Bayesian Adaptation Gym: A Benchmark for the Bayesian Low-Rank Adaptation of Multi-Modal Language Models
Pith reviewed 2026-06-26 12:05 UTC · model grok-4.3
The pith
Bayesian Adaptation Gym supplies the first standardized benchmark for Bayesian low-rank adaptation of multi-modal language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
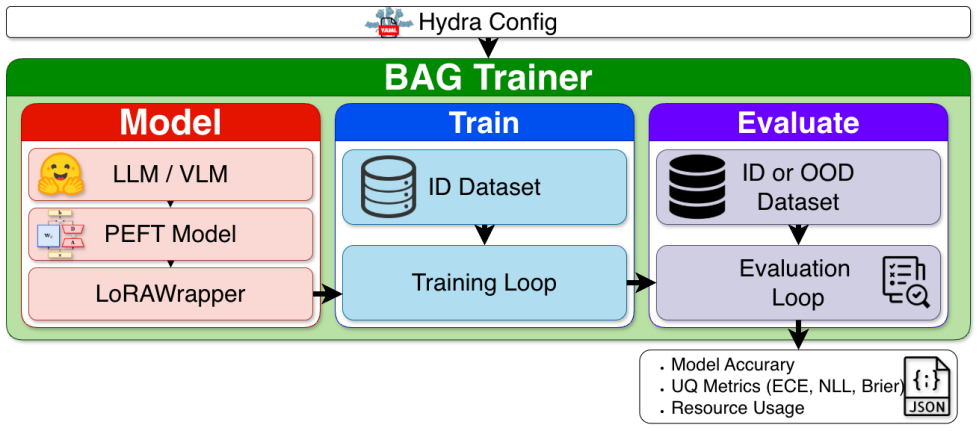
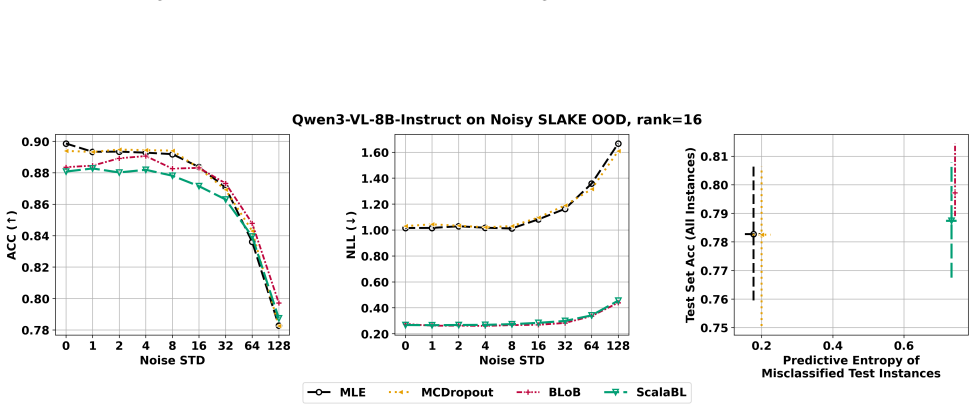
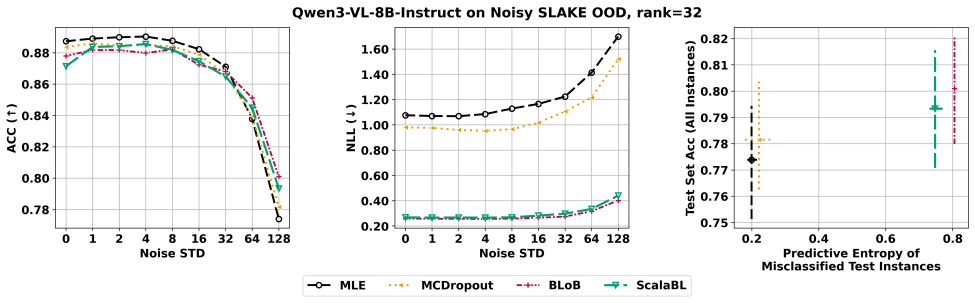
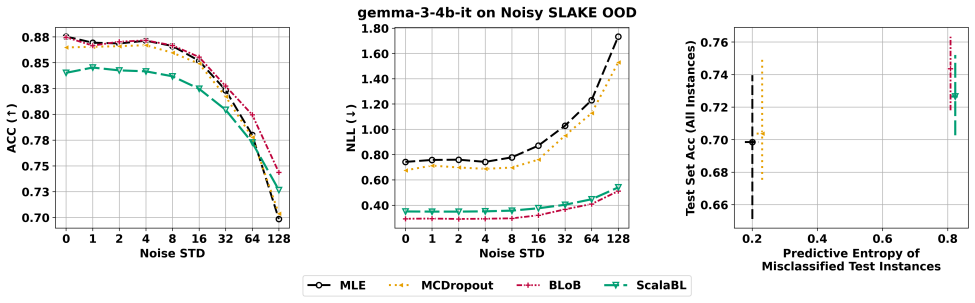
We introduce Bayesian Adaptation Gym (BAG), a benchmark for the Bayesian adaptation of multi-modal language models. BAG provides reference implementations of classic Bayesian baselines and state-of-the-art adaptation methods, along with a multi-modal dataset and task suite designed to probe calibration, robustness under distribution shift, and decision-making under uncertainty via active learning. Using BAG, we conduct and report extensive experiments across model sizes, datasets, and tasks to highlight the successes and failures of current Bayesian adaptation approaches.
What carries the argument
Bayesian Adaptation Gym (BAG), the open benchmark containing reference implementations, multi-modal datasets, and tasks for calibration, distribution shift, and active learning.
If this is right
- Researchers can now run controlled comparisons of Bayesian low-rank methods against non-Bayesian baselines on identical calibration, shift, and active-learning tasks.
- The reported experiments already identify concrete model sizes and tasks where Bayesian adaptation improves uncertainty estimates and where it does not.
- The open-source release lets new adaptation techniques be added and immediately evaluated against the same reference suite.
- Deployment decisions in high-stakes domains can be informed by the benchmark's calibration and robustness results rather than isolated case studies.
Where Pith is reading between the lines
- The benchmark's task design could be reused to test whether non-Bayesian uncertainty methods reach similar calibration levels at lower cost.
- Extending the suite to additional modalities or larger base models would test whether the observed patterns of success and failure generalize.
- The active-learning results may indicate specific decision rules that benefit most from Bayesian low-rank posteriors.
Load-bearing premise
The chosen multi-modal dataset and task suite are sufficient to reveal where Bayesian low-rank adaptation methods provide meaningful benefits over non-Bayesian baselines.
What would settle it
Re-running the full BAG suite and finding no consistent, statistically significant gains in calibration error or robustness for any Bayesian low-rank method across all model sizes and tasks would show the benchmark does not yet separate meaningful benefits.
Figures
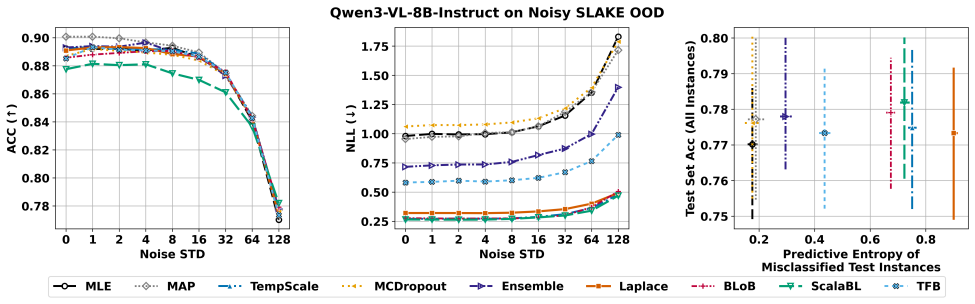
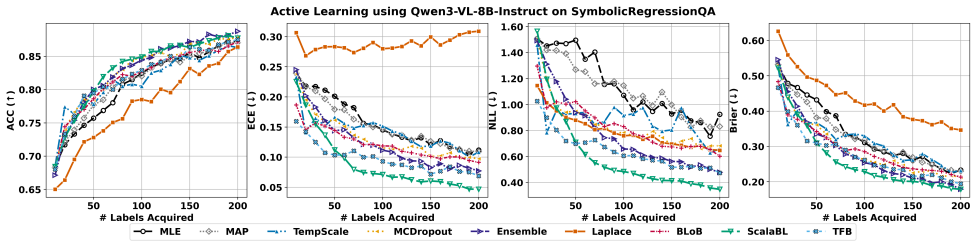
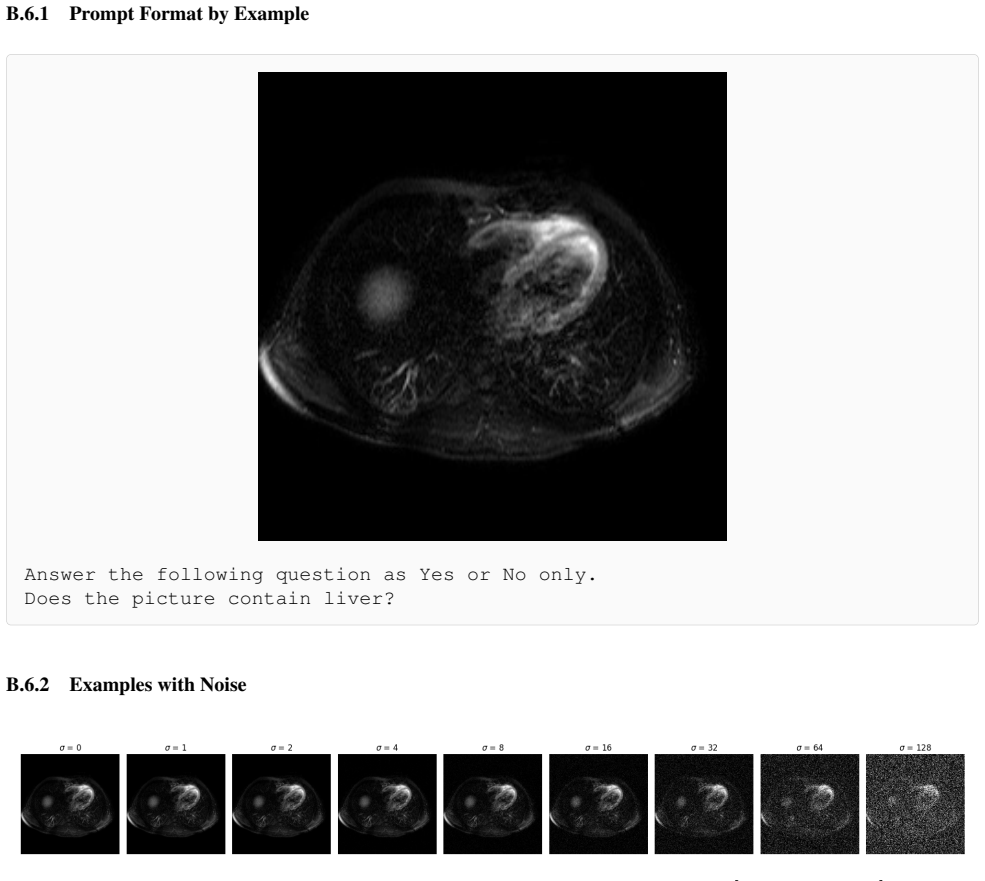
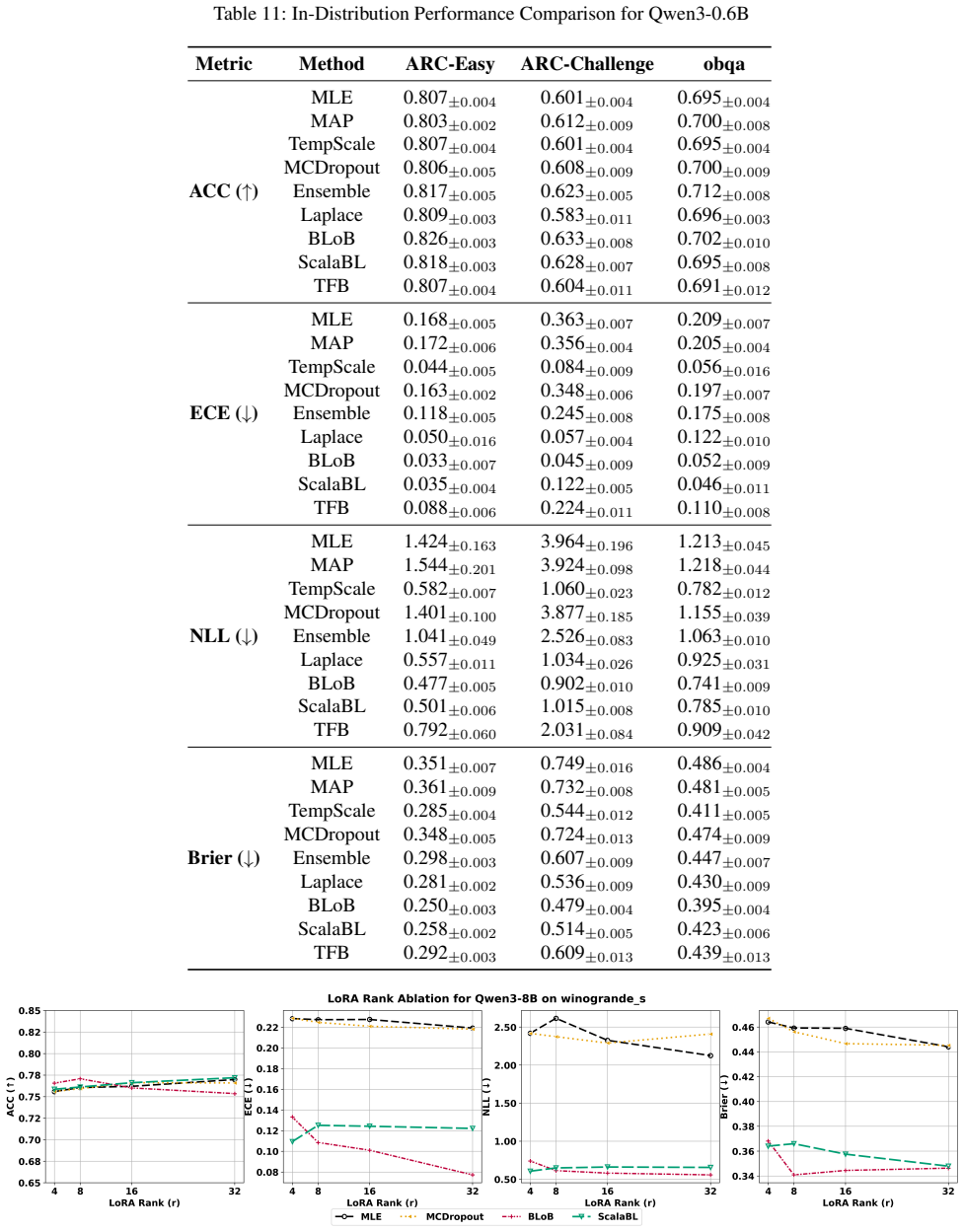
read the original abstract
Large multi-modal language models are increasingly deployed in high-stakes domains, making well-calibrated uncertainty essential. Traditional Bayesian methods approximate posteriors over all model weights, which becomes intractable for modern large models. For this reason, recent work instead considers Bayesian low-rank adaptation to enable tractable posterior approximation. Due to a lack of a standardized benchmark to evaluate these approaches, it remains unclear where these methods provide meaningful benefits. To fill this gap, we introduce Bayesian Adaptation Gym (BAG), a benchmark for the Bayesian adaptation of multi-modal language models. BAG provides reference implementations of classic Bayesian baselines and state-of-the-art adaptation methods, along with a multi-modal dataset and task suite designed to probe calibration, robustness under distribution shift, and decision-making under uncertainty via active learning. Using BAG, we conduct and report extensive experiments across model sizes, datasets, and tasks to highlight the successes and failures of current Bayesian adaptation approaches. To enable further research, BAG is fully open source: https://github.com/SRI-CSL/BayesAdapt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bayesian Adaptation Gym (BAG), an open-source benchmark for evaluating Bayesian low-rank adaptation methods on multi-modal language models. It supplies reference implementations of classic Bayesian baselines and state-of-the-art adaptation techniques, a multi-modal dataset, and a task suite targeting calibration, robustness under distribution shift, and decision-making under uncertainty via active learning. The authors report extensive experiments across model sizes, datasets, and tasks to illustrate successes and failures of current approaches.
Significance. A standardized benchmark in this area would be useful for clarifying the practical value of Bayesian low-rank adaptation in high-stakes settings that require well-calibrated uncertainty. The open release of code, reference implementations, and the task suite is a concrete strength that directly supports reproducibility and follow-on work.
major comments (1)
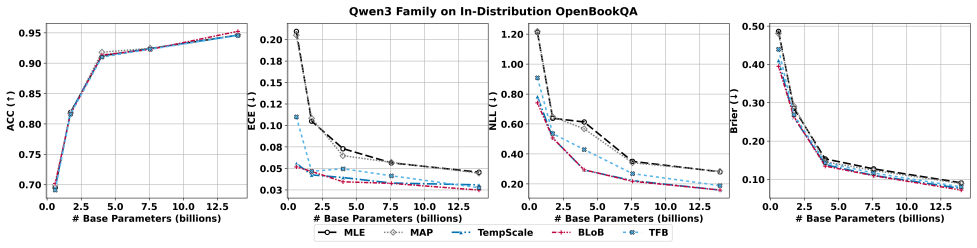
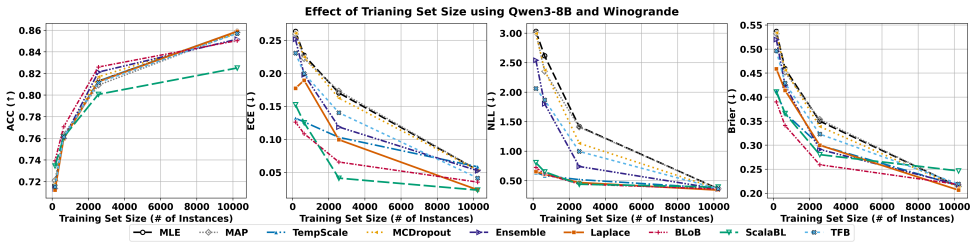
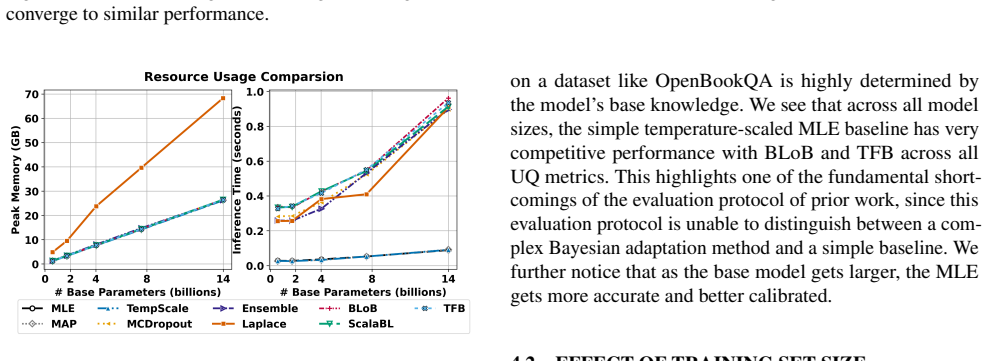
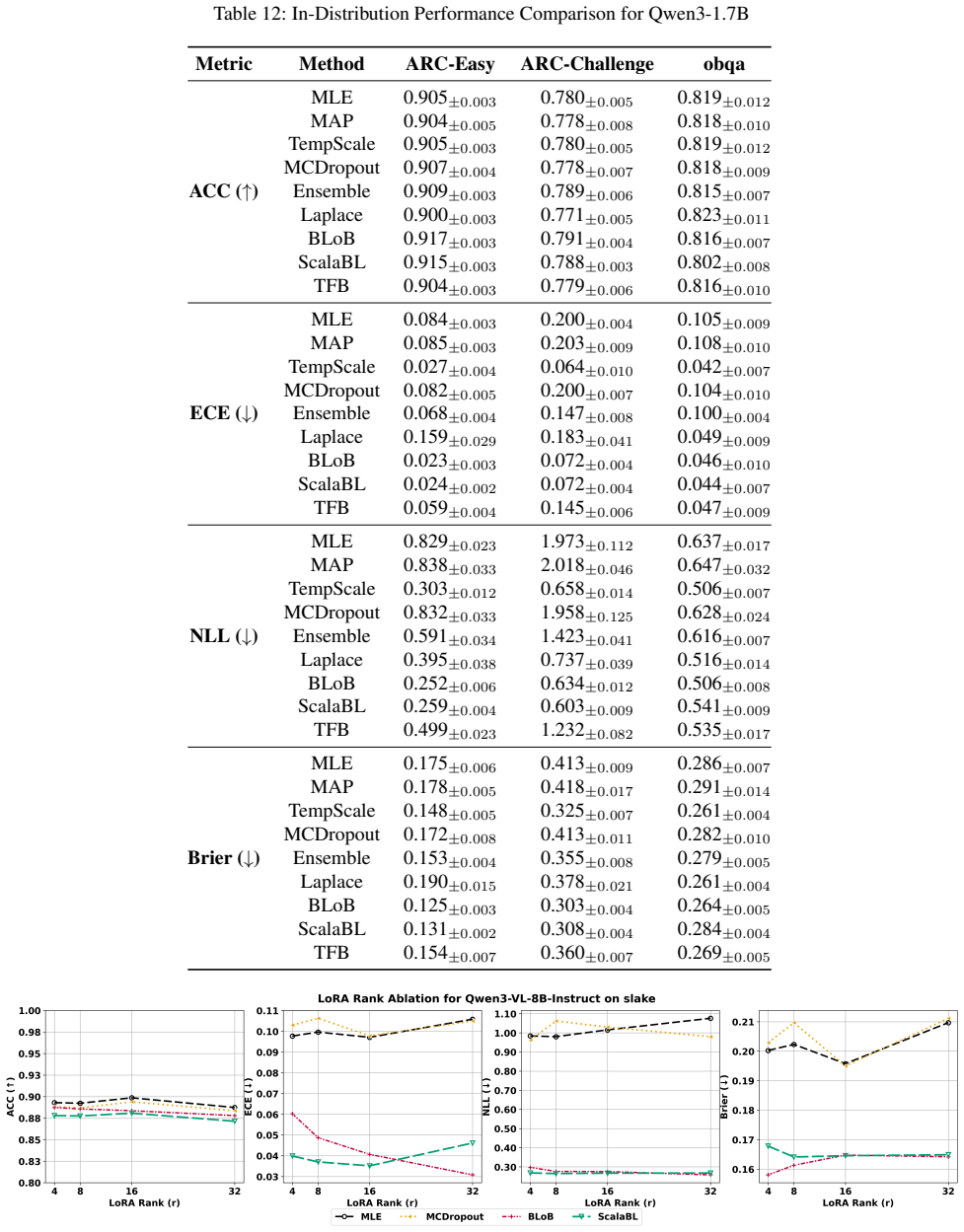
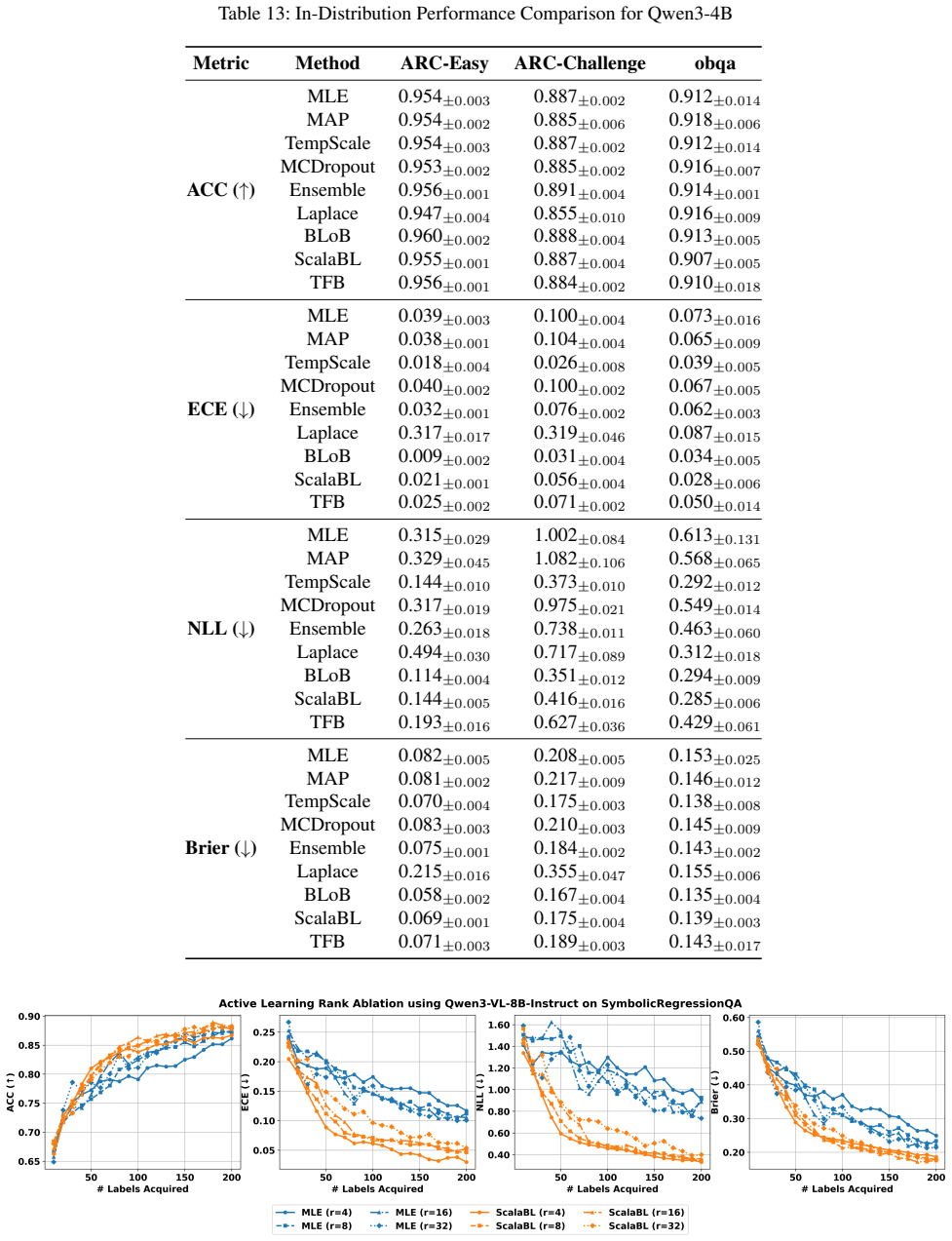
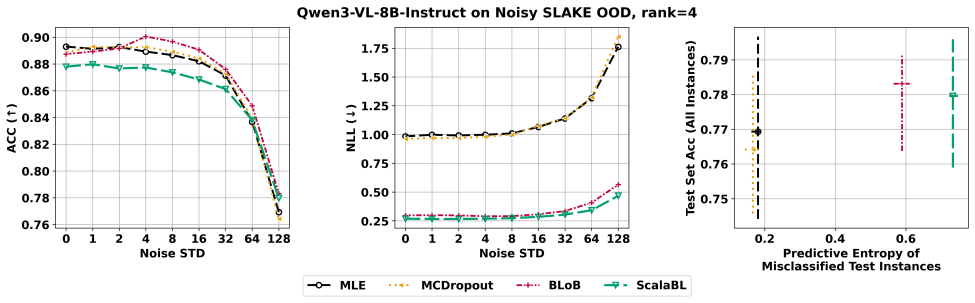
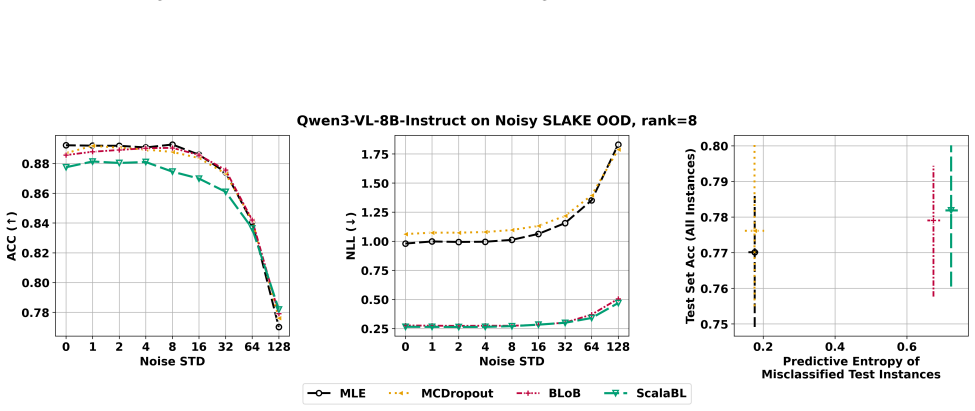
- [Abstract and task-suite description] Task suite and experimental design: the central claim that BAG clarifies where Bayesian adaptation yields meaningful benefits over non-Bayesian LoRA baselines rests on the chosen calibration, distribution-shift, and active-learning tasks actually surfacing performance gaps. No concrete metrics, statistical tests, or ablation results are supplied in the abstract or high-level description to confirm the tasks are diagnostic rather than saturated; this is load-bearing for the benchmark's stated purpose.
minor comments (1)
- [Abstract] The GitHub link is given but no commit hash or release tag is provided, which would aid exact reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract and task-suite description] Task suite and experimental design: the central claim that BAG clarifies where Bayesian adaptation yields meaningful benefits over non-Bayesian LoRA baselines rests on the chosen calibration, distribution-shift, and active-learning tasks actually surfacing performance gaps. No concrete metrics, statistical tests, or ablation results are supplied in the abstract or high-level description to confirm the tasks are diagnostic rather than saturated; this is load-bearing for the benchmark's stated purpose.
Authors: We agree that the abstract would be strengthened by including concrete metrics and brief indications of performance gaps to better substantiate the claim that the tasks are diagnostic. The full manuscript already reports extensive quantitative results, statistical comparisons, and ablations across calibration (e.g., ECE), robustness (distribution-shift accuracy), and active learning (query efficiency) in the experimental sections. To directly address the concern at the high-level description, we will revise the abstract to incorporate 1-2 key illustrative results demonstrating where Bayesian methods outperform or underperform non-Bayesian LoRA baselines. revision: yes
Circularity Check
No circularity: benchmark creation paper has no derivation chain
full rationale
This paper introduces an external benchmark (BAG) with reference implementations, a multi-modal dataset, and task suite for calibration, distribution shift, and active learning. Its central contribution is the release of this evaluation framework rather than any derivation, prediction, or fitted quantity. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided text; the work is self-contained as an independent resource whose value rests on external use rather than internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631,
-
[2]
Qiguang Chen, Mingda Yang, Libo Qin, Jinhao Liu, Zheng Yan, Jiannan Guan, Dengyun Peng, Yiyan Ji, Hanjing Li, Mengkang Hu, et al. Ai4research: A survey of arti- ficial intelligence for scientific research.arXiv preprint arXiv:2507.01903,
-
[3]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
-
[4]
Bayesian active learning for classification and preference learning.arXiv preprint arXiv:1112.5745,
Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classification and preference learning.arXiv preprint arXiv:1112.5745,
-
[5]
Why language models hallucinate.arXiv preprint arXiv:2509.04664,
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. Why language models hallucinate.arXiv preprint arXiv:2509.04664,
-
[6]
Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114,
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114,
-
[7]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
-
[8]
Bayesian Adaptation Gym: A Benchmark for the Bayesian Low-Rank Adaptation of Multi-Modal Language Models (Supplementary Material) Colin Samplawski1 Ramneet Kaur1 Manoj Acharya1 Anirban Roy1 Adam D. Cobb1 1Neuro-Symbolic Computing and Intelligence Research Group, Computer Science Laboratory, SRI International A FURTHER METHOD DETAILS In this section we pro...
2017
-
[9]
is a post-hoc Bayesian adaptation method which starts from a standard fine-tuning LoRA checkpoint θMLE. An isotropic Gaussian prior p(θ) =N(0, λ −1I) is placed over the LoRA parameters and the posterior is approximated by a Laplace Gaussian: p(θ| D)≈ N(θ MLE,Σ),Σ = (F+λI) −1, whereFis the Fisher curvature, in a KFAC Kronecker-factorized form. For a test i...
2024
-
[10]
follows the stochastic variational inference approach of BLoB, but instead performs inference in a r-dimensional subspace (where r is the LoRA rank). That is, we learn a variational approximation over anr-dimensional vectorsas a diagonal Gaussian distribution: qθ(s) =N(s|s µ,diag(s σ))(5) with mean and variance parameters θ= [s µ,s σ]. Like BLoB the repar...
1999
-
[11]
cold start)
For each training run within the loop, we train for 1000 steps and start from randomly initialized adaptation parameters each time (i.e. cold start). We find that the main bottleneck in this loop is computing the acquisition function a on each element in the unlabeled pool, which in practice is the training set of one of the datasets in BAG. For this reas...
2011
-
[12]
It is a part of Windows Essentials software suite and offers the ability to create and edit videos as well as to publish them on OneDrive, Facebook, Vimeo, YouTube, and Flickr
is a discontinued video editing software by Microsoft. It is a part of Windows Essentials software suite and offers the ability to create and edit videos as well as to publish them on OneDrive, Facebook, Vimeo, YouTube, and Flickr. Question: is windows movie maker part of windows essentials? B.4.2 Dataset Statistics # Instances # ClassesTrain Validation T...
2025
-
[13]
We randomly generate a train/validation/test split for use for this dataset
tests a model’s visual understanding and reasoning abilities using data cases where the model must understand the input image in order to correctly answer the question. We randomly generate a train/validation/test split for use for this dataset. B.8.1 Prompt Format by Example Answer the multiple choice question below. Output the letter of your choice only...
arXiv 2024
-
[14]
C.1.1 OOD Results: OBQA -> MMLU We next consider out-of-distribution (ODD) experiments. We start with OOD experiments similar to prior work where we first train an adapter on the OpenBookQA dataset and then test on various topics from the MMLU dataset [Hendrycks et al., 2021]. We note that in contrast to prior work we use the MMLU-Redux2.0 dataset which f...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.