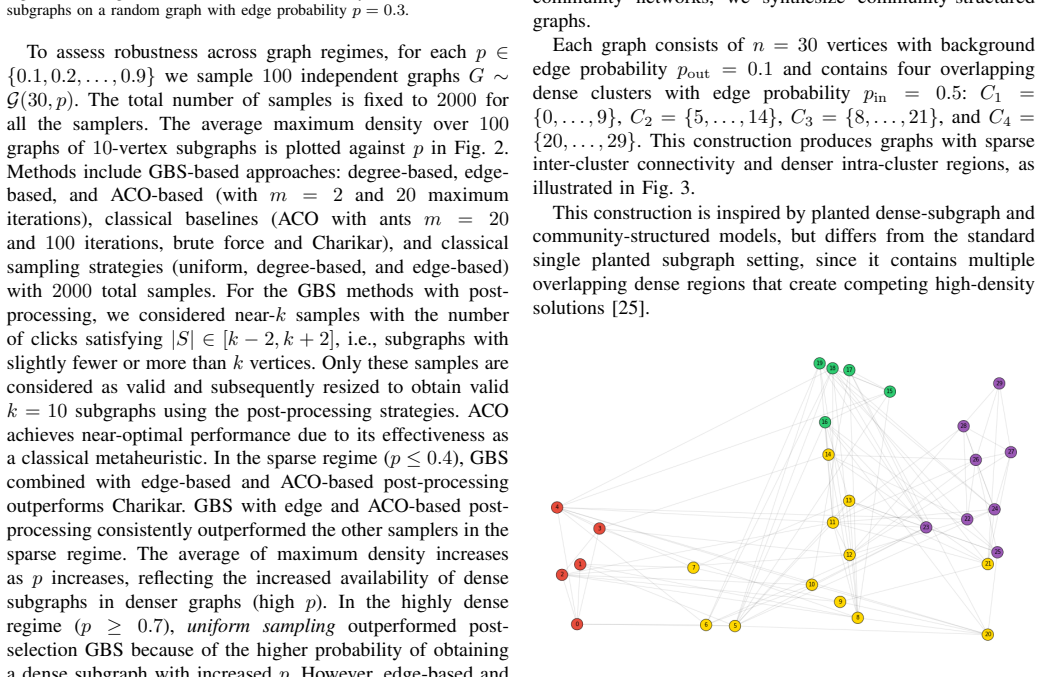
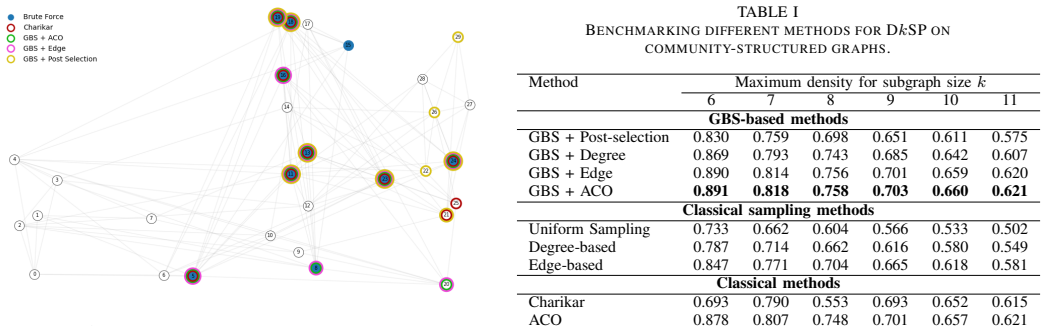
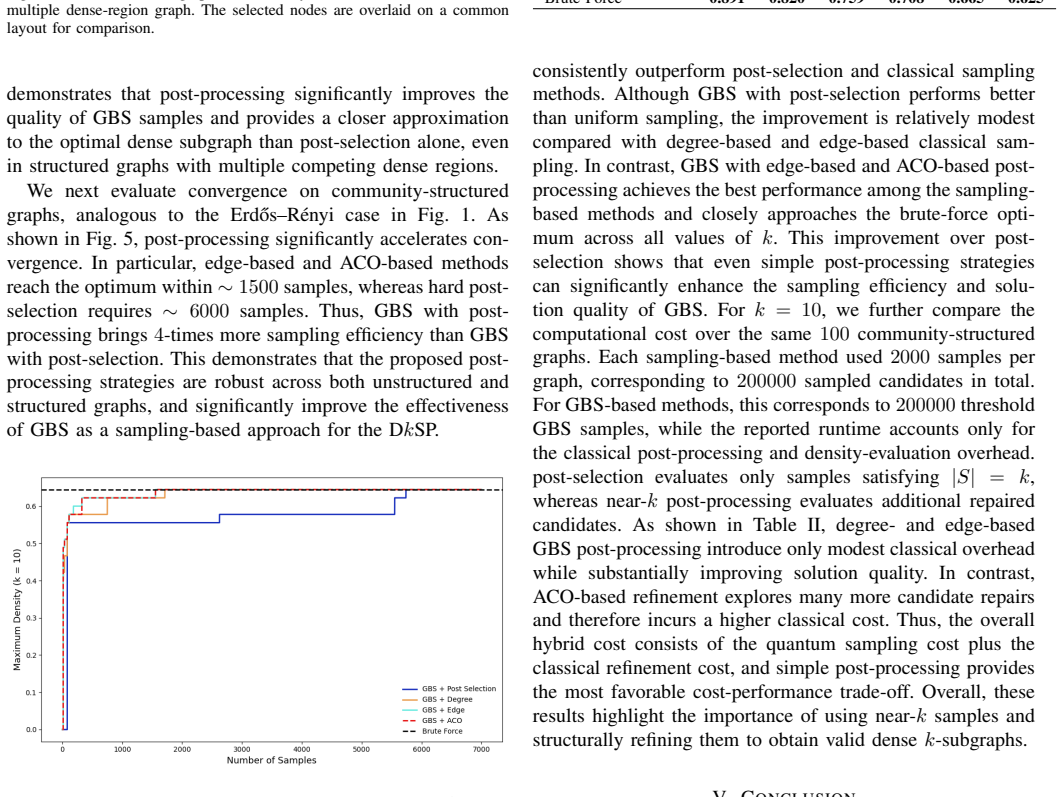
GBS with hard post-selection alone proves insufficient for the densest k-subgraph problem because strict cardinality filtering produces low sampling efficiency. Classical post-processing strategies that convert near-k samples into feasible solutions deliver near-optimal solution quality, raise sampling efficiency by approximately 4X on community-structured graphs, and still perform on par with or better than established classical heuristics for graphs of moderate size. On sparse random graphs, pure post-selection frequently fails to recover the optimum even after drawing large numbers of samples. The results indicate that GBS functions best as a sampling primitive inside a hybrid quantum-cla
What carries the argument
Classical post-processing strategies that transform near-k GBS samples into feasible k-subgraph solutions.
If this is right
- GBS becomes viable for DkSP only when paired with refinement rather than used with hard post-selection.
- Approximately 4X sampling-efficiency gains appear on graphs that contain community structure.
- The hybrid method matches or exceeds classical baselines on graphs up to moderate size.
- Pure post-selection GBS often misses the optimum on sparse random graphs regardless of sample count.
- GBS can serve as a useful sampling primitive inside hybrid frameworks for combinatorial graph problems.
Where Pith is reading between the lines
- If the classical refinement step stays cheap, the same pattern could apply to larger graphs where pure classical search slows down.
- Analogous near-k cleanup rules might improve GBS performance on other cardinality-constrained combinatorial tasks.
- Any quantum advantage would appear only when the sampling distribution supplies better initial points than classical heuristics at the same total effort.
Load-bearing premise
The classical post-processing steps can turn near-k samples into high-quality feasible solutions without introducing bias or extra cost large enough to cancel any quantum sampling benefit.
What would settle it
Running the hybrid pipeline on a collection of community-structured graphs and finding that total runtime or solution quality is no better than pure post-selection or a standard classical solver.
Figures
read the original abstract
We study the application of Gaussian Boson Sampling (GBS) to the densest k-subgraph problem (DkSP). GBS with hard post-selection suffers from poor sampling efficiency due to strict cardinality constraints. To address this limitation, we introduce effective classical post-processing strategies that transform, otherwise discarded, near-k samples into feasible solutions. A comprehensive set of simulations is carried out, demonstrating that these approaches achieve near-optimal solution quality while improving sampling efficiency by approximately 4X compared to post-selection on community-structured graphs, and also post-selection often fails to reach the optimal solution on sparse random graphs even with large number of samples. Furthermore, the proposed methods perform on par with, and in some cases outperform, established classical approaches for graphs up to moderate size. Overall, the results indicate that while GBS with post-selection alone is insufficient, its combination with lightweight classical refinement can be highly effective. This underscores the potential of hybrid quantum-classical frameworks and positions GBS as a promising sampling primitive for combinatorial graph optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies Gaussian Boson Sampling (GBS) applied to the densest k-subgraph problem (DkSP). It identifies the poor sampling efficiency of GBS under hard post-selection due to cardinality constraints and proposes classical post-processing strategies to convert near-k samples into feasible k-subgraphs. Simulations are reported to show that the hybrid approach achieves near-optimal solution quality, improves sampling efficiency by approximately 4X over post-selection on community-structured graphs, outperforms or matches classical methods on moderate-sized graphs, and that pure post-selection often fails to reach optima on sparse random graphs.
Significance. If the simulation results and efficiency claims hold under scrutiny, the work would provide concrete evidence that GBS can function as a useful sampling primitive for combinatorial graph problems when augmented by lightweight classical refinement, supporting the broader case for hybrid quantum-classical solvers.
major comments (2)
- [Abstract] Abstract: the central efficiency claim of an approximately 4X sampling improvement and the assertion that post-processing is 'lightweight' are presented without any reported graph sizes, number of trials, error bars, baseline implementations, runtime breakdowns, or big-O analysis of the refinement steps. These omissions make it impossible to verify whether the reported gain produces a net wall-clock benefit.
- [Abstract] Abstract: the quality claim that the hybrid method reaches 'near-optimal' solutions and 'performs on par with, and in some cases outperforms, established classical approaches' rests on unspecified simulation details; without explicit comparison protocols or data on how near-k samples are converted, the load-bearing assertion that classical post-processing adds negligible cost cannot be assessed.
minor comments (1)
- [Abstract] The abstract refers to 'a comprehensive set of simulations' and 'community-structured graphs' and 'sparse random graphs' without citing specific figures, tables, or sections that contain the supporting data.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback focused on the abstract. We address each comment below and agree that the abstract can be strengthened for greater self-containment while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central efficiency claim of an approximately 4X sampling improvement and the assertion that post-processing is 'lightweight' are presented without any reported graph sizes, number of trials, error bars, baseline implementations, runtime breakdowns, or big-O analysis of the refinement steps. These omissions make it impossible to verify whether the reported gain produces a net wall-clock benefit.
Authors: We agree that the abstract would benefit from additional context on the simulation parameters supporting the efficiency claim. The main text reports the relevant details, including the specific sizes of the community-structured graphs tested, the number of trials performed, error bars on the sampling efficiency, and direct runtime comparisons against pure post-selection. The post-processing consists of simple local adjustments (node addition or removal) whose per-sample cost is linear in k and is shown to be negligible relative to the sampling overhead in the reported experiments. We will revise the abstract to include representative graph sizes and a brief qualifier on the overhead to allow readers to assess net wall-clock impact directly from the summary. revision: yes
-
Referee: [Abstract] Abstract: the quality claim that the hybrid method reaches 'near-optimal' solutions and 'performs on par with, and in some cases outperforms, established classical approaches' rests on unspecified simulation details; without explicit comparison protocols or data on how near-k samples are converted, the load-bearing assertion that classical post-processing adds negligible cost cannot be assessed.
Authors: We concur that the abstract would be improved by referencing the scale and nature of the comparisons. The manuscript details the conversion procedure for near-k samples (a lightweight greedy density-maximizing adjustment to cardinality k) and presents explicit head-to-head results against classical baselines such as greedy heuristics and SDP relaxations on the same moderate-sized instances. These results, including solution quality metrics and runtime breakdowns, appear in the simulation section. We will update the abstract to note the graph-size regime and the character of the post-processing step so that the quality and cost claims are more readily verifiable from the abstract itself. revision: yes
Circularity Check
No circularity: empirical simulation results with no derivations or self-referential fitting.
full rationale
The paper presents an application of GBS to DkSP via simulations on community-structured and random graphs, claiming improved sampling efficiency (~4X) and near-optimal quality through classical post-processing of near-k samples. No equations, parameter fittings, uniqueness theorems, or ansatzes are referenced in the abstract or described claims. The central results rest on direct simulation outputs comparing GBS+refinement against post-selection and classical baselines, without any reduction of predictions to inputs by construction or load-bearing self-citations. This is a standard empirical hybrid quantum-classical study whose validity hinges on external reproducibility of the simulations rather than internal definitional closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The densek-subgraph problem,
U. Feige, G. Kortsarz, and D. Peleg, “The densek-subgraph problem,” Algorithmica, vol. 29, no. 3, pp. 410–421, 2001
2001
-
[2]
Dense subgraph discovery: Kdd 2015 tutorial,
A. Gionis and C. E. Tsourakakis, “Dense subgraph discovery: Kdd 2015 tutorial,” inProceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2015, pp. 2313–2314
2015
-
[3]
Dense subgraph extraction with application to community detection,
J. Chen and Y . Saad, “Dense subgraph extraction with application to community detection,”IEEE Transactions on Knowledge and Data Engineering, vol. 24, no. 7, pp. 1216–1230, 2012
2012
-
[4]
Inferring strange behavior from connectivity pattern in social networks,
M. Jiang, P. Cui, A. Beutel, C. Faloutsos, and S. Yang, “Inferring strange behavior from connectivity pattern in social networks,” inAdvances in Knowledge Discovery and Data Mining, ser. Lecture Notes in Computer Science, V . S. Tseng, T. B. Ho, Z.-H. Zhou, A. L. P. Chen, and H.-Y . Kao, Eds. Cham: Springer International Publishing, 2014, pp. 126–138
2014
-
[5]
Densest subgraph discovery on large graphs: applications, challenges, and techniques,
Y . Fang, W. Luo, and C. Ma, “Densest subgraph discovery on large graphs: applications, challenges, and techniques,”Proc. VLDB Endow., vol. 15, no. 12, p. 3766–3769, Aug. 2022. [Online]. Available: https://doi.org/10.14778/3554821.3554895
-
[6]
Spotlight: Detecting anomalies in streaming graphs,
D. Eswaran, C. Faloutsos, S. Guha, and N. Mishra, “Spotlight: Detecting anomalies in streaming graphs,” inProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2018, pp. 1378–1386
2018
-
[7]
Almost-polynomial ratio ETH-hardness of approxi- mating densestk-subgraph,
P. Manurangsi, “Almost-polynomial ratio ETH-hardness of approxi- mating densestk-subgraph,” inProceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing (STOC). ACM, 2017, pp. 954–961
2017
-
[8]
Finding a maximum density subgraph,
A. V . Goldberg, “Finding a maximum density subgraph,”University of California Berkeley Technical Report, 1984
1984
-
[9]
P. M. Pardalos and J. Xue, “The maximum clique problem,”Journal of Global Optimization, vol. 4, no. 3, pp. 301–328, Apr 1994. [Online]. Available: https://doi.org/10.1007/BF01098364
-
[10]
Gaussian boson sampling,
C. S. Hamilton, R. Kruse, L. Sansoni, S. Barkhofen, C. Silberhorn, and I. Jex, “Gaussian boson sampling,”Phys. Rev. Lett., vol. 119, p. 170501, Oct 2017. [Online]. Available: https://link.aps.org/doi/10.1103/ PhysRevLett.119.170501
2017
-
[11]
Using gaussian boson sampling to find dense subgraphs,
J. M. Arrazola and T. R. Bromley, “Using gaussian boson sampling to find dense subgraphs,”Phys. Rev. Lett., vol. 121, p. 030503, Jul
-
[12]
[Online]. Available: https://link.aps.org/doi/10.1103/PhysRevLett. 121.030503
-
[13]
Locally densest subgraph discovery,
L. Qin, R.-H. Li, L. Chang, and C. Zhang, “Locally densest subgraph discovery,” inProceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’15. New York, NY , USA: Association for Computing Machinery, 2015, p. 965–974. [Online]. Available: https://doi.org/10.1145/2783258.2783299
-
[14]
Solving graph problems using gaussian boson sampling,
Y .-H. Denget al., “Solving graph problems using gaussian boson sampling,”Phys. Rev. Lett., vol. 130, p. 190601, May 2023. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevLett.130.190601
-
[15]
Molecular docking with gaussian boson sampling,
L. Banchi, M. Fingerhuth, T. Babej, C. Ing, and J. M. Arrazola, “Molecular docking with gaussian boson sampling,”Science Advances, vol. 6, no. 23, p. eaax1950, 2020. [Online]. Available: https: //www.science.org/doi/abs/10.1126/sciadv.aax1950
-
[16]
Experimentally finding dense subgraphs using a time-bin encoded gaussian boson sampling device,
S. Sempere-Llagostera, R. B. Patel, I. A. Walmsley, and W. S. Kolthammer, “Experimentally finding dense subgraphs using a time-bin encoded gaussian boson sampling device,”Phys. Rev. X, vol. 12, p. 031045, Sep 2022. [Online]. Available: https: //link.aps.org/doi/10.1103/PhysRevX.12.031045
-
[17]
Greedy approximation algorithms for finding dense com- ponents in a graph,
M. Charikar, “Greedy approximation algorithms for finding dense com- ponents in a graph,” inApproximation Algorithms for Combinatorial Optimization, K. Jansen and S. Khuller, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2000, pp. 84–95
2000
-
[18]
Ant colony optimization: a new meta- heuristic,
M. Dorigo and G. Di Caro, “Ant colony optimization: a new meta- heuristic,” inProceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), vol. 2, 1999, pp. 1470–1477 V ol. 2
1999
-
[19]
A survey on the densest subgraph problem and its variants,
T. Lanciano, A. Miyauchi, A. Fazzone, and F. Bonchi, “A survey on the densest subgraph problem and its variants,”ACM Comput. Surv., vol. 56, no. 8, Apr. 2024. [Online]. Available: https://doi.org/10.1145/3653298
-
[20]
On solving the densest k-subgraph problem on large graphs,
R. Sotirov, “On solving the densest k-subgraph problem on large graphs,”Optimization Methods and Software, vol. 35, no. 6, pp. 1160– 1178, 2020. [Online]. Available: https://doi.org/10.1080/10556788.2019. 1595620
-
[21]
On finding dense subgraphs,
S. Khuller and B. Saha, “On finding dense subgraphs,” inInternational Colloquium on Automata, Languages and Programming, 2009. [Online]. Available: https://api.semanticscholar.org/CorpusID:1774289
2009
-
[22]
Effect of photonic errors on quantum enhanced dense-subgraph finding,
N. R. Solomons, O. F. Thomas, and D. P. S. McCutcheon, “Effect of photonic errors on quantum enhanced dense-subgraph finding,” Phys. Rev. Appl., vol. 20, p. 054043, Nov 2023. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevApplied.20.054043
-
[23]
Applications of near-term photonic quantum computers: software and algorithms,
T. R. Bromleyet al., “Applications of near-term photonic quantum computers: software and algorithms,”Quantum Science and Technology, vol. 5, no. 3, p. 034010, 2020
2020
-
[24]
On the evolution of random graphs,
P. Erd ˝os and A. Rényi, “On the evolution of random graphs,”Publication of the Mathematical Institute of the Hungarian Academy of Sciences, vol. 5, pp. 17–61, 1960
1960
-
[25]
Strawberry Fields: A Software Platform for Photonic Quantum Computing,
N. Killoran, J. Izaac, N. Quesada, V . Bergholm, M. Amy, and C. Weedbrook, “Strawberry Fields: A Software Platform for Photonic Quantum Computing,”Quantum, vol. 3, p. 129, Mar. 2019. [Online]. Available: https://doi.org/10.22331/q-2019-03-11-129
-
[26]
Modularity and community structure in networks
M. E. J. Newman, “Modularity and community structure in networks,”Proceedings of the National Academy of Sciences, vol. 103, no. 23, pp. 8577–8582, 2006. [Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas.0601602103
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.