Exploring the Value of Diverse LLM Explanations in Introductory Programming
Pith reviewed 2026-06-30 08:45 UTC · model grok-4.3
The pith
Diverse LLM explanations improve student accuracy on open-ended programming questions by 7.7%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across participants, open-ended response accuracy was consistently about 7.7% higher when students received diverse explanations, with no difference in perceived cognitive load. The study assigns students to diverse or generic LLM-generated explanations for programming exercises, where diverse ones emphasize distinct aspects such as function, concept, and goal.
What carries the argument
Diverse versus generic LLM-generated explanations, where diversity means multiple explanations each emphasizing distinct conceptual aspects.
If this is right
- Students achieve higher accuracy on open-ended responses when provided with diverse explanations.
- Perceived cognitive load remains unchanged across the two explanation conditions.
- Variation in explanation emphasis relates to patterns in learner engagement and understanding.
- Combining multiple explanations with different focuses can enhance student performance on programming tasks.
Where Pith is reading between the lines
- Similar benefits might appear in other educational domains where conceptual multiple perspectives aid learning.
- Future studies could isolate whether the benefit arises from the number of explanations or their conceptual differences specifically.
- Course designers might integrate diverse LLM explanations into materials to support varied student needs without increasing student effort.
Load-bearing premise
The two explanation conditions differed primarily due to the intended diversity in conceptual emphasis rather than uncontrolled differences in explanation length, wording, accuracy, or presentation format.
What would settle it
Finding no difference in open-ended accuracy in a new study where explanations are matched on length, wording, and factual accuracy would falsify the claim that diversity in emphasis drives the performance gain.
Figures


read the original abstract
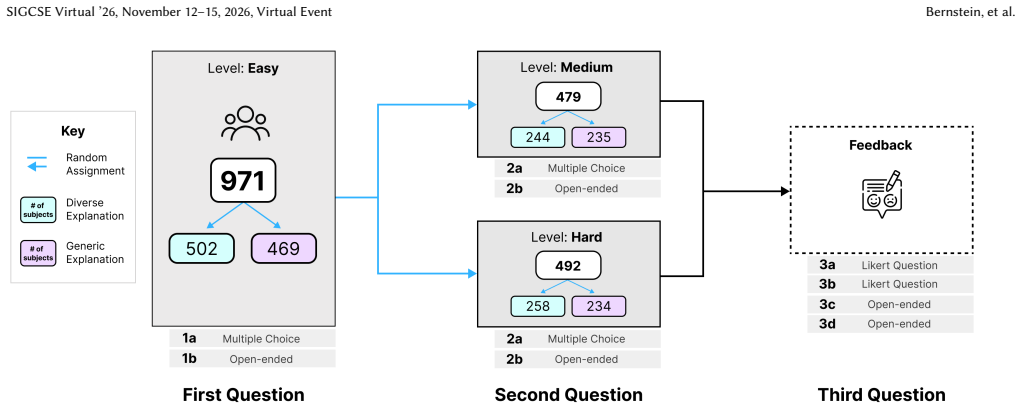
Large Language Models (LLMs) have shown the potential to generate code explanations that surpass those of peers in quality, offering promising opportunities for computer science education. While these explanations may not yet match the depth and clarity of instructor-provided explanations, research in computational creativity highlights that the quantity and diversity of ideas can often outweigh a singular focus on quality. Inspired by this, we explore whether combining multiple diverse explanations, each emphasizing distinct aspects (e.g., function, concept, goal), can enhance students' understanding of programming exercises compared to generic explanations that do not emphasize distinct conceptual aspects. In our study 971 first-year computing students were randomly assigned either diverse or generic LLM-generated explanations for two programming exercises. Students completed multiple-choice and open-ended questions for each exercise, followed by Likert-scale questions and open-ended reflections. Our findings outline patterns in student performance and perceived cognitive load across the two explanation conditions. These findings highlight how variation in explanation emphasis may relate to learner engagement and understanding. Across participants, open-ended response accuracy was consistently about 7.7% higher when students received diverse explanations, with no difference in perceived cognitive load.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a between-subjects experiment with 971 first-year computing students randomly assigned to receive either diverse LLM-generated explanations (each emphasizing distinct conceptual aspects such as function, concept, or goal) or generic LLM explanations for two programming exercises. Students answered multiple-choice and open-ended questions, then completed Likert-scale cognitive-load items and open-ended reflections. The central empirical claim is that open-ended accuracy was consistently 7.7% higher under the diverse-explanation condition, with no difference in perceived cognitive load.
Significance. If the reported accuracy advantage proves robust after proper statistical reporting and confound checks, the work would offer a concrete, low-cost design principle for LLM-augmented programming instruction: that variation in conceptual emphasis can improve comprehension without raising load. The large sample and random assignment are strengths that would support practical recommendations for educational tool design.
major comments (3)
- [Abstract] Abstract: the headline claim that open-ended accuracy was 'consistently about 7.7% higher' is presented without any statistical test, p-value, confidence interval, per-condition sample size, or effect-size statistic, so it is impossible to judge whether the difference exceeds sampling variability or is practically meaningful.
- [Abstract] Abstract: the performance difference is attributed to 'diversity in conceptual emphasis,' yet the text supplies no evidence that the two explanation sets were matched (or even measured) on length, lexical complexity, factual accuracy, or presentation format; any systematic difference on these surface variables would constitute an uncontrolled confound capable of producing the observed accuracy gap.
- [Abstract] Abstract: no information is given on the scoring rubrics, number of raters, or inter-rater reliability for the open-ended accuracy measure that underpins the central claim.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the two specific programming exercises and briefly described how the diverse versus generic prompts were constructed.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments focused on the abstract. We agree that the abstract requires additional detail for transparency and have revised it to incorporate the requested statistical reporting, evidence of condition matching, and scoring procedure information. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that open-ended accuracy was 'consistently about 7.7% higher' is presented without any statistical test, p-value, confidence interval, per-condition sample size, or effect-size statistic, so it is impossible to judge whether the difference exceeds sampling variability or is practically meaningful.
Authors: We agree that the abstract should include these details. The full manuscript reports a chi-square test of independence showing the difference is statistically significant (χ^{2}(1, N=971) = 14.67, p < 0.001), with per-condition sample sizes of 485 and 486, a 95% CI for the proportion difference of [3.8%, 11.6%], and a small effect size (Cramer's V = 0.12). We have revised the abstract to report these statistics. revision: yes
-
Referee: [Abstract] Abstract: the performance difference is attributed to 'diversity in conceptual emphasis,' yet the text supplies no evidence that the two explanation sets were matched (or even measured) on length, lexical complexity, factual accuracy, or presentation format; any systematic difference on these surface variables would constitute an uncontrolled confound capable of producing the observed accuracy gap.
Authors: The manuscript verifies that the two sets of explanations were matched on these surface features prior to the experiment: mean length (248 vs 251 words), lexical complexity (Flesch reading ease 64.2 vs 63.9), factual accuracy (confirmed by two CS instructors with full agreement), and identical presentation format (same formatting and structure). We have added a sentence to the abstract summarizing this matching. revision: yes
-
Referee: [Abstract] Abstract: no information is given on the scoring rubrics, number of raters, or inter-rater reliability for the open-ended accuracy measure that underpins the central claim.
Authors: We agree this information belongs in the abstract. Open-ended responses were scored independently by two trained raters using a 4-point rubric assessing correctness, use of relevant concepts, and completeness. Inter-rater reliability was high (Cohen's κ = 0.87). We have updated the abstract to include the rubric description, rater count, and reliability statistic. revision: yes
Circularity Check
No circularity: empirical study with direct data observations
full rationale
This is an empirical human-subjects experiment (N=971) that randomly assigns participants to two explanation conditions and measures performance and load via direct questions. The abstract and described methods contain no equations, models, derivations, fitted parameters, or predictions that could reduce to inputs by construction. The reported 7.7% open-ended accuracy difference is presented as a raw data observation, not a quantity defined in terms of itself or obtained via self-citation chains. No steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Randomized assignment to conditions produces comparable groups on average
Reference graph
Works this paper leans on
-
[1]
Shaaron Ainsworth. 1999. The functions of multiple representations.Computers & Education33, 2-3 (1999), 131–152. https://doi.org/10.1016/S0360-1315(99)00029-9
-
[2]
Seth Bernstein, Paul Denny, Juho Leinonen, Lauren Kan, Arto Hellas, Matt Little- field, Sami Sarsa, and Stephen Macneil. 2024. "Like a Nesting Doll": Analyzing Recursion Analogies Generated by CS Students Using Large Language Models. InProceedings of the 2024 on Innovation and Technology in Computer Science Edu- cation V. 1. ACM, Milan Italy, 122–128. htt...
-
[3]
Seth Bernstein, Paul Denny, Juho Leinonen, Matt Littlefield, Arto Hellas, and Stephen MacNeil. 2024. Analyzing Students’ Preferences for LLM-Generated Analogies. InProceedings of the 2024 on Innovation and Technology in Computer Science Education V. 2. ACM, Milan Italy, 812–812. https://doi.org/10.1145/ 3649405.3659504
-
[4]
Seth Bernstein, Ashfin Rahman, Nadia Sharifi, Ariunjargal Terbish, and Stephen MacNeil. 2025. Beyond the Benefits: A Systematic Review of the Harms and Consequences of Generative AI in Computing Education. InProceedings of the 25th Koli Calling International Conference on Computing Education Research (Koli Calling ’25). Association for Computing Machinery...
-
[5]
Briana Bettin, Linda Ott, and Julia Hiebel. 2022. Semaphore or Metaphor? Ex- ploring Concurrent Students’ Conceptions of and with Analogy. InProceedings of the 27th ACM Conference on on Innovation and Technology in Computer Sci- ence Education Vol. 1(Dublin, Ireland)(ITiCSE ’22). Association for Computing Machinery, 200–206. https://doi.org/10.1145/350271...
-
[6]
Clara Bove, Jonathan Aigrain, Marie-Jeanne Lesot, Charles Tijus, and Marcin Detyniecki. 2022. Contextualization and Exploration of Local Feature Importance Explanations to Improve Understanding and Satisfaction of Non-Expert Users. In Proceedings of the 27th International Conference on Intelligent User Interfaces (IUI ’22). Association for Computing Machi...
-
[7]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative Research in Psychology3, 2 (Jan. 2006), 77–101. https://doi.org/10. 1191/1478088706qp063oa
2006
-
[8]
Alice Cai, Steven R Rick, Jennifer L Heyman, Yanxia Zhang, Alexandre Filipowicz, Matthew Hong, Matt Klenk, and Thomas Malone. 2023. DesignAID: Using Generative AI and Semantic Diversity for Design Inspiration. InProceedings of The ACM Collective Intelligence Conference (CI ’23). Association for Computing Machinery, 1–11. https://doi.org/10.1145/3582269.3615596
-
[9]
Malcolm Corney, Sue Fitzgerald, Brian Hanks, Raymond Lister, Renee McCauley, and Laurie Murphy. 2014. ’explain in plain english’ questions revisited: data structures problems. InProceedings of the 45th ACM Technical Symposium on Computer Science Education(Atlanta, Georgia, USA)(SIGCSE ’14). Association for Computing Machinery, 591–596
2014
-
[10]
Pierpaolo Dondio and Suha Shaheen. 2020. Is StackOverflow an Effective Com- plement to Gaining Practical Knowledge Compared to Traditional Computer Science Learning?. InProceedings of the 11th International Conference on Education Technology and Computers(Amsterdam, Netherlands)(ICETC ’19). Association for Computing Machinery, 132–138. https://doi.org/10....
-
[11]
Steven Dow, Julie Fortuna, Dan Schwartz, Beth Altringer, Daniel Schwartz, and Scott Klemmer. 2011. Prototyping dynamics: sharing multiple designs improves exploration, group rapport, and results. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’11). Association for Computing Machinery, 2807–2816. https://doi.org/10.1145/1...
-
[12]
Rodrigo Duran, Albina Zavgorodniaia, and Juha Sorva. 2022. Cognitive Load Theory in Computing Education Research: A Review.ACM Trans. Comput. Educ. 22, 4, Article 40 (Sept. 2022), 27 pages. https://doi.org/10.1145/3483843
-
[13]
Joseph L Fleiss. 1971. Measuring nominal scale agreement among many raters. Psychological bulletin76, 5 (1971), 378
1971
-
[14]
Irene Hou, Sophia Mettille, Owen Man, Zhuo Li, Cynthia Zastudil, and Stephen MacNeil. 2024. The Effects of Generative AI on Computing Students’ Help- Seeking Preferences. InProceedings of the 26th Australasian Computing Education Conference (ACE ’24). Association for Computing Machinery, New York, NY, USA, 39–48. https://doi-org.libproxy.temple.edu/10.114...
-
[15]
Breanna Jury, Angela Lorusso, Juho Leinonen, Paul Denny, and Andrew Luxton- Reilly. 2024. Evaluating LLM-generated Worked Examples in an Introductory Programming Course. InProceedings of the 26th Australasian Computing Educa- tion Conference(Sydney, NSW, Australia)(ACE ’24). Association for Computing Machinery, 77–86. https://doi.org/10.1145/3636243.3636252
-
[16]
Essi Lahtinen, Kirsti Ala-Mutka, and Hannu-Matti Järvinen. 2005. A study of the difficulties of novice programmers.Acm sigcse bulletin37, 3 (2005), 14–18
2005
-
[17]
Retno Larasati, Anna De Liddo, and Enrico Motta. 2023. Meaningful Explanation Effect on User’s Trust in an AI Medical System: Designing Explanations for Non-Expert Users.ACM Trans. Interact. Intell. Syst.13, 4, Article 30, 39 pages. https://doi.org/10.1145/3631614
- [18]
-
[19]
Raymond Lister, Elizabeth S Adams, Sue Fitzgerald, William Fone, John Hamer, Morten Lindholm, Robert McCartney, Jan Erik Moström, Kate Sanders, Otto Seppälä, et al. 2004. A multi-national study of reading and tracing skills in novice programmers.ACM SIGCSE Bulletin36, 4 (2004), 119–150
2004
-
[20]
Mun Ling Lo and Ference Marton. 2012. Towards a science of the art of teaching. International Journal for Lesson and Learning Studies1, 1 (2012), 7–22. https://doi. org/10.1108/20468251211179678 Publisher: Emerald Group Publishing Limited
-
[21]
Evanfiya Logacheva, Arto Hellas, James Prather, Sami Sarsa, and Juho Leinonen
-
[22]
InProceedings of the 2024 ACM Conference on International Computing Education Research-Volume 1
Evaluating Contextually Personalized Programming Exercises Created with Generative AI. InProceedings of the 2024 ACM Conference on International Computing Education Research-Volume 1. 95–113
2024
-
[23]
Stephen MacNeil, Andrew Tran, Arto Hellas, Joanne Kim, Sami Sarsa, Paul Denny, Seth Bernstein, and Juho Leinonen. 2023. Experiences from Using Code Expla- nations Generated by Large Language Models in a Web Software Development E-Book. InProc. SIGCSE’23. ACM, 6 pages
2023
-
[24]
Stephen MacNeil, Andrew Tran, Dan Mogil, Seth Bernstein, Erin Ross, and Ziheng Huang. 2022. Generating Diverse Code Explanations Using the GPT-3 Large Language Model. InProc. of the 2022 ACM Conf. on Int. Computing Education Research - Volume 2. ACM, 37–39
2022
-
[25]
Lauren E Margulieux, Mark Guzdial, and Richard Catrambone. 2012. Subgoal- labeled instructional material improves performance and transfer in learning to develop mobile applications. InProceedings of the ninth annual international conference on International computing education research. 71–78
2012
-
[26]
Samiha Marwan, Nicholas Lytle, Joseph Jay Williams, and Thomas Price. 2019. The Impact of Adding Textual Explanations to Next-step Hints in a Novice Pro- gramming Environment. InProceedings of the 2019 ACM Conference on Innovation and Technology in Computer Science Education(Aberdeen, Scotland Uk)(ITiCSE ’19). Association for Computing Machinery, 520–526....
-
[27]
Richard E Mayer. 2005. Cognitive theory of multimedia learning.The Cambridge handbook of multimedia learning41, 1 (2005), 31–48
2005
-
[28]
Richard E. Mayer and Roxana Moreno. 2003. Nine Ways to Reduce Cognitive Load in Multimedia Learning.Educational Psychologist38, 1 (Jan. 2003), 43–52. https://doi.org/10.1207/S15326985EP3801_6
-
[29]
James Prather, Paul Denny, Juho Leinonen, Brett A Becker, Ibrahim Albluwi, Michelle Craig, Hieke Keuning, Natalie Kiesler, Tobias Kohn, Andrew Luxton- Reilly, et al. 2023. The robots are here: Navigating the generative ai revolution in computing education. InProceedings of the 2023 Working Group Reports on Innovation and Technology in Computer Science Edu...
2023
-
[30]
Nishat Raihan, Mohammed Latif Siddiq, Joanna CS Santos, and Marcos Zampieri
-
[31]
InProceedings of the 56th ACM Technical Symposium on Computer Science Education V
Large language models in computer science education: A systematic litera- ture review. InProceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1. 938–944
-
[32]
Sandoval
William A. Sandoval. 2004. Explanation-driven inquiry: Integrating conceptual and epistemic scaffolds for scientific inquiry. InScience Education Volume 88
2004
-
[33]
Sami Sarsa, Paul Denny, Arto Hellas, and Juho Leinonen. 2022. Automatic Gen- eration of Programming Exercises and Code Explanations Using Large Language Models. InProceedings of the 2022 ACM Conference on International Computing Education Research - Volume 1(Lugano and Virtual Event, Switzerland)(ICER ’22). Association for Computing Machinery, 27–43. http...
-
[34]
Arnold, Krzysztof Z
Pao Siangliulue, Kenneth C. Arnold, Krzysztof Z. Gajos, and Steven P. Dow
-
[35]
Toward Collaborative Ideation at Scale: Leveraging Ideas from Others to Generate More Creative and Diverse Ideas. InProceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing (CSCW ’15). Association for Computing Machinery, 937–945. https://doi.org/10.1145/ 2675133.2675239
-
[36]
Matthias Stadler, Maria Bannert, and Michael Sailer. 2024. Cognitive ease at a cost: LLMs reduce mental effort but compromise depth in student scientific inquiry.Computers in Human Behavior160 (2024), 108386
2024
-
[37]
John Sweller. 2011. Cognitive Load Theory. InPsychology of Learning and Motivation. Vol. 55. Elsevier, 37–76
2011
-
[38]
Anne Venables, Grace Tan, and Raymond Lister. 2009. A Closer Look at Tracing, Explaining and Code Writing Skills in the Novice Programmer. InProc. of the Fifth Int. Workshop on Computing Education Research Workshop(Berkeley, CA, USA)(ICER ’09). ACM, 117–128. https://doi.org/10.1145/1584322.1584336
-
[39]
Thomas B Ward, Steven M Smith, and Ronald A Finke. 1999. Creative cognition. Handbook of creativity189 (1999), 212
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.