NOVA: A Verification-Aware Agent Harness for Architecture Evolution in Industrial Recommender Systems
Pith reviewed 2026-06-26 02:01 UTC · model grok-4.3
The pith
NOVA uses a verification cascade and architecture gradient to guide scalable evolution of industrial recommender architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
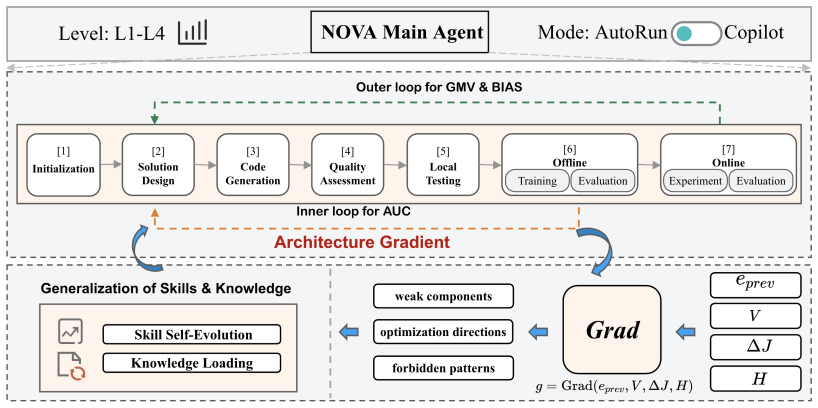
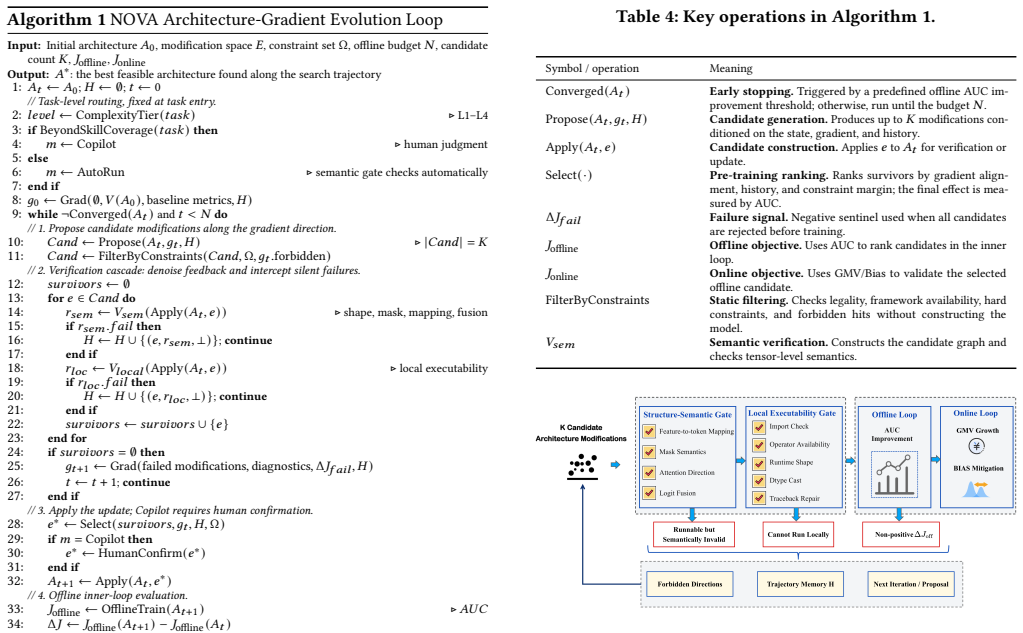
NOVA deploys an architecture gradient, an SGD-inspired non-differentiable update signal that aggregates prior modifications, verification diagnostics, metric feedback, and trajectory memory to guide the next modification. It pairs this with a verification cascade that checks structure semantics, local executability, offline effectiveness, and online impact, blocking invalid candidates early and recording forbidden directions. Level-aware L1-L4 control matches automation to task complexity and risk. In an industrial advertising system, NOVA reaches 54.5% and 60.0% effective pass rates on L2 ScaleUp and L3 Literature-to-Production tasks, reduces silent failures versus coding-agent baselines, s
What carries the argument
The architecture gradient, a non-differentiable update signal aggregating prior modifications, verification diagnostics, metric feedback, and trajectory memory to direct the next architecture change, supported by the verification cascade that filters candidates at multiple stages before online impact.
If this is right
- Achieves the highest effective pass rate on L2 ScaleUp (54.5%) and L3 Literature-to-Production (60.0%) tasks.
- Reduces silent failures compared with coding-agent baselines.
- Shortens one literature-to-production cycle by over 13x in human-attended time.
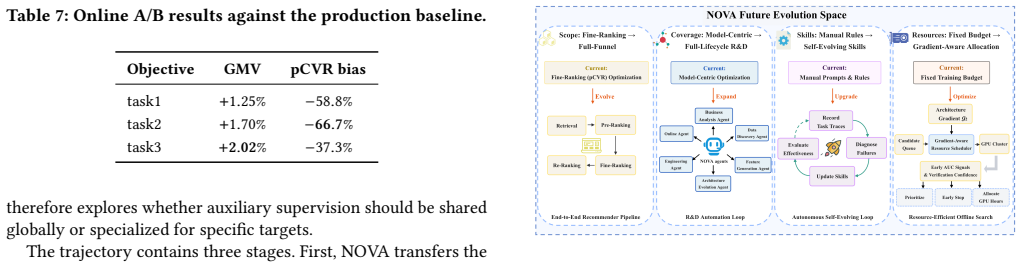
- Improves GMV on three pCVR objectives by +1.25%, +1.70%, and +2.02% and reduces pCVR bias by 58.8%, 66.7%, and 37.3% in online A/B testing.
Where Pith is reading between the lines
- If the cascade generalizes, the harness could apply to architecture evolution in other machine learning systems beyond advertising recommenders.
- Recording forbidden directions across cycles could allow the system to accumulate knowledge and reduce repeated errors in ongoing production evolution.
- The level-aware routing suggests a template for balancing automation and oversight in other LLM-driven code or model modification workflows.
Load-bearing premise
The verification cascade combined with the architecture gradient reliably identifies and promotes only beneficial architecture changes without missing high-value candidates or allowing performance-degrading ones to reach online testing.
What would settle it
An observed case in which a high-value architecture change is blocked by the cascade or a performance-degrading change passes all verification stages and reaches online testing with negative impact.
Figures
read the original abstract
Industrial advertising recommender models are continuously improved through architecture evolution. Upgrades such as RankMixer, TokenMixer-Large, and MixFormer show that better structures remain a key source of quality and business gains. Yet developing such upgrades in production is expert-intensive and difficult to scale. Existing automation is insufficient: AutoML mainly tunes hyper-parameters, while effective gains often require cross-module changes under strict constraints; generic LLM coding agents optimize for runnable code, but runnable code does not imply a valid recommender architecture. Candidates may pass local tests while causing silent failures that degrade performance. We present NOVA, a level-aware agent harness for verification-aware architecture evolution. NOVA uses an architecture gradient, an SGD-inspired, non-differentiable update signal that aggregates prior modifications, verification diagnostics, metric feedback, and trajectory memory to guide the next modification. A verification cascade checks structure semantics, local executability, offline effectiveness, and online impact; invalid candidates are blocked early, with failure patterns recorded as forbidden directions. L1--L4 task-level control matches automation to task complexity and risk, routing high-risk tasks to Copilot for human oversight. Deployed in an industrial advertising system, NOVA achieves the highest effective pass rate on L2 ScaleUp and L3 Literature-to-Production tasks (54.5% and 60.0%), reduces silent failures compared with coding-agent baselines, and shortens one literature-to-production cycle by over 13x in human-attended time. In online A/B testing, the selected L3 candidate improves GMV on three pCVR objectives by +1.25%, +1.70%, and +2.02%, while reducing pCVR bias by 58.8%, 66.7%, and 37.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents NOVA, a level-aware agent harness for verification-aware architecture evolution in industrial advertising recommender systems. It proposes an architecture gradient (non-differentiable, SGD-inspired signal aggregating modifications, diagnostics, metrics, and trajectory memory) to guide changes, combined with a verification cascade (structure semantics, local executability, offline effectiveness, online impact) and L1-L4 task-level control. The paper claims the highest effective pass rates on L2 ScaleUp (54.5%) and L3 Literature-to-Production (60.0%) tasks versus coding-agent baselines, reduced silent failures, over 13x reduction in human-attended time for one cycle, and online A/B test gains of +1.25%, +1.70%, +2.02% GMV on three pCVR objectives with corresponding bias reductions of 58.8%, 66.7%, and 37.3%.
Significance. If the results hold, the work has substantial significance for industrial recommender systems research by demonstrating a practical, verification-aware approach to scaling architecture evolution beyond AutoML hyper-parameter tuning or generic LLM coding agents. The online A/B test results provide direct evidence of business impact (GMV and bias metrics), and the level-aware routing to human oversight addresses risk in production settings.
major comments (3)
- [§5] §5 (Experimental Evaluation): The reported effective pass rates, silent failure reductions, and online GMV lifts are presented without ablations that isolate the verification cascade's contribution from the architecture gradient or from the coding-agent baselines. This is load-bearing for the central claim that the cascade reliably blocks degrading changes while surfacing beneficial ones.
- [§4] §4 (Verification Cascade): No enumeration or analysis of failure modes that passed early cascade stages (e.g., structure semantics and local executability) yet failed later (offline or online) is provided, leaving open the possibility that recommender-specific silent failures (such as cross-module interaction shifts under production traffic) evade detection.
- [Table 2] Table 2 (or equivalent results table): The comparison to coding-agent baselines lacks details on baseline implementations, statistical tests, dataset descriptions, and how 'effective pass rate' is computed, making it impossible to assess whether the reported 54.5% and 60.0% figures support the superiority claim.
minor comments (2)
- [§3] The architecture gradient is described as 'SGD-inspired' but lacks a precise algorithmic definition or pseudo-code; adding this in §3 would improve clarity without altering the central claims.
- The abstract and results sections report specific quantitative outcomes (e.g., 13x time reduction, exact GMV percentages) but the full experimental protocol (including how candidates are selected for online testing and any post-hoc filtering) should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of NOVA. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Experimental Evaluation): The reported effective pass rates, silent failure reductions, and online GMV lifts are presented without ablations that isolate the verification cascade's contribution from the architecture gradient or from the coding-agent baselines. This is load-bearing for the central claim that the cascade reliably blocks degrading changes while surfacing beneficial ones.
Authors: We agree that the current manuscript lacks explicit ablations isolating the verification cascade. The presented results compare the full NOVA system to baselines but do not decompose contributions. In the revised version we will add ablation experiments (NOVA without cascade; NOVA without architecture gradient) reporting pass rates, silent failure counts, and cycle times to quantify each component's impact. revision: yes
-
Referee: [§4] §4 (Verification Cascade): No enumeration or analysis of failure modes that passed early cascade stages (e.g., structure semantics and local executability) yet failed later (offline or online) is provided, leaving open the possibility that recommender-specific silent failures (such as cross-module interaction shifts under production traffic) evade detection.
Authors: The manuscript does not currently include such an enumeration. We will add a dedicated analysis (new subsection or appendix) that catalogs failure modes observed in deployment logs which passed early stages but were rejected later, including examples of cross-module shifts and how the cascade detected them, while respecting industrial confidentiality limits. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table): The comparison to coding-agent baselines lacks details on baseline implementations, statistical tests, dataset descriptions, and how 'effective pass rate' is computed, making it impossible to assess whether the reported 54.5% and 60.0% figures support the superiority claim.
Authors: We acknowledge the need for greater experimental transparency. The revision will expand the experimental section and Table 2 caption with: (i) precise baseline configurations and prompting details, (ii) dataset and task descriptions for L2/L3, (iii) statistical tests (e.g., significance of pass-rate differences), and (iv) the exact definition and computation of effective pass rate (candidates passing all cascade stages with positive offline metric delta). revision: yes
Circularity Check
No circularity: empirical system claims rest on external deployment results
full rationale
The paper presents NOVA as a verification-aware agent harness whose core components (architecture gradient aggregating modifications/diagnostics/feedback/memory, and a four-stage verification cascade) are described as engineering constructs rather than derived quantities. No equations, fitted parameters, or self-referential definitions appear in the provided text. Performance claims (pass rates, GMV lifts, bias reductions) are reported from industrial A/B tests and baseline comparisons, not from any internal prediction that reduces to the inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Frame- work. InProceedings of the 25th ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining. 2623–2631
2019
-
[2]
Anthropic. 2026. Claude Sonnet 4.6. https://www.anthropic.com/claude/sonnet. Accessed: 2026-06-08
2026
-
[3]
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for Hyper-Parameter Optimization. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 24
2011
-
[4]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah
-
[5]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems. 7–10
-
[6]
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Tobias Springenberg, Manuel Blum, and Frank Hutter. 2015. Efficient and Robust Automated Machine Learning. InAdvances in Neural Information Processing Systems
2015
-
[7]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine Based Neural Network for CTR Prediction. InProceedings of the 26th International Joint Conference on Artificial Intelligence. 1725–1731
2017
-
[8]
Xu Huang, Hao Zhang, Zhifang Fan, Yunwen Huang, Zhuoxing Wei, Zheng Chai, Jinan Ni, Yuchao Zheng, and Qiwei Chen. 2026. MixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders.arXiv preprint arXiv:2602.14110 (2026)
arXiv 2026
-
[9]
Yunwen Huang, Shiyong Hong, Xijun Xiao, Jinqiu Jin, Xuanyuan Luo, Zhe Wang, Zheng Chai, Shikang Wu, Yuchao Zheng, and Jingjian Lin. 2026. HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR 9 Prediction.arXiv preprint arXiv:2601.12681(2026)
arXiv 2026
-
[10]
Yuchen Jiang, Jie Zhu, Xintian Han, Hui Lu, Kunmin Bai, Mingyu Yang, Shikang Wu, Ruihao Zhang, Wenlin Zhao, Shipeng Bai, et al. 2026. TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders.arXiv preprint arXiv:2602.06563(2026)
arXiv 2026
-
[11]
Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Field- aware Factorization Machines for CTR Prediction. InProceedings of the 10th ACM Conference on Recommender Systems. 43–50
2016
-
[12]
Ashwin Kumar, Erwin Gao, Matan Levi, Sheela Yadawad, Sherman Wong, Sneha Iyer, and Vinodh Kumar Sunkara. 2026. Ranking Engineer Agent (REA): The Autonomous AI Agent Accelerating Meta’s Ads Ranking Innovation. Meta Engineering Blog. https://engineering.fb.com/2026/03/17/developer- tools/ranking-engineer-agent-rea-autonomous-ai-system-accelerating-meta- ads...
2026
-
[13]
Hanxiao Liu, Karen Simonyan, and Yiming Yang. 2019. DARTS: Differentiable Architecture Search. InInternational Conference on Learning Representations
2019
-
[14]
H. Brendan McMahan, Gary Holt, David Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, Sharat Chikkerur, Dan Liu, Martin Wattenberg, Arnar Mar Hrafnkelsson, Tom Boulos, and Jeremy Kubica. 2013. Ad Click Prediction: A View from the Trenches. In Proceedings of the 19th ACM SIGKDD International Confe...
2013
-
[15]
Le, and Jeff Dean
Hieu Pham, Melody Guan, Barret Zoph, Quoc V. Le, and Jeff Dean. 2018. Efficient Neural Architecture Search via Parameter Sharing. InProceedings of the 35th International Conference on Machine Learning. 4095–4104
2018
-
[16]
Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based Interest Model for Lifelong User Behavior Sequence Modeling in Click-Through Rate Prediction. InProceedings of the 29th ACM International Conference on Information and Knowledge Management. 2685–2692
2020
-
[17]
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng
-
[18]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , publisher =
Automatic Prompt Optimization with “Gradient Descent” and Beam Search. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 7957–7968. https://doi. org/10.18653/v1/2023.emnlp-main.494
-
[19]
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V. Le. 2019. Regularized Evolution for Image Classifier Architecture Search. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 4780–4789
2019
-
[20]
Steffen Rendle. 2010. Factorization Machines. InProceedings of the 2010 IEEE International Conference on Data Mining. 995–1000
2010
-
[21]
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, et al . 2026. Attention residuals.arXiv preprint arXiv:2603.15031(2026)
Pith/arXiv arXiv 2026
-
[22]
Hoos, and Kevin Leyton-Brown
Chris Thornton, Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. 2013. Auto-WEKA: Combined Selection and Hyperparameter Optimization of Clas- sification Algorithms. InProceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 847–855
2013
-
[23]
Haochen Wang, Yi Wu, Daryl Chang, Li Wei, and Lukasz Heldt. 2026. Self- evolving recommendation system: End-to-end autonomous model optimization with LLM agents.arXiv preprint arXiv:2602.10226(2026)
arXiv 2026
-
[24]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[25]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Gra- ham Neubig. 2025. OpenHands: An Open Platform for...
2025
-
[26]
Xidong Wu, Yue Zhuan, Ruoqiao Wei, Hangxin Chen, Di Bai, Jintao Liu, Xinyi Wang, Xue Wang, Luoshu Wang, and Xinwu Cheng. 2026. AgenticRecTune: Multi-Agent with Self-Evolving Skillhub for Recommendation System Optimiza- tion.arXiv preprint arXiv:2604.26969(2026)
Pith/arXiv arXiv 2026
-
[27]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems, Vol. 37
2024
-
[28]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations (ICLR)
2023
-
[29]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. 2024. TextGrad: Automatic “Differentiation” via Text. https://doi.org/10.48550/arXiv.2406.07496 arXiv:2406.07496 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.07496 2024
-
[30]
Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun. 2026. Onetrans: Unified feature interaction and sequence modeling with one transformer in industrial recommender. InProceedings of the ACM Web Conference 2026. 8162–8170
2026
-
[31]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep Interest Evolution Network for Click-Through Rate Prediction. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 5941–5948
2019
-
[32]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click- Through Rate Prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1059–1068
2018
-
[33]
Size” is the prompt + skill bundle size; “Input
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316. 10 A Appendix: Harness Footprint, Efficiency, a...
2025
-
[34]
Parse the full paper before any local implementation; extract architecture, equations, tensor shapes, and dependencies
-
[35]
Separate paper-stated facts from inferences and engineering assumptions; log unresolved ambiguities explicitly
-
[36]
Generate faithful code, tests, runnable examples, and audit artifacts under paper_repro/. ... # REPRESENTATIVE GUARDRAILS - Never code directly from vague intuition. - Every major implementation choice MUST be tagged as {paper-stated|inferred-from-paper|engineering-assumption}. ... # OUTPUTS spec.md, equation_map.md, ambiguity_log.md, src/model.py, tests/...
-
[37]
Retrieve the correct context/topo/ and context/scene/ files BEFORE proposing any modification
-
[38]
# REPRESENTATIVE GUARDRAILS - Read topology and scene grounding files first
Select one optimization direction using priority matrices plus failure history from prior rounds... # REPRESENTATIVE GUARDRAILS - Read topology and scene grounding files first. - Reject changes that violate latency budget, exported-graph schema, or production deployment constraints. ... # OUTPUTS A ranked design.md containing records of the form (explanat...
-
[39]
Build unified diffs from each candidate to the baseline rather than reviewing raw code in isolation
-
[40]
# REPRESENTATIVE GUARDRAILS - Every finding MUST cite line ranges
Launch heterogeneous LLM reviewers in parallel and reconcile their findings by location and severity... # REPRESENTATIVE GUARDRAILS - Every finding MUST cite line ranges. - Unresolved block-level findings MUST be fixed or explicitly waived before training. ... # OUTPUTS - Per-reviewer reports - Consolidated summary.md - gate_decision∈{pass, revise, reject...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.