ARMOR-MAD: Adaptive Routing for Heterogeneous Multi-Agent Debate in Large Language Model Reasoning
Pith reviewed 2026-06-27 07:04 UTC · model grok-4.3
The pith
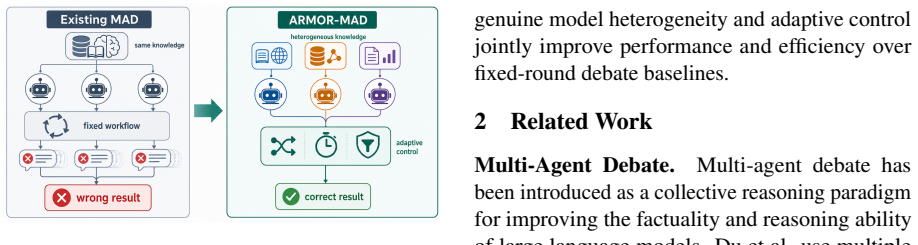
ARMOR-MAD uses agreement-based controls to make heterogeneous multi-agent debate more accurate than fixed-round versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
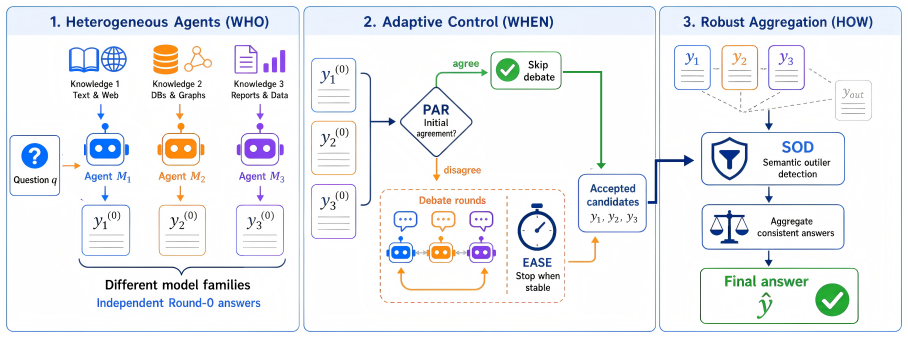
ARMOR-MAD combines Pre-debate Agreement Routing (PAR), Early Agreement Stopping Evaluator (EASE), and Semantic Outlier Detection (SOD) to treat debate as conditional computation, consistently improving over fixed-round heterogeneous debate to reach 65.5% on MATH Level 5, 96.5% on GSM8K, 90.0% on MMLU, and 81.5% on MMLU-Pro.
What carries the argument
The three control components (PAR, EASE, SOD) that decide whether debate is needed, when to stop it, and how to weight final answers based on semantic agreement and outliers.
If this is right
- Genuine model heterogeneity combined with agreement-based control improves accuracy over fixed-round debate.
- Skipping debate rounds when initial answers already agree saves computation.
- Down-weighting semantic outliers during final aggregation reduces the effect of abnormal answers.
- Both heterogeneity and agreement detection contribute to making multi-agent debate more accurate and efficient.
Where Pith is reading between the lines
- The routing logic could extend to other multi-agent LLM tasks to limit total token usage.
- Testing the same controls on tasks with stronger model correlation might expose where early stopping harms performance.
- The results imply that future systems could dynamically select which agents participate rather than using a fixed pool.
Load-bearing premise
The thresholds and similarity measures used in the three control components reliably detect agreement and outliers without introducing new failure modes.
What would settle it
Measuring whether accuracy on one of the benchmarks drops below the fixed-round heterogeneous baseline when the model pool has highly correlated errors.
Figures
read the original abstract
Multi-agent debate (MAD) can improve large language model reasoning, but fixed debate pipelines often waste computation and can amplify correlated errors among similar agents. We propose ARMOR-MAD, a training-free heterogeneous MAD framework that treats debate as conditional computation. ARMOR-MAD combines three components: Pre-debate Agreement Routing (PAR) decides whether independently generated Round-0 answers require debate; Early Agreement Stopping Evaluator (EASE) stops debate after convergence; and Semantic Outlier Detection (SOD) down-weights abnormal final answers during aggregation. Across MATH Level 5, GSM8K, MMLU, and MMLU-Pro, ARMOR-MAD consistently improves over fixed-round heterogeneous debate with the same model pool, reaching 65.5\%, 96.5\%, 90.0\%, and 81.5\% accuracy, respectively. The results suggest that genuine model heterogeneity and agreement-based control are both important for making MAD more accurate and efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ARMOR-MAD, a training-free heterogeneous multi-agent debate framework for LLM reasoning. It introduces three adaptive components—Pre-debate Agreement Routing (PAR) to decide whether Round-0 answers require debate, Early Agreement Stopping Evaluator (EASE) to halt after convergence, and Semantic Outlier Detection (SOD) to down-weight abnormal answers—claiming consistent accuracy gains over fixed-round heterogeneous debate on MATH Level 5 (65.5%), GSM8K (96.5%), MMLU (90.0%), and MMLU-Pro (81.5%).
Significance. If the adaptive controls are shown to be robust without hidden tuning, the work would demonstrate that agreement-based conditional computation can improve both accuracy and efficiency in multi-agent LLM systems while leveraging model heterogeneity, offering a practical alternative to fixed pipelines.
major comments (2)
- [Abstract] Abstract: reported accuracies lack error bars, standard deviations, or details on the model pool and baseline implementations (PAR/EASE/SOD), preventing assessment of whether the deltas reflect genuine improvements or post-hoc selection.
- [Abstract / §3] Abstract / §3 (components): no explicit threshold values, validation-set procedure, or sensitivity analysis is provided for the agreement/outlier detection mechanisms in PAR, EASE, and SOD; this is load-bearing because the headline claim requires these controls to detect agreement reliably without introducing new failure modes or benchmark-specific tuning.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will make revisions to improve transparency regarding error bars, implementation details, and the adaptive thresholds.
read point-by-point responses
-
Referee: [Abstract] Abstract: reported accuracies lack error bars, standard deviations, or details on the model pool and baseline implementations (PAR/EASE/SOD), preventing assessment of whether the deltas reflect genuine improvements or post-hoc selection.
Authors: We agree that the reported point estimates would be strengthened by error bars and standard deviations. In the revision we will add standard deviations computed over multiple independent runs for each benchmark accuracy. We will also expand the abstract and relevant sections to specify the model pool (listing the exact LLMs) and provide implementation details for the PAR, EASE, and SOD baselines so that the improvements can be properly evaluated. revision: yes
-
Referee: [Abstract / §3] Abstract / §3 (components): no explicit threshold values, validation-set procedure, or sensitivity analysis is provided for the agreement/outlier detection mechanisms in PAR, EASE, and SOD; this is load-bearing because the headline claim requires these controls to detect agreement reliably without introducing new failure modes or benchmark-specific tuning.
Authors: We acknowledge the absence of explicit threshold values and sensitivity analysis in the current text. The revised manuscript will state the precise thresholds employed (e.g., agreement threshold for PAR/EASE and semantic similarity cutoff for SOD) and describe how they were selected on a small held-out validation portion without per-benchmark retuning. We will also add a sensitivity study across a range of threshold values to confirm that performance gains remain stable and that the mechanisms do not introduce benchmark-specific artifacts or new failure modes. revision: yes
Circularity Check
No circularity: empirical framework with external benchmarks
full rationale
The paper introduces a training-free adaptive routing framework (PAR, EASE, SOD) whose performance claims rest on direct accuracy measurements across four standard benchmarks (MATH Level 5, GSM8K, MMLU, MMLU-Pro). No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text. The reported gains are therefore not reductions of the method to its own inputs by construction; they remain falsifiable external evaluations. Threshold choice is an unvalidated implementation detail rather than a definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International conference on learning representations , volume=
Large language models cannot self-correct reasoning yet , author=. International conference on learning representations , volume=
-
[2]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[3]
arXiv preprint arXiv:2207.05221 , year=
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[4]
IEEE Transactions on Computational Social Systems , year=
Knowledge-augmented interpretable network for zero-shot stance detection on social media , author=. IEEE Transactions on Computational Social Systems , year=
-
[5]
Information Fusion , volume=
Logic Augmented Multi-Decision Fusion framework for stance detection on social media , author=. Information Fusion , volume=. 2025 , publisher=
2025
-
[6]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[7]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Encouraging divergent thinking in large language models through multi-agent debate , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[8]
ChatEval: Towards Better
Chi-Min Chan and Weize Chen and Yusheng Su and Jianxuan Yu and Wei Xue and Shanghang Zhang and Jie Fu and Zhiyuan Liu , booktitle=. ChatEval: Towards Better. 2024 , url=
2024
-
[9]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Reconcile: Round-table conference improves reasoning via consensus among diverse llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[11]
International Conference on Learning Representations , volume=
Mixture-of-agents enhances large language model capabilities , author=. International Conference on Learning Representations , volume=
-
[12]
Journal of King Saud University Computer and Information Sciences , volume=
Adaptive heterogeneous multi-agent debate for enhanced educational and factual reasoning in large language models , author=. Journal of King Saud University Computer and Information Sciences , volume=. 2025 , publisher=
2025
-
[13]
M as R outer: Learning to Route LLM s for Multi-Agent Systems
Yue, Yanwei and Zhang, Guibin and Liu, Boyang and Wan, Guancheng and Wang, Kun and Cheng, Dawei and Qi, Yiyan. M as R outer: Learning to Route LLM s for Multi-Agent Systems. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[14]
Advances in Neural Information Processing Systems , volume=
Debate or vote: Which yields better decisions in multi-agent large language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
CONSENSAGENT: Towards efficient and effective consensus in multi-agent LLM interactions through sycophancy mitigation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[16]
Zijun Liu and Yanzhe Zhang and Peng Li and Yang Liu and Diyi Yang , year=. Dynamic
-
[17]
Rethinking the Bounds of
Wang, Qineng and Wang, Zihao and Su, Ying and Tong, Hanghang and Song, Yangqiu , booktitle=. Rethinking the Bounds of
-
[18]
Estornell, Andrew and Liu, Yang , booktitle=. Multi-
-
[19]
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , journal=
-
[20]
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and others , booktitle=
-
[21]
The Twelfth International Conference on Learning Representations , year=
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , author=. The Twelfth International Conference on Learning Representations , year=
-
[22]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[23]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[24]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[25]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.