Towards Fast and Effective Long Video Understanding of Multimodal Large Language Models via Adaptive Quasi-Gaussian Sampling
Pith reviewed 2026-06-26 00:51 UTC · model grok-4.3
The pith
AdaQ adapts Gaussian 3-sigma intervals to query type for efficient long-video frame selection in MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
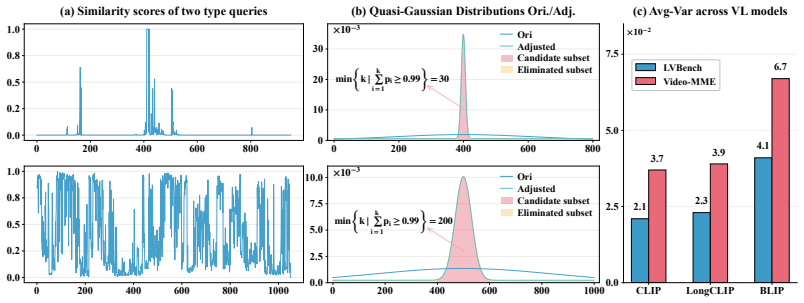
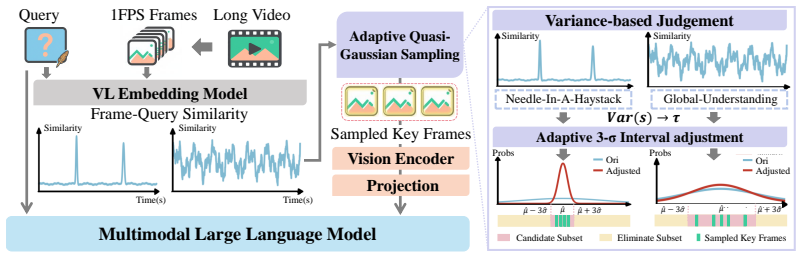
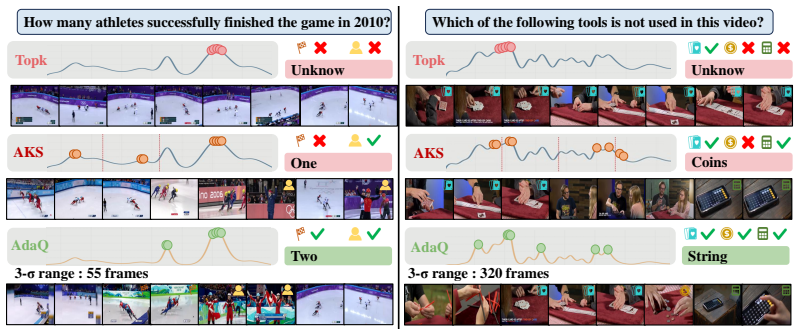
AdaQ achieves robust frame sampling by determining an optimal 3-sigma interval for each example, with the interval contracted for local queries and expanded for global queries, and this strategy improves long-video performance across tested MLLMs without any model training.
What carries the argument
Quasi-Gaussian Sampling, which maps the 3-sigma rule of a Gaussian distribution to adaptive frame-selection intervals that vary with query locality.
If this is right
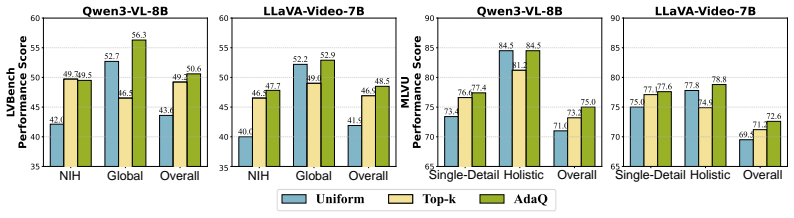
- Reduces required frames to 64 while raising accuracy above both default MLLM behavior and existing keyframe methods.
- Transfers to multiple MLLMs and embedding models without retraining.
- Maintains gains with only one hyperparameter across different video lengths.
- Delivers higher robustness than hard-sampling baselines that suffer from noise or inflexibility.
Where Pith is reading between the lines
- The same adaptive interval logic might apply to other ordered inputs such as audio streams or long documents.
- Extending the method to videos several times longer than the current benchmarks could test whether the local-global distinction remains sufficient.
- Combining AdaQ with existing token-reduction techniques inside the MLLM could produce further efficiency without new training.
Load-bearing premise
The 3-sigma rule of the Gaussian distribution maps directly onto the best frame-selection intervals when the query is either local or global.
What would settle it
A controlled test in which, for a local query, using a fixed large interval produces higher accuracy than the smaller adaptive interval chosen by AdaQ.
Figures

read the original abstract
Long video understanding remains a daunting challenge for Multimodal Large Language Models (MLLMs) due to the excessive computation and memory footprint. Thus, keyframe selection is often adopted to mitigate this shortcoming, which however still suffers from low flexibility and high noise due to its hard sampling principle. In this paper, we define video frame selection as a problem of Quasi-Gaussian Sampling, and propose an adaptive and training-free approach termed AdaQ. Inspired by the 3-$\sigma$ rule of Gaussian distribution, the objective of AdaQ is to achieve the optimal 3-$\sigma$ interval for different examples, i.e., a smaller 3-$\sigma$ interval for the local query and a larger one for the global query, thereby facilitating robust and adaptive frame sampling. To validate AdaQ, we apply it to four MLLMs with three embedding models. The extensive experimental results not only show its obvious performance gains over the default MLLMs and the SOTA keyframe selection methods, e.g., helping Qwen3-VL-8B outperform GPT4o by 15.8% on average by using only 64 frames, but also confirm its superior robustness and high efficiency for long-video understanding, e.g., only 1 hyper-parameter needs to be set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaQ, a training-free adaptive quasi-Gaussian sampling method for keyframe selection in long-video MLLM understanding. It models frame selection via the 3-σ rule of Gaussian distributions, setting smaller intervals for local queries and larger intervals for global queries to achieve 'optimal' adaptive sampling, and reports performance gains (e.g., Qwen3-VL-8B outperforming GPT-4o by 15.8% on average with 64 frames), robustness, and efficiency across four MLLMs and three embedding models while requiring only one hyper-parameter.
Significance. If the empirical claims hold under rigorous validation, AdaQ could provide a lightweight, training-free alternative to existing keyframe methods, reducing compute and memory demands for long videos while improving flexibility over hard sampling. The reported outperformance of strong baselines and single-hyperparameter design would be a practical contribution if the gains are shown to derive from the quasi-Gaussian principle rather than specific interval choices.
major comments (2)
- [Method (AdaQ definition and 3-σ mapping)] The central mechanism (smaller 3-σ interval for local queries, larger for global) is asserted as achieving the 'optimal' interval inspired by the Gaussian rule, yet no derivation, theoretical argument, or ablation is supplied to justify this direction of adaptation over the reverse, uniform sampling, or query-agnostic alternatives; the reported 15.8% gain could therefore arise from the particular interval values selected on the evaluation sets.
- [Experiments and abstract claims] The abstract and claims reference 'extensive experimental results' showing gains over default MLLMs and SOTA keyframe methods plus superior robustness, but supply no details on datasets, exact baselines, number of runs, error bars, or implementation steps; without these it is impossible to judge whether the data support the central claim of robustness and outperformance.
minor comments (1)
- [Method] Notation for 'Quasi-Gaussian Sampling' and the precise definition of the adaptive 3-σ interval (including how local vs. global query type is detected) should be formalized with equations to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, clarifying the motivation for AdaQ while acknowledging areas where additional evidence or details would strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (AdaQ definition and 3-σ mapping)] The central mechanism (smaller 3-σ interval for local queries, larger for global) is asserted as achieving the 'optimal' interval inspired by the Gaussian rule, yet no derivation, theoretical argument, or ablation is supplied to justify this direction of adaptation over the reverse, uniform sampling, or query-agnostic alternatives; the reported 15.8% gain could therefore arise from the particular interval values selected on the evaluation sets.
Authors: The adaptation direction follows from the core intuition that local queries benefit from denser sampling near relevant content (smaller 3-σ interval) while global queries require broader temporal coverage (larger interval), consistent with applying the 3-σ rule differently per query type. The manuscript presents this as an empirical design choice validated across four MLLMs and three embedding models rather than a derived optimum. We agree that an ablation comparing the proposed direction against the reverse, uniform sampling, and query-agnostic baselines would directly address whether gains are attributable to the quasi-Gaussian principle. We will add these ablations in the revision. revision: partial
-
Referee: [Experiments and abstract claims] The abstract and claims reference 'extensive experimental results' showing gains over default MLLMs and SOTA keyframe methods plus superior robustness, but supply no details on datasets, exact baselines, number of runs, error bars, or implementation steps; without these it is impossible to judge whether the data support the central claim of robustness and outperformance.
Authors: The experimental section reports results on long-video benchmarks using four MLLMs (e.g., Qwen3-VL-8B) and three embedding models, with the 15.8% average gain versus GPT-4o at 64 frames and comparisons to default and SOTA keyframe methods. The abstract summarizes these findings concisely. We acknowledge that explicit statements on the number of runs, error bars, and precise implementation steps would improve clarity and support claims of robustness. In the revised manuscript we will add these details, including error bars where feasible. revision: yes
Circularity Check
No circularity: AdaQ is a posited heuristic without derivation that reduces to its inputs
full rationale
The paper defines its objective directly as achieving smaller 3-σ intervals for local queries and larger ones for global queries, inspired by the Gaussian rule, but presents this as an assumption rather than a derived result from prior equations or self-citations. No load-bearing step equates a prediction to a fitted input or renames a result by construction. Performance gains are reported as empirical outcomes on external benchmarks with multiple MLLMs, keeping the central claim independent of any internal self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025a. doi: 10.48550/arXiv.2511.21631. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631
-
[2]
Tao Chen, Shaobo Ju, Qiong Wu, Chenxin Fang, Kun Zhang, Jun Peng, Hui Li, Yiyi Zhou, and Rongrong Ji
ISBN 978-0534243128. Tao Chen, Shaobo Ju, Qiong Wu, Chenxin Fang, Kun Zhang, Jun Peng, Hui Li, Yiyi Zhou, and Rongrong Ji. Towards effective and efficient long video understanding of multimodal large language models via one-shot clip retrieval.arXiv preprint arXiv:2512.08410,
-
[3]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference.arXiv preprint arXiv:2407.11550,
-
[4]
De-An Huang, Subhashree Radhakrishnan, Zhiding Yu, and Jan Kautz. Frag: Frame selec- tion augmented generation for long video and long document understanding.arXiv preprint arXiv:2504.17447,
-
[5]
Gpt-4o system card.arXiv preprint arXiv:2410.21276,
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
-
[6]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992,
2023
-
[7]
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, and Hyun Oh Song. Kvzip: Query-agnostic KV cache compression with context reconstruction.CoRR, abs/2505.23416, 2025a. doi: 10.48550/ARXIV .2505.23416. Junhyuck Kim, Jongho Park, Jaewoong Cho, and Dimitris Papailiopoulos. Lexico: Extreme KV cache compression via sparse coding over universal d...
work page internal anchor Pith review doi:10.48550/arxiv
-
[8]
OpenReview.net, 2025b. Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
-
[9]
Llava-onevision: Easy visual task transfer.Trans
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.Trans. Mach. Learn. Res., 2025, 2025a. 10 Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre- training for unified vision-language underst...
2025
-
[10]
Video-rag: Visually-aligned retrieval-augmented long video comprehension
Yongdong Luo, Xiawu Zheng, Xiao Yang, Guilin Li, Haojia Lin, Jinfa Huang, Jiayi Ji, Fei Chao, Jiebo Luo, and Rongrong Ji. Video-rag: Visually-aligned retrieval-augmented long video comprehension. arXiv Preprint, 2024.https://arxiv.org/abs/2411.13093. Ziyu Ma, Chenhui Gou, Hengcan Shi, Bin Sun, Shutao Li, Hamid Rezatofighi, and Jianfei Cai. Drvideo: Docume...
arXiv 2024
-
[11]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
Accessed: 2026-01-19. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
2026
-
[12]
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang
https: //arxiv.org/abs/2502.01549. Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models.arXiv preprint arXiv:2505.21334,
-
[13]
Longvu: Spatiotemporal adaptive compression for long video-language understanding
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spatiotemporal adaptive compression for long video-language understanding. InForty-second International Conference on Machine Learning. 11 Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo,...
2024
-
[14]
Cache me if you must: Adaptive key-value quantization for large language models
Alina Shutova, Vladimir Malinovskii, Vage Egiazarian, Denis Kuznedelev, Denis Mazur, Nikita Surkov, Ivan Ermakov, and Dan Alistarh. Cache me if you must: Adaptive key-value quantization for large language models. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19,
2025
-
[15]
URLhttps://doi.org/10.1609/aaai.v40i11.37862
doi: 10.1609/aaai.v40i11.37862. URLhttps://doi.org/10.1609/aaai.v40i11.37862. Zhen Sun, Yunhang Shen, Jie Li, Xing Sun, Pingyang Dai, Liujuan Cao, and Rongrong Ji. Ds- vlm: Diffusion supervision vision language model. InForty-second International Conference on Machine Learning,
-
[16]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
-
[17]
Bo Tong, Bokai Lai, Yiyi Zhou, Gen Luo, Yunhang Shen, Ke Li, Xiaoshuai Sun, and Rongrong Ji
doi: 10.1007/0-387-34240-0. Bo Tong, Bokai Lai, Yiyi Zhou, Gen Luo, Yunhang Shen, Ke Li, Xiaoshuai Sun, and Rongrong Ji. Flashsloth : Lightning multimodal large language models via embedded visual compression. In CVPR, pages 14570–14581,
-
[18]
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. Lvbench: An extreme long video understanding benchmark.arXiv Preprint, 2024a.https://arxiv.org/abs/2406.08035. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Ji...
Pith/arXiv arXiv 2025
-
[19]
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms.arXiv preprint arXiv:2506.22139,
-
[20]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: A comprehensive benchmark for multi-task long video understanding.arXiv Preprint, 2024.https://arxiv.org/abs/2406.04264. Zirui Zhu, Hailun Xu, Yang Luo, Yong Liu, Kanchan Sarkar, Zhenheng Yang, and Yang You. Focus: Efficient keyframe ...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.