Training-free Task Classification for Multi-Task Model Merging
Pith reviewed 2026-06-26 10:45 UTC · model grok-4.3
The pith
SiM classifies tasks via projection residuals onto SVD low-rank manifolds to route merged models without router training or task IDs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
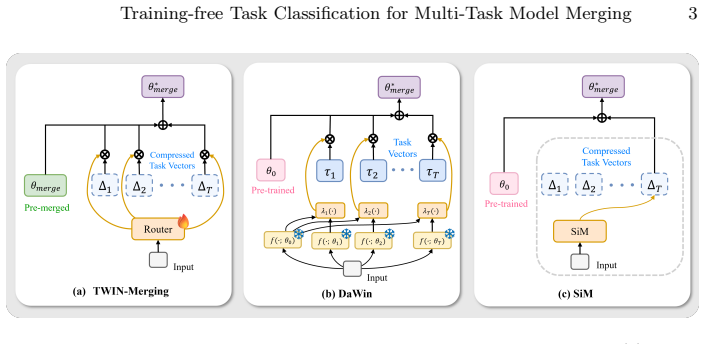
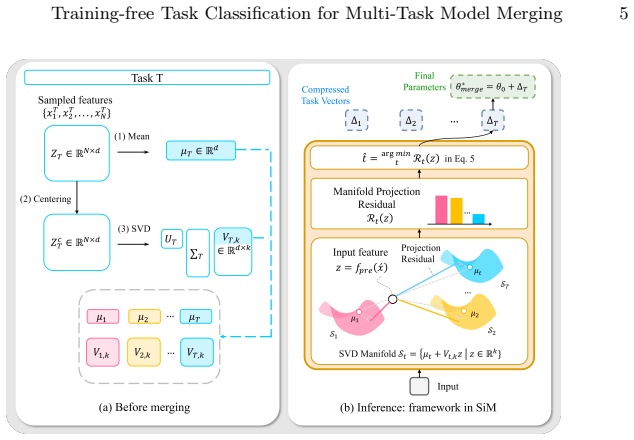
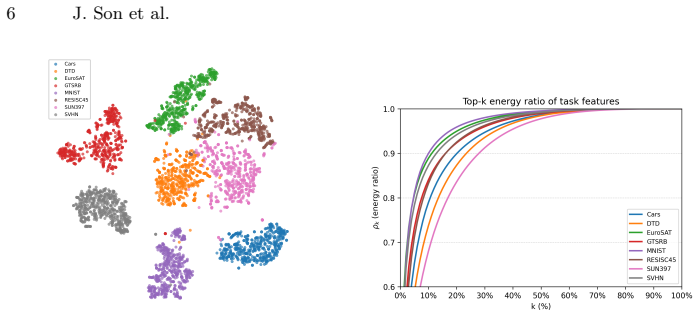
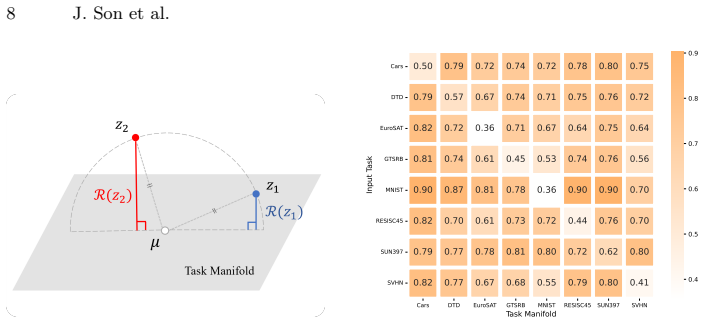
Task classification for routing can be performed without any router training by scoring each test input according to its projection residual onto SVD-derived low-rank manifolds computed separately for each task from a small support set; the lowest-residual task determines the routing choice, and the same manifolds integrate directly with subspace- or mask-based merging that stores only compressed task vectors.
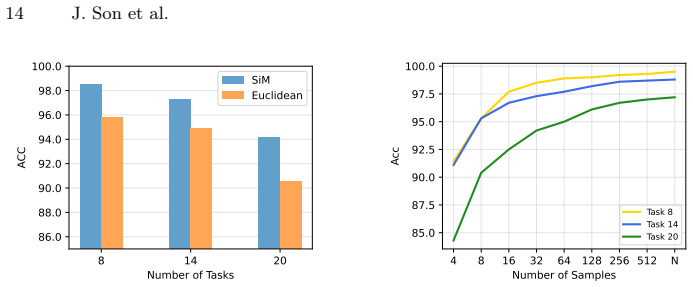
What carries the argument
SVD-based low-rank manifold approximations for each task, scored by projection residual of the test input feature.
If this is right
- Merged-model accuracy rises under task-unknown inference and narrows the gap to separate task experts.
- No router training and no task-ID access are required at inference.
- The method works with compressed task-vector representations that avoid storing full expert weights.
- The same offline manifold computation applies across both vision and language benchmarks.
Where Pith is reading between the lines
- The same residual-scoring idea could be tested on merging more than a handful of tasks without retraining any component.
- If the low-rank structure generalizes, support-set size could be reduced further while preserving separation quality.
- The approach suggests that task discrimination may not need learned routers when feature geometry already encodes task identity.
Load-bearing premise
SVD low-rank approximations from a small per-task support set produce manifolds whose projection residuals reliably distinguish tasks at inference time.
What would settle it
On a new collection of tasks, the task whose manifold yields the smallest residual for a given input matches the true task no more often than random selection, or the routed merged model shows no improvement over a non-routed baseline.
Figures
read the original abstract
Ever since the advent of foundation models and the pre-training-finetuning paradigm, there have been numerous efforts to merge multiple task-specific experts into a single multi-task model. Prior work largely focuses on finding a single merged model, but it often underperforms individual experts due to parameter interference. To resolve this, dynamic model merging employs routing to activate task-relevant parameters per input. However, existing routers typically require either additional training with abundant labeled datasets or assume the access to task IDs of each input at inference time. In this work, we aim to close the gap to expert performance without additional training or task-ID-access assumption. To this end, we formulate routing as training-free task classification for each test input. Using singular value decomposition (SVD)-based low-rank manifold approximations for each task, SiM scores tasks by the projection residual of the test input feature onto each task manifold and routes accordingly. The task manifolds are pre-computable offline from a pretrained backbone using a small per-task support set (e.g., 32 examples per task) prior to merging process, requiring no router training and no data during the merging process. Moreover, SiM integrates seamlessly with subspace-/mask-based merging that represents task-expert via lightweight compressed task vectors, avoiding the need to store full expert parameters. Experiments across computer vision and natural language processing benchmarks under task-unknown inference demonstrate that SiM substantially improves merged-model performance and consistently narrows the gap to individual task experts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SiM, a training-free task classification method for routing in multi-task model merging. It approximates each task's feature manifold via SVD on a small per-task support set (e.g., 32 examples), then routes each test input by the projection residual onto these manifolds, claiming this narrows the gap to individual task experts on CV and NLP benchmarks under task-unknown inference while integrating with subspace/mask-based merging and requiring no router training or task IDs.
Significance. If the reported gains hold after controlling for support-set sampling and SVD rank, the result would be significant for practical multi-task merging: it removes the usual costs of trained routers and task-ID assumptions while preserving the benefits of dynamic parameter activation. The offline pre-computation of manifolds from pretrained backbones and compatibility with compressed task vectors are practical strengths; the benchmark improvements, if robust, would demonstrate a viable path to closing the expert gap without additional labeled data.
major comments (3)
- [§3.2] §3.2 (task manifold construction and routing rule): the central claim that projection residuals onto SVD low-rank approximations from 32-example support sets reliably distinguish tasks is load-bearing, yet the manuscript provides no variance analysis across multiple draws of the support set, no scaling curves versus support-set size, and no quantification of inter-task subspace angles or overlap; without these, it is unclear whether the argmin residual decision is stable or discriminative when tasks share feature directions.
- [§4] §4 (experimental protocol): all reported results fix the support-set size at 32 and SVD rank without ablation or sensitivity analysis; this leaves open whether the claimed narrowing of the gap to task experts is an artifact of particular hyperparameter choices rather than a general property of the residual-based classifier.
- [Table 2 / Figure 3] Table 2 / Figure 3 (merged-model accuracy under task-unknown inference): the gains are presented without error bars over support-set resampling or backbone feature extractor variation, making it impossible to assess whether the improvements are statistically reliable or sensitive to the weakest assumption that 32-example manifolds separate task distributions.
minor comments (2)
- [§3.2] Notation for the projection residual ||(I - U_k U_k^T) f(x)|| is introduced without an explicit equation number; adding one would improve traceability when comparing to related subspace methods.
- [§1] The abstract and §1 state that manifolds are “pre-computable offline … requiring no data during the merging process,” but the dependence on a support set (even if small) should be clarified in the introduction to avoid implying zero data requirements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for robustness analyses. We will revise the manuscript to incorporate variance studies, ablations, and error bars as detailed below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (task manifold construction and routing rule): the central claim that projection residuals onto SVD low-rank approximations from 32-example support sets reliably distinguish tasks is load-bearing, yet the manuscript provides no variance analysis across multiple draws of the support set, no scaling curves versus support-set size, and no quantification of inter-task subspace angles or overlap; without these, it is unclear whether the argmin residual decision is stable or discriminative when tasks share feature directions.
Authors: We agree these analyses would strengthen the claims regarding stability. In revision we will add: (i) performance variance over 5 random support-set draws per task, (ii) scaling curves for support-set sizes 8–128, and (iii) average principal angles between task SVD bases to quantify overlap. These will be reported in a new subsection of §3.2. revision: yes
-
Referee: [§4] §4 (experimental protocol): all reported results fix the support-set size at 32 and SVD rank without ablation or sensitivity analysis; this leaves open whether the claimed narrowing of the gap to task experts is an artifact of particular hyperparameter choices rather than a general property of the residual-based classifier.
Authors: We will include sensitivity ablations varying support-set size (8, 16, 32, 64, 128) and SVD rank (1–16) on the main benchmarks, showing that the gap-narrowing effect holds across reasonable ranges of these hyperparameters. revision: yes
-
Referee: [Table 2 / Figure 3] Table 2 / Figure 3 (merged-model accuracy under task-unknown inference): the gains are presented without error bars over support-set resampling or backbone feature extractor variation, making it impossible to assess whether the improvements are statistically reliable or sensitive to the weakest assumption that 32-example manifolds separate task distributions.
Authors: We will recompute Table 2 and Figure 3 over multiple support-set resamplings and report mean ± std error bars. A short paragraph will also discuss sensitivity to the backbone feature extractor used for manifold construction. revision: yes
Circularity Check
No circularity: explicit SVD-based residual scoring from support sets
full rationale
The paper defines SiM directly as computing per-task low-rank manifolds via SVD on a small support set (e.g., 32 examples) and routing test inputs by explicit projection residuals ||(I - U_k U_k^T) f(x)||. This construction is the method itself; no parameter is fitted on one subset and then invoked as a 'prediction' of a related quantity, no self-citation chain justifies a uniqueness claim or ansatz, and no known result is merely renamed. The derivation chain consists of the stated algorithmic steps with no reduction to inputs by construction. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- support set size
- SVD approximation rank
axioms (1)
- standard math Singular value decomposition produces the optimal low-rank approximation in the Frobenius norm
invented entities (1)
-
task manifold
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Learning to Recover Task Experts from a Multi-Task Merged Model
ReTeX predicts additive offsets to undo merging interference and uses an SVD subspace signature task identifier to recover over 95% of expert performance while improving generalization to unseen tasks.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.08774 (2023)
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[2]
In: ICCCSP (2021)
Ahmed, M.I., Mamun, S.M., Asif, A.U.Z.: Dcnn-based vegetable image classifica- tion using transfer learning: A comparative study. In: ICCCSP (2021)
2021
-
[3]
Data in Brief (2023)
Ahmed, S.I., Ibrahim, M., Nadim, M., Rahman, M.M., Shejunti, M.M., Jabid, T., Ali, M.S.: Mangoleafbd: A comprehensive image dataset to classify diseased and healthy mango leaves. Data in Brief (2023)
2023
-
[4]
Alessio, C.: Animals-10.https://www.kaggle.com/datasets/alessiocorrado99/ animals10
-
[5]
In: NeurIPS (2019)
Ansuini, A., Laio, A., Macke, J.H., Zoccolan, D.: Intrinsic dimension of data rep- resentations in deep neural networks. In: NeurIPS (2019)
2019
-
[6]
Available on https://www
Bansal, P.: Intel image classification. Available on https://www. kaggle. com/puneet6060/intel-image-classification, Online (2019)
2019
-
[7]
In: ECCV (2014)
Bossard, L., Guillaumin, M., Gool, L.V.: Food-101 – mining discriminative com- ponents with random forests. In: ECCV (2014)
2014
-
[8]
In: NeurIPS (2020)
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Win- ter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford...
2020
-
[9]
CCHANG: Garbage classification.https://www.kaggle.com/ds/81794(2018)
2018
-
[10]
Proceedings of the IEEE (2017)
Cheng, G., Han, J., Lu, X.: Remote sensing image scene classification: Benchmark and state of the art. Proceedings of the IEEE (2017)
2017
-
[11]
In: CVPR (2020)
Choi, Y., Uh, Y., Yoo, J., Ha, J.W.: Stargan v2: Diverse image synthesis for mul- tiple domains. In: CVPR (2020)
2020
-
[12]
In: CVPR (2014)
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., Vedaldi, A.: Describing textures in the wild. In: CVPR (2014)
2014
-
[13]
arXiv preprint arXiv:1812.01718 (2018)
Clanuwat, T., Bober-Irizar, M., Kitamoto, A., Lamb, A., Yamamoto, K., Ha, D.: Deep learning for classical japanese literature. arXiv preprint arXiv:1812.01718 (2018)
Pith/arXiv arXiv 2018
-
[14]
In: AISTATS (2011)
Coates, A., Ng, A., Lee, H.: An analysis of single-layer networks in unsupervised feature learning. In: AISTATS (2011)
2011
-
[15]
In: IJCNN (2017)
Cohen, G., Afshar, S., Tapson, J., Schaik, A.v.: Emnist: Extending mnist to hand- written letters. In: IJCNN (2017)
2017
-
[16]
Journal of Diabetes Science and Technology (2009) 16 J
Cuadros, J., Bresnick, G.: Eyepacs: An adaptable telemedicine system for diabetic retinopathy screening. Journal of Diabetes Science and Technology (2009) 16 J. Son et al
2009
-
[17]
cats.https://kaggle.com/competitions/dogs-vs-cats (2013)
Cukierski, W.: Dogs vs. cats.https://kaggle.com/competitions/dogs-vs-cats (2013)
2013
-
[18]
DeepNets: Landscape recognition.https : / / www . kaggle . com / datasets / utkarshsaxenadn/landscape-recognition-image-dataset-12k-images
-
[19]
IEEE Signal Processing Magazine (SPM) (2012)
Deng, L.: The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Processing Magazine (SPM) (2012)
2012
-
[20]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[21]
Computer Vision and Image Understanding (2007)
Fei-Fei, L., Fergus, R., Perona, P.: Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object cate- gories. Computer Vision and Image Understanding (2007)
2007
-
[22]
In: NeurIPS (2022)
Feng, R., Zheng, K., Huang, Y., Zhao, D., Jordan, M., Zha, Z.J.: Rank diminishing in deep neural networks. In: NeurIPS (2022)
2022
-
[23]
arXiv preprint arXiv:2412.00081 (2024)
Gargiulo, A.A., Crisostomi, D., Bucarelli, M.S., Scardapane, S., Silvestri, F., Rodolà, E.: Task singular vectors: Reducing task interference in model merging. arXiv preprint arXiv:2412.00081 (2024)
arXiv 2024
-
[24]
In: ICONIP (2013)
Goodfellow, I.J., Erhan, D., Carrier, P.L., Courville, A., Mirza, M., Hamner, B., Cukierski, W., Tang, Y., Thaler, D., Lee, D.H., Zhou, Y., Ramaiah, C., Feng, F., Li, R., Wang, X., Athanasakis, D., Shawe-Taylor, J., Milakov, M., Park, J., Ionescu, R., Popescu, M., Grozea, C., Bergstra, J., Xie, J., Romaszko, L., Xu, B., Chuang, Z., Bengio, Y.: Challenges ...
2013
-
[25]
Griffin, G., Holub, A., Perona, P.: Caltech-256 object category dataset. Tech. rep., California Institute of Technology (2007)
2007
-
[26]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2019)
Helber, P., Bischke, B., Dengel, A., Borth, D.: Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2019)
2019
-
[27]
In: CVPR (2015)
Horn, G.V., Branson, S., Farrell, R., Haber, S., Barry, J., Ipeirotis, P., Perona, P., Belongie, S.: Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection. In: CVPR (2015)
2015
-
[28]
Howard, J.: Imagenette: A smaller subset of 10 easily classified classes from ima- genet.https://github.com/fastai/imagenette(2019)
2019
-
[29]
In: NeurIPS (2024)
Huang, C., Ye, P., Chen, T., He, T., Yue, X., Ouyang, W.: Emr-merging: Tuning- free high-performance model merging. In: NeurIPS (2024)
2024
-
[30]
In: ICLR (2023)
Ilharco, G., Tulio Ribeiro, M., Wortsman, M., Gururangan, S., Schmidt, L., Ha- jishirzi, H., Farhadi, A.: Editing models with task arithmetic. In: ICLR (2023)
2023
-
[31]
In: ICLR (2025)
Iurada, L., Ciccone, M., Tommasi, T.: Efficient model editing with task-localized sparse fine-tuning. In: ICLR (2025)
2025
-
[32]
In: ICLR (2023)
Jin, X., Ren, X., Preotiuc-Pietro, D., Cheng, P.: Dataless knowledge fusion by merging weights of language models. In: ICLR (2023)
2023
-
[33]
Cell (2018)
Kermany, D.S., Goldbaum, M., Cai, W., Valentim, C.C.S., Liang, H., Baxter, S.L., McKeown, A., Yang, G., Wu, X., Yan, F., Dong, J., Prasadha, M., Pei, J., Ting, M., Zhu, J., Li, C., Hewett, S., Dong, J., Ziyar, I., Shi, A., Zhang, R., Gupta, K., Wong, R.M.Y., Lam, L.A.T.C., Cheung, J., Tsoi, M., Wu, V., Yan, C., Huang, C., Lee, D.H., Zhang, Y., Wong, J.W.,...
2018
-
[34]
In: CVPR (2011) Training-free Task Classification for Multi-Task Model Merging 17
Khosla, A., Jayadevaprakash, N., Yao, B., Fei-Fei, L.: Novel dataset for fine-grained image categorization. In: CVPR (2011) Training-free Task Classification for Multi-Task Model Merging 17
2011
-
[35]
In: AAAI (2020)
Khot, T., Clark, P., Guerquin, M., Jansen, P., Sabharwal, A.: Qasc: A dataset for question answering via sentence composition. In: AAAI (2020)
2020
-
[36]
In: ICCV Workshop (2013)
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3d object representations for fine- grained categorization. In: ICCV Workshop (2013)
2013
-
[37]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
2009
-
[38]
In: ECCV (2012)
Kumar, N., Belhumeur, P.N., Biswas, A., Jacobs, D.W., Kress, W.J., Lopez, I.C., Soares, J.V.B.: Leafsnap: A computer vision system for automatic plant species identification. In: ECCV (2012)
2012
-
[39]
Lab, M.A.: Bean disease dataset (2020),https://github.com/AI-Lab-Makerere/ ibean
2020
-
[40]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2005)
Lee, K.C., Ho, J., Kriegman, D.J.: Acquiring linear subspaces for face recogni- tion under variable lighting. IEEE Transactions on Pattern Analysis and Machine Intelligence (2005)
2005
-
[41]
In: ICLR (2025)
Lee, Y., Jung, J., Baik, S.: Mitigating parameter interference in model merging via sharpness-aware fine-tuning. In: ICLR (2025)
2025
-
[42]
In: KR (2012)
Levesque, H., Davis, E., Morgenstern, L.: The winograd schema challenge. In: KR (2012)
2012
-
[43]
In: CVPR (2017)
Li, S., Deng, W., Du, J.: Reliable crowdsourcing and deep locality-preserving learn- ing for expression recognition in the wild. In: CVPR (2017)
2017
-
[44]
arXiv preprint arXiv:2206.11404 (2022)
Liao, P., Li, X., Liu, X., Keutzer, K.: The artbench dataset: Benchmarking gener- ative models with artworks. arXiv preprint arXiv:2206.11404 (2022)
arXiv 2022
-
[45]
Liu, Z., He, K.: A decade’s battle on dataset bias: Are we there yet? In: ICLR (2025)
2025
-
[46]
In: NeurIPS (2024)
Lu, Z., Fan, C., Wei, W., Qu, X., Chen, D., Cheng, Y.: Twin-merging: Dynamic integration of modular expertise in model merging. In: NeurIPS (2024)
2024
-
[47]
arXiv preprint arXiv:1306.5151 (2013)
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151 (2013)
Pith/arXiv arXiv 2013
-
[48]
In: ICML (2025)
Marczak, D., Magistri, S., Cygert, S., Twardowski, B., Bagdanov, A.D., van de Weijer, J.: No task left behind: Isotropic model merging with common and task- specific subspaces. In: ICML (2025)
2025
-
[49]
In: NeurIPS (2022)
Matena, M., Raffel, C.: Merging models with fisher-weighted averaging. In: NeurIPS (2022)
2022
-
[50]
Frontiers in Plant Science (2016)
Mohanty, S.P., Hughes, D.P., Salathé, M.: Using deep learning for image-based plant disease detection. Frontiers in Plant Science (2016)
2016
-
[51]
Acta Universitatis Sapientiae, Informatica (2018)
Muresan, H., Oltean, M.: Fruit recognition from images using deep learning. Acta Universitatis Sapientiae, Informatica (2018)
2018
-
[52]
Nagaraj, A.: Asl alphabet.https://www.kaggle.com/datasets/grassknoted/ asl-alphabet
-
[53]
In: NIPS Workshop (2011)
Netzer, Y., Coates, A., Wu, B., Wang, T., Ng, A.Y.: Reading digits in natural images with unsupervised feature learning. In: NIPS Workshop (2011)
2011
-
[54]
In: ICVGIP (2008)
Nilsback, M.E., Zisserman, A.: Automated flower classification over a large number of classes. In: ICVGIP (2008)
2008
-
[55]
In: ICLR (2025)
Oh, C., Li, Y., Song, K., Yun, S., Han, D.: Dawin: Training-free dynamic weight interpolation for robust adaptation. In: ICLR (2025)
2025
-
[56]
Sci- entific Reports (2019)
Olsen, A., Konovalov, D.A., Philippa, B., Ridd, P., Wood, J.C., Johns, J., Banks, W., Girgenti, B., Kenny, O., Whinney, J., Calvert, B., Rahimi Azghadi, M., White, R.D.: Deepweeds: A multiclass weed species image dataset for deep learning. Sci- entific Reports (2019)
2019
-
[57]
In: NeurIPS (2023) 18 J
Ortiz-Jimenez, G., Favero, A., Frossard, P.: Task arithmetic in the tangent space: Improved editing of pre-trained models. In: NeurIPS (2023) 18 J. Son et al
2023
-
[58]
In: CVPR (2012)
Parkhi, O.M., Vedaldi, A., Zisserman, A., Jawahar, C.V.: Cats and dogs. In: CVPR (2012)
2012
-
[59]
In: ACM MMSys (2017)
Pogorelov, K., Randel, K.R., Griwodz, C., Eskeland, S.L., de Lange, T., Johansen, D., Spampinato, C., Dang-Nguyen, D.T., Lux, M., Schmidt, P.T., et al.: Kvasir: A multi-class image dataset for computer aided gastrointestinal disease detection. In: ACM MMSys (2017)
2017
-
[60]
In: CVPR (2009)
Quattoni, A., Torralba, A.: Recognizing indoor scenes. In: CVPR (2009)
2009
-
[61]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[62]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners (2019)
2019
-
[63]
In: JMLR (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.: Exploring the limits of transfer learning with a unified text-to-text transformer. In: JMLR (2020)
2020
-
[64]
In: AAAI (2020)
Sakaguchi, K., Bras, R.L., Bhagavatula, C., Choi, Y.: Winogrande: An adversarial winograd schema challenge at scale. In: AAAI (2020)
2020
-
[65]
In: ACL (2018)
Sharma, R., Allen, J., Bakhshandeh, O., Mostafazadeh, N.: Tackling the story ending biases in the story cloze test. In: ACL (2018)
2018
-
[66]
arXiv preprint arXiv:2506.16506 (2025)
Skorobogat, R., Roth, K., Georgescu, M.I.: Subspace-boosted model merging. arXiv preprint arXiv:2506.16506 (2025)
arXiv 2025
-
[67]
In: EMNLP (2013)
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C.D., Ng, A., Potts, C.: Recursive deep models for semantic compositionality over a sentiment treebank. In: EMNLP (2013)
2013
-
[68]
In: IJCNN (2011)
Stallkamp, J., Schlipsing, M., Salmen, J., Igel, C.: The german traffic sign recog- nition benchmark: a multi-class classification competition. In: IJCNN (2011)
2011
-
[69]
In: EMNLP (2019)
Tafjord, O., Gardner, M., Lin, K., Clark, P.: Quartz: An open-domain dataset of qualitative relationship questions. In: EMNLP (2019)
2019
-
[70]
In: ICML (2024)
Tang, A., Shen, L., Luo, Y., Yin, N., Zhang, L., Tao, D.: Merging multi-task models via weight-ensembling mixture of experts. In: ICML (2024)
2024
-
[71]
In: CVPR (2011)
Torralba, A., Efros, A.A.: Unbiased look at dataset bias. In: CVPR (2011)
2011
-
[72]
arXiv preprint arXiv:2302.13971 (2023)
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., Lample, G.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
Pith/arXiv arXiv 2023
-
[73]
In: MICCAI (2018)
Veeling, B.S., Linmans, J., Winkens, J., Cohen, T., Welling, M.: Rotation equiv- ariant cnns for digital pathology. In: MICCAI (2018)
2018
-
[74]
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The caltech-ucsd birds-200-2011 dataset. Tech. rep., California Institute of Technology (2011)
2011
-
[75]
In: ICML (2024)
Wang, K., Dimitriadis, N., Ortiz-Jimenez, G., Fleuret, F., Frossard, P.: Localizing task information for improved model merging and compression. In: ICML (2024)
2024
-
[76]
In: ICLR (2022)
Wei, J., Bosma, M., Zhao, V.Y., Guu, K., Yu, A.W., Lester, B., Du, N., Dai, A.M., Le, Q.V.: Finetuned language models are zero-shot learners. In: ICLR (2022)
2022
-
[77]
In: ICML (2025)
Wei, Y., Tang, A., Shen, L., Hu, Z., Yuan, C., Cao, X.: Modeling multi-task model merging as adaptive projective gradient descent. In: ICML (2025)
2025
-
[78]
In: CVPR (2022)
Wortsman, M., Ilharco, G., Kim, J.W., Li, M., Kornblith, S., Roelofs, R., Gontijo- Lopes, R., Hajishirzi, H., Farhadi, A., Namkoong, H., Schmidt, L.: Robust fine- tuning of zero-shot models. In: CVPR (2022)
2022
-
[79]
IEEE Transactions on Geoscience and Remote Sensing (2017) Training-free Task Classification for Multi-Task Model Merging 19
Xia, G.S., Hu, J., Hu, F., Shi, B., Bai, X., Zhong, Y., Zhang, L., Lu, X.: Aid: A benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing (2017) Training-free Task Classification for Multi-Task Model Merging 19
2017
-
[80]
Xiao, H., Zhang, F., Shen, Z., Wu, K., Zhang, J.: Classification of weather phe- nomenonfromimagesbyusingdeepconvolutionalneuralnetwork.EarthandSpace Science (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.