Node Attribute Generation on Graphs
Pith reviewed 2026-05-24 17:23 UTC · model grok-4.3
The pith
A shared latent representation learned via adversarial training generates missing node attributes from graph structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
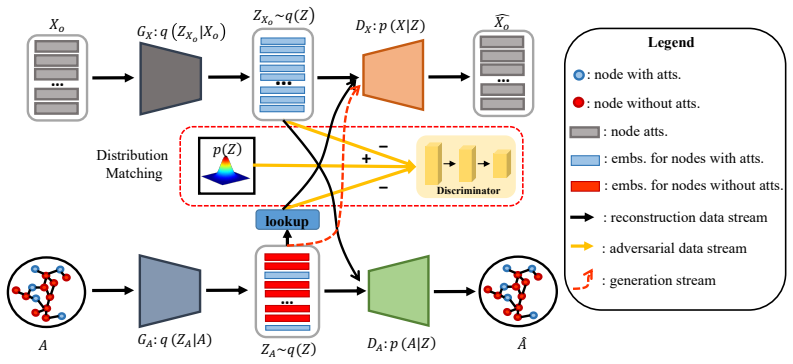
NANG learns a unifying latent representation shared by node attributes and graph structures and translates information from one modality to the other through adversarial training, thereby generating attributes for nodes whose attributes are unobserved.
What carries the argument
The unifying latent representation that acts as a bridge, learned adversarially to enable translation between graph structure and node attribute modalities.
If this is right
- The generated attributes can be substituted into existing graph algorithms to restore or exceed performance on node classification and link prediction.
- The same latent bridge supports graph data augmentation by producing synthetic node features consistent with observed structure.
- Profiling tasks that require complete node descriptions become feasible even when attribute data is absent for some nodes.
- The approach works across multiple real-world graph datasets without requiring paired attribute-structure examples for every node.
Where Pith is reading between the lines
- The method could be extended to cases where only partial attributes are missing by conditioning the translation on the observed subset.
- If the latent space proves stable under graph perturbations, the generator might serve as a regularizer for training graph neural networks on incomplete data.
- Testing the same adversarial translation on directed or temporal graphs would reveal whether the shared representation generalizes beyond static undirected cases.
Load-bearing premise
A single latent representation can be learned that captures enough information from both node attributes and graph structures to permit reliable translation between the two via adversarial training.
What would settle it
On a dataset where node attributes are statistically independent of graph structure, the generated attributes would fail to match held-out real attributes or would not improve accuracy on node classification when substituted for the missing values.
Figures

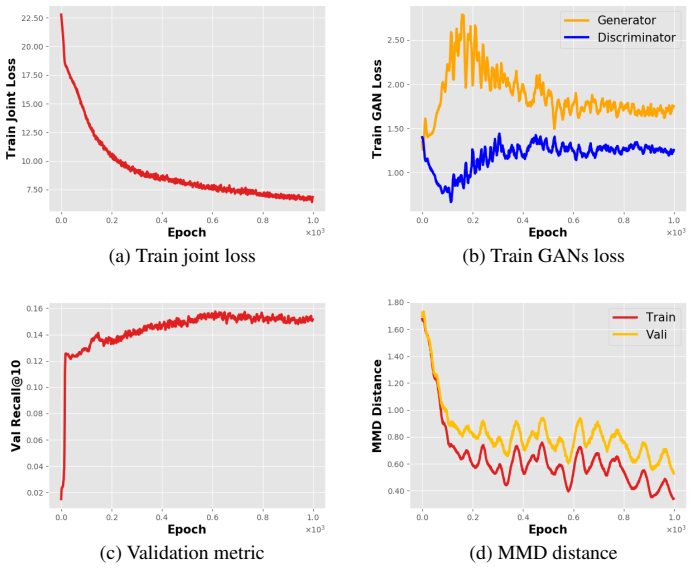
read the original abstract
Graph structured data provide two-fold information: graph structures and node attributes. Numerous graph-based algorithms rely on both information to achieve success in supervised tasks, such as node classification and link prediction. However, node attributes could be missing or incomplete, which significantly deteriorates the performance. The task of node attribute generation aims to generate attributes for those nodes whose attributes are completely unobserved. This task benefits many real-world problems like profiling, node classification and graph data augmentation. To tackle this task, we propose a deep adversarial learning based method to generate node attributes; called node attribute neural generator (NANG). NANG learns a unifying latent representation which is shared by both node attributes and graph structures and can be translated to different modalities. We thus use this latent representation as a bridge to convert information from one modality to another. We further introduce practical applications to quantify the performance of node attribute generation. Extensive experiments are conducted on four real-world datasets and the empirical results show that node attributes generated by the proposed method are high-qualitative and beneficial to other applications. The datasets and codes are available online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes NANG, a deep adversarial learning method that learns a shared latent representation between node attributes and graph structure and translates between the two modalities to generate attributes for nodes with completely unobserved features. It evaluates the approach on four real-world datasets and claims that the generated attributes are high-quality and improve performance on downstream tasks such as node classification and link prediction.
Significance. If the empirical results hold under proper controls, the work addresses a practically relevant problem of missing node attributes in graph-structured data and provides a mechanism for graph data augmentation. The release of datasets and code is a clear strength that supports reproducibility and follow-up work.
major comments (3)
- [§4] §4 (Experiments): the reported improvements on node classification and link prediction lack error bars, standard deviations across multiple runs, or statistical significance tests, so it is impossible to determine whether the gains over baselines are reliable or could be due to random variation.
- [§3] §3 (Method): the precise adversarial objective, generator/discriminator architectures, and any regularization terms used to enforce the shared latent space are not specified with equations, making the central mechanism (translation via a unifying latent representation) impossible to verify or reproduce from the text alone.
- [§4.2] §4.2 (Downstream evaluation): the protocol for how generated attributes are injected into the downstream models (e.g., whether the original graph structure is held fixed, how missing nodes are selected, and whether the same train/test splits are used) is not described, which is load-bearing for the claim that the generated attributes are beneficial.
minor comments (2)
- The abstract states that 'the datasets and codes are available online' but does not provide the URL or repository link in the manuscript body.
- Notation for the latent representation and the two modalities is introduced without a clear table or diagram summarizing the dimensions and mappings.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional rigor and clarity will strengthen the manuscript. We address each major comment below and will incorporate the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the reported improvements on node classification and link prediction lack error bars, standard deviations across multiple runs, or statistical significance tests, so it is impossible to determine whether the gains over baselines are reliable or could be due to random variation.
Authors: We agree that reporting variability across runs is necessary to substantiate the empirical improvements. In the revised manuscript, we will include results averaged over multiple independent runs with standard deviations and perform statistical significance tests (e.g., paired t-tests) against baselines to demonstrate that the observed gains are reliable. revision: yes
-
Referee: [§3] §3 (Method): the precise adversarial objective, generator/discriminator architectures, and any regularization terms used to enforce the shared latent space are not specified with equations, making the central mechanism (translation via a unifying latent representation) impossible to verify or reproduce from the text alone.
Authors: The current text provides a high-level description of the adversarial setup and shared latent space. To fully address reproducibility concerns, we will add the exact adversarial loss equations, network architecture specifications (layer sizes, activation functions), and any regularization terms in the revised method section. revision: yes
-
Referee: [§4.2] §4.2 (Downstream evaluation): the protocol for how generated attributes are injected into the downstream models (e.g., whether the original graph structure is held fixed, how missing nodes are selected, and whether the same train/test splits are used) is not described, which is load-bearing for the claim that the generated attributes are beneficial.
Authors: We acknowledge that the downstream evaluation protocol requires explicit description. The revision will detail the injection procedure, confirm that the original graph structure remains fixed, specify how nodes with missing attributes are chosen, and state that identical train/test splits are used for fair comparison. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical adversarial method (NANG) with explicit generator/discriminator architectures, training objectives, and downstream evaluations on four datasets for node classification and link prediction. The shared latent representation is learned via adversarial translation and directly tested for utility; no equation or claim reduces by construction to a fitted input, self-citation chain, or renamed ansatz. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International Conference on Machine Learning, pages 214–223, 2017
work page 2017
-
[2]
Netgan: Generating graphs via random walks
Aleksandar Bojchevski, Oleksandr Shchur, Daniel Zügner, and Stephan Günnemann. Netgan: Generating graphs via random walks. In Proceedings of the 35th International Conference on Machine Learning , volume 80 of Proceedings of Machine Learning Research, pages 610–619, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR
work page 2018
-
[3]
Infogan: Interpretable representation learning by information maximizing generative adversarial nets
Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in neural information processing systems, pages 2172–2180, 2016
work page 2016
-
[4]
MolGAN: An implicit generative model for small molecular graphs
Nicola De Cao and Thomas Kipf. MolGAN: An implicit generative model for small molecular graphs. In ICML 2018 workshop on Theoretical Foundations and Applications of Deep Generative Models, 2018
work page 2018
-
[5]
Convolutional neural networks on graphs with fast localized spectral filtering
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. InAdvances in neural information processing systems, pages 3844– 3852, 2016
work page 2016
-
[6]
Transductive multi-view zero-shot learning
Yanwei Fu, Timothy M Hospedales, Tao Xiang, and Shaogang Gong. Transductive multi-view zero-shot learning. IEEE transactions on pattern analysis and machine intelligence, 37(11):2332–2345, 2015
work page 2015
-
[7]
Domain-adversarial training of neural networks
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. The Journal of Machine Learning Research, 17(1):2096–2030, 2016
work page 2096
-
[8]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014
work page 2014
-
[9]
node2vec: Scalable feature learning for networks
Aditya Grover and Jure Leskovec. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 855–864. ACM, 2016
work page 2016
-
[10]
Inductive representation learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems, pages 1024–1034, 2017
work page 2017
-
[11]
beta-vae: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In International Conference on Learning Representations, 2017
work page 2017
-
[12]
Geoffrey E Hinton, Peter Dayan, Brendan J Frey, and Radford M Neal. The" wake-sleep" algorithm for unsupervised neural networks. Science, 268(5214):1158–1161, 1995
work page 1995
-
[13]
Zhiting Hu, Zichao Yang, Ruslan Salakhutdinov, and Eric P. Xing. On unifying deep generative models. In International Conference on Learning Representations, 2018
work page 2018
-
[14]
Image-to-image translation with conditional adversarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017
work page 2017
-
[15]
Junction tree variational autoencoder for molecular graph generation
Wengong Jin, Regina Barzilay, and Tommi Jaakkola. Junction tree variational autoencoder for molecular graph generation. In Proceedings of the 35th International Conference on Machine Learning, 2018
work page 2018
-
[16]
Vassilis Kalofolias, Xavier Bresson, Michael Bronstein, and Pierre Vandergheynst. Matrix completion on graphs. arXiv preprint arXiv:1408.1717, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Auto-encoding variational bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. In International Conference on Learning Representations, 2014
work page 2014
-
[18]
Variational graph auto-encoders
Thomas N Kipf and Max Welling. Variational graph auto-encoders. In NIPS Workshop on Bayesian Deep Learning, 2016
work page 2016
-
[19]
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017
work page 2017
-
[20]
Actional-structural graph convolutional networks for skeleton-based action recognition
Maosen Li, Siheng Chen, Xu Chen, Ya Zhang, Yanfeng Wang, and Qi Tian. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2019
work page 2019
-
[21]
Unsupervised image-to-image translation networks
Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. In Advances in Neural Information Processing Systems, pages 700–708, 2017
work page 2017
-
[22]
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(Nov):2579–2605, 2008
work page 2008
-
[23]
Alireza Makhzani. Implicit autoencoders. arXiv preprint arXiv:1805.09804, 2018. 10
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, and Ian Goodfellow. Adversarial autoencoders. In International Conference on Learning Representations, 2016
work page 2016
-
[25]
Least squares generative adversarial networks
Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. InProceedings of the IEEE International Conference on Computer Vision, pages 2794–2802, 2017
work page 2017
-
[26]
Automating the construc- tion of internet portals with machine learning
Andrew Kachites McCallum, Kamal Nigam, Jason Rennie, and Kristie Seymore. Automating the construc- tion of internet portals with machine learning. Information Retrieval, 3(2):127–163, 2000
work page 2000
-
[27]
Efficient estimation of word representations in vector space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. In International Conference on Learning Representations, 2013
work page 2013
-
[28]
Query-driven active surveying for collective classification
Galileo Namata, Ben London, Lise Getoor, Bert Huang, and UMD EDU. Query-driven active surveying for collective classification. In10th International Workshop on Mining and Learning with Graphs, 2012
work page 2012
-
[29]
f-gan: Training generative neural samplers using variational divergence minimization
Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. f-gan: Training generative neural samplers using variational divergence minimization. In Advances in neural information processing systems, pages 271–279, 2016
work page 2016
-
[30]
Deepwalk: Online learning of social representations
Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 701–710. ACM, 2014
work page 2014
-
[31]
Few-shot learning with graph neural networks
Victor Garcia Satorras and Joan Bruna Estrach. Few-shot learning with graph neural networks. In International Conference on Learning Representations, 2018
work page 2018
-
[32]
Collective classification in network data.AI magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. Collective classification in network data.AI magazine, 29(3):93–93, 2008
work page 2008
-
[33]
Graph convolutional neural networks for web-scale recommender systems
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 974–983. ACM, 2018
work page 2018
-
[34]
Rex Ying, Jiaxuan You, Christopher Morris, Xiang Ren, William L. Hamilton, and Jure Leskovec. Hi- erarchical graph representation learning with differentiable pooling. In Advances in neural information processing systems, pages 4800–4810, 2018
work page 2018
-
[35]
GraphRNN: Generating realistic graphs with deep auto-regressive models
Jiaxuan You, Rex Ying, Xiang Ren, William Hamilton, and Jure Leskovec. GraphRNN: Generating realistic graphs with deep auto-regressive models. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 5708–5717, Stockholmsmässan, Stockholm ...
work page 2018
-
[36]
Infovae: Information maximizing variational autoen- coders
Shengjia Zhao, Jiaming Song, and Stefano Ermon. Infovae: Information maximizing variational autoen- coders. In Proceedings of the 33rd Association for the Advancement of Artificial Intelligence, 2019
work page 2019
-
[37]
Degeneration in VAE: in the Light of Fisher Information Loss
Huangjie Zheng, Jiangchao Yao, Ya Zhang, and Ivor Wai-Hung Tsang. Degeneration in vae: in the light of fisher information loss. ArXiv, abs/1802.06677, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
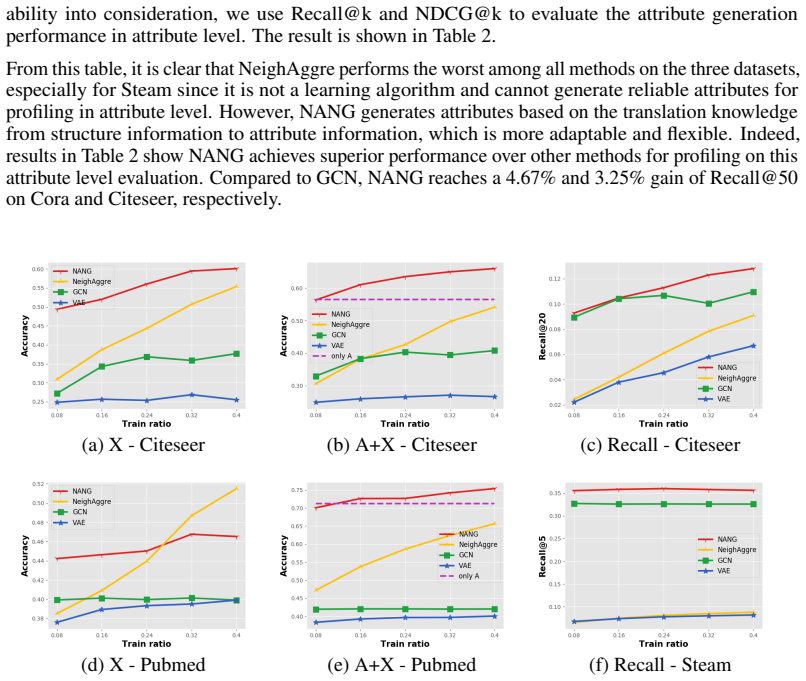
A+X" setting and profiling task. (a-c) means the result for node classification with
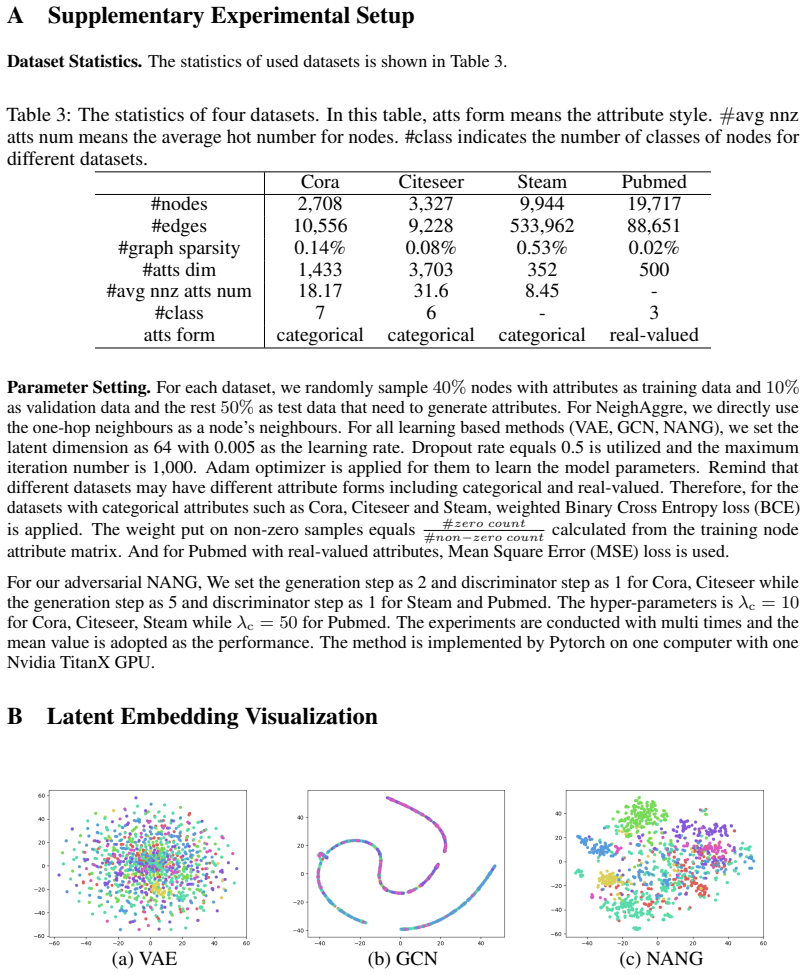
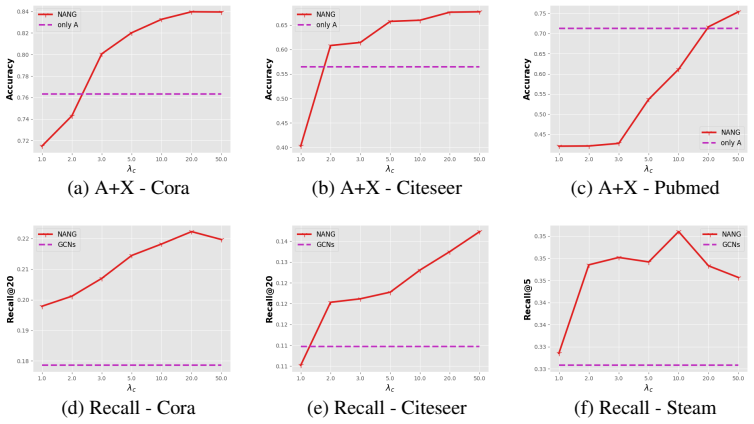
Huangjie Zheng, Jiangchao Yao, Ya Zhang, Ivor Wai-Hung Tsang, and Jia Wang. Understanding vaes in fisher-shannon plane. InProceedings of the 33rd Association for the Advancement of Artificial Intelligence, 2019. 11 A Supplementary Experimental Setup Dataset Statistics. The statistics of used datasets is shown in Table 3. Table 3: The statistics of four data...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.