Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
Pith reviewed 2026-06-27 13:05 UTC · model grok-4.3
The pith
A single LLM bootstraps better agent performance by simultaneously simulating both the agent and its training environment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
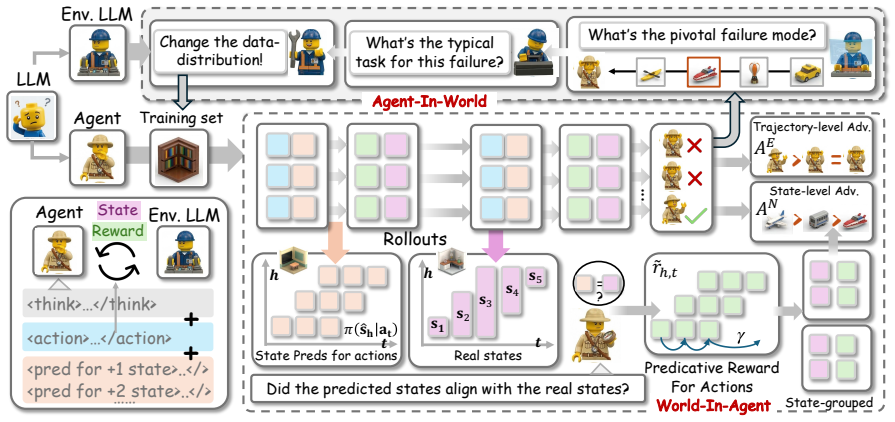
Role-Agent lets a single LLM function as both agent and environment through two linked roles: World-In-Agent produces process rewards from the match between predicted and actual next states, while Agent-In-World extracts failure patterns from unsuccessful runs and retrieves matching tasks to reshape the training distribution, producing measurable performance lifts.
What carries the argument
Dual-role co-evolution in which the same LLM generates future-state predictions for alignment-based rewards and failure-mode analysis for targeted task retrieval.
If this is right
- Agents can generate their own process rewards without external environment models.
- Training distributions can be reshaped on the fly by pulling tasks that match observed failure modes.
- Environment-aware reasoning emerges from the prediction-alignment signal.
- A single model can drive iterative improvement across multiple benchmarks without added supervision.
Where Pith is reading between the lines
- The same self-simulation loop could be extended to multi-step planning horizons or multi-agent settings.
- If the prediction quality scales with model size, larger models might need fewer external examples to reach the same competence.
- The failure-retrieval step might generalize to domains where tasks share structural error patterns rather than surface features.
Load-bearing premise
The LLM produces accurate enough future-state predictions and failure analyses that the resulting rewards and task selections improve actual task performance rather than merely reinforcing the model's own patterns.
What would settle it
Run the same training loop but replace state-alignment rewards with random scores and replace failure-pattern retrieval with random task sampling; if the performance gain disappears, the dual-role mechanism is not the driver.
Figures






read the original abstract
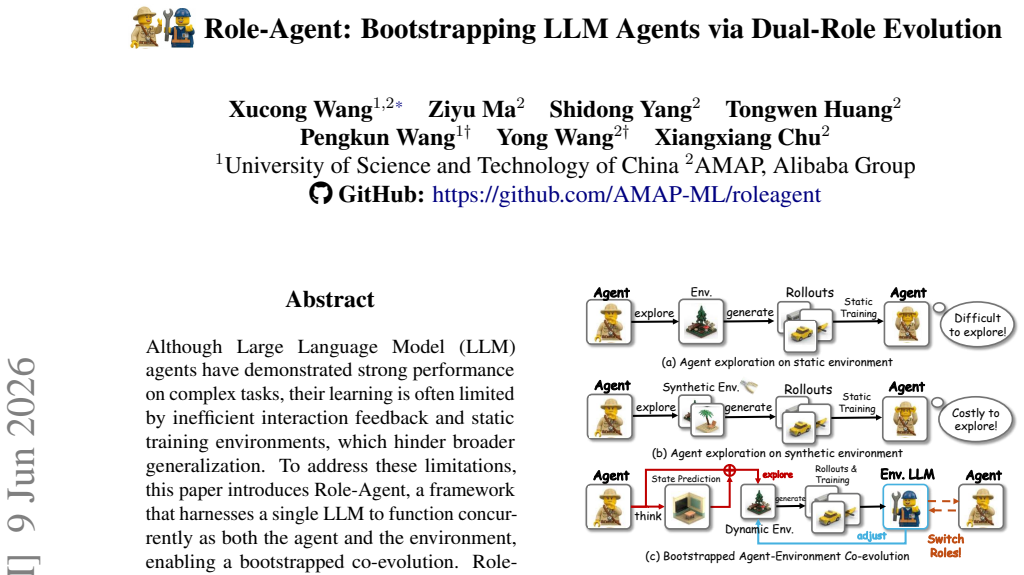
Although Large Language Model (LLM) agents have demonstrated strong performance on complex tasks, their learning is often limited by inefficient interaction feedback and static training environments, which hinder broader generalization. To address these limitations, this paper introduces Role-Agent, \textcolor{black}{a framework} that harnesses a single LLM to function concurrently as both the agent and the environment, enabling a bootstrapped co-evolution. Role-Agent comprises two synergistic components: World-In-Agent (WIA) and Agent-In-World (AIW). In WIA, the LLM acts as the agent and predicts future states after each action; the alignment between predicted and actual states is then used as a process reward, encouraging environment-aware reasoning. In AIW, the LLM analyzes failure modes from failed trajectories and retrieves tasks with similar failure patterns, thereby reshaping the training data distribution for targeted practice. Experiments on multiple benchmarks show that Role-Agent consistently improves performance, yielding an average gain of over 4\% over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Role-Agent, a framework that uses a single LLM to simultaneously serve as both agent and environment via two components: World-In-Agent (WIA), which generates process rewards from alignment between the LLM's predicted and 'actual' future states, and Agent-In-World (AIW), which retrieves tasks based on LLM-generated failure-mode analyses. The central claim is that this dual-role bootstrapping enables co-evolution and yields an average performance improvement of over 4% across multiple benchmarks relative to strong baselines.
Significance. If the claimed gains are shown to arise from genuine generalization rather than intra-model consistency, the approach would be significant for enabling self-improving LLM agents without external simulators or human feedback. The method's reliance on a single model for both roles is a novel direction, but its value hinges on whether the resulting training signals produce capabilities beyond echoing the model's own simulation style.
major comments (3)
- [Abstract, §3] Abstract and §3 (WIA description): the process reward is defined as alignment between two generations from the same LLM (agent prediction vs. environment 'actual' state under different prompts). This makes the signal intra-model consistency rather than grounding in an independent dynamics model; the manuscript must demonstrate that this still produces measurable out-of-distribution generalization rather than overfitting to the LLM's internal patterns.
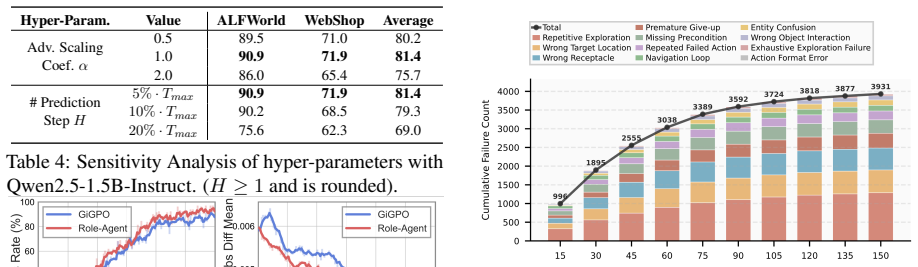
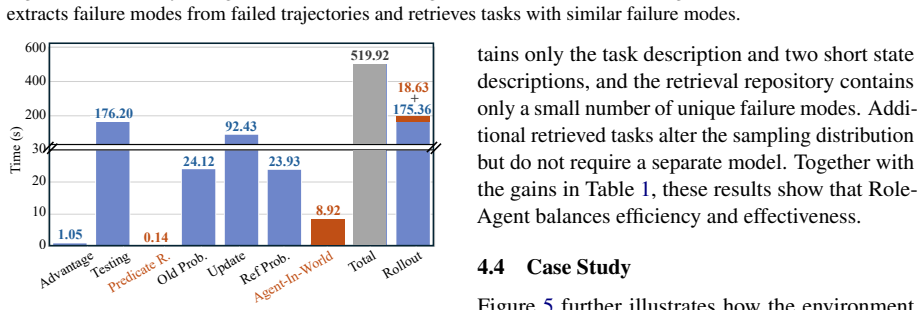
- [Experiments] Experiments section: the reported >4% average gain lacks accompanying details on baseline implementations, number of runs, statistical significance tests, or controls for prompt sensitivity and temperature. Without these, it is impossible to assess whether the improvement is robust or attributable to the dual-role mechanism.
- [§4] §4 (AIW): task retrieval is conditioned on LLM-generated failure-mode analyses from the same model; this inherits the same intra-model risk as WIA and requires explicit validation that retrieved tasks drive new capabilities rather than reinforcing existing failure patterns.
minor comments (2)
- [§3] Notation for the alignment-based reward in WIA should be formalized with an equation rather than described only in prose.
- [Abstract, Experiments] The abstract states 'multiple benchmarks' without naming them; the experiments section should include a table listing all benchmarks, baselines, and per-benchmark scores.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We appreciate the concerns about the intra-model nature of the signals and the need for greater experimental rigor. We address each major comment point by point below, clarifying our position and indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (WIA description): the process reward is defined as alignment between two generations from the same LLM (agent prediction vs. environment 'actual' state under different prompts). This makes the signal intra-model consistency rather than grounding in an independent dynamics model; the manuscript must demonstrate that this still produces measurable out-of-distribution generalization rather than overfitting to the LLM's internal patterns.
Authors: We agree that the WIA process reward is based on intra-model consistency between two generations from the same LLM. This is a deliberate design to enable fully bootstrapped co-evolution without external simulators or human feedback. By aligning the agent's predictions with its own simulated future states, the mechanism encourages more coherent environment-aware reasoning within the model. The reported average gains of over 4% on diverse benchmarks provide initial evidence that this leads to improved task performance rather than mere overfitting. To strengthen the claim, we will add explicit out-of-distribution generalization experiments (e.g., held-out task distributions) in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section: the reported >4% average gain lacks accompanying details on baseline implementations, number of runs, statistical significance tests, or controls for prompt sensitivity and temperature. Without these, it is impossible to assess whether the improvement is robust or attributable to the dual-role mechanism.
Authors: We acknowledge that the current Experiments section lacks sufficient implementation and statistical details. In the revised manuscript, we will expand this section to include complete baseline implementation descriptions, results averaged over multiple independent runs with different random seeds, statistical significance testing (e.g., paired t-tests with p-values), and controls for prompt sensitivity and temperature variations. These additions will allow better assessment of whether the gains are robust and attributable to the dual-role components. revision: yes
-
Referee: [§4] §4 (AIW): task retrieval is conditioned on LLM-generated failure-mode analyses from the same model; this inherits the same intra-model risk as WIA and requires explicit validation that retrieved tasks drive new capabilities rather than reinforcing existing failure patterns.
Authors: We recognize that AIW similarly relies on the LLM's self-generated failure analyses for task retrieval. This is intended to create a dynamic curriculum focused on the model's weaknesses, enabling targeted improvement. The overall benchmark gains indicate that the approach drives capability enhancement rather than simple reinforcement of existing patterns. To address the concern directly, we will add validation analyses in the revision, such as measuring task diversity in retrieved sets and performance improvements on failure modes not present in the original training distribution. revision: yes
Circularity Check
No significant circularity; empirical gains measured externally
full rationale
The paper introduces Role-Agent with WIA and AIW components that use a single LLM in dual roles to generate process rewards via alignment of its own predictions and states. No equations, fitted parameters, or mathematical derivations are present that would reduce the reported benchmark improvements to these internal signals by construction. Performance gains are claimed as empirical results on external benchmarks, and no self-citations or ansatzes are invoked as load-bearing premises in the provided text. The central claim therefore remains independent of self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel
Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978. Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. 2023. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797. Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan...
Pith/arXiv arXiv 2023
-
[2]
Genetic Programming and Evolvable Machines, 25(2):21
Evolving code with a large language model. Genetic Programming and Evolvable Machines, 25(2):21. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Con- ference on Computational Linguistics, pages 6609– 6625. 9 S...
Pith/arXiv arXiv 2020
-
[3]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun...
Pith/arXiv arXiv 2017
-
[4]
Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, and 1 others
-
[5]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Jun- tao Tan, and Yongfeng Zhang
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Jun- tao Tan, and Yongfeng Zhang. 2025. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110. Taofeng Xue, Chong Peng, Mianqiu Huang, Linsen Guo, Tiancheng Han, Haozhe Wang, Jianing Wan...
Pith/arXiv arXiv 2025
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empiri- cal methods in natural language processing, pages 236...
Pith/arXiv arXiv 2018
-
[7]
The task requires the same type of reasoning or skill that the agent is currently failing at
-
[8]
The task’s failure analysis describes a similar root cause or mistake
-
[9]
AGENT_ACTION (step 1)
Re-training on this task would most directly help the agent overcome the current pattern. ## Output Format Output ONLY the following structured block, with no additional text: <selected_tasks> INDEX/TASK/REFLECTIONS: <index, task and reflections from the candidate list> REASON: <one sentence explaining why this task matches the current failure pattern> IN...
-
[10]
TASK": "Put a clean cloth in toilet
"TASK": "Put a clean cloth in toilet.", "RETRIEVED_REFLECTION": "Agent placed dirty cloth directly into toilet. Should have cleaned cloth at sinkbasin first. Rule: check object state precondition before final placement."
-
[11]
TASK": "Put a clean sponge in bathtubbasin
"TASK": "Put a clean sponge in bathtubbasin.", "RETRIEVED_REFLECTION": "Agent failed to clean sponge before placing in bathtubbasin. Cleaning at faucet or sinkbasin is required when task specifies ’clean’ object."
-
[12]
TASK": "Put a clean dishsponge in cabinet
"TASK": "Put a clean dishsponge in cabinet.", "RETRIEVED_REFLECTION": "Agent must clean dishsponge at sinkbasin before placing in cabinet. Always read task description for object state requirements." INDEX 4 REASON: "Same failure pattern: agent must clean an object (cloth) before placing it at the target. Requires sinkbasin cleaning step before placement....
-
[13]
TASK": "Examine the book with the desklamp
"TASK": "Examine the book with the desklamp.", "RETRIEVED_REFLECTION": "Desklamp search should start at desk. Agent spent too many steps on shelves and drawers before checking the obvious location."
-
[14]
TASK": "Look at mug under the desklamp
"TASK": "Look at mug under the desklamp.", "SIMILARITY_REASON": "Same WRONG_TARGET_LOCATION: desklamp not found within step budget due to poor search ordering.",
-
[15]
TASK": "Examine the pen with the desklamp
"TASK": "Examine the pen with the desklamp.", "RETRIEVED_REFLECTION": "Always check the desk for desklamp first. If not on desk, check nearby shelves. Do not exhaust steps on low-probability locations." INDEX 17: REASON: "Identical tool-finding failure: agent must locate desklamp to examine an object. Same WRONG_TARGET_LOCATION pattern.", INDEX 20: REASON...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.