Towards Evaluating Data Priors for Tabular Foundation Models
Pith reviewed 2026-06-30 08:31 UTC · model grok-4.3
The pith
Different priors for tabular foundation models produce distinct patterns of downstream performance and ranking consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By re-implementing publicly available priors through a single unified interface and generating training tasks from each, the same model architecture trained under a fixed protocol yields models whose downstream behaviors differ: some priors produce stronger absolute performance on classification tasks while others produce more consistent relative rankings across datasets, and similarity between the prior's data distribution and the downstream data accounts for only part of these differences.
What carries the argument
A unified interface for re-implementing priors from tabular foundation models that preserves their original statistical properties, allowing isolated comparison via generated-task statistics and downstream performance.
If this is right
- Choice of prior can be used to target either higher peak accuracy or more stable dataset rankings in the resulting model.
- Downstream performance cannot be fully predicted from overlap between prior data and evaluation data alone.
- The same model architecture can exhibit different generalization profiles depending only on the prior used for pretraining.
- Evaluation of tabular foundation models should separate the contribution of the prior from the architecture and training protocol.
Where Pith is reading between the lines
- The comparison protocol could be applied to test whether new priors can be engineered to achieve both high absolute performance and high ranking consistency simultaneously.
- Practitioners might select among existing foundation models partly by inspecting which prior was used during their pretraining.
- Extending the method to measure how priors interact with different model sizes or optimization settings would reveal whether the observed differences persist under varied conditions.
Load-bearing premise
Public priors can be re-implemented through one interface without introducing artifacts or biases that would alter their statistical properties or confound the performance comparisons.
What would settle it
Retraining the identical architecture on tasks from the unified priors and observing identical distributions of downstream accuracy and ranking consistency across all priors would falsify the claim that priors produce distinct behaviors.
Figures


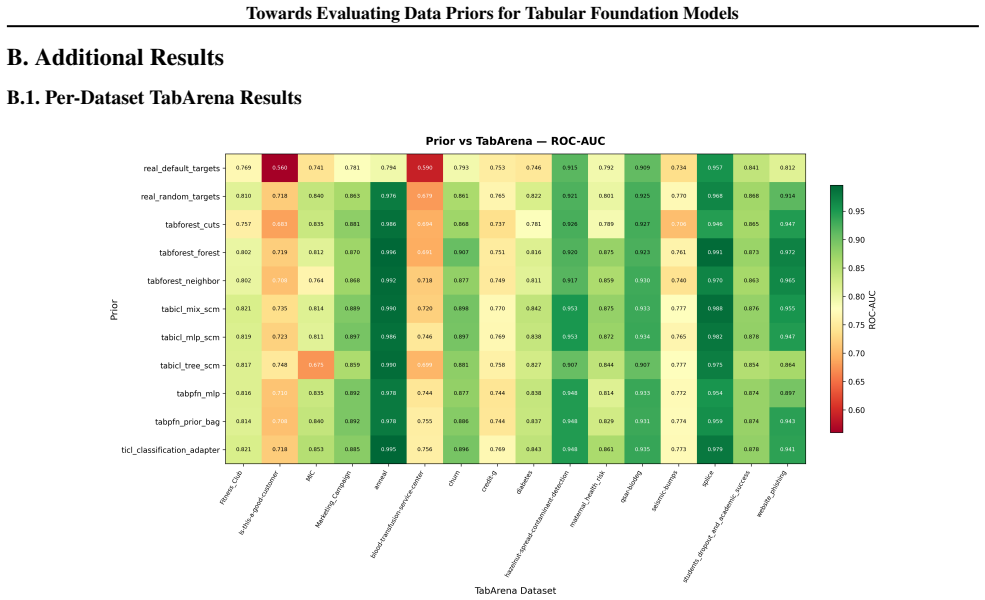
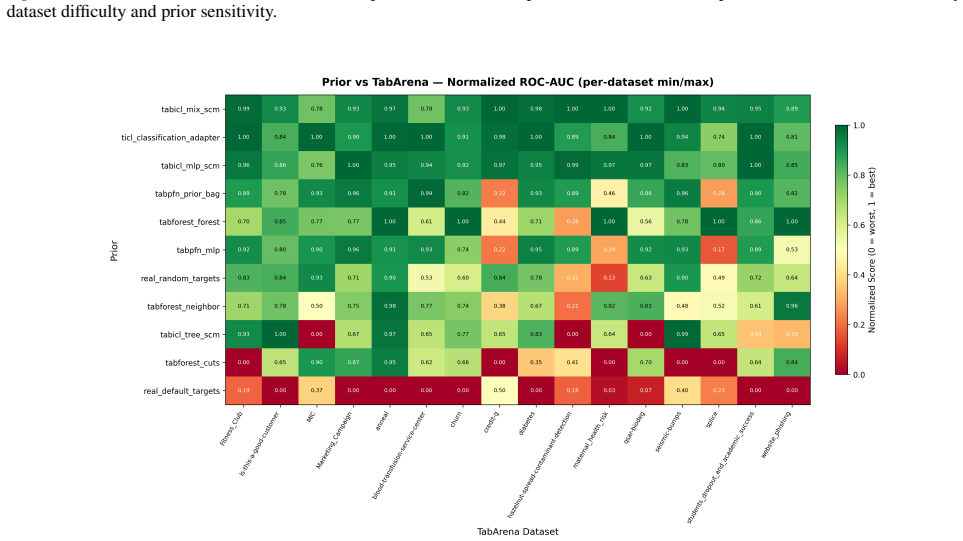
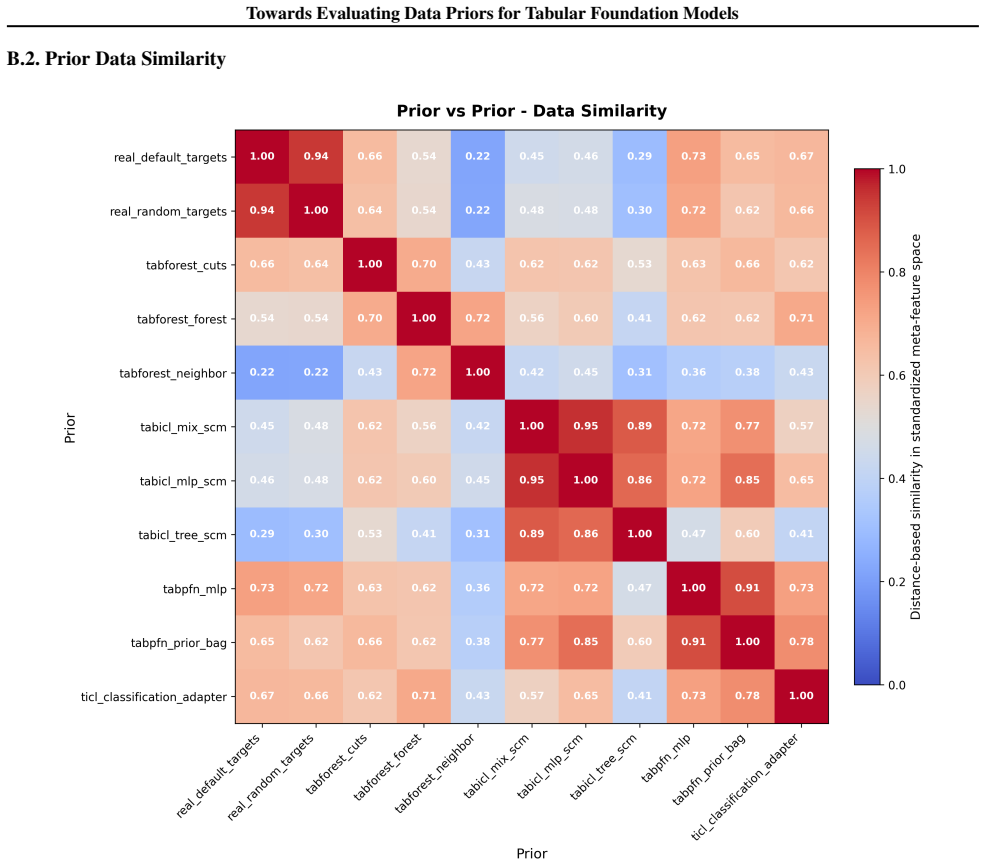
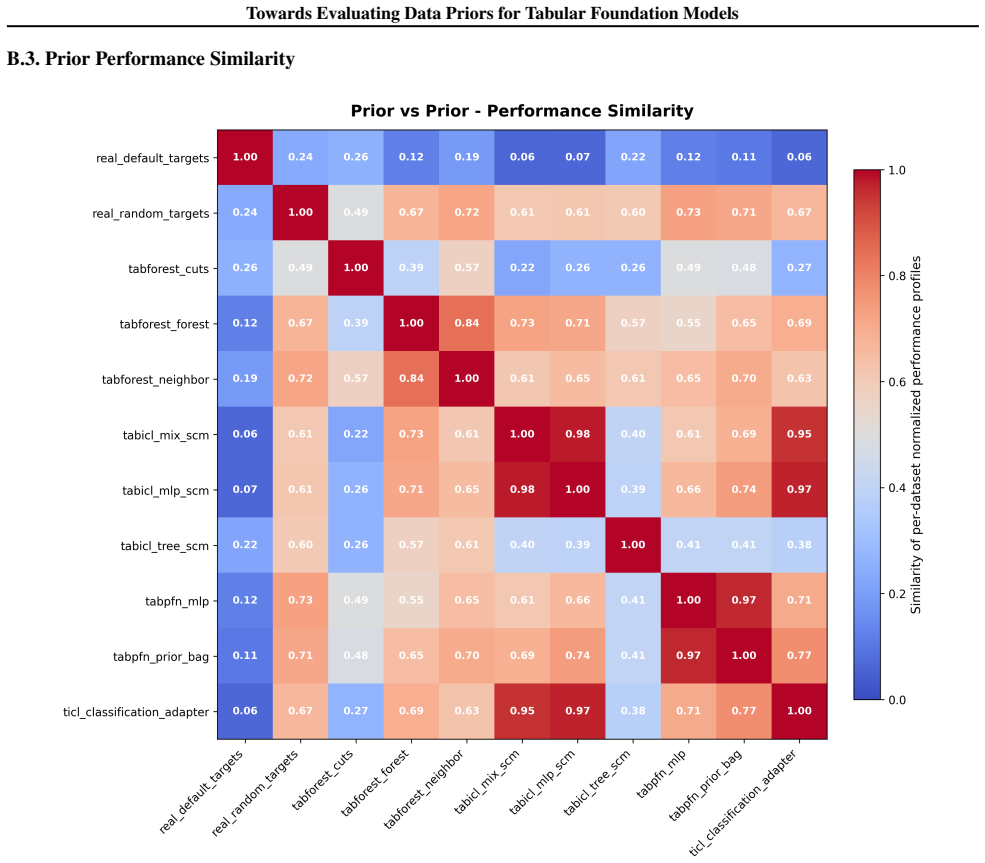
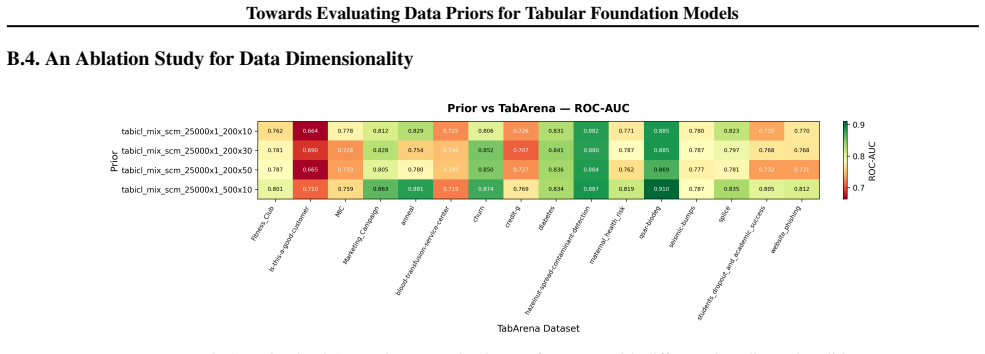
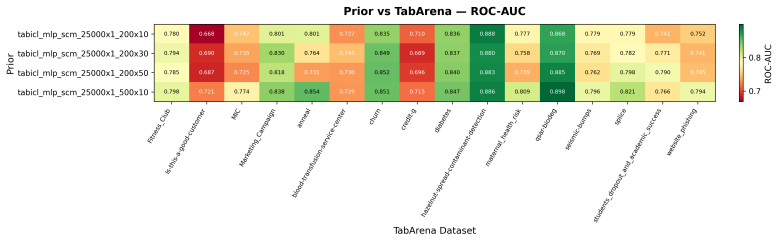
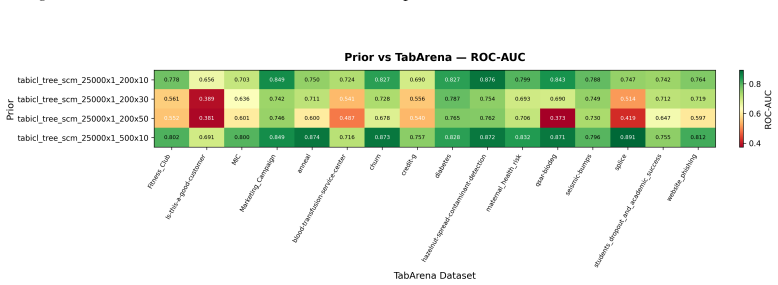
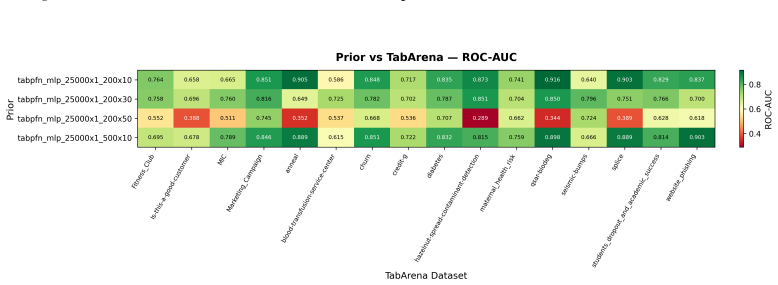
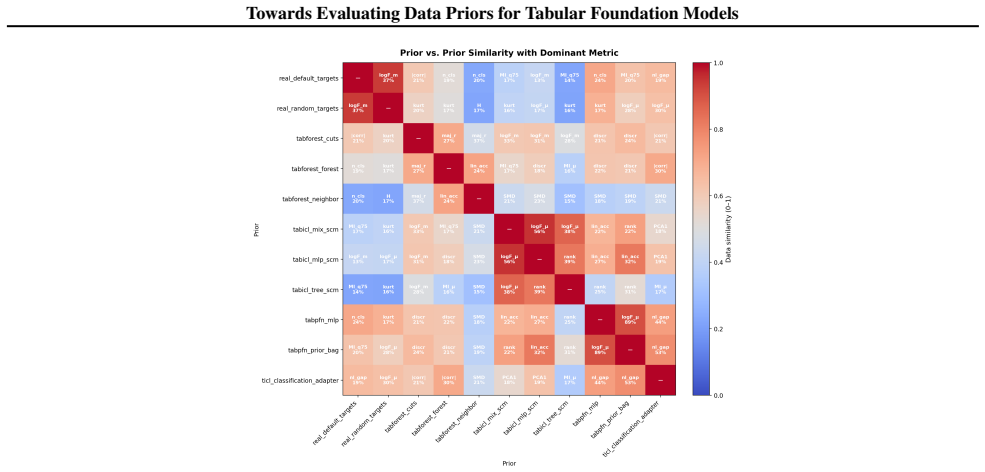
read the original abstract
Data-generating priors are a central component of tabular foundation models because they define the task distribution used during pretraining. However, priors are rarely evaluated as independent components, making it difficult to understand how much they affect downstream model behavior. This raises a methodological question: how can priors from different tabular foundation models be compared independently of the architectures and training protocols they were introduced with? To study this question, we implement a unified interface for publicly available priors from recent tabular foundation models and priors constructed from real datasets. We generate training tasks from each prior, train the same model architecture under a fixed training protocol, and evaluate the resulting models on shared downstream classification tasks. We compare priors through both generated-task statistics and downstream predictive performance. Our results show that different priors favor different downstream behaviors, with some achieving stronger absolute performance and others exhibiting more consistent relative rankings across datasets. We further find that data-level similarity only partially explains downstream behavior. Our code is available at https://github.com/automl/TFM-Playground/tree/prior-dev.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a unified interface for publicly available data-generating priors from tabular foundation models (plus real-data priors), generates pretraining tasks from each, trains an identical model architecture under a fixed protocol, and evaluates the resulting models on shared downstream classification tasks. Comparisons are made via generated-task statistics and downstream predictive performance. The central findings are that different priors induce distinct downstream behaviors (some with stronger absolute performance, others with more consistent relative rankings) and that data-level similarity only partially accounts for the observed differences.
Significance. If the re-implementations are shown to faithfully reproduce the original priors, the work supplies a needed methodological tool for isolating the contribution of the prior itself in tabular foundation models, separate from architecture and training choices. Public release of the code is a clear strength that supports reproducibility and extension by others.
major comments (2)
- [Abstract/Methods] Abstract and Methods: the claim that the unified interface preserves the original statistical properties of each prior is load-bearing for the central claim, yet no quantitative fidelity checks (matching of marginals, covariances, or higher-order sampling statistics) against the source implementations are reported; without them, downstream differences could arise from re-implementation artifacts rather than the intended priors.
- [Results] Results: downstream performance gaps and consistency rankings are presented without any mention of statistical significance tests or multiple-testing correction, so it is unclear whether the reported patterns (absolute performance differences and relative ranking stability) exceed what would be expected by chance.
minor comments (2)
- [Abstract] The GitHub repository link is provided; this is helpful, but the manuscript would benefit from a brief description in the text of which specific priors were re-implemented and any hyper-parameter choices made in the unified interface.
- Notation for the generated-task statistics (e.g., how similarity is quantified) could be introduced earlier and used consistently when discussing partial explanatory power of data-level similarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below and will revise the manuscript accordingly to strengthen the claims with additional validation and statistical analysis.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract and Methods: the claim that the unified interface preserves the original statistical properties of each prior is load-bearing for the central claim, yet no quantitative fidelity checks (matching of marginals, covariances, or higher-order sampling statistics) against the source implementations are reported; without them, downstream differences could arise from re-implementation artifacts rather than the intended priors.
Authors: We agree that explicit quantitative fidelity checks are necessary to support the claim that the unified interface faithfully reproduces the original priors. The current manuscript relies on the design of the interface to match the public source code but does not report direct statistical comparisons. In the revised version we will add tables and figures comparing marginal distributions, pairwise covariances, and selected higher-order statistics (e.g., skewness, kurtosis, and selected conditional moments) between the original implementations and our unified versions across multiple sampled datasets. These checks will be placed in the Methods section and referenced in the Abstract. revision: yes
-
Referee: [Results] Results: downstream performance gaps and consistency rankings are presented without any mention of statistical significance tests or multiple-testing correction, so it is unclear whether the reported patterns (absolute performance differences and relative ranking stability) exceed what would be expected by chance.
Authors: We acknowledge that the Results section currently presents absolute performance differences and ranking consistencies without formal statistical testing. In the revision we will add paired statistical tests (Wilcoxon signed-rank or paired t-tests, as appropriate) for the reported performance gaps, together with a multiple-testing correction (e.g., Bonferroni or FDR) across the set of downstream tasks. We will also report p-values and effect sizes for the consistency-of-ranking metric. These additions will be integrated into the existing results tables and figures. revision: yes
Circularity Check
No circularity: empirical comparison without self-referential derivations
full rationale
This is an empirical study that re-implements priors via a unified interface, generates tasks from each, trains identical models under fixed protocols, and measures downstream performance plus task statistics. No equations, fitted parameters, or predictions are defined in terms of themselves. The central claim (different priors produce distinct behaviors) rests on experimental outcomes rather than reducing to inputs by construction, self-citation chains, or ansatzes smuggled from prior work. No load-bearing uniqueness theorems or renamings of known results appear. The work is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single model architecture and training protocol can be applied uniformly across priors without introducing interactions that favor one prior over another.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
2023 , eprint=
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second , author=. 2023 , eprint=
2023
-
[10]
2025 , eprint=
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Generalization Can Emerge in Tabular Foundation Models From a Single Table , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
Mitra: Mixed Synthetic Priors for Enhancing Tabular Foundation Models , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
Fine-tuned In-Context Learning Transformers are Excellent Tabular Data Classifiers , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
nanoTabPFN: A Lightweight and Educational Reimplementation of TabPFN , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
MotherNet: Fast Training and Inference via Hyper-Network Transformers , author=. 2025 , eprint=
2025
-
[16]
2024 , eprint=
The Road Less Scheduled , author=. 2024 , eprint=
2024
-
[17]
2026 , eprint=
TabDPT: Scaling Tabular Foundation Models on Real Data , author=. 2026 , eprint=
2026
-
[18]
2025 , eprint=
TabArena: A Living Benchmark for Machine Learning on Tabular Data , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
Real-TabPFN: Improving Tabular Foundation Models via Continued Pre-training With Real-World Data , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Universal Embeddings of Tabular Data , author=. 2025 , eprint=
2025
-
[21]
2026 , url=
TFM-Playground: A Playground for Tabular Foundation Models , author=. 2026 , url=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.