Interpreting Style Representations via Style-Eliciting Prompts
Pith reviewed 2026-06-28 01:15 UTC · model grok-4.3
The pith
Style representations can be interpreted by decoding them back into the natural language prompts that elicit matching text from an LLM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By generating text with an LLM conditioned on 1,010 curated style features across 26 categories, the authors train a decoder that maps the style representation of that text back to the conditioning prompt. The recovered prompts then serve as an interface for describing the style of generated or human text and for steering LLMs to produce new text in the same style, yielding higher performance on description and imitation tasks than baselines that prompt LLMs directly with the target text.
What carries the argument
The style-eliciting prompt: a natural language instruction that steers an LLM to generate text reflecting a chosen stylistic attribute, serving as the explicit, recoverable link between a style representation and controllable output.
If this is right
- Recovered prompts allow accurate reconstruction of the original stylistic attributes for both generated and human text.
- Text generated from the recovered prompts matches the style of the source text more closely than text from direct prompting baselines.
- The decoder enables steering an LLM to imitate the style of arbitrary human-written examples using the recovered prompts.
- The performance gains hold across the 26 stylistic categories used to build the feature set.
Where Pith is reading between the lines
- The same decoder could support style editing by letting users modify parts of a recovered prompt and regenerate text.
- Comparing recovered prompts across texts might offer a new route to measuring stylistic similarity for authorship tasks.
- The method could be extended to combine multiple style features in one prompt for more nuanced control over generated writing.
Load-bearing premise
LLM-generated text conditioned on the curated features produces style representations that encode those features faithfully enough for a decoder trained on them to generalize to human-written text without inheriting LLM-specific biases.
What would settle it
A test in which the trained decoder, when applied to style representations of held-out human-written texts, produces prompts that yield lower accuracy on style description or lower style-matching scores on imitation tasks than simply prompting the LLM directly with the human text.
Figures
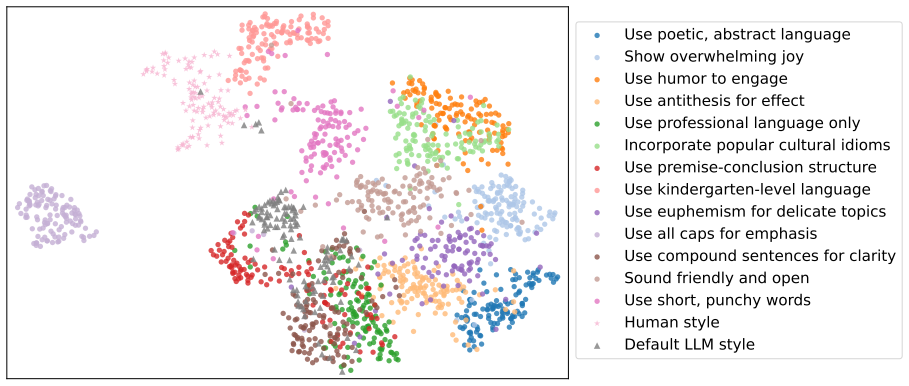

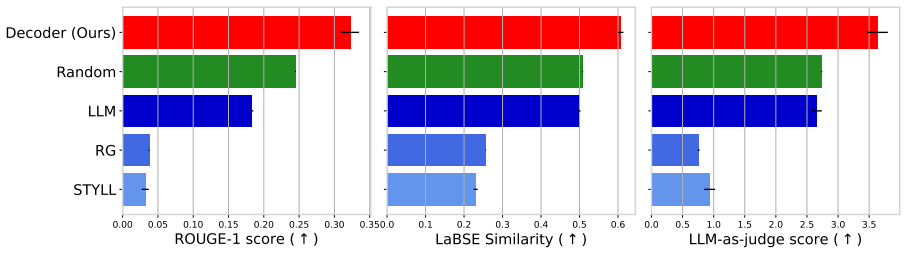
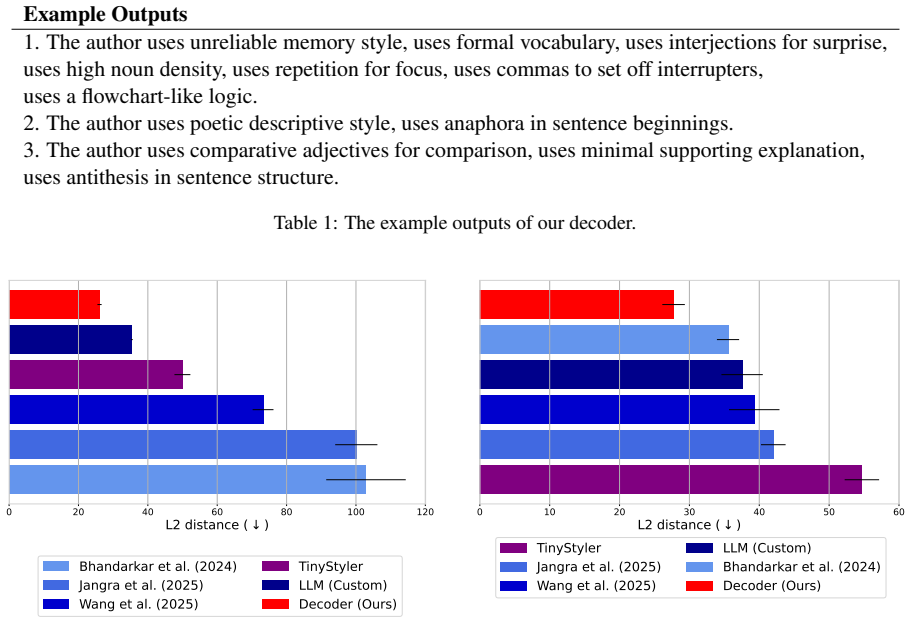
read the original abstract
Style representation learning is a powerful tool for authorship analysis and modeling writing style, yet the latent nature of learned representations makes them difficult to interpret. Recent work has attempted to explain these representations by generating natural language descriptions with large language models (LLMs) conditioned on input text. However, such descriptions are often prone to the LLM's biases and hallucinations, and they lack an explicit objective and practical utility. In this work, we propose a novel framework for interpreting style representations through style-eliciting prompts: natural language instructions designed to steer LLMs to generate text that reflects specific stylistic attributes. We curate 1,010 distinct style features spanning 26 stylistic categories and construct a dataset by prompting an LLM to generate text conditioned on these features. Using this data, we train a decoder to generate a style prompt from the style representation of the generated text. We evaluate our approach on three tasks: (1) recovering original style prompts from generated text, (2) generating text in the same style using the recovered prompts, and (3) steering LLM outputs to match the style of human-written texts. Experiments demonstrate that our method consistently outperforms strong baselines that directly prompt LLMs with target text, achieving superior performance in both style description and style imitation. These results highlight that style-eliciting prompts can provide a practical and interpretable interface to stylistic information encoded in style representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for interpreting latent style representations by curating 1,010 style features across 26 categories, generating a synthetic dataset via LLM prompting conditioned on these features, training a decoder to map style representations of the generated text back to natural-language style-eliciting prompts, and then using those prompts to steer LLMs. The method is evaluated on three tasks—recovering the original prompts from generated text, using recovered prompts for style imitation, and steering LLM output to match the style of human-written texts—with the claim that it outperforms strong baselines that directly prompt LLMs with target text.
Significance. If the empirical results hold after addressing the noted gaps, the work would supply a practical, prompt-based interface for extracting and applying stylistic information from representations, which could benefit authorship analysis, style transfer, and controlled generation. The explicit curation of a large feature set and the attempt to evaluate on human-written text (rather than purely synthetic data) are positive elements that move beyond purely LLM-internal descriptions.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'consistently outperforms strong baselines' on the three tasks is stated without any quantitative results, performance metrics, baseline details, dataset sizes, or error analysis, leaving the primary empirical assertion unsupported by visible evidence.
- [Task (3) evaluation] Task (3) evaluation: the decoder is trained exclusively on LLM-generated text conditioned on the 1,010 features, yet is applied to recover prompts for human-written texts; no details are supplied on how style representations are obtained from human text, whether any human-only validation set was used, or controls to distinguish genuine cross-domain style recovery from the decoder simply inverting LLM-specific generation artifacts.
minor comments (2)
- [Abstract] Abstract: the description of baselines and evaluation metrics should be expanded to allow readers to assess the strength of the outperformance claim.
- The manuscript should report dataset statistics, including the number of examples per style feature and any splits used for training the decoder.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the work's potential impact. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'consistently outperforms strong baselines' on the three tasks is stated without any quantitative results, performance metrics, baseline details, dataset sizes, or error analysis, leaving the primary empirical assertion unsupported by visible evidence.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the performance claims. In the revised manuscript we will add specific metrics (e.g., accuracy or similarity scores on each of the three tasks), baseline descriptions, and dataset sizes while keeping the abstract concise. revision: yes
-
Referee: [Task (3) evaluation] Task (3) evaluation: the decoder is trained exclusively on LLM-generated text conditioned on the 1,010 features, yet is applied to recover prompts for human-written texts; no details are supplied on how style representations are obtained from human text, whether any human-only validation set was used, or controls to distinguish genuine cross-domain style recovery from the decoder simply inverting LLM-specific generation artifacts.
Authors: Style representations for human-written texts are obtained with the identical encoder used on the synthetic data. A held-out set of human texts was used for validation, and all baselines (including direct LLM prompting) operate on the same representations to isolate the decoder's contribution. We will expand the manuscript with explicit details on the human-text pipeline, the human-only validation split, and additional controls for potential LLM-generation artifacts. revision: partial
Circularity Check
No circularity in derivation; empirical pipeline uses external human-text evaluation
full rationale
The paper presents an empirical method: curate 1,010 style features, generate LLM text conditioned on them, train a decoder to map style representations back to prompts, then evaluate on three tasks including steering on human-written texts. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described pipeline. Task (3) supplies independent human-text grounding outside the LLM-generated training distribution, so the central claim does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Curated set of 1010 style features
axioms (1)
- domain assumption LLMs can be steered via prompts to generate text that reflects specific stylistic attributes
Reference graph
Works this paper leans on
-
[1]
Newspaper Research Journal , volume =
Jean Kelly and Jan Knight and Lee Anne Peck and Guy Reel , title =. Newspaper Research Journal , volume =. 2003 , doi =
2003
-
[2]
CLEF (Working Notes) , year =
Overview of the 2019 Author Profiling Task at PAN , author =. CLEF (Working Notes) , year =
2019
-
[3]
CEUR workshop proceedings , volume=
Overview of the authorship verification task at PAN 2022 , author=. CEUR workshop proceedings , volume=. 2022 , organization=
2022
-
[4]
European Conference on Information Retrieval , pages=
Overview of pan 2024: multi-author writing style analysis, multilingual text detoxification, oppositional thinking analysis, and generative ai authorship verification , author=. European Conference on Information Retrieval , pages=. 2024 , organization=
2024
-
[5]
Journal of Consumer Psychology , volume =
Boghrati, Reihane and Berger, Jonah and Packard, Grant , title =. Journal of Consumer Psychology , volume =. doi:https://doi.org/10.1002/jcpy.1346 , url =. https://myscp.onlinelibrary.wiley.com/doi/pdf/10.1002/jcpy.1346 , abstract =
-
[6]
A Recipe for Arbitrary Text Style Transfer with Large Language Models
Reif, Emily and Ippolito, Daphne and Yuan, Ann and Coenen, Andy and Callison-Burch, Chris and Wei, Jason. A Recipe for Arbitrary Text Style Transfer with Large Language Models. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.94
-
[7]
Stylized Text Generation: Approaches and Applications
Mou, Lili and Vechtomova, Olga. Stylized Text Generation: Approaches and Applications. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts. 2020. doi:10.18653/v1/2020.acl-tutorials.5
-
[8]
Mukherjee, Sourabrata and Ojha, Atul Kr. and Dusek, Ondrej. Are Large Language Models Actually Good at Text Style Transfer?. Proceedings of the 17th International Natural Language Generation Conference. 2024. doi:10.18653/v1/2024.inlg-main.42
-
[9]
The Reversal Curse:
Lukas Berglund and Meg Tong and Maximilian Kaufmann and Mikita Balesni and Asa Cooper Stickland and Tomasz Korbak and Owain Evans , booktitle=. The Reversal Curse:. 2024 , url=
2024
-
[10]
Solan , journal =
Peter Tiersma and Lawrence M. Solan , journal =. The Linguist on the Witness Stand: Forensic Linguistics in American Courts , urldate =
-
[11]
2019 , publisher=
Register, genre, and style , author=. 2019 , publisher=
2019
-
[12]
Red Teaming Language Models with Language Models
Perez, Ethan and Huang, Saffron and Song, Francis and Cai, Trevor and Ring, Roman and Aslanides, John and Glaese, Amelia and McAleese, Nat and Irving, Geoffrey. Red Teaming Language Models with Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.225
-
[13]
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , booktitle=. Auto. 2024 , url=
2024
-
[14]
The Twelfth International Conference on Learning Representations , year=
Curiosity-driven Red-teaming for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
Forty-second International Conference on Machine Learning , year=
Eliciting Language Model Behaviors with Investigator Agents , author=. Forty-second International Conference on Machine Learning , year=
-
[16]
Who Wrote it and Why? Prompting Large-Language Models for Authorship Verification
Hung, Chia-Yu and Hu, Zhiqiang and Hu, Yujia and Lee, Roy. Who Wrote it and Why? Prompting Large-Language Models for Authorship Verification. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.937
-
[17]
Can Large Language Models Identify Authorship?
Huang, Baixiang and Chen, Canyu and Shu, Kai. Can Large Language Models Identify Authorship?. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.26
-
[18]
Instruct
Yujia Hu and Zhiqiang Hu and Chun Wei Seah and Roy Ka-Wei Lee , booktitle=. Instruct. 2024 , url=
2024
-
[19]
CAVE : Controllable Authorship Verification Explanations
Ramnath, Sahana and Pandey, Kartik and Boschee, Elizabeth and Ren, Xiang. CAVE : Controllable Authorship Verification Explanations. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.451
-
[20]
Learning Interpretable Style Embeddings via Prompting LLM s
Patel, Ajay and Rao, Delip and Kothary, Ansh and McKeown, Kathleen and Callison-Burch, Chris. Learning Interpretable Style Embeddings via Prompting LLM s. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.1020
-
[21]
Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution
Alshomary, Milad and Ri, Narutatsu and Apidianaki, Marianna and Patel, Ajay and Muresan, Smaranda and McKeown, Kathleen. Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[22]
Zhu, Jian and Jurgens, David. Idiosyncratic but not Arbitrary: Learning Idiolects in Online Registers Reveals Distinctive yet Consistent Individual Styles. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.25
-
[23]
Does It Capture STEL ? A Modular, Similarity-based Linguistic Style Evaluation Framework
Wegmann, Anna and Nguyen, Dong. Does It Capture STEL ? A Modular, Similarity-based Linguistic Style Evaluation Framework. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.569
-
[24]
and Miano, Olivia Elizabeth and Ordonez, Juanita and Chen, Barry Y
Rivera-Soto, Rafael A. and Miano, Olivia Elizabeth and Ordonez, Juanita and Chen, Barry Y. and Khan, Aleem and Bishop, Marcus and Andrews, Nicholas. Learning Universal Authorship Representations. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.70
-
[25]
Same Author or Just Same Topic? Towards Content-Independent Style Representations
Wegmann, Anna and Schraagen, Marijn and Nguyen, Dong. Same Author or Just Same Topic? Towards Content-Independent Style Representations. Proceedings of the 7th Workshop on Representation Learning for NLP. 2022. doi:10.18653/v1/2022.repl4nlp-1.26
-
[26]
Transactions of the Association for Computational Linguistics , volume =
Wang, Andrew and Aggazzotti, Cristina and Kotula, Rebecca and Soto, Rafael Rivera and Bishop, Marcus and Andrews, Nicholas , title =. Transactions of the Association for Computational Linguistics , volume =. 2023 , month =. doi:10.1162/tacl_a_00610 , url =
-
[27]
2024 , eprint=
Separating Style from Substance: Enhancing Cross-Genre Authorship Attribution through Data Selection and Presentation , author=. 2024 , eprint=
2024
-
[28]
RAG s to Style: Personalizing LLM s with Style Embeddings
Neelakanteswara, Abhiman and Chaudhari, Shreyas and Zamani, Hamed. RAG s to Style: Personalizing LLM s with Style Embeddings. Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSONALIZE 2024). 2024
2024
-
[29]
The Twelfth International Conference on Learning Representations , year=
Few-Shot Detection of Machine-Generated Text using Style Representations , author=. The Twelfth International Conference on Learning Representations , year=
-
[30]
Horvitz, Zachary and Patel, Ajay and Callison-Burch, Chris and Yu, Zhou and McKeown, Kathleen , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 202...
-
[31]
T iny S tyler: Efficient Few-Shot Text Style Transfer with Authorship Embeddings
Horvitz, Zachary and Patel, Ajay and Singh, Kanishk and Callison-Burch, Chris and McKeown, Kathleen and Yu, Zhou. T iny S tyler: Efficient Few-Shot Text Style Transfer with Authorship Embeddings. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.781
-
[32]
, author=
Authorship Verification: A Review of Recent Advances. , author=. Research in Computing Science , volume=
-
[33]
arXiv preprint arXiv:2209.06869 , year=
On the state of the art in authorship attribution and authorship verification , author=. arXiv preprint arXiv:2209.06869 , year=
-
[34]
Deep Learning for Text Style Transfer: A Survey
Jin, Di and Jin, Zhijing and Hu, Zhiting and Vechtomova, Olga and Mihalcea, Rada. Deep Learning for Text Style Transfer: A Survey. Computational Linguistics. 2022. doi:10.1162/coli_a_00426
-
[35]
Hu, Zhiqiang and Lee, Roy Ka-Wei and Aggarwal, Charu C. and Zhang, Aston , title =. SIGKDD Explor. Newsl. , month = jun, pages =. 2022 , issue_date =. doi:10.1145/3544903.3544906 , abstract =
-
[36]
2024 , eprint=
A Survey of Text Style Transfer: Applications and Ethical Implications , author=. 2024 , eprint=
2024
-
[37]
Proceedings of the 34th International Conference on Machine Learning , pages =
Toward Controlled Generation of Text , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[38]
Style Transfer from Non-Parallel Text by Cross-Alignment , url =
Shen, Tianxiao and Lei, Tao and Barzilay, Regina and Jaakkola, Tommi , booktitle =. Style Transfer from Non-Parallel Text by Cross-Alignment , url =
-
[39]
Style Transfer Through Back-Translation
Prabhumoye, Shrimai and Tsvetkov, Yulia and Salakhutdinov, Ruslan and Black, Alan W. Style Transfer Through Back-Translation. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1080
-
[40]
Proceedings of the 37th International Conference on Machine Learning , pages =
On Variational Learning of Controllable Representations for Text without Supervision , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[41]
Proceedings of the 37th International Conference on Machine Learning , pages =
Educating Text Autoencoders: Latent Representation Guidance via Denoising , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[42]
2024 , eprint=
Low-Resource Authorship Style Transfer: Can Non-Famous Authors Be Imitated? , author=. 2024 , eprint=
2024
-
[43]
2025 , eprint=
Steering Large Language Models with Register Analysis for Arbitrary Style Transfer , author=. 2025 , eprint=
2025
-
[44]
Emulating Author Style: A Feasibility Study of Prompt-enabled Text Stylization with Off-the-Shelf LLM s
Bhandarkar, Avanti and Wilson, Ronald and Swarup, Anushka and Woodard, Damon. Emulating Author Style: A Feasibility Study of Prompt-enabled Text Stylization with Off-the-Shelf LLM s. Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSONALIZE 2024). 2024
2024
-
[45]
Wang, Zhengxiang and Tripto, Nafis Irtiza and Park, Solha and Li, Zhenzhen and Zhou, Jiawei. Catch Me If You Can? Not Yet: LLM s Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.532
-
[46]
2025 , eprint=
Evaluating Style-Personalized Text Generation: Challenges and Directions , author=. 2025 , eprint=
2025
-
[47]
Reformulating Unsupervised Style Transfer as Paraphrase Generation
Krishna, Kalpesh and Wieting, John and Iyyer, Mohit. Reformulating Unsupervised Style Transfer as Paraphrase Generation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.55
-
[48]
Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[49]
Fisher, Jillian and Hallinan, Skyler and Lu, Ximing and Gordon, Mitchell L and Harchaoui, Zaid and Choi, Yejin. S tyle R emix: Interpretable Authorship Obfuscation via Distillation and Perturbation of Style Elements. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.241
-
[50]
S tyle D istance: Stronger Content-Independent Style Embeddings with Synthetic Parallel Examples
Patel, Ajay and Zhu, Jiacheng and Qiu, Justin and Horvitz, Zachary and Apidianaki, Marianna and McKeown, Kathleen and Callison-Burch, Chris. S tyle D istance: Stronger Content-Independent Style Embeddings with Synthetic Parallel Examples. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
-
[51]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Li, Xiang Lisa and Liang, Percy. Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.353
-
[52]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, Brian and Al-Rfou, Rami and Constant, Noah. The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.243
-
[53]
Tsimpoukelli, Maria and Menick, Jacob L and Cabi, Serkan and Eslami, S. M. Ali and Vinyals, Oriol and Hill, Felix , booktitle =. Multimodal Few-Shot Learning with Frozen Language Models , url =
-
[54]
2023 , eprint=
Gaussian Error Linear Units (GELUs) , author=. 2023 , eprint=
2023
-
[55]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[56]
Shengding Hu and Yuge Tu and Xu Han and Ganqu Cui and Chaoqun He and Weilin Zhao and Xiang Long and Zhi Zheng and Yewei Fang and Yuxiang Huang and Xinrong Zhang and Zhen Leng Thai and Chongyi Wang and Yuan Yao and Chenyang Zhao and Jie Zhou and Jie Cai and Zhongwu Zhai and Ning Ding and Chao Jia and Guoyang Zeng and dahai li and Zhiyuan Liu and Maosong Su...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.