Multi-Level Contextual Token Relation Modeling for Machine-Generated Text Detection
Pith reviewed 2026-05-20 19:03 UTC · model grok-4.3
The pith
Modeling local and global relations among token detection scores corrects randomness bias in machine-generated text detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deriving the multi-hop transitions of token-level detection scores and exploring their local and global relations, a multi-level contextual token relation modeling framework is proposed, consisting of a lightweight Markov-informed calibration module for local relations and a rule-support reasoning module for global relations, which are combined in a joint multi-level inference framework for improved MGT detection.
What carries the argument
The multi-level contextual token relation modeling framework that refines token-level evidence using local Markov calibration and global rule-support reasoning before aggregation.
If this is right
- Improved detection accuracy holds in cross-LLM and cross-domain scenarios.
- The approach maintains low computational overhead relative to model-based alternatives.
- Joint local calibration and global rule reasoning yields more stable detection signals.
- The unified framework reveals common limitations across existing metric-based detectors.
Where Pith is reading between the lines
- The same relation-modeling idea could extend to spotting generated content in other modalities such as code or images.
- Hybrid systems that layer this calibration on top of current detectors might achieve both efficiency and robustness gains.
- Further tests on entirely unseen model families would strengthen the cross-LLM generalization claim.
Load-bearing premise
The token-level detection score is easily biased by the inherent randomness of the MGT generation process, and that theoretically derived multi-hop transitions plus local/global relation modeling can reliably correct this bias before aggregation.
What would settle it
A controlled experiment on generated texts where disabling the multi-level relation modules produces no gain over simple token-score aggregation under varying randomness levels.
Figures





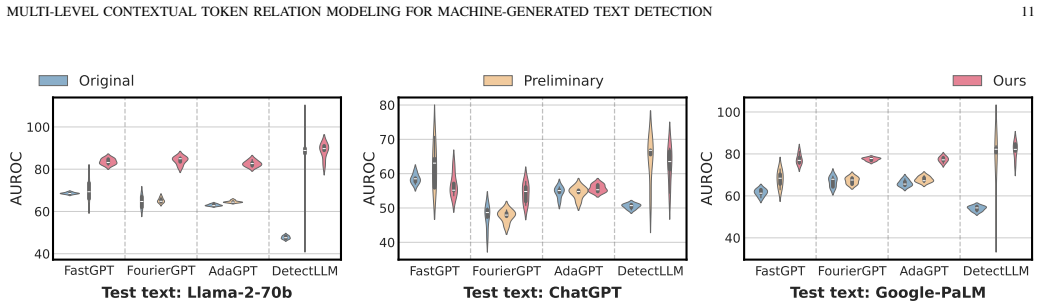




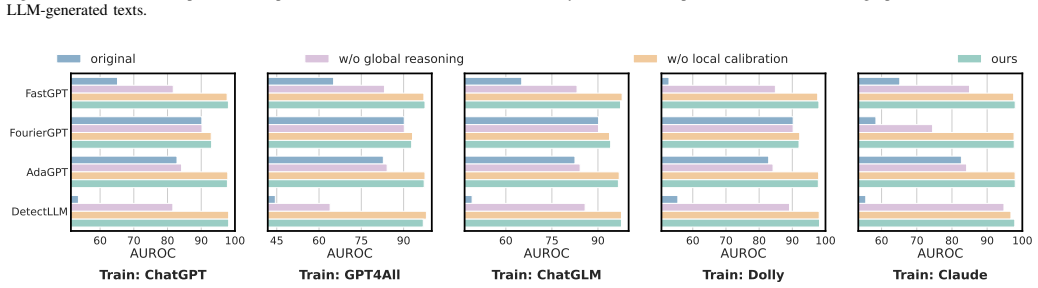

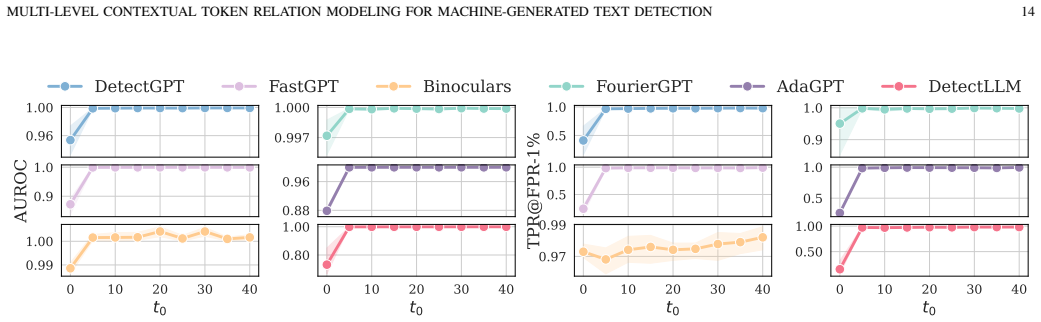
read the original abstract
Machine-generated texts (MGTs) pose risks such as disinformation and phishing, underscoring the need for reliable detection. Metric-based methods, which extract statistically distinguishable features of MGTs, are often more practical than complex model-based methods that are prone to overfitting. Given their diverse designs, we first place representative metric-based methods within a unified framework, enabling a clear assessment of their advantages and limitations. Our analysis identifies a core challenge across these methods: the token-level detection score is easily biased by the inherent randomness of the MGTs generation process. Then, we theoretically derive the multi-hop transitions of the token-level detection score and explore their local and global relations. Based on these findings, we propose a multi-level contextual token relation modeling framework for MGT detection. Specifically, for local relations, we model them through a lightweight Markov-informed calibration module that refines token-level evidence before aggregation. For global relations, we introduce a rule-support reasoning module that uses explicit logical rules derived from contextual score statistics. Finally, we combine the local calibrated score and the global rule-support reasoning signal in a joint multi-level inference framework. Extensive experiments show broad and substantial improvements across various real-world scenarios, including cross-LLM and cross-domain settings, with low computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript unifies representative metric-based methods for machine-generated text (MGT) detection under a single framework, identifies the core issue that token-level detection scores are biased by randomness in the generation process, theoretically derives multi-hop transitions of these scores along with their local and global relations, and proposes a multi-level contextual token relation modeling framework. The framework uses a lightweight Markov-informed calibration module to refine local token-level evidence before aggregation and a rule-support reasoning module that applies explicit logical rules from contextual score statistics; these signals are combined in a joint multi-level inference step. Extensive experiments are reported to demonstrate broad and substantial gains across real-world scenarios including cross-LLM and cross-domain settings, with low computational overhead.
Significance. If the theoretical derivation of the multi-hop transitions is sound and the local/global modules reliably correct the identified bias, the work would provide a practical, lightweight advance over existing metric-based detectors. It avoids the overfitting risks of model-based approaches while delivering measurable improvements in challenging transfer settings, which could be valuable for deployment in disinformation and content-moderation pipelines.
major comments (2)
- [§4] §4 (Theoretical Derivation): The multi-hop transition derivation and subsequent Markov-informed calibration module implicitly rely on stationary token-score statistics. Under modern non-stationary sampling regimes (temperature, top-p/nucleus sampling) the conditional distributions evolve within a sequence, which can break the Markov assumption used to characterize how generation randomness propagates to token scores. The paper must demonstrate, via analysis or targeted ablation, that the derived transitions remain valid or can be adapted in these regimes; otherwise the local calibration cannot be guaranteed to remove bias before the global rule-support signal is applied.
- [§6] §6 (Experiments): The claim of broad improvements across cross-LLM and cross-domain settings is central, yet the reported results do not isolate performance under varying generation hyperparameters (different temperatures or top-p values). Without such controls it is unclear whether the observed gains stem from the multi-level modeling correcting the randomness bias or from other factors; adding these ablations would directly test the load-bearing assumption identified in the weakest point of the argument.
minor comments (2)
- [Abstract / §3] The abstract and §3 would benefit from a short explicit statement of the precise baselines and metrics (e.g., AUROC, F1) used to quantify the “substantial improvements,” to allow readers to gauge effect sizes immediately.
- [§2 / §4] Notation for token-level scores, transition matrices, and rule-support signals should be introduced once in §2 or §4 and used consistently thereafter to avoid minor ambiguity when the local and global modules are combined.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the assumptions underlying our theoretical derivation and strengthen the experimental validation of our claims. We address each major comment below and outline the specific revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Derivation): The multi-hop transition derivation and subsequent Markov-informed calibration module implicitly rely on stationary token-score statistics. Under modern non-stationary sampling regimes (temperature, top-p/nucleus sampling) the conditional distributions evolve within a sequence, which can break the Markov assumption used to characterize how generation randomness propagates to token scores. The paper must demonstrate, via analysis or targeted ablation, that the derived transitions remain valid or can be adapted in these regimes; otherwise the local calibration cannot be guaranteed to remove bias before the global rule-support signal is applied.
Authors: We appreciate the referee's identification of the stationarity assumption in the multi-hop transition derivation. The Markov process is used to model local score transitions for tractable calibration of randomness bias, but we acknowledge that temperature and nucleus sampling can introduce non-stationarity in conditional distributions. Our framework's lightweight calibration module is empirically robust across the generation settings tested, yet to rigorously address this, we will add a new analysis subsection in §4 discussing adaptation of the transitions under non-stationary regimes (e.g., via time-varying transition matrices) and include targeted ablations measuring bias reduction as sampling parameters vary. These changes will clarify the scope of the local calibration's guarantees. revision: yes
-
Referee: [§6] §6 (Experiments): The claim of broad improvements across cross-LLM and cross-domain settings is central, yet the reported results do not isolate performance under varying generation hyperparameters (different temperatures or top-p values). Without such controls it is unclear whether the observed gains stem from the multi-level modeling correcting the randomness bias or from other factors; adding these ablations would directly test the load-bearing assumption identified in the weakest point of the argument.
Authors: We agree that explicit controls for generation hyperparameters are necessary to isolate the contribution of the multi-level contextual modeling and confirm that gains arise from bias correction rather than other factors. The current experiments use representative generation settings for cross-LLM and cross-domain transfer, but we will expand §6 with new ablation studies that vary temperature (e.g., 0.5, 0.8, 1.0) and top-p (e.g., 0.85, 0.95, 1.0) while reporting detection performance for our framework versus baselines. This will directly test the load-bearing assumption and demonstrate consistent improvements attributable to the local and global relation modules. revision: yes
Circularity Check
No circularity: theoretical derivation and framework remain independent of fitted outputs
full rationale
The paper first unifies existing metric-based detectors, identifies the token-level bias challenge from generation randomness, then states that it theoretically derives multi-hop transitions of the detection score before introducing local Markov calibration and global rule-support modules. No equations, self-citations, or fitted parameters are shown that would make the multi-hop derivation reduce to a re-expression of the same data or prior author results by construction. The claimed improvements rest on the subsequent empirical evaluation rather than any self-definitional or load-bearing self-citation step.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
theoretically derive the multi-hop transitions of the token-level detection score and explore their local and global relations... lightweight Markov-informed calibration module... rule-support reasoning module that uses explicit logical rules derived from contextual score statistics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
work page 2019
-
[3]
Disinformation capabilities of large language models,
I. Vykopal, M. Pikuliak, I. Srba, R. Moro, D. Macko, and M. Bielikov ´a, “Disinformation capabilities of large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2024, pp. 14 830–14 847
work page 2024
-
[4]
Codeipprompt: intellectual property infringement assessment of code language models,
Z. Yu, Y . Wu, N. Zhang, C. Wang, Y . V orobeychik, and C. Xiao, “Codeipprompt: intellectual property infringement assessment of code language models,” inProceedings of the International Conference on Machine Learning. PMLR, 2023, pp. 40 373–40 389
work page 2023
-
[5]
The state of phishing attacks,
J. Hong, “The state of phishing attacks,”Communications of the ACM, vol. 55, no. 1, pp. 74–81, 2012. MULTI-LEVEL CONTEXTUAL TOKEN RELATION MODELING FOR MACHINE-GENERATED TEXT DETECTION 15
work page 2012
-
[6]
Semstamp: A se- mantic watermark with paraphrastic robustness for text generation,
A. Hou, J. Zhang, T. He, Y . Wang, Y .-S. Chuang, H. Wang, L. Shen, B. Van Durme, D. Khashabi, and Y . Tsvetkov, “Semstamp: A se- mantic watermark with paraphrastic robustness for text generation,” in Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: L...
work page 2024
-
[7]
Release Strategies and the Social Impacts of Language Models
I. Solaiman, M. Brundage, J. Clark, A. Askell, A. Herbert-V oss, J. Wu, A. Radford, G. Krueger, J. W. Kim, S. Krepset al., “Release strategies and the social impacts of language models,”arXiv preprint arXiv:1908.09203, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[8]
How close is chatgpt to human experts? comparison corpus, evaluation, and detection,
B. Guo, X. Zhang, Z. Wang, M. Jiang, J. Nie, Y . Ding, J. Yue, and Y . Wu, “How close is chatgpt to human experts? comparison corpus, evaluation, and detection,”arXiv preprint arXiv:2301.07597, 2023
-
[9]
Seqxgpt: Sentence-level ai-generated text detection,
P. Wang, L. Li, K. Ren, B. Jiang, D. Zhang, and X. Qiu, “Seqxgpt: Sentence-level ai-generated text detection,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 1144–1156
work page 2023
-
[10]
X. Liu, Z. Zhang, Y . Wang, H. Pu, Y . Lan, and C. Shen, “Coco: Coherence-enhanced machine-generated text detection under data limita- tion with contrastive learning,”arXiv preprint arXiv:2212.10341, 2022
-
[11]
Detectgpt: Zero-shot machine-generated text detection using probability curvature,
E. Mitchell, Y . Lee, A. Khazatsky, C. D. Manning, and C. Finn, “Detectgpt: Zero-shot machine-generated text detection using probability curvature,” inProceedings of the International Conference on Machine Learning. PMLR, 2023, pp. 24 950–24 962
work page 2023
-
[12]
G. Bao, Y . Zhao, Z. Teng, L. Yang, and Y . Zhang, “Fast-detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature,” inProceedings of the Twelfth International Con- ference on Learning Representations, 2024, pp. 1–9
work page 2024
-
[13]
Spotting llms with binoc- ulars: Zero-shot detection of machine-generated text,
A. Hans, A. Schwarzschild, V . Cherepanova, H. Kazemi, A. Saha, M. Goldblum, J. Geiping, and T. Goldstein, “Spotting llms with binoc- ulars: Zero-shot detection of machine-generated text,” inProceedings of the International Conference on Machine Learning. PMLR, 2024, pp. 17 519–17 537
work page 2024
-
[14]
GLTR: Statistical Detection and Visualization of Generated Text
S. Gehrmann, H. Strobelt, and A. M. Rush, “Gltr: Statistical detection and visualization of generated text,”arXiv preprint arXiv:1906.04043, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[15]
Biscope: Ai-generated text detection by checking memorization of preceding tokens,
H. Guo, S. Cheng, X. Jin, Z. Zhang, K. Zhang, G. Tao, G. Shen, and X. Zhang, “Biscope: Ai-generated text detection by checking memorization of preceding tokens,”Proceedings of the Advances in Neural Information Processing Systems, vol. 37, pp. 104 065–104 090, 2024
work page 2024
-
[16]
Dna- detectllm: Unveiling ai-generated text via a dna-inspired mutation-repair paradigm,
X. Zhu, Y . Ren, F. Fang, Q. Tan, S. Wang, and Y . Cao, “Dna- detectllm: Unveiling ai-generated text via a dna-inspired mutation-repair paradigm,” inProceedings of the Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025, pp. 1–13
work page 2025
-
[17]
C. Wu, Y .-m. Cheung, S. Zhang, B. Han, and D. Lian, “Beyond raw detection scores: Markov-informed calibration for boosting machine- generated text detection,” inProceedings of the F ourteenth International Conference on Learning Representations, 2026, pp. 1–10
work page 2026
-
[18]
A watermark for large language models,
J. Kirchenbauer, J. Geiping, Y . Wen, J. Katz, I. Miers, and T. Gold- stein, “A watermark for large language models,” inProceedings of the International Conference on Machine Learning. PMLR, 2023, pp. 17 061–17 084
work page 2023
-
[19]
A resilient and accessible distribution-preserving watermark for large language models,
Y . Wu, Z. Hu, J. Guo, H. Zhang, and H. Huang, “A resilient and accessible distribution-preserving watermark for large language models,” inProceedings of the International Conference on Machine Learning. PMLR, 2024, pp. 53 443–53 470
work page 2024
-
[20]
{REMARK- LLM}: A robust and efficient watermarking framework for generative large language models,
R. Zhang, S. S. Hussain, P. Neekhara, and F. Koushanfar, “{REMARK- LLM}: A robust and efficient watermarking framework for generative large language models,” inProceedings of the 33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 1813–1830
work page 2024
-
[21]
Adaptive text watermark for large language mod- els,
Y . Liu and Y . Bu, “Adaptive text watermark for large language mod- els,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 30 718–30 737
work page 2024
-
[22]
GPTZero, “Gptzero official website,” [Online], 2023, https://gptzero.me
work page 2023
-
[23]
G3detector: General gpt-generated text detector,
H. Zhan, X. He, Q. Xu, Y . Wu, and P. Stenetorp, “G3detector: General gpt-generated text detector,”arXiv preprint arXiv:2305.12680, 2023
-
[24]
Llm paternity test: Generated text detection with llm genetic inheritance,
X. Yu, Y . Qi, K. Chen, G. Chen, X. Yang, P. Zhu, W. Zhang, and N. Yu, “Llm paternity test: Generated text detection with llm genetic inheritance,”arXiv preprint arXiv:2305.12519, 2023
-
[25]
Llmdet: A third party large language models generated text detection tool,
K. Wu, L. Pang, H. Shen, X. Cheng, and T.-S. Chua, “Llmdet: A third party large language models generated text detection tool,” in Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 2113–2133
work page 2023
-
[26]
Multiscale positive-unlabeled detection of ai-generated texts,
Y . Tian, H. Chen, X. Wang, Z. Bai, Q. ZHANG, R. Li, C. Xu, and Y . Wang, “Multiscale positive-unlabeled detection of ai-generated texts,” inProceedings of the Twelfth International Conference on Learning Representations, 2024, pp. 1–9
work page 2024
-
[27]
Radar: Robust ai-text detection via adversarial learning,
X. Hu, P.-Y . Chen, and T.-Y . Ho, “Radar: Robust ai-text detection via adversarial learning,”Advances in neural information processing systems, vol. 36, pp. 15 077–15 095, 2023
work page 2023
-
[28]
Ghostbuster: Detecting text ghostwritten by large language models,
V . Verma, E. Fleisig, N. Tomlin, and D. Klein, “Ghostbuster: Detecting text ghostwritten by large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), 2024, pp. 1702–1717
work page 2024
-
[29]
Detecting and grounding multi-modal media manipulation and beyond,
R. Shao, T. Wu, J. Wu, L. Nie, and Z. Liu, “Detecting and grounding multi-modal media manipulation and beyond,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5556– 5574, 2024
work page 2024
-
[30]
Detectllm: Leveraging log rank information for zero-shot detection of machine-generated text,
J. Su, T. Zhuo, D. Wang, and P. Nakov, “Detectllm: Leveraging log rank information for zero-shot detection of machine-generated text,” inProceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 12 395–12 412
work page 2023
-
[31]
Adadetectgpt: Adaptive detection of llm-generated text with statistical guarantees,
H. Zhou, J. Zhu, P. Su, K. Ye, Y . Yang, S. Gavioli-Akilagun, and C. Shi, “Adadetectgpt: Adaptive detection of llm-generated text with statistical guarantees,” inProceedings of the Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025, pp. 1–10
work page 2025
-
[32]
Dna-gpt: Divergent n-gram analysis for training-free detection of gpt- generated text,
X. Yang, W. Cheng, Y . Wu, L. R. Petzold, W. Y . Wang, and H. Chen, “Dna-gpt: Divergent n-gram analysis for training-free detection of gpt- generated text,” inProceedings of the Twelfth International Conference on Learning Representations, 2024, pp. 1–9
work page 2024
-
[33]
Zero-shot detection of machine-generated codes,
X. Yang, K. Zhang, H. Chen, L. Petzold, W. Y . Wang, and W. Cheng, “Zero-shot detection of machine-generated codes,”arXiv preprint arXiv:2310.05103, 2023
-
[34]
H.-Q. Nguyen-Son, M.-S. Dao, and K. Zettsu, “Simllm: Detecting sentences generated by large language models using similarity between the generation and its re-generation,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 22 340–22 352
work page 2024
-
[35]
Learn-to- distance: Distance learning for detecting llm-generated text,
H. Zhou, J. Zhu, K. Ye, Y . Yang, E. Xu, and C. Shi, “Learn-to- distance: Distance learning for detecting llm-generated text,”arXiv preprint arXiv:2601.21895, 2026
-
[36]
In- trinsic dimension estimation for robust detection of ai-generated texts,
E. Tulchinskii, K. Kuznetsov, L. Kushnareva, D. Cherniavskii, S. Nikolenko, E. Burnaev, S. Barannikov, and I. Piontkovskaya, “In- trinsic dimension estimation for robust detection of ai-generated texts,” Proceedings of the Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[37]
Zero-shot detection of llm-generated text using to- ken cohesiveness,
S. Ma and Q. Wang, “Zero-shot detection of llm-generated text using to- ken cohesiveness,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 17 538–17 553
work page 2024
-
[38]
Text fluoroscopy: Detecting llm-generated text through intrinsic features,
X. Yu, K. Chen, Q. Yang, W. Zhang, and N. Yu, “Text fluoroscopy: Detecting llm-generated text through intrinsic features,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 15 838–15 846
work page 2024
-
[39]
Repreguard: Detecting llm-generated text by revealing hidden representation patterns,
X. Chen, J. Wu, S. Yang, R. Zhan, Z. Wu, Z. Luo, D. Wang, M. Yang, L. S. Chao, and D. F. Wong, “Repreguard: Detecting llm-generated text by revealing hidden representation patterns,”arXiv preprint arXiv:2508.13152, 2025
-
[40]
Training-free llm-generated text detection by mining token probability sequences,
Y . Xu, Y . Wang, Y . Bi, H. Cao, Z. Lin, Y . Zhao, and F. Wu, “Training-free llm-generated text detection by mining token probability sequences,” inProceedings of the Thirteenth International Conference on Learning Representations, 2025, pp. 1–10
work page 2025
-
[41]
Y . Xu, Y . Wang, H. An, Z. Liu, and Y . Li, “Detecting subtle differences between human and model languages using spectrum of relative likeli- hood,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 10 108–10 121
work page 2024
-
[42]
J. Wu, J. Wang, Z. Liu, B. Chen, D. Hu, H. Wu, and S.-T. Xia, “Moses: Uncertainty-aware ai-generated text detection via mixture of stylistics experts with conditional thresholds,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 5797–5816
work page 2025
-
[43]
Y . He, S. Zhang, Y . Cao, L. Ma, and P. Luo, “Detree: Detecting human-ai collaborative texts via tree-structured hierarchical representation learn- ing,” inProceedings of the Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025, pp. 1–10
work page 2025
-
[44]
Human texts are outliers: Detecting llm-generated texts via out- of-distribution detection,
C. Zeng, S. Tang, Y . Chen, Z. Shen, W. Yu, X. Zhao, H. Chen, W. Cheng et al., “Human texts are outliers: Detecting llm-generated texts via out- of-distribution detection,” inProceedings of the Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025, pp. 1–10
work page 2025
-
[45]
Ipad: Inverse prompt for ai detection–a robust and explainable llm-generated text detector,
Z. Chen, Y . Feng, C. He, Y . Deng, H. Pu, and B. Li, “Ipad: Inverse prompt for ai detection–a robust and explainable llm-generated text detector,”arXiv e-prints, pp. arXiv–2502, 2025. MULTI-LEVEL CONTEXTUAL TOKEN RELATION MODELING FOR MACHINE-GENERATED TEXT DETECTION 16
work page 2025
-
[46]
Hld: Approx- imate hierarchical linguistic distribution modeling for llm-generated text detection,
R. Guo, W. Zeng, F. Wu, Y . Kong, Y . Wu, W. Donget al., “Hld: Approx- imate hierarchical linguistic distribution modeling for llm-generated text detection,” inProceedings of the F ourteenth International Conference on Learning Representations, 2026, pp. 1–10
work page 2026
-
[47]
Z. Liu, A. Desai, F. Liao, W. Wang, V . Xie, Z. Xu, A. Kyrillidis, and A. Shrivastava, “Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time,”Advances in Neural Information Processing Systems, vol. 36, pp. 52 342–52 364, 2023
work page 2023
-
[48]
Bayesian image super-resolution with deep modeling of image statistics,
S. Gao and X. Zhuang, “Bayesian image super-resolution with deep modeling of image statistics,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 2, pp. 1405–1423, 2022
work page 2022
-
[49]
Deeplogic: Joint learning of neural perception and logical reasoning,
X. Duan, X. Wang, P. Zhao, G. Shen, and W. Zhu, “Deeplogic: Joint learning of neural perception and logical reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4321– 4334, 2022
work page 2022
-
[50]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2022, pp. 3214–3252
work page 2022
-
[51]
Detectrl: Benchmarking llm-generated text detection in real-world sce- narios,
J. Wu, R. Zhan, D. Wong, S. Yang, X. Yang, Y . Yuan, and L. Chao, “Detectrl: Benchmarking llm-generated text detection in real-world sce- narios,”Proceedings of the Advances in Neural Information Processing Systems, vol. 37, pp. 100 369–100 401, 2024
work page 2024
-
[52]
Para- phrasing evades detectors of ai-generated text, but retrieval is an effective defense,
K. Krishna, Y . Song, M. Karpinska, J. Wieting, and M. Iyyer, “Para- phrasing evades detectors of ai-generated text, but retrieval is an effective defense,”Proceedings of Advances in Neural Information Processing Systems, vol. 36, pp. 27 469–27 500, 2023
work page 2023
-
[53]
Can AI-Generated Text be Reliably Detected?
V . S. Sadasivan, A. Kumar, S. Balasubramanian, W. Wang, and S. Feizi, “Can ai-generated text be reliably detected?”arXiv preprint arXiv:2303.11156, 2023
work page Pith review arXiv 2023
-
[54]
Slack federated ad- versarial training,
J. Zhu, B. Han, J. Yao, Q. Yao, T. Liu, and J. Xu, “Slack federated ad- versarial training,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.