MAS-PromptBench: When Does Prompt Optimization Improve Multi-Agent LLM Systems?
Pith reviewed 2026-06-26 09:14 UTC · model grok-4.3
The pith
Prompt optimization improves multi-agent LLM systems in many configurations but faces challenges from exponentially larger search spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
System prompts specify agents' roles and behaviors and therefore form a critical optimization surface in MAS. Extending prompt optimization from single LLMs to MAS is difficult because the search space grows exponentially, yet systematic benchmarking across varied tasks, workflows, protocols, and team sizes reveals that the approach can unlock significant gains while exposing open challenges in characterizing when and how much it helps.
What carries the argument
MAS-PromptBench benchmark that varies task, workflow, communication protocol, and team size while testing two prompt optimizers extending single-agent methods.
Load-bearing premise
The two chosen prompt optimizers and the sampled range of tasks, workflows, communication protocols, and team sizes are representative enough to support general statements about when prompt optimization helps in MAS.
What would settle it
A new experiment on a fresh collection of MAS configurations that produces either uniformly negligible gains or a qualitatively different dependence on setup parameters than the patterns reported.
Figures
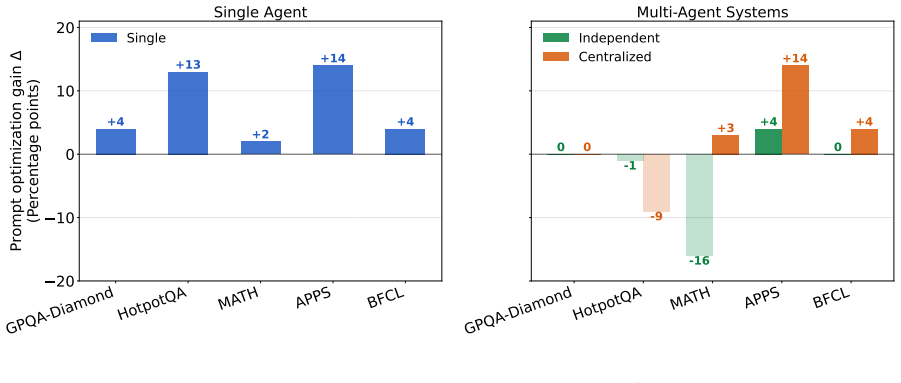
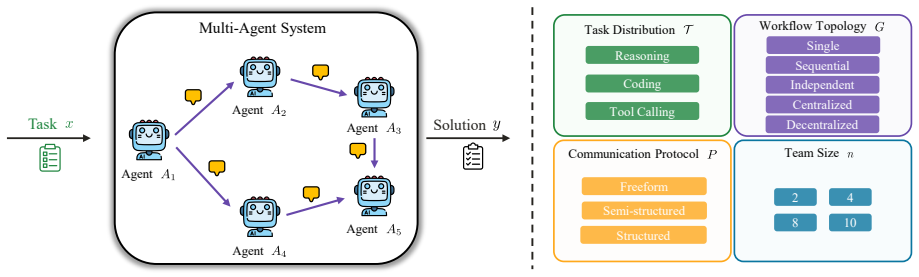
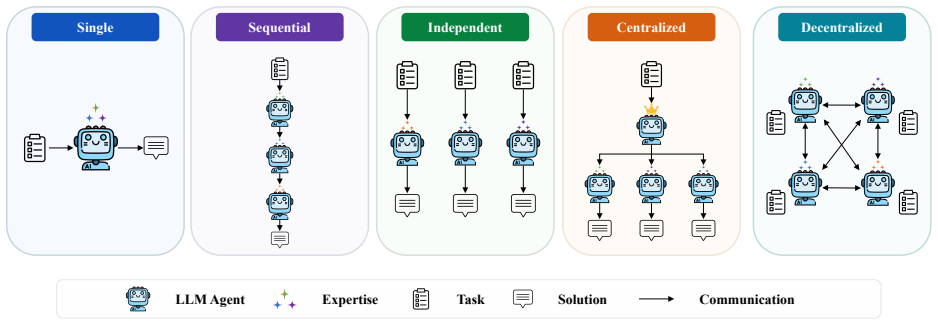
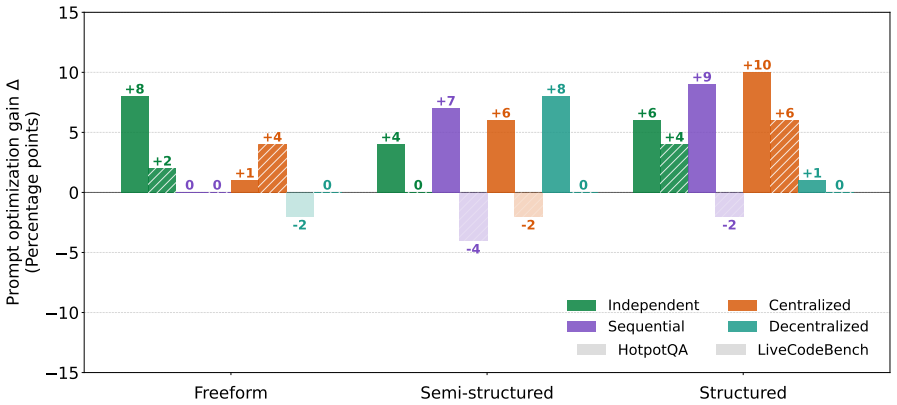
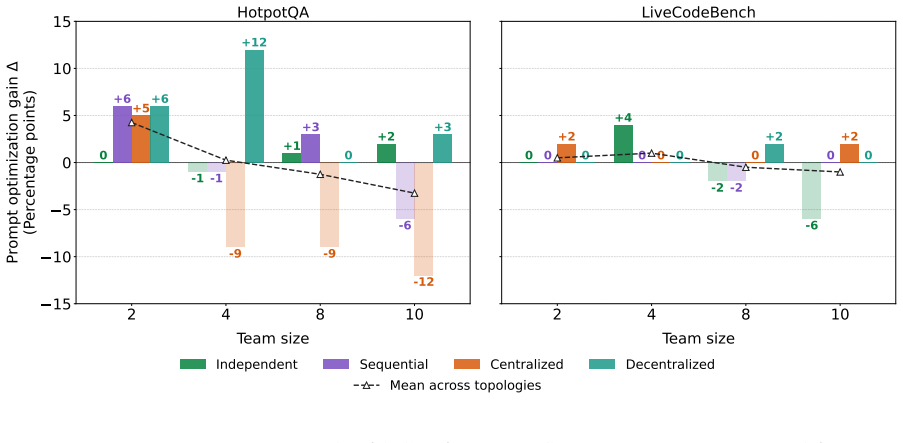
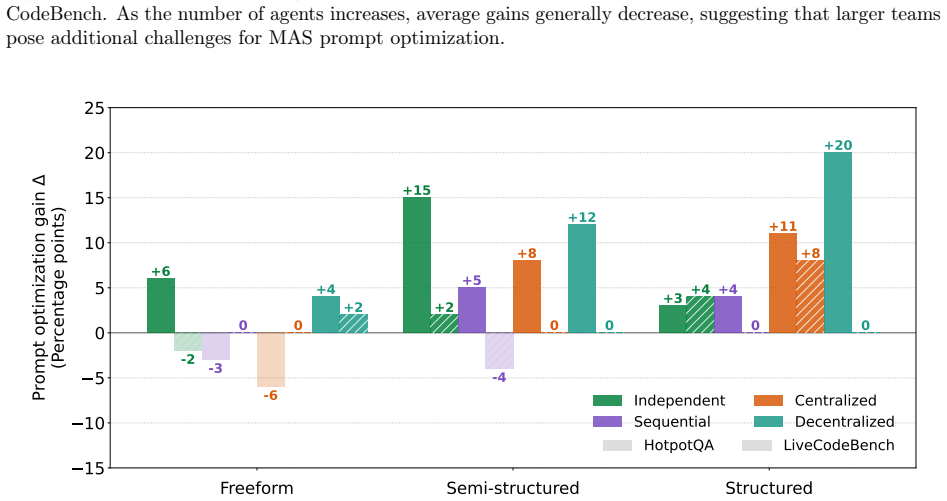
read the original abstract
Multi-agent systems (MAS) offer a scalable path forward for agentic AI, comprising multiple LLM-based agents, each assigned a system prompt and a position within a workflow that governs inter-agent coordination and output aggregation. System prompts thus form a critical and accessible optimization surface: they specify agents' roles and behaviors, enabling system-level improvements without model finetuning. Although prompt optimization has shown substantial potential for single LLMs, extending it to MAS poses distinct challenges, notably an exponentially growing search space. It remains unclear whether, when, and by how much prompt optimization improves MAS performance, and how sensitive such gains are to system configuration. In this work, we systematically study system-prompt optimization across a broad range of MAS setups varying in task, workflow, communication protocol, and team size, benchmarking two prompt optimizers that naturally extend state-of-the-art single-agent methods. The results reveal its potential to unlock significant gains while exposing open challenges, characterizing when and how much prompt optimization helps across diverse MAS settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAS-PromptBench, an empirical benchmark that extends two single-agent prompt optimizers to multi-agent LLM systems and evaluates them across a range of tasks, workflows, communication protocols, and team sizes. It claims to characterize when and by how much system-prompt optimization improves MAS performance while identifying open challenges.
Significance. If the reported gains prove robust under the sampled conditions, the work would supply useful empirical data on scaling prompt optimization beyond single agents, a timely contribution to agentic AI research. The benchmarking approach itself is a strength, as it directly tests applicability without requiring model finetuning.
major comments (1)
- [Abstract] Abstract: the central claim that the study 'characterizes when and how much prompt optimization helps across diverse MAS settings' rests on the assumption that two single-agent-derived optimizers and the chosen finite sample of tasks/workflows/protocols/team sizes are representative. No details are supplied on sampling strategy, coverage of larger team sizes, cyclic protocols, or joint inter-agent prompt optimization, leaving the generalization step unsecured.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to qualify the scope of our claims. We agree that the abstract phrasing and lack of explicit design details leave the generalization unsecured, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the study 'characterizes when and how much prompt optimization helps across diverse MAS settings' rests on the assumption that two single-agent-derived optimizers and the chosen finite sample of tasks/workflows/protocols/team sizes are representative. No details are supplied on sampling strategy, coverage of larger team sizes, cyclic protocols, or joint inter-agent prompt optimization, leaving the generalization step unsecured.
Authors: We acknowledge the validity of this observation. Our experiments apply two single-agent prompt optimizers to a curated collection of tasks, workflows, protocols, and team sizes selected to cover representative MAS patterns from prior work, but we did not articulate a formal sampling strategy or exhaustively cover all possible configurations. In the revision we will (1) rephrase the abstract to state that the study characterizes prompt-optimization effects “in the evaluated MAS settings” rather than claiming a broad characterization across diverse settings; (2) add a dedicated subsection under Experimental Setup that explicitly describes the selection criteria and rationale for the chosen tasks, workflows, communication protocols, and team sizes; and (3) add a Limitations paragraph that notes the absence of larger team sizes, cyclic protocols, and joint inter-agent prompt optimization, framing these as important directions for future work. These changes will make the scope of the empirical claims transparent without altering the reported results. revision: yes
Circularity Check
No circularity: empirical benchmarking study with no derivations or fitted predictions
full rationale
The paper is an empirical benchmarking study that evaluates two prompt optimizers across sampled MAS configurations (tasks, workflows, protocols, team sizes). No equations, derivations, or 'predictions' appear that could reduce to inputs by construction. Claims rest on experimental results rather than self-citation chains or ansatzes. The generalization to 'when and how much' is an empirical interpretation, not a mathematical reduction, so no load-bearing circular steps exist.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[2]
arXiv preprint arXiv:2305.14325 , year=
Improving factuality and reasoning in language models through multiagent debate , author=. arXiv preprint arXiv:2305.14325 , year=
-
[3]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Rlprompt: Optimizing discrete text prompts with reinforcement learning , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[4]
gradient descent
Automatic prompt optimization with “gradient descent” and beam search , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[5]
Textgrad: Automatic" differentiation" via text , author=. arXiv preprint arXiv:2406.07496 , year=
-
[6]
The eleventh international conference on learning representations , year=
Large language models are human-level prompt engineers , author=. The eleventh international conference on learning representations , year=
-
[7]
International Conference on Learning Representations , volume=
Large language models as optimizers , author=. International Conference on Learning Representations , volume=
-
[8]
International Conference on Learning Representations , volume=
Connecting large language models with evolutionary algorithms yields powerful prompt optimizers , author=. International Conference on Learning Representations , volume=
-
[9]
arXiv preprint arXiv:2309.16797 , year=
Promptbreeder: Self-referential self-improvement via prompt evolution , author=. arXiv preprint arXiv:2309.16797 , year=
-
[10]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[11]
arXiv preprint arXiv:2310.03714 , year=
Dspy: Compiling declarative language model calls into self-improving pipelines , author=. arXiv preprint arXiv:2310.03714 , year=
-
[12]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Optimizing instructions and demonstrations for multi-stage language model programs , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[13]
arXiv preprint arXiv:2507.19457 , year=
Gepa: Reflective prompt evolution can outperform reinforcement learning , author=. arXiv preprint arXiv:2507.19457 , year=
-
[14]
International Conference on Learning Representations , volume=
Automated design of agentic systems , author=. International Conference on Learning Representations , volume=
-
[15]
arXiv preprint arXiv:2502.04180 , year=
Multi-agent architecture search via agentic supernet , author=. arXiv preprint arXiv:2502.04180 , year=
-
[16]
International Conference on Learning Representations , volume=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. International Conference on Learning Representations , volume=
-
[17]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Chatdev: Communicative agents for software development , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[18]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Encouraging divergent thinking in large language models through multi-agent debate , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[19]
International Conference on Learning Representations , volume=
Mixture-of-agents enhances large language model capabilities , author=. International Conference on Learning Representations , volume=
-
[20]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Reconcile: Round-table conference improves reasoning via consensus among diverse llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
International Conference on Learning Representations , volume=
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors , author=. International Conference on Learning Representations , volume=
-
[22]
Forty-first International Conference on Machine Learning , year=
Gptswarm: Language agents as optimizable graphs , author=. Forty-first International Conference on Machine Learning , year=
-
[23]
arXiv preprint arXiv:2410.11782 , year=
G-designer: Architecting multi-agent communication topologies via graph neural networks , author=. arXiv preprint arXiv:2410.11782 , year=
-
[24]
Advances in neural information processing systems , volume=
Camel: Communicative agents for" mind" exploration of large language model society , author=. Advances in neural information processing systems , volume=
-
[25]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Autogen studio: A no-code developer tool for building and debugging multi-agent systems , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2024
-
[26]
Advances in Neural Information Processing Systems , volume=
Why do multi-agent llm systems fail? , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Multiagentbench: Evaluating the collaboration and competition of llm agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
Journal of Machine Learning Research , volume=
Promptbench: A unified library for evaluation of large language models , author=. Journal of Machine Learning Research , volume=
-
[29]
Forty-second International Conference on Machine Learning , year=
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models , author=. Forty-second International Conference on Machine Learning , year=
-
[30]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Appworld: A controllable world of apps and people for benchmarking interactive coding agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
International Conference on Learning Representations , volume=
Gaia: a benchmark for general ai assistants , author=. International Conference on Learning Representations , volume=
-
[32]
arXiv preprint arXiv:2402.01622 , year=
Travelplanner: A benchmark for real-world planning with language agents , author=. arXiv preprint arXiv:2402.01622 , year=
-
[33]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[34]
arXiv preprint arXiv:2502.02533 , year=
Multi-agent design: Optimizing agents with better prompts and topologies , author=. arXiv preprint arXiv:2502.02533 , year=
-
[35]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[36]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[37]
International Conference on Learning Representations , volume=
Promptagent: Strategic planning with language models enables expert-level prompt optimization , author=. International Conference on Learning Representations , volume=
-
[38]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
Grips: Gradient-free, edit-based instruction search for prompting large language models , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[39]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Interactive debugging and steering of multi-agent ai systems , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[40]
arXiv preprint arXiv:2505.00212 , year=
Which agent causes task failures and when? on automated failure attribution of llm multi-agent systems , author=. arXiv preprint arXiv:2505.00212 , year=
-
[41]
Journal of Artificial Intelligence Research , volume=
Agentic large language models, a survey , author=. Journal of Artificial Intelligence Research , volume=
-
[42]
arXiv preprint arXiv:2412.17481 , year=
A survey on llm-based multi-agent system: Recent advances and new frontiers in application , author=. arXiv preprint arXiv:2412.17481 , year=
-
[43]
arXiv preprint arXiv:2408.06292 , year=
The ai scientist: Towards fully automated open-ended scientific discovery , author=. arXiv preprint arXiv:2408.06292 , year=
-
[44]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
A systematic survey of automatic prompt optimization techniques , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[45]
arXiv preprint arXiv:2404.01077 , year=
Efficient prompting methods for large language models: A survey , author=. arXiv preprint arXiv:2404.01077 , year=
-
[46]
arXiv preprint arXiv:2602.03794 , year=
Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity , author=. arXiv preprint arXiv:2602.03794 , year=
-
[47]
arXiv preprint arXiv:2512.08296 , year=
Towards a science of scaling agent systems , author=. arXiv preprint arXiv:2512.08296 , year=
-
[48]
International Conference on Learning Representations , volume=
Scaling large language model-based multi-agent collaboration , author=. International Conference on Learning Representations , volume=
-
[49]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Understanding the information propagation effects of communication topologies in llm-based multi-agent systems , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Hivemind: Contribution-guided online prompt optimization of llm multi-agent systems , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[51]
arXiv preprint arXiv:2505.16086 , year=
Optimizing llm-based multi-agent system with textual feedback: A case study on software development , author=. arXiv preprint arXiv:2505.16086 , year=
-
[52]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
MAPRO: Recasting Multi-Agent Prompt Optimization as Maximum a Posteriori Inference , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[53]
arXiv preprint arXiv:2603.02630 , year=
MASPOB: Bandit-Based Prompt Optimization for Multi-Agent Systems with Graph Neural Networks , author=. arXiv preprint arXiv:2603.02630 , year=
-
[54]
arXiv preprint arXiv:2505.10936 , year=
Connecting the Dots: A Chain-of-Collaboration Prompting Framework for LLM Agents , author=. arXiv preprint arXiv:2505.10936 , year=
-
[55]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[56]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[57]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[58]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[59]
arXiv preprint arXiv:2105.09938 , year=
Measuring coding challenge competence with apps , author=. arXiv preprint arXiv:2105.09938 , year=
-
[60]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
ToolHop: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[61]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Api-bank: A comprehensive benchmark for tool-augmented llms , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[62]
Wang, Zhexuan and Liu, Xuebo and Wang, Li and Shan, Zifei and Wang, Yutong and Song, Zhenxi and Zhang, Min , journal=
-
[63]
arXiv preprint arXiv:2509.23331 , year=
C-Evolve: Consensus-based Evolution for Prompt Groups , author=. arXiv preprint arXiv:2509.23331 , year=
-
[64]
arXiv preprint arXiv:2605.30227 , year=
Unifying Temporal and Structural Credit Assignment in LLM-Based Multi-Agent Prompt Optimization , author=. arXiv preprint arXiv:2605.30227 , year=
-
[65]
CrewAI: Framework for Orchestrating Role-Playing Autonomous AI Agents , year =
-
[66]
The Next Evolution of the Agents SDK , year =
-
[67]
LangGraph: Build Resilient Language Agents as Stateful Graph Workflows , year =
-
[68]
System Prompts , year =
-
[69]
Gemini generateContent API , year =
-
[70]
Llama 4: Model Cards and Prompt Formats , year =
-
[71]
2026 , note =
Skills , howpublished =. 2026 , note =
2026
-
[72]
Extend Claude with Skills , year =
-
[73]
2026 , note =
Build a Skill Registry , howpublished =. 2026 , note =
2026
-
[74]
International Conference on Learning Representations , volume=
Aflow: Automating agentic workflow generation , author=. International Conference on Learning Representations , volume=
-
[75]
International Conference on Learning Representations , volume=
Agentsquare: Automatic llm agent search in modular design space , author=. International Conference on Learning Representations , volume=
-
[76]
arXiv preprint arXiv:2604.01687 , year=
Coevoskills: Self-evolving agent skills via co-evolutionary verification , author=. arXiv preprint arXiv:2604.01687 , year=
-
[77]
International Conference on Learning Representations , volume=
Cut the crap: An economical communication pipeline for llm-based multi-agent systems , author=. International Conference on Learning Representations , volume=
-
[78]
International Conference on Learning Representations , volume=
Agentbench: Evaluating llms as agents , author=. International Conference on Learning Representations , volume=
-
[79]
Claude Code , year =
-
[80]
arXiv preprint arXiv:2606.12683 , year=
From AGI to ASI , author=. arXiv preprint arXiv:2606.12683 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.