Polyphony: Diffusion-based Dual-Hand Action Segmentation with Alternating Vision Transformer and Semantic Conditioning
Pith reviewed 2026-06-28 22:57 UTC · model grok-4.3
The pith
A shared vision transformer trained on alternating left- and right-hand batches, conditioned on semantic action descriptions, segments actions for both hands from video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Polyphony shows that an Alternating Dual-Hand Vision Transformer, which switches between left-hand and right-hand mini-batches while sharing one spatio-temporal encoder, combined with Semantic Feature Conditioning that matches visual features to compositional action text and a diffusion segmentation head that performs cross-hand fusion plus adaptive loss weighting, produces state-of-the-art dense action predictions on dual-hand video datasets and also on the single-stream Breakfast dataset, all with a single backbone that outperforms prior methods using much larger backbones or separate per-hand models.
What carries the argument
The Alternating Dual-Hand Vision Transformer, which alternates left- and right-hand mini-batches on a shared spatio-temporal encoder to balance gradient contributions from both hands.
If this is right
- A single shared backbone can surpass separate per-hand models on dual-hand segmentation.
- Semantic conditioning on compositional action descriptions improves discrimination among similar fine-grained actions.
- Cross-hand feature fusion inside the diffusion process coordinates inter-hand dependencies.
- The same architecture reaches 82.5 percent on the single-stream Breakfast dataset while using a backbone twelve times smaller than the prior best method.
- Adaptive loss weighting during diffusion training balances performance across the two hands.
Where Pith is reading between the lines
- The alternating-batch idea could be tested on other asymmetric multi-task settings where one task normally dominates gradients, such as dominant versus non-dominant limb tracking.
- If the shared encoder proves effective across hands, the same principle might extend to multi-person interaction videos by cycling through more than two streams.
- Semantic conditioning might be replaced or augmented with other structured priors, such as object affordance graphs, to further reduce ambiguity in fine-grained actions.
- The reported gains on both dual-hand and single-hand data suggest the method could serve as a drop-in replacement for existing single-hand action segmentation pipelines.
Load-bearing premise
Alternating left- and right-hand mini-batches during training will produce balanced gradient contributions from both hands without introducing new biases or convergence problems in the shared encoder.
What would settle it
A controlled comparison in which simultaneous training on mixed left-right batches yields higher accuracy and more balanced per-hand performance than the alternating schedule would falsify the necessity of alternation.
Figures

read the original abstract
Dual-hand action segmentation, densely predicting actions for both hands from untrimmed videos, is essential for understanding complex bimanual activities. However, it poses several unique challenges: complex inter-hand dependencies, visual asymmetry between hands, representation conflicts where the dominant hand monopolizes gradients, and semantic ambiguity in fine-grained actions. We propose Polyphony, a three-stage method to address these challenges through: (1) an Alternating Dual-Hand Vision Transformer that alternates training between left- and right-hand mini-batches to ensure balanced gradient contributions from both hands while sharing a spatio-temporal encoder; (2) Semantic Feature Conditioning that aligns visual features with structured, compositional action descriptions to enhance discrimination of semantically similar actions; and (3) Diffusion-Based Segmentation with cross-hand feature fusion for inter-hand coordination and adaptive loss weighting for balancing performance. Polyphony achieves state-of-the-art on both dual-hand datasets (HA-ViD, ATTACH) with improvements up to 16.8 points, and on the single-stream Breakfast dataset (82.5%), outperforming the prior best method that uses a 12x larger backbone. Notably, our unified model with a single shared backbone surpasses baselines requiring separate per-hand models. Code is at https://github.com/x-labs-xyz/Polyphony-Dual-hand-Action-Segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Polyphony, a three-stage framework for dual-hand action segmentation from untrimmed videos. Stage 1 is an Alternating Dual-Hand Vision Transformer that alternates left- and right-hand mini-batches to balance gradients while sharing a spatio-temporal encoder; Stage 2 applies Semantic Feature Conditioning to align visual features with compositional action descriptions; Stage 3 uses Diffusion-Based Segmentation incorporating cross-hand feature fusion and adaptive loss weighting. The work claims state-of-the-art results on the dual-hand datasets HA-ViD and ATTACH (gains up to 16.8 points) and on the single-stream Breakfast dataset (82.5%), with a single shared-backbone model outperforming separate per-hand baselines. Code is released at https://github.com/x-labs-xyz/Polyphony-Dual-hand-Action-Segmentation.
Significance. If the performance claims hold after proper validation, the contribution would be significant for bimanual action understanding by demonstrating effective handling of inter-hand dependencies and visual asymmetry via a unified model rather than separate per-hand networks. The open release of code is a clear strength that enables reproducibility and extension by the community.
major comments (2)
- [§3.1] §3.1: The claim that alternating left- and right-hand mini-batches 'ensures balanced gradient contributions from both hands while sharing a spatio-temporal encoder' is unsupported by any reported monitoring of per-hand gradient norms, analysis of convergence under batch switching, or ablation that isolates alternation from semantic conditioning and diffusion fusion. This directly undermines attribution of the unified-model advantage over separate per-hand baselines.
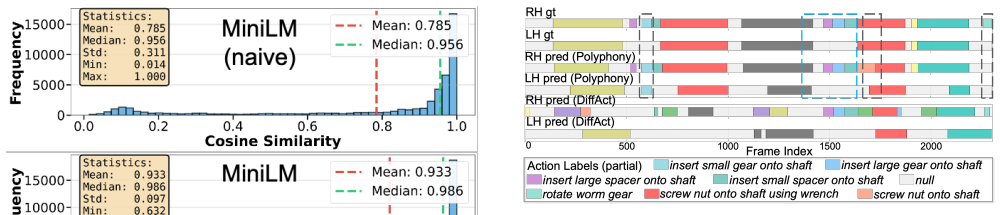
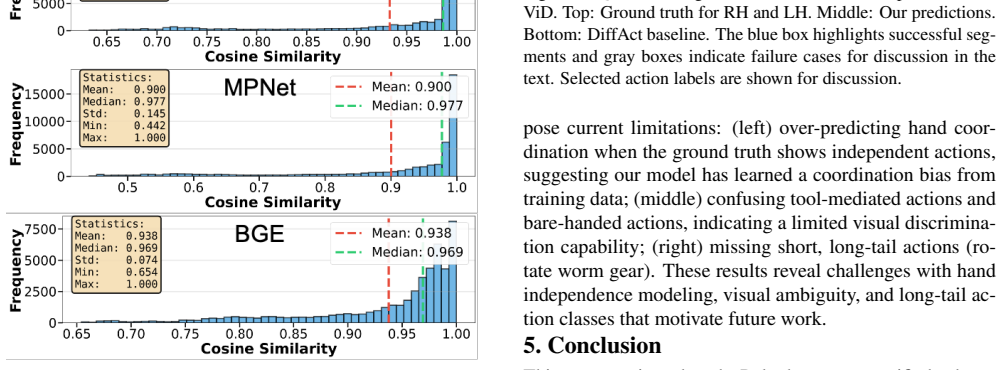
- [Abstract] Abstract and experimental claims: Reported SOTA gains of up to 16.8 points on HA-ViD/ATTACH and 82.5% on Breakfast are presented without any description of baseline implementations, number of runs, statistical significance tests, error bars, or ablation studies isolating each stage. The central empirical claim therefore cannot be verified from the provided evidence.
minor comments (1)
- [§3.3] The diffusion fusion and adaptive loss weighting mechanisms in Stage 3 would benefit from explicit equations or pseudocode to clarify implementation details.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address each of the major comments below and plan to incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§3.1] §3.1: The claim that alternating left- and right-hand mini-batches 'ensures balanced gradient contributions from both hands while sharing a spatio-temporal encoder' is unsupported by any reported monitoring of per-hand gradient norms, analysis of convergence under batch switching, or ablation that isolates alternation from semantic conditioning and diffusion fusion. This directly undermines attribution of the unified-model advantage over separate per-hand baselines.
Authors: We acknowledge that the current manuscript does not report explicit monitoring of per-hand gradient norms or dedicated ablations isolating the effect of alternation from the other components. To address this, we will include in the revised version: (1) plots showing per-hand gradient norms during training with alternating batches versus non-alternating, (2) convergence analysis under batch switching, and (3) an ablation study that isolates the contribution of the alternating training strategy. This will provide direct evidence for the balanced gradient contributions and support the attribution of the unified model's advantages. revision: yes
-
Referee: [Abstract] Abstract and experimental claims: Reported SOTA gains of up to 16.8 points on HA-ViD/ATTACH and 82.5% on Breakfast are presented without any description of baseline implementations, number of runs, statistical significance tests, error bars, or ablation studies isolating each stage. The central empirical claim therefore cannot be verified from the provided evidence.
Authors: We agree that additional details are necessary to substantiate the performance claims. In the revision, we will expand the experimental section to describe the implementation details of all baselines, report results over multiple runs with mean and standard deviation (error bars), include statistical significance tests where appropriate, and provide ablations that isolate the contribution of each stage (alternating transformer, semantic conditioning, and diffusion segmentation). This will allow verification of the reported gains. revision: yes
Circularity Check
No circularity; empirical architecture proposal without derivation chain or self-referential reductions.
full rationale
The manuscript presents Polyphony as a three-stage empirical method (Alternating Dual-Hand Vision Transformer, Semantic Feature Conditioning, Diffusion-Based Segmentation) motivated by listed challenges. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The alternating mini-batch design is stated directly as a solution to gradient imbalance rather than derived from prior results by the same authors or reduced to inputs by construction. The central performance claims rest on experimental outcomes, not on any tautological step. This matches the default case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A human-robot collab- orative assembly framework with quality checking based on real-time dual-hand action segmentation,
H. Zheng, W. Xia, and X. Xu, “A human-robot collab- orative assembly framework with quality checking based on real-time dual-hand action segmentation,”Robotics and Computer-Integrated Manufacturing, vol. 94, p. 102976,
-
[2]
A survey on video-based human action recognition: recent updates, datasets, challenges, and applications,
P. Pareek and A. Thakkar, “A survey on video-based human action recognition: recent updates, datasets, challenges, and applications,” vol. 54, no. 3, pp. 2259–2322
-
[3]
Aligning AI with public values: Deliberation and decision-making for governing multimodal LLMs in politi- cal video analysis,
T. Sharma, Y . Potter, Z. Kilhoffer, Y . Huang, D. Song, and Y . Wang, “Aligning AI with public values: Deliberation and decision-making for governing multimodal LLMs in politi- cal video analysis,” vol. 8, no. 3, pp. 2345–2359. 1
-
[4]
Videomae v2: Scaling video masked autoencoders with dual masking,
L. Wang, B. Huang, Z. Zhao, Z. Tong, Y . He, Y . Wang, Y . Wang, and Y . Qiao, “Videomae v2: Scaling video masked autoencoders with dual masking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14549–14560, June 2023. 1, 5, 7
2023
-
[5]
MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation ,
Y . A. Farha and J. Gall, “ MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation ,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (Los Alamitos, CA, USA), pp. 3570– 3579, IEEE Computer Society, June 2019. 2, 5, 6
2019
-
[6]
Diffusion Action Segmentation ,
D. Liu, Q. Li, A.-D. Dinh, T. Jiang, M. Shah, and C. Xu, “ Diffusion Action Segmentation ,” in2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), (Los Alamitos, CA, USA), pp. 10105–10115, IEEE Computer So- ciety, Oct. 2023. 2, 4, 6
2023
-
[7]
Fact: Frame-action cross-attention temporal modeling for efficient action segmentation,
Z. Lu and E. Elhamifar, “Fact: Frame-action cross-attention temporal modeling for efficient action segmentation,” in 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pp. 18175–18185, 2024. 1, 2, 6
2024
-
[8]
Ha-vid: A human assem- bly video dataset for comprehensive assembly knowledge understanding,
H. Zheng, R. Lee, and Y . Lu, “Ha-vid: A human assem- bly video dataset for comprehensive assembly knowledge understanding,” inAdvances in Neural Information Process- ing Systems(A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, eds.), vol. 36, pp. 67069–67081, Curran Associates, Inc., 2023. 1, 5, 7
2023
-
[9]
Robot cooking with stir-fry: Bimanual non-prehensile manipulation of semi-fluid objects,
J. Liu, Y . Chen, Z. Dong, S. Wang, S. Calinon, M. Li, and F. Chen, “Robot cooking with stir-fry: Bimanual non-prehensile manipulation of semi-fluid objects,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 5159– 5166, 2022
2022
-
[10]
Continuous monitoring of surgical bimanual expertise us- ing deep neural networks in virtual reality simulation,
R. Yilmaz, A. Winkler-Schwartz, N. Mirchi, A. Reich, S. Christie, D. H. Tran, N. Ledwos, A. M. Fazlollahi, C. San- taguida, A. J. Sabbagh, K. Bajunaid, and R. Del Maestro, “Continuous monitoring of surgical bimanual expertise us- ing deep neural networks in virtual reality simulation,” vol. 5, no. 1, p. 54. 1
-
[11]
Two hands, one brain: cognitive neuroscience of bimanual skill,
S. P. Swinnen and N. Wenderoth, “Two hands, one brain: cognitive neuroscience of bimanual skill,” vol. 8, no. 1, pp. 18–25. 1
-
[12]
Predictive cod- ing: an account of the mirror neuron system,
J. M. Kilner, K. J. Friston, and C. D. Frith, “Predictive cod- ing: an account of the mirror neuron system,” vol. 8, no. 3, pp. 159–166. 2
-
[13]
Temporal Convolutional Networks for Action Segmentation and Detection ,
C. Lea, M. D. Flynn, R. Vidal, A. Reiter, and G. D. Hager, “ Temporal Convolutional Networks for Action Segmentation and Detection ,” in2017 IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), (Los Alamitos, CA, USA), pp. 1003–1012, IEEE Computer Society, July 2017. 2
2017
-
[14]
Boundary- aware cascade networks for temporal action segmentation,
Z. Wang, Z. Gao, L. Wang, Z. Li, and G. Wu, “Boundary- aware cascade networks for temporal action segmentation,” inECCV (25), vol. 12370 ofLecture Notes in Computer Sci- ence, pp. 34–51, Springer, 2020. 2, 6
2020
-
[15]
Improving action seg- mentation via graph-based temporal reasoning,
Y . Huang, Y . Sugano, and Y . Sato, “Improving action seg- mentation via graph-based temporal reasoning,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14021–14031, 2020. 2
2020
-
[16]
Asformer: Transformer for ac- tion segmentation,
F. Yi, H. Wen, and T. Jiang, “Asformer: Transformer for ac- tion segmentation,” inThe British Machine Vision Confer- ence (BMVC), 2021. 2, 6
2021
-
[17]
Duha: a dual-hand action segmentation method for human-robot collaborative assembly,
H. Zheng, R. Lee, Y . Lu, and X. Xu, “Duha: a dual-hand action segmentation method for human-robot collaborative assembly,” in2024 IEEE 20th International Conference on Automation Science and Engineering (CASE), pp. 522–527,
-
[18]
Ducas: a knowledge-enhanced dual-hand compositional action seg- mentation method for human-robot collaborative assembly,
H. Zheng, R. Lee, H. Liang, Y . Lu, and X. Xu, “Ducas: a knowledge-enhanced dual-hand compositional action seg- mentation method for human-robot collaborative assembly,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 7175–7180, 2024. 2
2024
-
[19]
Vision-language mod- els for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language mod- els for vision tasks: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5625– 5644, 2024. 2
2024
-
[20]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021. 2
2021
-
[21]
Scaling up vi- sual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. V . Le, Y .-H. Sung, Z. Li, and T. Duerig, “Scaling up vi- sual and vision-language representation learning with noisy text supervision,” inInternational Conference on Machine Learning, 2021. 2
2021
-
[22]
Expanding language-image pretrained models for general video recognition,
B. Ni, H. Peng, M. Chen, S. Zhang, G. Meng, J. Fu, S. Xiang, and H. Ling, “Expanding language-image pretrained models for general video recognition,” inEuropean Conference on Computer Vision, 2022. 2
2022
-
[23]
Actionclip: A new paradigm for video action recognition,
M. Wang, J. Xing, and Y . Liu, “Actionclip: A new paradigm for video action recognition,” 2021. 2
2021
-
[24]
Something-else: Compositional action recog- nition with spatial-temporal interaction networks,
J. Materzynska, T. Xiao, R. Herzig, H. Xu, X. Wang, and T. Darrell, “Something-else: Compositional action recog- nition with spatial-temporal interaction networks,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1046–1056, 2020. 2
2020
-
[25]
Disentangled action recognition with knowledge bases,
Z. Luo, S. Ghosh, D. Guillory, K. Kato, T. Darrell, and H. Xu, “Disentangled action recognition with knowledge bases,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies(M. Carpuat, M.-C. de Marneffe, and I. V . Meza Ruiz, eds.), (Seattle, United States), pp. 5...
2022
-
[26]
Semantic-disentangled transformer with noun-verb embed- ding for compositional action recognition,
P. Huang, R. Yan, X. Shu, Z. Tu, G. Dai, and J. Tang, “Semantic-disentangled transformer with noun-verb embed- ding for compositional action recognition,”IEEE Transac- tions on Image Processing, vol. 33, pp. 297–309, 2024. 2
2024
-
[27]
Knowledge-driven compositional action recognition,
Y . Liu, F. Liu, L. Jiao, Q. Bao, S. Li, L. Li, and X. Liu, “Knowledge-driven compositional action recognition,”Pat- tern Recognition, vol. 163, p. 111452, 2025. 2
2025
-
[28]
Human-robot shared assembly taxonomy: A step toward seamless human-robot knowledge transfer,
R. K.-J. Lee, H. Zheng, and Y . Lu, “Human-robot shared assembly taxonomy: A step toward seamless human-robot knowledge transfer,”Robotics and Computer-Integrated Manufacturing, vol. 86, p. 102686, 2024. 2, 4
2024
-
[29]
An im- age is worth 16x16 words: Transformers for image recogni- tion at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An im- age is worth 16x16 words: Transformers for image recogni- tion at scale,” 2021. 3
2021
-
[30]
Improved denoising diffusion probabilistic models,
A. Nichol and P. Dhariwal, “Improved denoising diffusion probabilistic models,” 2021. 4
2021
-
[31]
Attach dataset: Annotated two-handed assembly actions for human action understanding,
D. Aganian, B. Stephan, M. Eisenbach, C. Stretz, and H.- M. Gross, “Attach dataset: Annotated two-handed assembly actions for human action understanding,” in2023 IEEE In- ternational Conference on Robotics and Automation (ICRA), pp. 11367–11373, 2023. 5
2023
-
[32]
The language of ac- tions: Recovering the syntax and semantics of goal-directed human activities,
H. Kuehne, A. Arslan, and T. Serre, “The language of ac- tions: Recovering the syntax and semantics of goal-directed human activities,” in2014 IEEE Conference on Computer Vision and Pattern Recognition, pp. 780–787, 2014. 5
2014
-
[33]
The kinetics human action video dataset,
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Nat- sev, M. Suleyman, and A. Zisserman, “The kinetics human action video dataset,” 2017. 5
2017
-
[34]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,” inAdvances in Neural Information Processing Systems(H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, eds.), vol. 33, pp. 5776–5788, Curran Associates, Inc., 2020. 5, 7
2020
-
[35]
Temporal relational modeling with self-supervision for action segmentation,
D. Wang, D. Hu, X. Li, and D. Dou, “Temporal relational modeling with self-supervision for action segmentation,”
-
[36]
C2f-tcn: A frame- work for semi- and fully-supervised temporal action segmen- tation,
D. Singhania, R. Rahaman, and A. Yao, “C2f-tcn: A frame- work for semi- and fully-supervised temporal action segmen- tation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 11484–11501, 2023. 6
2023
-
[37]
How much temporal long-term context is needed for action segmentation?,
E. Bahrami, G. Francesca, and J. Gall, “How much temporal long-term context is needed for action segmentation?,” 2023. 6
2023
-
[38]
End-to-end action segmentation transformer,
T. Wang and S. Todorovic, “End-to-end action segmentation transformer,” 2025. 6
2025
-
[39]
Tsm: Temporal shift module for efficient video understanding,
J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” in2019 IEEE/CVF Inter- national Conference on Computer Vision (ICCV), pp. 7082– 7092, 2019. 7
2019
-
[40]
Is space-time at- tention all you need for video understanding?,
G. Bertasius, H. Wang, and L. Torresani, “Is space-time at- tention all you need for video understanding?,” 2021. 7
2021
-
[41]
Quo vadis, action recogni- tion? a new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recogni- tion? a new model and the kinetics dataset,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4724–4733, 2017. 7
2017
-
[42]
Mvitv2: Improved multiscale vi- sion transformers for classification and detection,
Y . Li, C.-Y . Wu, H. Fan, K. Mangalam, B. Xiong, J. Ma- lik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vi- sion transformers for classification and detection,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4794–4804, 2022. 7
2022
-
[43]
Uniformerv2: Unlocking the potential of image vits for video understanding,
K. Li, Y . Wang, Y . He, Y . Li, Y . Wang, L. Wang, and Y . Qiao, “Uniformerv2: Unlocking the potential of image vits for video understanding,” in2023 IEEE/CVF International Con- ference on Computer Vision (ICCV), pp. 1632–1643, 2023. 7
2023
-
[44]
Mpnet: Masked and permuted pre-training for language understand- ing,
K. Song, X. Tan, T. Qin, J. Lu, and T.-Y . Liu, “Mpnet: Masked and permuted pre-training for language understand- ing,” 2020. 7
2020
-
[45]
Bge m3-embedding: Multi-lingual, multi-functionality, multi- granularity text embeddings through self-knowledge distil- lation,
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “Bge m3-embedding: Multi-lingual, multi-functionality, multi- granularity text embeddings through self-knowledge distil- lation,” 2024. 7
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.