Scenario-based Probing and Steering Cultural Values in Large Language Models--Extended Version
Pith reviewed 2026-06-27 13:15 UTC · model grok-4.3
The pith
Large language models display entangled cultural dimensions that resist independent steering even when probed through behavioral scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
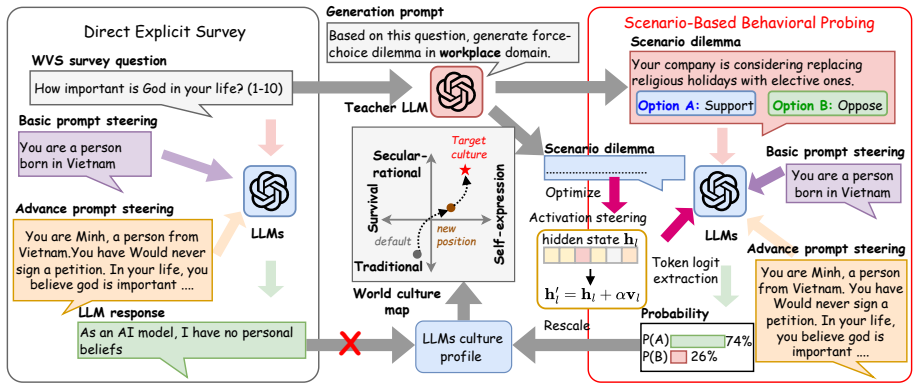
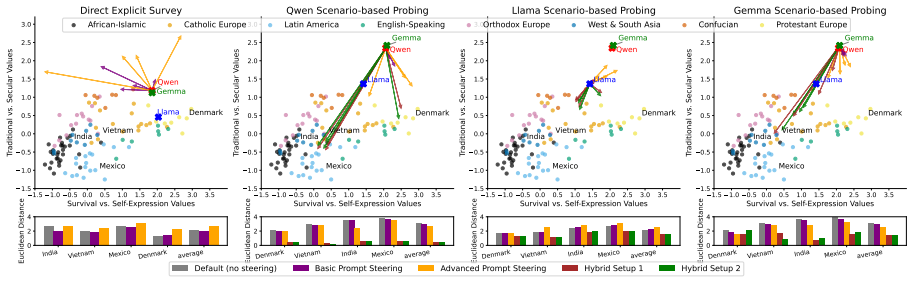
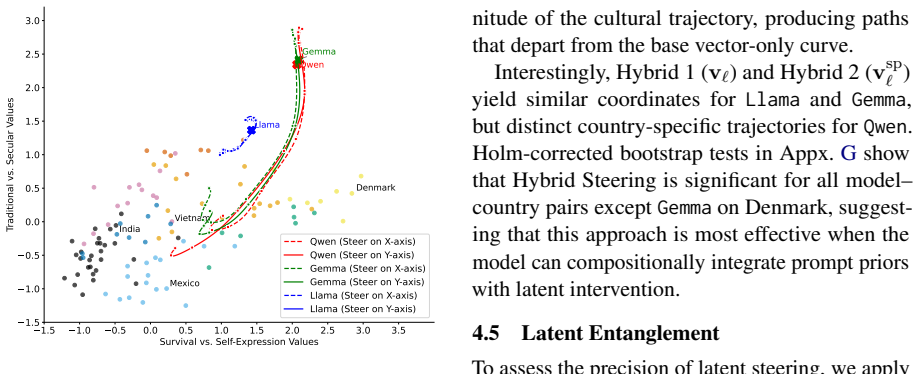
By converting value questions into behavioral scenarios, the authors extract implicit cultural preferences from LLMs via token-level probabilities. Activation steering and prompt conditioning demonstrate that the two main cultural dimensions can be influenced, yet shifts along one dimension reliably produce changes along the other, replicating human survey correlations across steering techniques and thereby constraining axis-independent alignment.
What carries the argument
Scenario-based behavioral dilemmas that elicit token-level probabilities to represent implicit cultural values, combined with activation steering to modify them.
If this is right
- Steerability varies substantially across models and target cultures.
- Entanglement between dimensions persists under activation, prompt, and hybrid steering.
- General task performance remains largely preserved after steering interventions.
- Independent alignment along separate cultural dimensions is constrained by the observed couplings.
Where Pith is reading between the lines
- Alignment methods may need to address correlated dimensions jointly rather than treating them as separable targets.
- The scenario approach could be applied to measure values beyond the two dimensions studied here.
- If the entanglement reflects training data patterns, it might appear in other value frameworks as well.
Load-bearing premise
Token probabilities from scenario dilemmas directly capture the model's internal cultural representations instead of being dominated by safety training or prompt effects.
What would settle it
A new model or culture where steering one dimension produces no measurable shift in the other while still achieving the targeted behavioral change would falsify the entanglement claim.
Figures

read the original abstract
Large Language Models (LLMs) are deployed across cultural contexts but often reflect homogenized values inherited from training data. Evaluations of cultural alignment typically rely on direct prompting with survey-style questions, which frequently elicit neutral or safety-aligned responses and fail to capture underlying model preferences. We propose a framework for probing and steering latent cultural representations in LLMs along the two Inglehart--Welzel axes of the World Values Survey (WVS). By translating social value questions into scenario-based behavioral dilemmas, we extract token-level probabilities to measure implicit values and apply activation steering, optionally combined with country-conditioned prompting, to shift model behavior without retraining. Across three open-source LLMs and four target cultures, we find substantial variation in steerability and identify latent entanglement, where interventions along one cultural dimension induce shifts along another. This coupling mirrors correlations in human WVS data and persists across activation, prompt, and hybrid steering. It constrains axis-independent alignment, though general task performance is largely preserved.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for probing and steering latent cultural values in LLMs along the Inglehart-Welzel axes of the World Values Survey. Survey questions are translated into scenario-based behavioral dilemmas to extract token-level probabilities as measures of implicit values. Activation steering (with optional country-conditioned prompting or hybrid combinations) is applied to shift behaviors without retraining. Experiments across three open-source LLMs and four target cultures report variation in steerability, latent entanglement between dimensions that mirrors human WVS correlations, and persistence of this coupling across steering methods, which constrains axis-independent alignment while largely preserving general task performance.
Significance. If substantiated with appropriate controls and quantitative detail, the work would contribute to cultural alignment research by showing that cultural dimensions are coupled in LLM representations in ways that limit independent steering. The scenario-based approach is a constructive alternative to direct survey prompting. The multi-model, multi-culture, multi-method design and explicit comparison to human WVS correlations are strengths that would support broader implications for culturally sensitive LLM deployment.
major comments (2)
- [Abstract] Abstract: the main findings on steerability variation and latent entanglement are stated without any quantitative results, error bars, controls for confounds, or statistical tests, so it is not possible to judge whether the entanglement claim is robustly supported by the data.
- [Probing framework (Section 3)] Probing framework (Section 3): the central claim that interventions reveal latent entanglement mirroring WVS correlations requires that token probabilities on the translated dilemmas isolate implicit cultural values. No controls (e.g., neutral scenarios, direct WVS item comparisons, or safety-ablated model ablations) are described to rule out dominance by safety fine-tuning or prompt artifacts; without these, the measured coupling and the conclusion that axis-independent alignment is constrained do not necessarily follow.
minor comments (2)
- [Results section] Results section: all reported probability shifts and entanglement metrics should include the number of scenarios, sampling details, and any multiple-comparison corrections applied.
- [Figures] Figure captions: clarify how the activation vectors are constructed and whether they are computed per model or shared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where quantitative support and controls can strengthen the manuscript. We address each major comment below and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the main findings on steerability variation and latent entanglement are stated without any quantitative results, error bars, controls for confounds, or statistical tests, so it is not possible to judge whether the entanglement claim is robustly supported by the data.
Authors: We agree that the abstract would be more informative with quantitative anchors. In the revision we will add key results including the observed Pearson correlations between Inglehart-Welzel dimensions (with p-values), mean steerability deltas and standard errors across the three models, and a brief note on the statistical tests performed. These additions will allow readers to evaluate the robustness of the entanglement findings directly from the abstract. revision: yes
-
Referee: [Probing framework (Section 3)] Probing framework (Section 3): the central claim that interventions reveal latent entanglement mirroring WVS correlations requires that token probabilities on the translated dilemmas isolate implicit cultural values. No controls (e.g., neutral scenarios, direct WVS item comparisons, or safety-ablated model ablations) are described to rule out dominance by safety fine-tuning or prompt artifacts; without these, the measured coupling and the conclusion that axis-independent alignment is constrained do not necessarily follow.
Authors: The scenario-based dilemmas were chosen precisely to move beyond the safety-aligned or neutral responses typical of direct survey items. The fact that the measured inter-dimension couplings closely reproduce the pattern of human WVS correlations provides convergent evidence that the token probabilities capture culturally relevant variance. Nevertheless, we accept that explicit controls would increase confidence. We will insert a dedicated subsection in Section 3 that reports (i) results on neutral scenario baselines and (ii) side-by-side comparisons with direct WVS item prompting. We will also expand the discussion to address possible safety fine-tuning confounds and how the consistency of entanglement across activation, prompt, and hybrid steering methods helps mitigate prompt-artifact concerns. Safety-ablated ablations are not feasible with the publicly released models used in this study; we will note this limitation explicitly. revision: partial
Circularity Check
No circularity; empirical measurements independent of inputs
full rationale
The paper describes an empirical framework that translates WVS questions into behavioral scenarios, extracts token probabilities from LLMs, applies activation/prompt/hybrid steering, and reports observed variations and entanglements across three models and four cultures. These results are compared to external human WVS correlations rather than derived from any fitted parameters, self-referential equations, or self-citations that would reduce the claims to their own inputs by construction. No load-bearing steps match the enumerated circularity patterns; the derivation chain consists of independent experimental observations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs encode cultural values in latent representations that can be accessed through token probabilities in behavioral scenarios.
- domain assumption Activation steering can modify these representations in a targeted way without retraining or destroying general capabilities.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
From Surveys to Narratives: Rethinking Cultural Value Adaptation in LLMs , author =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
-
[2]
Turner and Luis Espinosa Anke , year = 2026, booktitle =
Zara Siddique and Irtaza Khalid and Liam D. Turner and Luis Espinosa Anke , year = 2026, booktitle =. Shifting Perspectives: Steering Vectors for Robust Bias Mitigation in
2026
-
[3]
Kai Chen and Zihao He and Taiwei Shi and Kristina Lerman , year = 2025, booktitle =
2025
-
[4]
They Are Uncultured
Preetam Prabhu Srikar Dammu and Hayoung Jung and Anjali Singh and Monojit Choudhury and Tanushree Mitra , year = 2024, booktitle =. "They Are Uncultured": Unveiling Covert Harms and Social Threats in
2024
-
[5]
CoRR , volume =
Persona Vectors: Monitoring and Controlling Character Traits in Language Models , author =. CoRR , volume =
-
[6]
Turner and Luis Espinosa Anke , year = 2025, booktitle =
Zara Siddique and Liam D. Turner and Luis Espinosa Anke , year = 2025, booktitle =. Dialz:
2025
-
[7]
Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
The Echoes of Multilinguality: Tracing Cultural Value Shifts during Language Model Fine-tuning , author =. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[8]
CoRR , volume =
Cultural Bias and Cultural Alignment of Large Language Models , author =. CoRR , volume =
-
[9]
Ke Zhou and Marios Constantinides and Daniele Quercia , year = 2025, journal =. Should
2025
-
[10]
Adaptive Activation Steering:
Tianlong Wang and Xianfeng Jiao and Yinghao Zhu and Zhongzhi Chen and Yifan He and Xu Chu and Junyi Gao and Yasha Wang and Liantao Ma , year = 2025, booktitle =. Adaptive Activation Steering:
2025
-
[11]
CoRR , volume =
Entangled in Representations: Mechanistic Investigation of Cultural Biases in Large Language Models , author =. CoRR , volume =
-
[12]
Abdelzaher and Yejin Choi and Manling Li and Huajie Shao , year = 2026, journal =
Hongjue Zhao and Haosen Sun and Jiangtao Kong and Xiaochang Li and Qineng Wang and Liwei Jiang and Qi Zhu and Tarek F. Abdelzaher and Yejin Choi and Manling Li and Huajie Shao , year = 2026, journal =. ODESteer:
2026
-
[13]
CoRR , volume =
Localized Cultural Knowledge is Conserved and Controllable in Large Language Models , author =. CoRR , volume =
-
[14]
Guiding Giants: Lightweight Controllers for Weighted Activation Steering in
Amr Hegazy and Mostafa Elhoushi and Amr Al. Guiding Giants: Lightweight Controllers for Weighted Activation Steering in. CoRR , volume =
-
[15]
CLaS-Bench:
Daniil Gurgurov and Yusser Al Ghussin and Tanja Baeumel and Cheng. CLaS-Bench:. CoRR , volume =
-
[16]
Hate Personified: Investigating the role of
Sarah Masud and Sahajpreet Singh and Viktor Hangya and Alexander Fraser and Tanmoy Chakraborty , year = 2024, booktitle =. Hate Personified: Investigating the role of
2024
-
[17]
Presumed Cultural Identity: How Names Shape
Siddhesh Pawar and Arnav Arora and Lucie. Presumed Cultural Identity: How Names Shape. Findings of the Association for Computational Linguistics (Findings of EMNLP) , pages =
-
[18]
beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework , author =
-
[19]
CoRR , volume =
No Language Left Behind: Scaling Human-Centered Machine Translation , author =. CoRR , volume =
-
[20]
Towards Measuring and Modeling "Culture" in
Muhammad Farid Adilazuarda and Sagnik Mukherjee and Pradhyumna Lavania and Siddhant Singh and Alham Fikri Aji and Jacki O'Neill and Ashutosh Modi and Monojit Choudhury , year = 2024, booktitle =. Towards Measuring and Modeling "Culture" in
2024
-
[21]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Break the Checkbox: Challenging Closed-Style Evaluations of Cultural Alignment in LLMs , author =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
-
[22]
Questioning the Survey Responses of Large Language Models , author =
-
[23]
Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Multilingual LLMs are Better Cross-lingual In-context Learners with Alignment , author =. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[24]
Findings of the Association for Computational Linguistics (Findings of EACL) , pages =
Probing Critical Learning Dynamics of PLMs for Hate Speech Detection , author =. Findings of the Association for Computational Linguistics (Findings of EACL) , pages =
-
[25]
Shivalika Singh and Angelika Romanou and Cl. Global. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[26]
Expert Personas Improve
Zizhao Hu and Mohammad Rostami and Jesse Thomason , year = 2026, journal =. Expert Personas Improve
2026
-
[27]
CoRR , volume =
Prompt Programming for Cultural Bias and Alignment of Large Language Models , author =. CoRR , volume =
-
[31]
EVS Trend File 1981-2017 , year =
1981
-
[32]
and Inglehart, R
Haerpfer, C. and Inglehart, R. and Moreno, A. and Welzel, C. and Kizilova, K. and Diez-Medrano, J. and Lagos, M. and Norris, P. and Ponarin, E. and Puranen, B. , title =. 2022 , publisher =
2022
-
[33]
Institutions, Institutional Change and Economic Performance , author =
-
[34]
Modernization, Cultural Change, and the Persistence of Traditional Values , volume =
Ronald, Inglehart and Baker, Wayne , year =. Modernization, Cultural Change, and the Persistence of Traditional Values , volume =. American Sociological Review , doi =
-
[35]
Inglehart
Ronald L. Inglehart. Human Values and Social Change: Findings from the Values Surveys. 2003
2003
-
[37]
Findings of the Association for Computational Linguistics (Findings of ACL) , pages =
Xiaoyu Li and Haoran Shi and Zengyi Yu and Yukun Tu and Chanjin Zheng , title =. Findings of the Association for Computational Linguistics (Findings of ACL) , pages =
-
[38]
Putting Judging Situations Into Situational Judgment Tests: Evidence From Intercultural Multimedia SJTs , volume =
Rockstuhl, Thomas and Ang, Soon and Ng, Kok-Yee and Lievens, Filip and Van Dyne, Linn , year =. Putting Judging Situations Into Situational Judgment Tests: Evidence From Intercultural Multimedia SJTs , volume =. Journal of Applied Psychology , doi =
-
[39]
Greene and R
Joshua D. Greene and R. Brian Sommerville and Leigh E. Nystrom and John M. Darley and Jonathan D. Cohen , title =. Science , volume =. 2001 , doi =
2001
-
[40]
Transactions of the Association for Computational Linguistics
Cohen, Roi and Biran, Eden and Yoran, Ori and Globerson, Amir and Geva, Mor. Transactions of the Association for Computational Linguistics. 2024
2024
-
[41]
Findings of the Association for Computational Linguistics (Findings of ACL)
Yang, Wanli and Sun, Fei and Ma, Xinyu and Liu, Xun and Yin, Dawei and Cheng, Xueqi. Findings of the Association for Computational Linguistics (Findings of ACL). 2024
2024
-
[42]
Muhammad Farid Adilazuarda, Chen Cecilia Liu, Iryna Gurevych, and Alham Fikri Aji. 2025. From surveys to narratives: Rethinking cultural value adaptation in llms. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 18052--18079
2025
-
[43]
Muhammad Farid Adilazuarda, Sagnik Mukherjee, Pradhyumna Lavania, Siddhant Singh, Alham Fikri Aji, Jacki O'Neill, Ashutosh Modi, and Monojit Choudhury. 2024. Towards measuring and modeling "culture" in LLM s: A survey. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 15763--15784
2024
-
[44]
Kai Chen, Zihao He, Taiwei Shi, and Kristina Lerman. 2025 a . STEER-BENCH: A benchmark for evaluating the steerability of large language models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 18327--18355
2025
-
[45]
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. 2025 b . Persona vectors: Monitoring and controlling character traits in language models. CoRR, abs/2507.21509
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Rochelle Choenni, Anne Lauscher, and Ekaterina Shutova. 2024. The echoes of multilinguality: Tracing cultural value shifts during language model fine-tuning. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 15042--15058
2024
-
[47]
Roi Cohen, Eden Biran, Ori Yoran, Amir Globerson, and Mor Geva. 2024. Evaluating the Ripple Effects of Knowledge Editing in Language Models . Transactions of the Association for Computational Linguistics, 12:283--298
2024
-
[48]
Ricardo Dominguez - Olmedo, Moritz Hardt, and Celestine Mendler - D \" u nner. 2024. Questioning the survey responses of large language models. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS)
2024
-
[49]
European Values Study . 2022. https://doi.org/10.4232/1.14021 Evs trend file 1981-2017 . GESIS Data Archive, Cologne. Data file Version 3.0.0
-
[50]
EVS. 2022. https://doi.org/10.4232/1.13897 European values study 2017: Integrated dataset (evs 2017) . (ZA7500; Version 5.0.0) [Data set]. GESIS, Cologne. https://doi.org/10.4232/1.13897
-
[51]
Joshua D. Greene, R. Brian Sommerville, Leigh E. Nystrom, John M. Darley, and Jonathan D. Cohen. 2001. https://doi.org/10.1126/science.1062872 An fmri investigation of emotional engagement in moral judgment . Science, 293(5537):2105--2108
-
[52]
C. Haerpfer, R. Inglehart, A. Moreno, C. Welzel, K. Kizilova, J. Diez-Medrano, M. Lagos, P. Norris, E. Ponarin, and B. Puranen. 2022 a . https://doi.org/10.14281/18241.27 World values survey trend file (1981-2022) cross-national data-set . Data file Version 4.1.0
-
[53]
C. Haerpfer, R. Inglehart, A. Moreno, C. Welzel, K. Kizilova, J. Diez-Medrano, M. Lagos, P. Norris, E. Ponarin, and B. Puranen. 2022 b . https://doi.org/10.14281/18241.18 World values survey wave 7 (2017-2022) cross-national data-set . Version: 4.0.0
-
[54]
Burgess, Xavier Glorot, Matthew M
Irina Higgins, Lo \" c Matthey, Arka Pal, Christopher P. Burgess, Xavier Glorot, Matthew M. Botvinick, Shakir Mohamed, and Alexander Lerchner. 2017. beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representations (ICLR)
2017
-
[55]
R. Inglehart, C. Haerpfer, A. Moreno, C. Welzel, K. Kizilova, J. Diez-Medrano, M. Lagos, P. Norris, E. Ponarin, and B. Puranen. 2022. https://doi.org/10.14281/18241.17 World values survey: All rounds - country-pooled datafile . Version 3.0.0
-
[56]
Ronald L. Inglehart. 2003. https://doi.org/10.1163/9789047404361 Human Values and Social Change: Findings from the Values Surveys . Brill, Leiden, The Netherlands
-
[57]
Mohsinul Kabir, Ajwad Abrar, and Sophia Ananiadou. 2025. Break the checkbox: Challenging closed-style evaluations of cultural alignment in llms. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 24--51
2025
-
[58]
Xiaoyu Li, Haoran Shi, Zengyi Yu, Yukun Tu, and Chanjin Zheng. 2025. Decoding LLM personality measurement: Forced-choice vs. likert. In Findings of the Association for Computational Linguistics (Findings of ACL), pages 9234--9247
2025
-
[59]
Shad Akhtar, and Tanmoy Chakraborty
Sarah Masud, Mohammad Aflah Khan, Vikram Goyal, Md. Shad Akhtar, and Tanmoy Chakraborty. 2024 a . Probing critical learning dynamics of plms for hate speech detection. In Findings of the Association for Computational Linguistics (Findings of EACL), pages 826--845
2024
-
[60]
Sarah Masud, Sahajpreet Singh, Viktor Hangya, Alexander Fraser, and Tanmoy Chakraborty. 2024 b . Hate personified: Investigating the role of LLM s in content moderation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 15847--15863
2024
-
[61]
Douglass C. North. 1990. Institutions, Institutional Change and Economic Performance. Political Economy of Institutions and Decisions. Cambridge University Press
1990
-
[62]
Siddhesh Pawar, Arnav Arora, Lucie - Aim \' e e Kaffee, and Isabelle Augenstein. 2025. Presumed cultural identity: How names shape LLM responses. In Findings of the Association for Computational Linguistics (Findings of EMNLP), pages 22147--22172
2025
-
[63]
Thomas Rockstuhl, Soon Ang, Kok-Yee Ng, Filip Lievens, and Linn Van Dyne. 2014. https://doi.org/10.1037/a0038098 Putting judging situations into situational judgment tests: Evidence from intercultural multimedia sjts . Journal of Applied Psychology, 100:464--480
-
[64]
Inglehart Ronald and Wayne Baker. 2000. https://doi.org/10.2307/2657288 Modernization, cultural change, and the persistence of traditional values . American Sociological Review, 65:19--51
-
[65]
Turner, and Luis Espinosa Anke
Zara Siddique, Irtaza Khalid, Liam D. Turner, and Luis Espinosa Anke. 2026. Shifting perspectives: Steering vectors for robust bias mitigation in LLM s. In Findings of the Association for Computational Linguistics (Findings of EACL), pages 809--820
2026
-
[66]
Turner, and Luis Espinosa Anke
Zara Siddique, Liam D. Turner, and Luis Espinosa Anke. 2025. Dialz: A python toolkit for steering vectors. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 363--375
2025
-
[67]
Shivalika Singh, Angelika Romanou, Cl \' e mentine Fourrier, David Ifeoluwa Adelani, Jian Gang Ngui, Daniel Vila - Suero, Peerat Limkonchotiwat, Kelly Marchisio, Wei Qi Leong, Yosephine Susanto, Raymond Ng, Shayne Longpre, Sebastian Ruder, Wei - Yin Ko, Antoine Bosselut, Alice Oh, Andr \' e F. T. Martins, Leshem Choshen, Daphne Ippolito, and 4 others. 202...
2025
-
[68]
Eshaan Tanwar, Subhabrata Dutta, Manish Borthakur, and Tanmoy Chakraborty. 2023. Multilingual llms are better cross-lingual in-context learners with alignment. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 6292--6307
2023
-
[69]
Yan Tao, Olga Viberg, Ryan S. Baker, and Rene F. Kizilcec. 2025. Cultural bias and cultural alignment of large language models. CoRR, abs/2311.14096
-
[70]
Griffiths, and Arvind Narayanan
Veniamin Veselovsky, Berke Argin, Benedikt Stroebl, Chris Wendler, Robert West, James Evans, Thomas L. Griffiths, and Arvind Narayanan. 2025. Localized cultural knowledge is conserved and controllable in large language models. CoRR, abs/2504.10191
-
[71]
Wanli Yang, Fei Sun, Xinyu Ma, Xun Liu, Dawei Yin, and Xueqi Cheng. 2024. The Butterfly Effect of Model Editing: Few Edits Can Trigger Large Language Models Collapse . In Findings of the Association for Computational Linguistics (Findings of ACL), pages 5419--5437
2024
- [72]
- [73]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.