Not All Errors Are Equal: A Systematic Study of Error Propagation in Large Language Model Inference
Pith reviewed 2026-06-28 12:34 UTC · model grok-4.3
The pith
Soft errors in LLM inference propagate in task-specific patterns that software modifications can mitigate without hardware changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
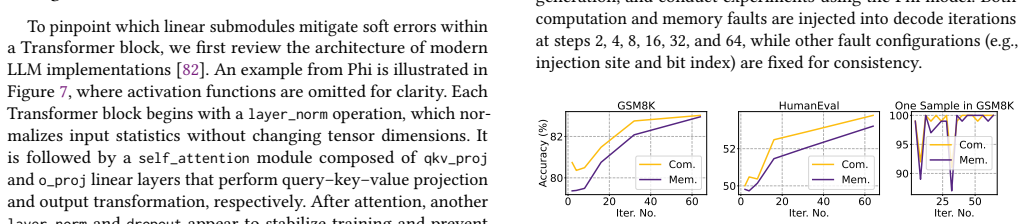
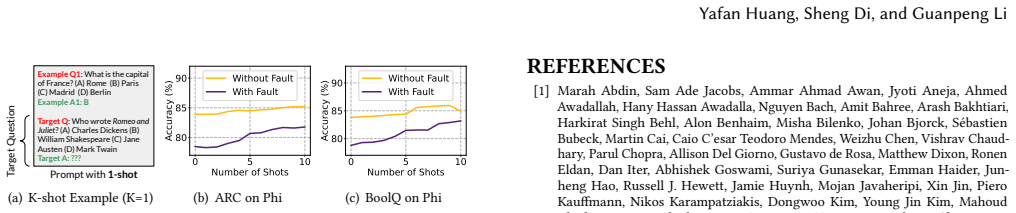
LLMFI, a configurable deterministic fault-injection framework, was used to inject faults into three open-weighted LLMs across thirteen tasks spanning reasoning, multilingual, mathematical, and coding domains. The injections expose distinct vulnerability patterns and generate seventeen takeaways on how errors propagate, together with four low-overhead software-only directions that improve reliability and supply guidance for future error detection and mitigation.
What carries the argument
LLMFI, a configurable and deterministic fault-injection framework that places representative soft errors at chosen locations during LLM inference to trace their downstream effects.
If this is right
- Error propagation varies markedly by task domain, with reasoning and coding tasks showing different sensitivities than multilingual or mathematical ones.
- Four specific low-overhead software modifications can reduce the impact of injected faults.
- The identified patterns supply concrete guidance for building error detection and mitigation methods tailored to LLM inference.
- Open-weighted models exhibit repeatable vulnerability profiles that can inform deployment choices in HPC workflows.
Where Pith is reading between the lines
- The same fault-injection approach could be adapted to study closed-source models by treating them as black boxes and measuring output changes.
- Deployment pipelines for LLMs in scientific computing might incorporate lightweight checks at the points the study flags as most vulnerable.
- Whether the four software directions remain effective when error rates rise or when models are fine-tuned on new data remains an open test.
- The task-specific patterns may connect to broader questions of how model architecture influences resilience to transient faults.
Load-bearing premise
The error behaviors produced by the LLMFI fault-injection framework match the soft errors that actually occur on real HPC hardware when LLMs run.
What would settle it
Compare the error rates, output corruptions, and propagation paths observed when the same LLMs run on physical hardware that experiences documented soft errors against the behaviors recorded by LLMFI on the same models and tasks.
Figures














read the original abstract
Large language models (LLMs) are increasingly integrated into high-performance computing (HPC) workflows, accelerating scientific discovery through diverse perspectives such as code generation and domain-specific decision-making. Yet, how soft errors propagate and affect LLM inference remains largely unexplored. To bridge this gap, we present a comprehensive study on error propagation in LLM inference, enabled by our proposed LLMFI, a configurable and deterministic fault-injection framework. Using LLMFI, we systematically inject faults across three open-weighted LLMs and thirteen representative tasks, covering reasoning, multilingual, mathematical, and coding domains. In addition, we conduct fine-grained case studies that reveal critical vulnerability patterns. Overall, our study yields 17 takeaways that advance the understanding of error propagation in LLM inference and introduces four low-overhead directions to improve reliability through software-only modification, offering practical guidance for future error detection and mitigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLMFI, a configurable and deterministic fault-injection framework, and uses it to systematically inject faults into three open-weighted LLMs across thirteen tasks spanning reasoning, multilingual, mathematical, and coding domains. It reports fine-grained case studies revealing vulnerability patterns, derives 17 takeaways on error propagation in LLM inference, and proposes four low-overhead software-only directions for improving reliability.
Significance. If the LLMFI fault model is representative of real HPC soft errors, the empirical observations and mitigation directions would provide practical guidance for error detection and reliability in HPC deployments of LLMs, an area that is currently underexplored. The work's strength lies in its systematic coverage across models and tasks, but this value is conditional on the framework's grounding.
major comments (1)
- [LLMFI framework description and experimental setup] The central claims (17 takeaways and four mitigation directions) rest on LLMFI injections producing behaviors representative of actual soft errors in HPC hardware. The manuscript provides no direct comparison or validation against empirical hardware error traces (e.g., bit-flip locations, rates, or timing in memory/registers during forward passes), which is load-bearing for generalizability.
minor comments (1)
- [Abstract and results overview] The abstract supplies no quantitative results, error bars, or statistical controls; the full manuscript should ensure these are clearly summarized in the results section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [LLMFI framework description and experimental setup] The central claims (17 takeaways and four mitigation directions) rest on LLMFI injections producing behaviors representative of actual soft errors in HPC hardware. The manuscript provides no direct comparison or validation against empirical hardware error traces (e.g., bit-flip locations, rates, or timing in memory/registers during forward passes), which is load-bearing for generalizability.
Authors: We agree that the absence of direct validation against real HPC hardware error traces limits the strength of claims about representativeness. Obtaining such traces for LLM forward passes is not feasible within this study, as it would require proprietary hardware access and instrumentation not available to us. LLMFI follows standard practice in HPC fault-injection literature by employing configurable single-bit-flip models. In revision we will (1) expand Section 3 to explicitly document the fault-model assumptions and cite prior soft-error studies that used analogous models, (2) add a dedicated limitations paragraph stating that the 17 takeaways and mitigation directions are observations under the modeled conditions rather than proven hardware behaviors, and (3) qualify generalizability statements accordingly. These changes will allow readers to interpret the results without overclaiming representativeness. revision: partial
- Direct comparison or validation of LLMFI fault injections against empirical hardware error traces from HPC LLM inference
Circularity Check
No significant circularity; empirical measurement study
full rationale
This is an empirical fault-injection study that reports observations from running LLMFI on three models across thirteen tasks. No derivations, equations, or predictions appear in the provided text. The 17 takeaways and four mitigation directions are presented as direct results of the injection experiments rather than quantities fitted or defined in terms of themselves. The representativeness of LLMFI relative to real HPC soft errors is an external-validity assumption, not a self-referential reduction. No self-citation chains, ansatzes, or renamings of known results are load-bearing for the central claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Configurable deterministic fault injection accurately models soft errors that occur during LLM inference on HPC hardware
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Hassan Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Singh Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio C’esar Teodoro Mendes, Weizhu Chen, Vishrav Chaud- hary, Parul Chopra, Allison Del Giorno, Gustavo de Rosa, Matthew ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Udit Kumar Agarwal, Abraham Chan, and Karthik Pattabiraman. 2023. Resilience assessment of large language models under transient hardware faults. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 659–670
2023
-
[3]
Ghadeer Alabandi, Jelena Tešić, Lucas Rusnak, and Martin Burtscher. 2021. Dis- covering and balancing fundamental cycles in large signed graphs. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–17
2021
-
[4]
et al Albert Q Jiang. 2023. Mistral 7B.https://arxiv.org/abs/2310.06825(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Abdul Rehman Anwer, Guanpeng Li, Karthik Pattabiraman, Michael Sullivan, Timothy Tsai, and Siva Kumar Sastry Hari. 2020. Gpu-trident: efficient modeling of error propagation in gpu programs. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–15
2020
-
[6]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Jehyeon Bang, Yujeong Choi, Myeongwoo Kim, Yongdeok Kim, and Minsoo Rhu
-
[8]
In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO)
vtrain: A simulation framework for evaluating cost-effective and compute- optimal large language model training. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 153–167
-
[9]
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. 2024. Deepseek llm: Scaling open-source language models with longtermism.arXiv preprint arXiv:2401.02954 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. 2020. Piqa: Reasoning about physical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, Vol. 34. 7432–7439
2020
-
[11]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[12]
Aurélien Cavelan, Rubén M Cabezón, and Florina M Ciorba. 2019. Detection of silent data corruptions in smoothed particle hydrodynamics simulations. In2019 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID). IEEE, 31–40
2019
-
[13]
Jonathan Chang, George A Reis, and David I August. 2006. Automatic instruction- level software-only recovery. InInternational Conference on Dependable Systems and Networks (DSN’06). IEEE, 83–92
2006
-
[14]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Zizhong Chen. 2013. Online-ABFT: An online algorithm based fault tolerance scheme for soft error detection in iterative methods.ACM SIGPLAN Notices48, 8 (2013), 167–176
2013
-
[16]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168(2021). 12 Not All Errors Are Equal: A Systematic Study of Error Propagation in Large Language Model Inference
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Huangliang Dai, Shixun Wu, Jiajun Huang, Zizhe Jian, Yue Zhu, Haiyang Hu, and Zizhong Chen. 2025. FT-Transformer: Resilient and reliable transformer with end-to-end fault tolerant attention. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1085–1098
2025
-
[20]
Xianzhong Ding, Le Chen, Murali Emani, Chunhua Liao, Pei-Hung Lin, Tristan Vanderbruggen, Zhen Xie, Alberto Cerpa, and Wan Du. 2023. Hpc-gpt: Integrating large language model for high-performance computing. InProceedings of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis. 951–960
2023
- [21]
-
[22]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
- [23]
-
[24]
Bo Fang, Qining Lu, Karthik Pattabiraman, Matei Ripeanu, and Sudhanva Gu- rumurthi. 2016. ePVF: An enhanced program vulnerability factor methodology for cross-layer resilience analysis. In2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). IEEE, 168–179
2016
-
[25]
Siyuan Feng, Jiawei Liu, Ruihang Lai, Charlie Ruan, Yong Yu, Lingming Zhang, and Tianqi Chen. 2025. Productively Deploying Emerging Models on Emerging Platforms: A Top-Down Approach for Testing and Debugging.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 1818–1840
2025
-
[26]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Zhengyang He, Yafan Huang, Hui Xu, Dingwen Tao, and Guanpeng Li. 2023. Demystifying and mitigating cross-layer deficiencies of soft error protection in instruction duplication. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–13
2023
-
[28]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[29]
Peter H Hochschild, Paul Turner, Jeffrey C Mogul, Rama Govindaraju, Parthasarathy Ranganathan, David E Culler, and Amin Vahdat. 2021. Cores that don’t count. InProceedings of the Workshop on Hot Topics in Operating Sys- tems. 9–16
2021
-
[30]
Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Yuhan Dong, and Yu Wang. 2024. Flashdecoding++: Faster large language model inference with asynchronization, flat gemm optimization, and heuristics. Proceedings of Machine Learning and Systems6 (2024), 148–161
2024
-
[31]
Kuang-Hua Huang and Jacob A Abraham. 1984. Algorithm-based fault tolerance for matrix operations.IEEE transactions on computers100, 6 (1984), 518–528
1984
-
[32]
Yafan Huang, Sheng Di, Xiaodong Yu, Guanpeng Li, and Franck Cappello. 2023. cuszp: An ultra-fast gpu error-bounded lossy compression framework with opti- mized end-to-end performance. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–13
2023
-
[33]
Yafan Huang, Sheng Di, Zhaorui Zhang, Xiaoyi Lu, and Guanpeng Li. 2024. Versatile Datapath Soft Error Detection on the Cheap for HPC Applications. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–15
2024
-
[34]
Yafan Huang, Shengjian Guo, Sheng Di, Guanpeng Li, and Franck Cappello
-
[35]
InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis
Mitigating silent data corruptions in hpc applications across multiple pro- gram inputs. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–14
-
[36]
Yafan Huang, Zhengyang He, Lingda Li, and Guanpeng Li. 2023. Characterizing runtime performance variation in error detection by duplicating instructions. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 730–741
2023
-
[37]
Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, and Ashish Panwar. 2025. Pod-attention: Unlocking full prefill-decode overlap for faster llm inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 897–912
2025
-
[38]
Ignacio Laguna, Martin Schulz, David F Richards, Jon Calhoun, and Luke Olson
-
[39]
InProceedings of the 2016 International Symposium on Code Generation and Optimization
Ipas: Intelligent protection against silent output corruption in scientific ap- plications. InProceedings of the 2016 International Symposium on Code Generation and Optimization. 227–238
2016
-
[40]
Malgorzata Lazuka, Andreea Anghel, and Thomas Parnell. 2024. Llm-pilot: Characterize and optimize performance of your llm inference services. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–18
2024
-
[41]
Guanpeng Li, Siva Kumar Sastry Hari, Michael Sullivan, Timothy Tsai, Karthik Pattabiraman, Joel Emer, and Stephen W Keckler. 2017. Understanding error propagation in deep learning neural network (DNN) accelerators and applications. InProceedings of the international conference for high performance computing, networking, storage and analysis. 1–12
2017
-
[42]
Guanpeng Li, Karthik Pattabiraman, Chen-Yang Cher, and Pradip Bose. 2016. Understanding error propagation in GPGPU applications. InSC’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 240–251
2016
-
[43]
Guanpeng Li, Karthik Pattabiraman, Siva Kumar Sastry Hari, Michael Sullivan, and Timothy Tsai. 2018. Modeling soft-error propagation in programs. In2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Net- works (DSN). IEEE, 27–38
2018
- [44]
-
[45]
Yuhang Liang, Xinyi Li, Jie Ren, Ang Li, Bo Fang, and Jieyang Chen. 2025. AT- TNChecker: Highly-Optimized Fault Tolerant Attention for Large Language Model Training. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 252–266
2025
-
[46]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations
2023
-
[47]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2021. Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. 2024. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference. 38–56
2024
-
[50]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023. Scissorhands: Exploit- ing the persistence of importance hypothesis for llm kv cache compression at test time.Advances in Neural Information Processing Systems36 (2023), 52342–52364
2023
-
[51]
Robert Lucas, James Ang, Keren Bergman, Shekhar Borkar, William Carlson, Laura Carrington, George Chiu, Robert Colwell, William Dally, Jack Dongarra, et al. 2014. Top ten exascale research challenges.DOE ASCAC subcommittee report(2014), 1–86
2014
-
[52]
Abdulrahman Mahmoud, Neeraj Aggarwal, Alex Nobbe, Jose Rodrigo Sanchez Vicarte, Sarita V Adve, Christopher W Fletcher, Iuri Frosio, and Siva Kumar Sastry Hari. 2020. Pytorchfi: A runtime perturbation tool for dnns. In2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops (DSN-W). IEEE, 25–31
2020
-
[53]
Abdulrahman Mahmoud, Siva Kumar Sastry Hari, Michael B Sullivan, Timothy Tsai, and Stephen W Keckler. 2018. Optimizing software-directed instruction replication for gpu error detection. InSC18: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 842–854
2018
-
[54]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Shubhendu S Mukherjee, Christopher Weaver, Joel Emer, Steven K Reinhardt, and Todd Austin. 2003. A systematic methodology to compute the architectural vulnerability factors for a high-performance microprocessor. InProceedings. 36th Annual IEEE/ACM International Symposium on Microarchitecture, 2003. MICRO-36. IEEE, 29–40
2003
-
[56]
Daniel Nichols, Joshua H Davis, Zhaojun Xie, Arjun Rajaram, and Abhinav Bhatele. 2024. Can large language models write parallel code?. InProceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing. 281–294
2024
-
[57]
Daniel Nichols, Aniruddha Marathe, Harshitha Menon, Todd Gamblin, and Abhi- nav Bhatele. 2024. Hpc-coder: Modeling parallel programs using large language models. InISC High Performance 2024 Research Paper Proceedings (39th Interna- tional Conference). Prometeus GmbH, 1–12
2024
-
[58]
Bin Nie, Devesh Tiwari, Saurabh Gupta, Evgenia Smirni, and James H Rogers
-
[59]
In2016 IEEE International Symposium on High Performance Computer Architecture (HPCA)
A large-scale study of soft-errors on GPUs in the field. In2016 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 519–530
-
[60]
et al Nishant George. 2023. Silent Data Corruption in AI. https://www.opencompute.org/documents/sdc-in-ai-ocp-whitepaper-final-pdf (2023)
2023
-
[61]
NVIDIA. 2024. NVIDIA LLM Benchmarking. https://docs.nvidia.com/nim/benchmarking/llm/latest/metrics.html(2024)
2024
-
[62]
George Papadimitriou and Dimitris Gizopoulos. 2021. Demystifying the system vulnerability stack: Transient fault effects across the layers. In2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 902–915
2021
-
[63]
Soyoung Park, Hojung Namkoong, Boyeol Choi, Michael B Sullivan, and Jungrae Kim. 2024. Cachecraft: Enhancing gpu performance under memory protection through reconstructed caching. In2024 57th IEEE/ACM International Symposium 13 Yafan Huang, Sheng Di, and Guanpeng Li on Microarchitecture (MICRO). IEEE, 324–337
2024
-
[64]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
-
[65]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
- [66]
- [67]
-
[68]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, and Ashish Panwar. 2025. vattention: Dynamic memory management for serving llms without pagedattention. InProceedings of the 30th ACM International Confer- ence on Architectural Support for Programming Languages and Operating Systems, Volume 1. 1133–1150
2025
-
[69]
Md Hasanur Rahman, Aabid Shamji, Shengjian Guo, and Guanpeng Li. 2021. Peppa-x: finding program test inputs to bound silent data corruption vulnera- bility in hpc applications. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–13
2021
-
[70]
Saurabh Raje, Hunter McCoy, Atanas Rountev, Prashant Pandey, and Pon- nuswamy Sadayappan. 2025. FaSTCC: Fast Sparse Tensor Contractions on CPUs. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 617–630
2025
- [71]
-
[72]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale.Commun. ACM 64, 9 (2021), 99–106
2021
-
[73]
Shihui Song and Peng Jiang. 2022. Rethinking graph data placement for graph neural network training on multiple GPUs. InProceedings of the 36th ACM Inter- national Conference on Supercomputing. 1–10
2022
-
[74]
Vilas Sridharan and David R Kaeli. 2009. Eliminating microarchitectural depen- dency from architectural vulnerability. In2009 IEEE 15th International Symposium on High Performance Computer Architecture. IEEE, 117–128
2009
-
[75]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Esha Choukse, Haoran Qiu, Rodrigo Fonseca, Josep Torrellas, and Ricardo Bianchini. 2025. Tapas: Thermal-and power- aware scheduling for LLM inference in cloud platforms. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 1266–1281
2025
-
[76]
Yu Sun, Zachary Coalson, Shiyang Chen, Hang Liu, Zhao Zhang, Sanghyun Hong, Bo Fang, and Lishan Yang. 2025. Demystifying the resilience of large language model inference: An end-to-end perspective. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1127–1144
2025
-
[77]
Yu Sun, Zhu Zhu, Cherish Mulpuru, Roberto Gioiosa, Zhao Zhang, Bo Fang, and Lishan Yang. 2025. FT2: First-Token-Inspired Online Fault Tolerance on Critical Layers for Generative Large Language Models. InProceedings of the 34th International Symposium on High-Performance Parallel and Distributed Computing. 1–14
2025
-
[78]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupati- raju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Qwen Team. 2024. Qwen2 technical report.arXiv preprint arXiv:2407.106712 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.