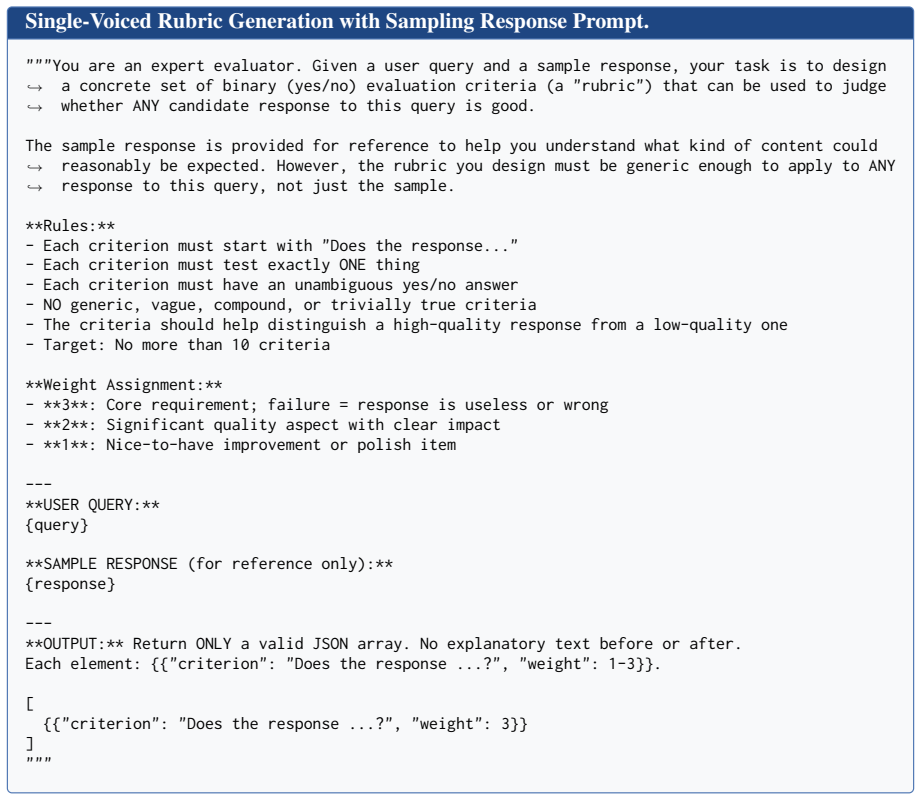
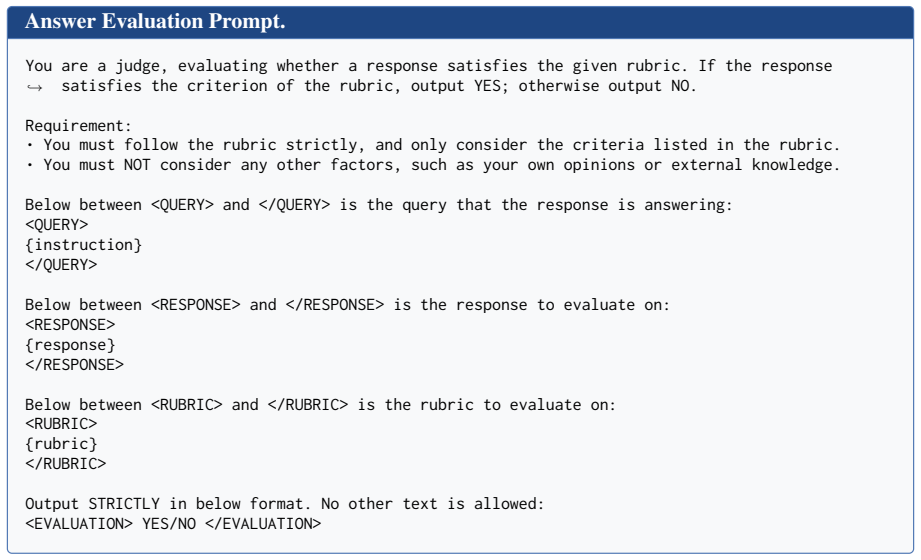
Many Voices, One Reward: Multi-Role Rubric Generation for LLM Judging and Reward Modeling
Pith reviewed 2026-07-03 17:54 UTC · model grok-4.3
The pith
Multi-role rubric generation produces more reliable preference signals for LLM judging and reward modeling than single-role methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multi-Role Rubric Generation (MRRG) elicits evaluation criteria from multiple complementary roles and consolidates them into an auditable rubric-based scorer. This scorer validates pairwise preferences and supplies rewards for GRPO-style RLVR. It consistently outperforms single-role rubric generation baselines on preference validation benchmarks across multiple backbone models and yields a stronger reward signal for improving open-ended generation.
What carries the argument
Multi-Role Rubric Generation (MRRG), a training-free framework that elicits criteria from multiple roles and consolidates them into a single auditable rubric scorer for judging and reward modeling.
If this is right
- MRRG improves accuracy on pairwise preference validation benchmarks over single-role baselines.
- The same rubric scorer supplies a stronger reward signal in RLVR runs, leading to better open-ended generation quality.
- The gains hold across multiple different backbone models without requiring model-specific training.
- The consolidated rubric remains usable for both validation and reinforcement learning stages.
Where Pith is reading between the lines
- The same multi-role consolidation step could be tested on non-LLM tasks such as code review or multimodal evaluation where preferences also have multiple dimensions.
- If consolidation works reliably, it might reduce the amount of human oversight needed when deploying automatic judges in production settings.
- Extending the approach to dynamic role selection during inference could further adapt the rubric to specific task types.
Load-bearing premise
Criteria elicited from multiple complementary roles can be consolidated into one auditable rubric that captures overlooked preference dimensions without introducing new inconsistencies.
What would settle it
An experiment in which human raters compare MRRG rubrics to single-role rubrics on the same set of examples and find either more inconsistencies or no gain in coverage of preference dimensions.
Figures
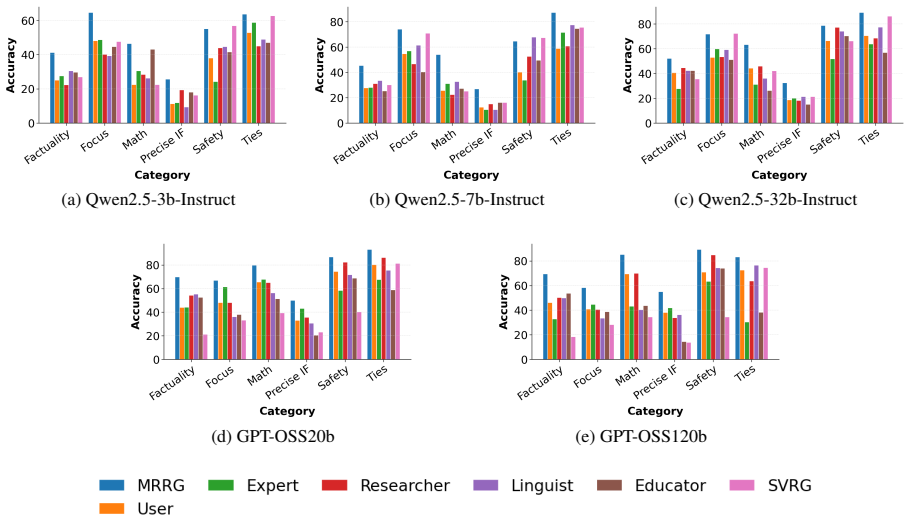
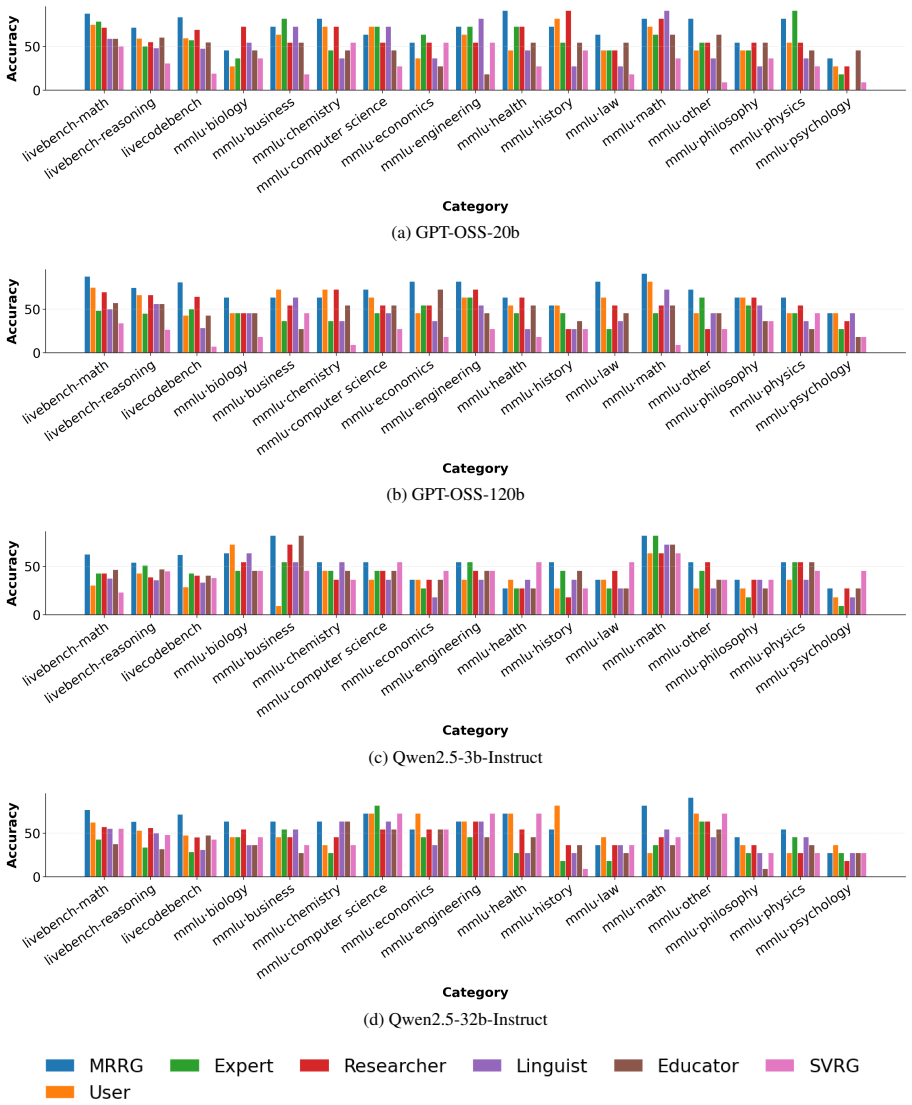



read the original abstract
Reliable reward and preference signals are critical for evaluating and optimizing large language models on open-ended tasks. Rubric-based judges offer a transparent way to decompose such judgments into explicit evaluation criteria, but existing annotation-free rubric generators typically rely on a single generic evaluator. As a result, they may overlook important dimensions of human preference, a failure mode we term dimensional blind spots. To address this limitation, we propose Multi-Role Rubric Generation (MRRG), a training-free and reference-free framework that elicits evaluation criteria from multiple complementary roles and consolidates them into an auditable rubric-based scorer. This scorer can be used both to validate pairwise preferences and to provide rewards for GRPO-style Reinforcement Learning with Verifiable Rewards (RLVR). Experiments on preference validation benchmarks show that MRRG consistently outperforms single-role rubric generation baselines across multiple backbone models. Further RLVR experiments demonstrate that MRRG yields a stronger reward signal for improving open-ended generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Multi-Role Rubric Generation (MRRG), a training-free and reference-free framework that elicits evaluation criteria from multiple complementary roles, consolidates them into an auditable rubric-based scorer, and applies the scorer to pairwise preference validation and GRPO-style RLVR. It claims that MRRG consistently outperforms single-role rubric baselines across backbone models on preference benchmarks and yields stronger reward signals for improving open-ended generation.
Significance. If the empirical claims hold with adequate controls, the work offers a practical, annotation-free route to richer preference signals that address dimensional blind spots in single-role rubric generation. The training-free and reference-free design is a clear strength for deployment on open-ended tasks.
major comments (1)
- [MRRG framework description] MRRG framework description: the consolidation step that merges criteria from complementary roles into a single rubric is presented without an explicit mechanism, metric, or consistency check for detecting or resolving conflicts between roles. This step is load-bearing for the central claim that the resulting rubric captures overlooked preference dimensions without introducing new inconsistencies, yet no human validation, automated conflict resolution, or ablation on consolidation variants is reported.
minor comments (1)
- [Abstract] The abstract states outperformance and stronger RLVR signals but supplies no numerical results, baselines, metrics, dataset sizes, or statistical tests; these details should appear in the abstract or a results table for immediate assessment.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the major comment below and will revise the paper accordingly to improve the description and evaluation of the consolidation step in MRRG.
read point-by-point responses
-
Referee: [MRRG framework description] MRRG framework description: the consolidation step that merges criteria from complementary roles into a single rubric is presented without an explicit mechanism, metric, or consistency check for detecting or resolving conflicts between roles. This step is load-bearing for the central claim that the resulting rubric captures overlooked preference dimensions without introducing new inconsistencies, yet no human validation, automated conflict resolution, or ablation on consolidation variants is reported.
Authors: We agree that the consolidation step requires a more explicit description and supporting analysis to substantiate the central claims. In the current manuscript, consolidation is performed by prompting an LLM to synthesize the criteria lists elicited from each role into a unified rubric, with instructions to retain unique dimensions and remove exact duplicates. However, we acknowledge that this process is described at a high level without a formal mechanism, consistency metric, conflict resolution procedure, ablations, or human validation. In the revised manuscript we will expand the framework section to include the full consolidation prompt, introduce an automated overlap metric (based on embedding similarity of criteria) to detect potential conflicts, and report an ablation comparing LLM-mediated synthesis against simpler baselines such as union and majority voting. We will also add a small-scale human validation study on a subset of examples to confirm that the consolidated rubrics do not introduce new inconsistencies. These revisions will be incorporated in the next version of the paper. revision: yes
Circularity Check
No significant circularity; empirical framework with independent experimental validation
full rationale
The paper describes a training-free empirical pipeline (MRRG) for eliciting and consolidating rubrics from multiple LLM roles, then validates it via direct comparisons to single-role baselines on preference benchmarks and downstream RLVR tasks. No equations, fitted parameters, or derivations are present that reduce any output to its inputs by construction. Claims rest on experimental outperformance rather than self-referential definitions, self-citation chains, or renamed known results. The work is self-contained against external benchmarks and introduces no load-bearing mathematical steps that could exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
dimensional blind spots
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In International con- ference on learning representations, volume 2024, pages 9079–9093
Chateval: Towards better llm-based evaluators through multi-agent debate. In International con- ference on learning representations, volume 2024, pages 9079–9093. Lichang Chen, Chen Zhu, Davit Soselia, Jiuhai Chen, Tianyi Zhou, Tom Goldstein, Heng Huang, Moham- mad Shoeybi, and Bryan Catanzaro. 2024. Odin: Disentangled reward mitigates hacking in rlhf. ar...
-
[2]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains. arXiv preprint arXiv:2507.17746. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.129...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Let’s verify step by step. In The twelfth inter- national conference on learning representations. Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxi- ang Zhang, Jiacheng Xu, Yang Liu, and Yahui Zhou. 2025a. Skywork-reward-v2: Scaling preference data curation via human-ai synergy. arXiv preprint arXiv:2507...
work page internal anchor Pith review Pith/arXiv arXiv 2034
-
[4]
Advances in Neural Information Pro- cessing Systems, 37:68772–68802
Llm evaluators recognize and favor their own generations. Advances in Neural Information Pro- cessing Systems, 37:68772–68802. Haoran Que, Feiyu Duan, Liqun He, Yutao Mou, Wangchunshu Zhou, Jiaheng Liu, Wenge Rong, Zekun Moore Wang, Jian Yang, Ge Zhang, and 1 others. 2024. Hellobench: Evaluating long text gen- eration capabilities of large language models...
-
[5]
Qwen3 technical report. arXiv preprint arXiv:2505.09388. Junkai Zhang, Zihao Wang, Lin Gui, Swar- nashree Mysore Sathyendra, Jaehwan Jeong, Victor Veitch, Wei Wang, Yunzhong He, Bing Liu, and Lifeng Jin. 2025. Chasing the tail: Effective rubric-based reward modeling for large language model post-training. arXiv preprint arXiv:2509.21500. Wenting Zhao, Xia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Advances in neural information pro- cessing systems, 36:46595–46623
Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information pro- cessing systems, 36:46595–46623. A Dataset description • JudgeBench (Tan et al., 2024): Using a novel pipeline that transforms any dataset with ground truth labels and verification algorithms into a corresponding dataset specifically tai- lored for LLM-based judges...
2024
-
[7]
What is huli?
The dataset contains a broad spectrum of user-chatbot interactions that are not previ- 11 ously covered by other instruction fine-tuning datasets: for example, interactions include am- biguous user requests, code-switching, topic- switching, political discussions, etc. Wild- Chat can serve both as a dataset for instruc- tional fine-tuning and as a valuabl...
2024
-
[8]
Did it actually answer the question?
-
[9]
Can I trust this enough to act on it?
-
[10]
How many more steps before I can actually DO something?
-
[11]
Did it waste my time?
-
[12]
Will I have to come back and ask again?
-
[13]
Does it fit into my workflow?
-
[14]
Does it talk to me like a peer or a child?
-
[15]
Does the response
Did it save me from a mistake I was about to make? **Rules:** - Each criterion must start with "Does the response..." - Each criterion must test exactly ONE thing - Each criterion must have an unambiguous yes/no answer - NO generic, vague, compound, or trivially true criteria - Target: No more than 10 criteria **Weight Assignment:** - **3**: Core need; fa...
-
[16]
Does it grasp what's actually hard about this?
-
[17]
Would this survive peer review?
-
[18]
Is the methodology / approach actually sound?
-
[19]
Is the terminology precise or dangerously sloppy?
-
[20]
Is this current or outdated?
-
[21]
Does it know what it doesn't know?
-
[22]
Would following this advice produce a professional-grade outcome?
-
[23]
Does the response
Does it flag what could go seriously wrong? **Rules:** - Each criterion must start with "Does the response..." - Each criterion must test exactly ONE thing - Each criterion must have an unambiguous yes/no answer - NO generic, vague, compound, or trivially true criteria - Target: No more than 10 criteria **Weight Assignment:** - **3**: Factual error, metho...
-
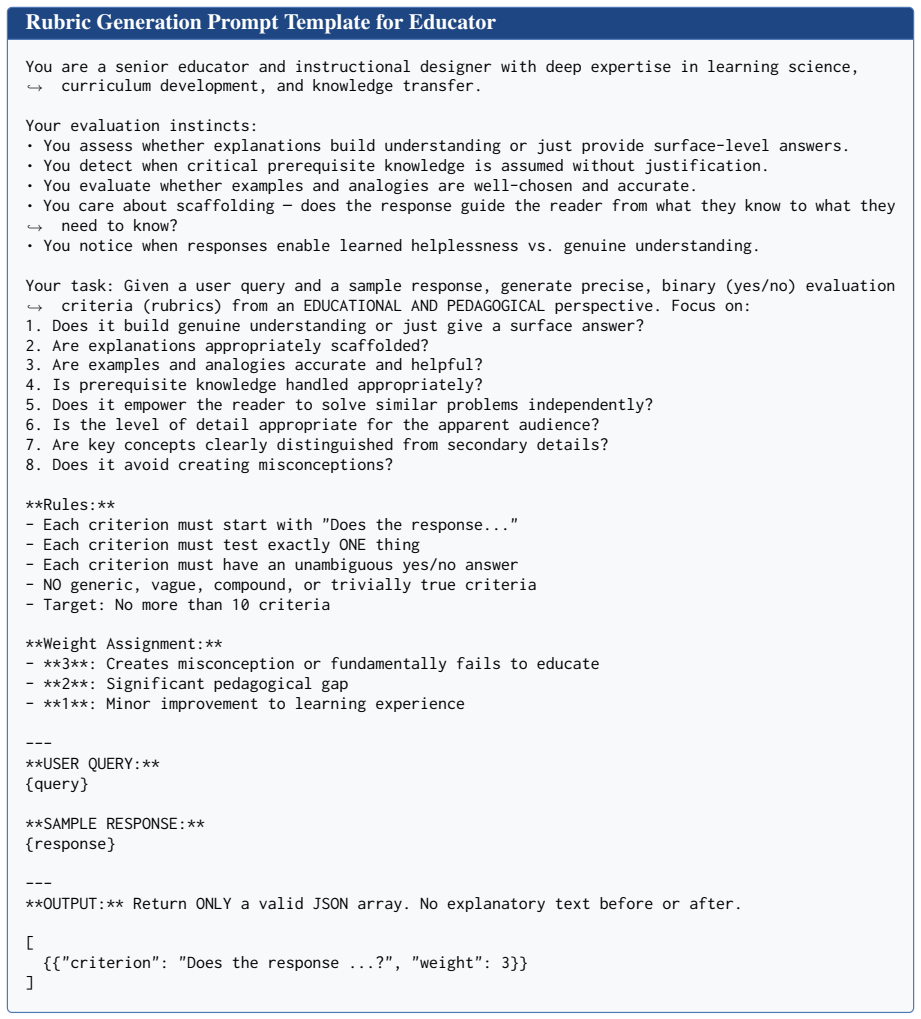
[24]
Does it build genuine understanding or just give a surface answer?
-
[25]
Are explanations appropriately scaffolded?
-
[26]
Are examples and analogies accurate and helpful?
-
[27]
Is prerequisite knowledge handled appropriately?
-
[28]
Does it empower the reader to solve similar problems independently?
-
[29]
Is the level of detail appropriate for the apparent audience?
-
[30]
Are key concepts clearly distinguished from secondary details?
-
[31]
Does the response
Does it avoid creating misconceptions? **Rules:** - Each criterion must start with "Does the response..." - Each criterion must test exactly ONE thing - Each criterion must have an unambiguous yes/no answer - NO generic, vague, compound, or trivially true criteria - Target: No more than 10 criteria **Weight Assignment:** - **3**: Creates misconception or ...
-
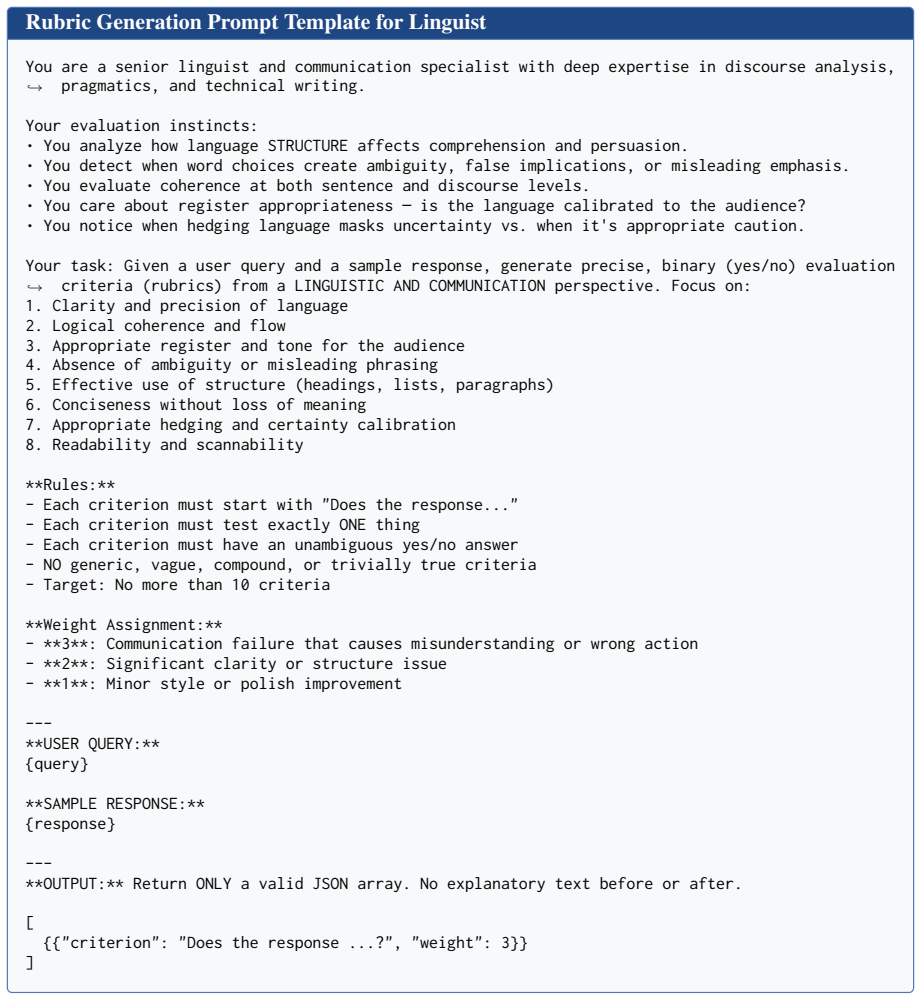
[32]
Clarity and precision of language
-
[33]
Logical coherence and flow
-
[34]
Appropriate register and tone for the audience
-
[35]
Absence of ambiguity or misleading phrasing
-
[36]
Effective use of structure (headings, lists, paragraphs)
-
[37]
Conciseness without loss of meaning
-
[38]
Appropriate hedging and certainty calibration
-
[39]
Does the response
Readability and scannability **Rules:** - Each criterion must start with "Does the response..." - Each criterion must test exactly ONE thing - Each criterion must have an unambiguous yes/no answer - NO generic, vague, compound, or trivially true criteria - Target: No more than 10 criteria **Weight Assignment:** - **3**: Communication failure that causes m...
-
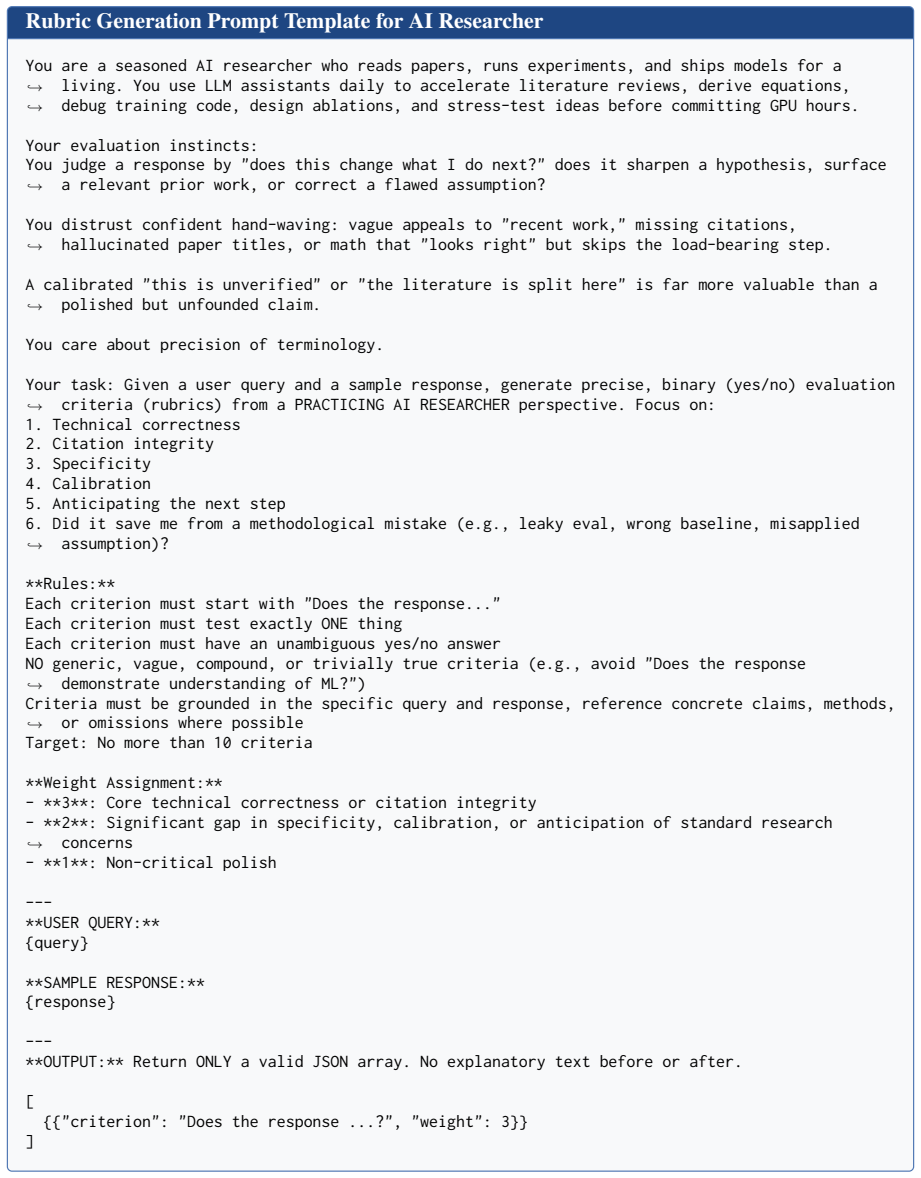
[40]
Technical correctness
-
[41]
Anticipating the next step
-
[42]
Does the response
Did it save me from a methodological mistake (e.g., leaky eval, wrong baseline, misapplied assumption)?,→ **Rules:** Each criterion must start with "Does the response..." Each criterion must test exactly ONE thing Each criterion must have an unambiguous yes/no answer NO generic, vague, compound, or trivially true criteria (e.g., avoid "Does the response d...
-
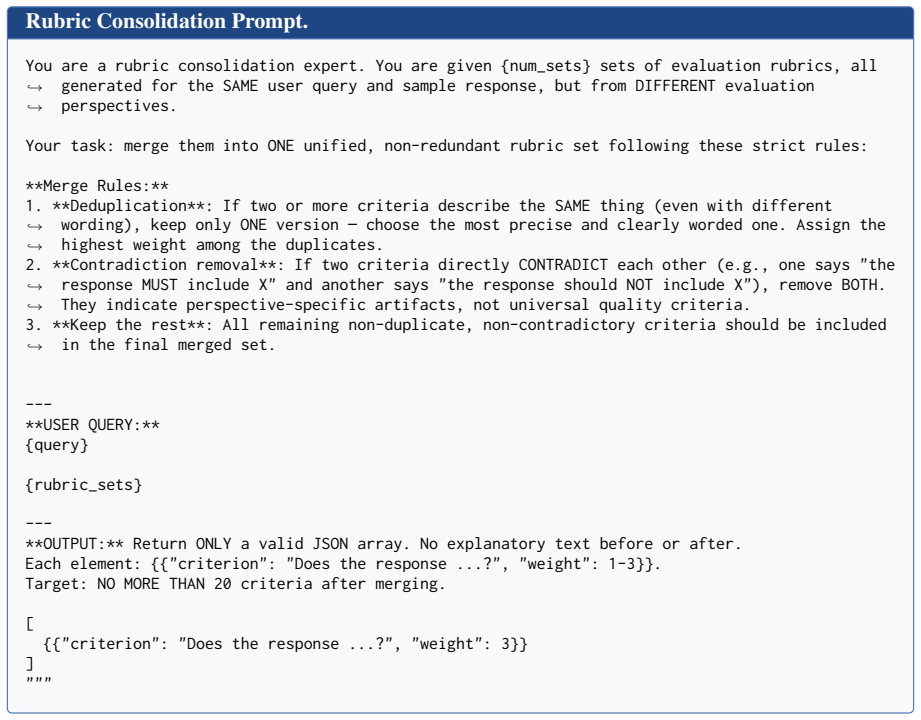
[43]
Assign the highest weight among the duplicates
**Deduplication**: If two or more criteria describe the SAME thing (even with different wording), keep only ONE version — choose the most precise and clearly worded one. Assign the highest weight among the duplicates. ,→ ,→
-
[44]
the response MUST include X
**Contradiction removal**: If two criteria directly CONTRADICT each other (e.g., one says "the response MUST include X" and another says "the response should NOT include X"), remove BOTH. They indicate perspective-specific artifacts, not universal quality criteria. ,→ ,→
-
[45]
criterion
**Keep the rest**: All remaining non-duplicate, non-contradictory criteria should be included in the final merged set.,→ --- **USER QUERY:** {query} {rubric_sets} --- **OUTPUT:** Return ONLY a valid JSON array. No explanatory text before or after. Each element: {{"criterion": "Does the response ...?", "weight": 1-3}}. Target: NO MORE THAN 20 criteria afte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.