Non-Uniform L2 Cache Latency Across the Streaming Multiprocessors of an NVIDIA L40
Pith reviewed 2026-06-26 09:33 UTC · model grok-4.3
The pith
L2 cache hit latency on NVIDIA L40 varies 52 percent by which streaming multiprocessor issues the load.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
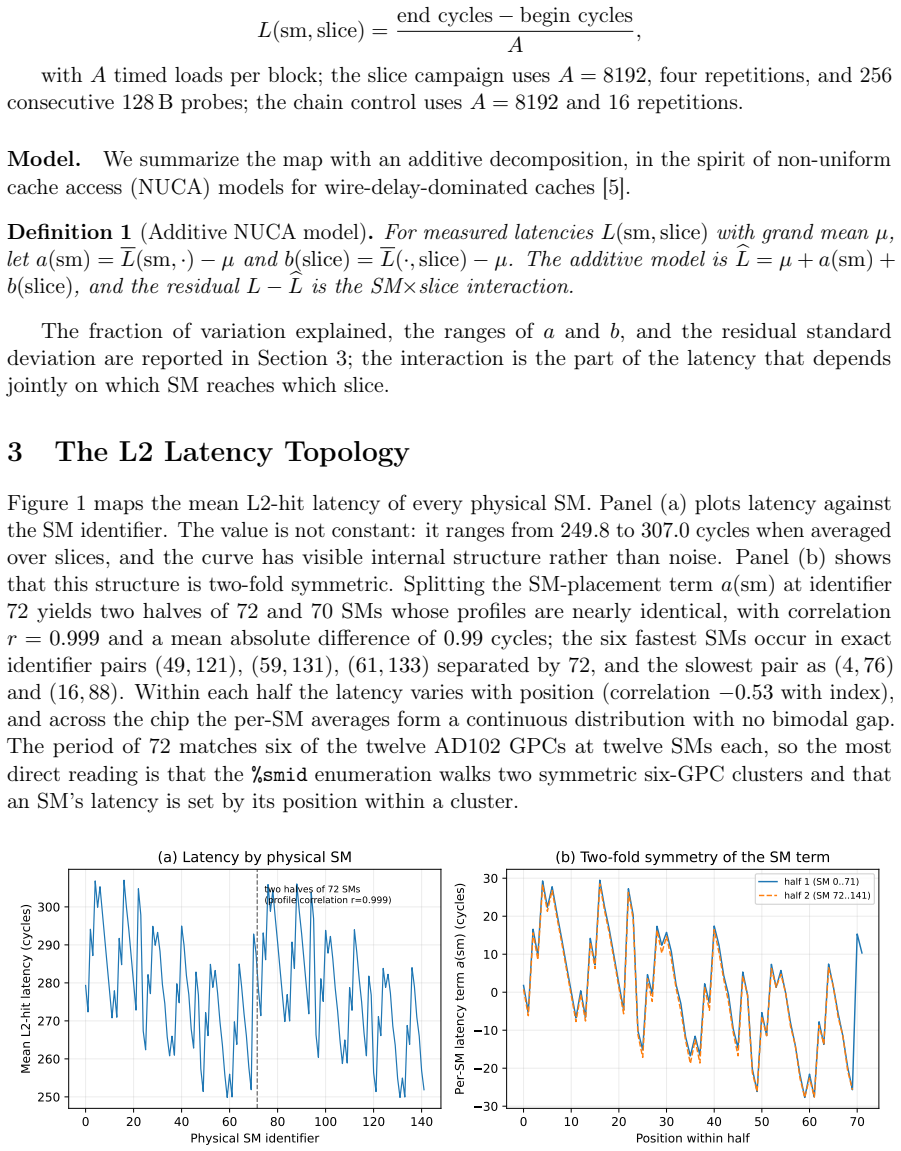
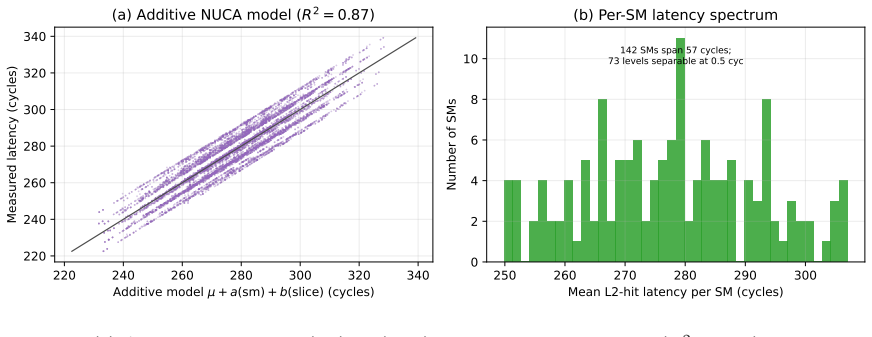
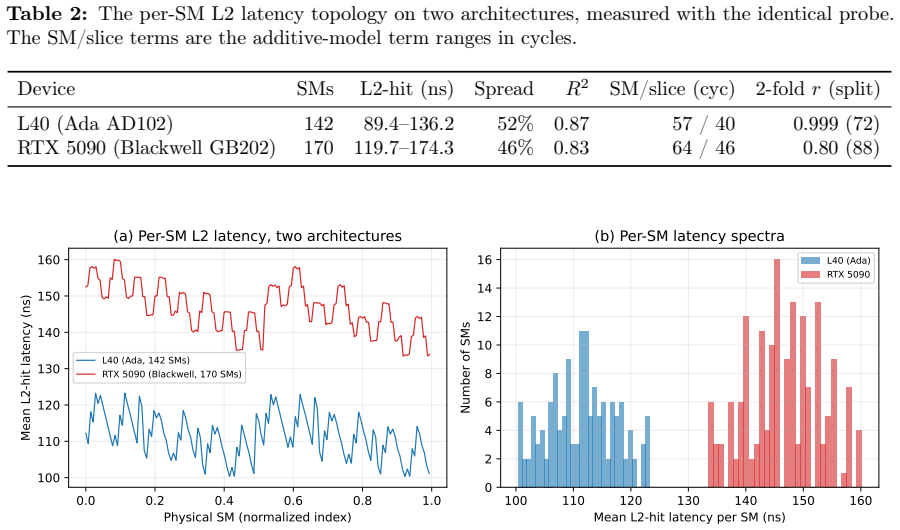
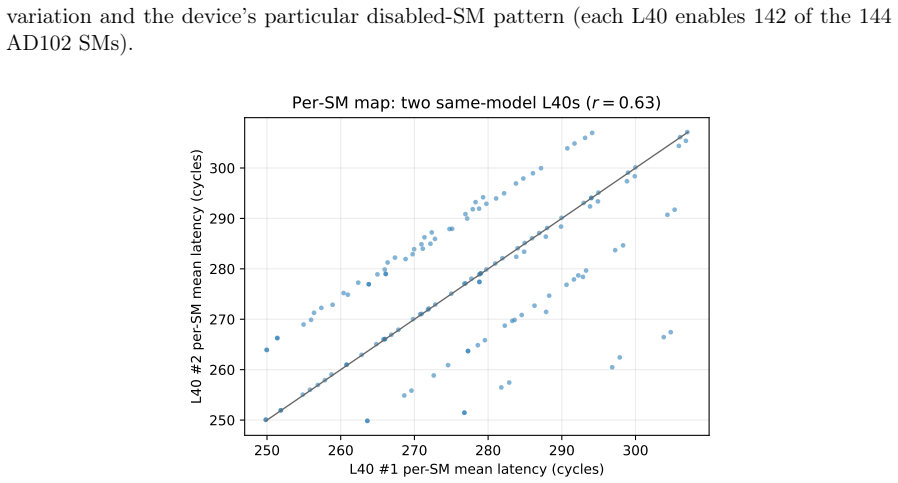
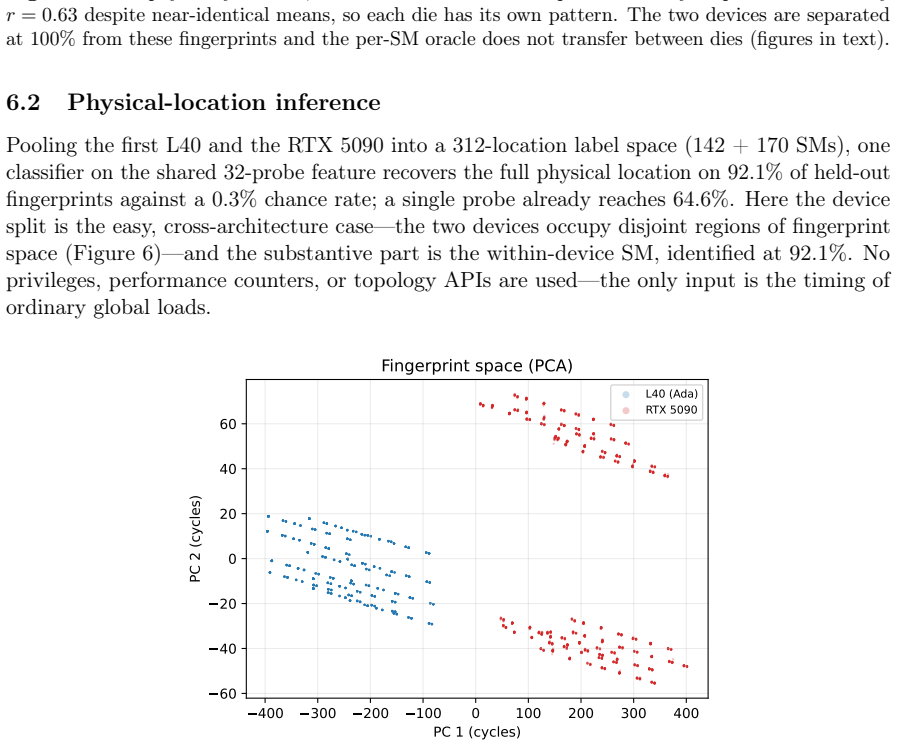
L2-hit latency is not constant near 279 cycles but spans 222-339 cycles (52 percent range) depending on the issuing SM; an additive model L = μ + a(sm) + b(slice) explains R² = 0.87 of the variance (0.98 with one rank-1 term), the SM term is two-fold symmetric with r = 0.999, and the pattern is stable, device-specific, and enables 92 percent SM identification plus 100 percent device fingerprinting between identical L40 cards.
What carries the argument
The turn-serialized, %smid-resolved probe that resolves per-SM L2 hit latency across all 142 SMs in a single launch.
If this is right
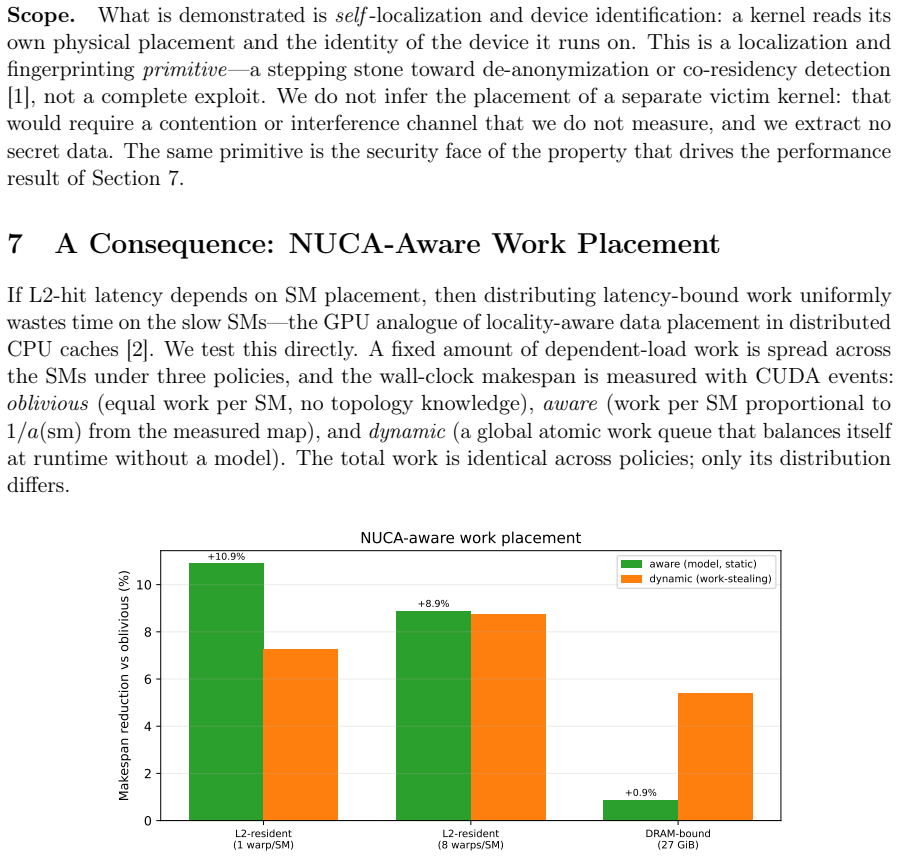
- Distributing latency-bound work according to the per-SM map reduces makespan by up to 11 percent.
- A kernel can read its own SM placement inside the device at 92 percent accuracy from the latency map.
- The same probe distinguishes two physically identical L40 cards at 100 percent accuracy despite near-identical mean latency.
- The non-uniform pattern appears on Blackwell GPUs, showing the effect is not limited to the L40.
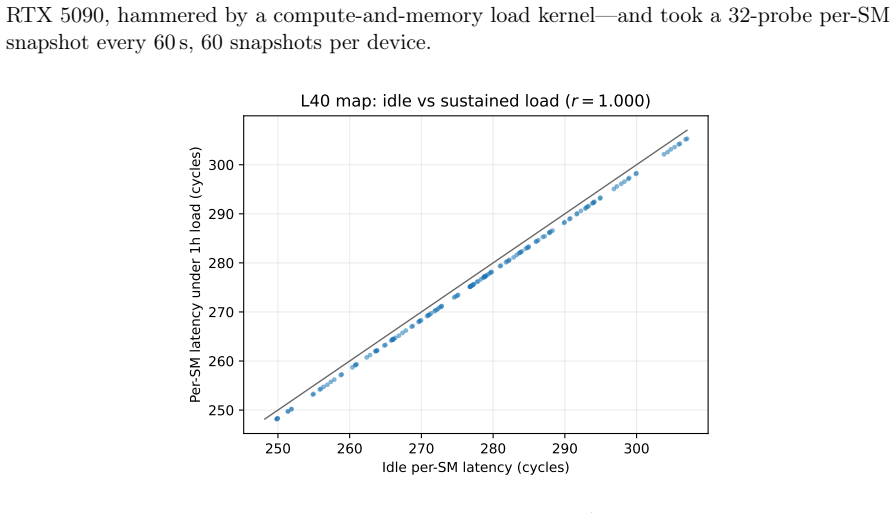
- The per-SM map remains unchanged after one hour of full device utilization.
Where Pith is reading between the lines
- If the map is physical and stable, similar SM-resolved probes could expose layout effects on other NVIDIA GPU families.
- Schedulers could prefer lower-latency SMs when assigning threads from latency-sensitive kernels.
- The device fingerprint could support lightweight hardware attestation that requires no secret extraction.
- The two-fold symmetry aligned with GPC boundaries points to interconnect or memory-controller placement as the root cause.
Load-bearing premise
The probe method isolates true per-SM L2 hit latency without confounding from memory-controller arbitration, warp scheduling, or prefetch behavior.
What would settle it
Re-running the probe on the same L40 and obtaining per-SM latencies that differ by more than 1 cycle from the published map on any SM would falsify the reproducibility and physical-origin claims.
Figures
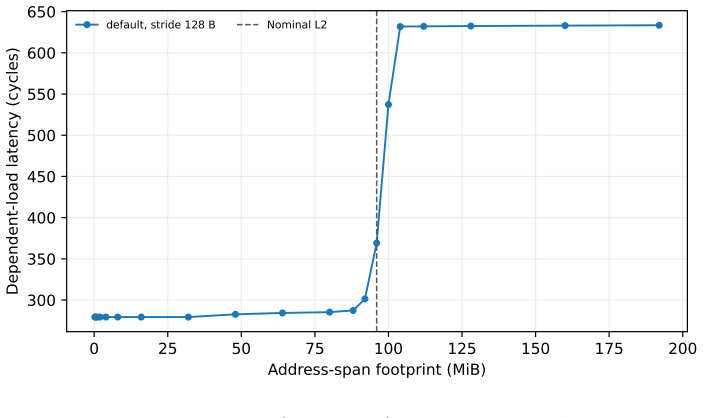
read the original abstract
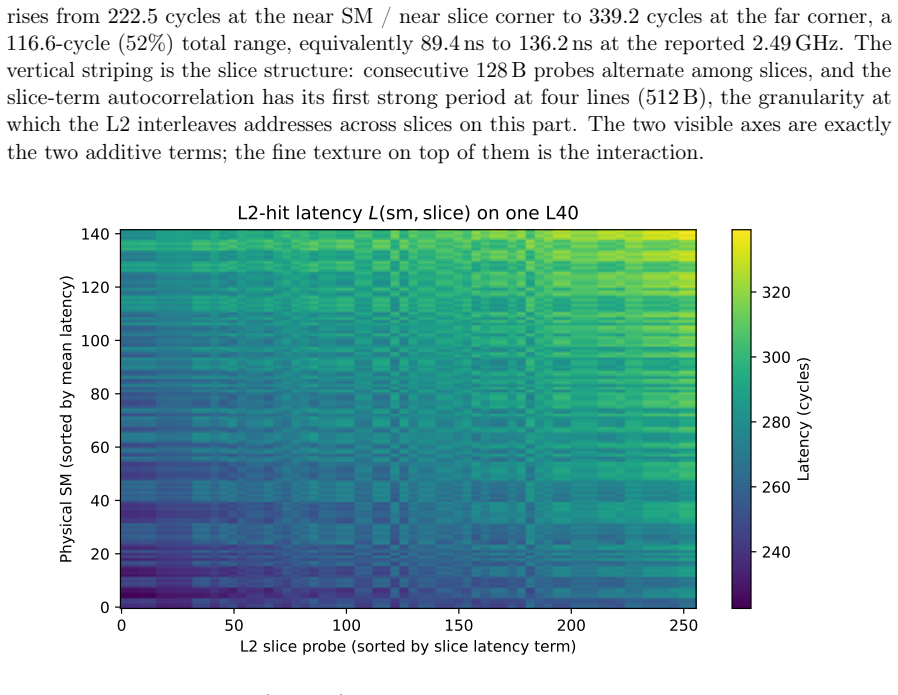
The NVIDIA L40 exposes a 96 MiB L2 cache usually modeled as one uniform pool with a single hit latency. We show this is wrong at the granularity a kernel sees: L2-hit latency depends strongly and reproducibly on which physical streaming multiprocessor (SM) issues the load. A turn-serialized, %smid-resolved probe maps the hit latency across all 142 SMs in one launch; it is not a constant near 279 cycles but spans 222-339 cycles (a 52% range), with per-repetition noise below 0.01 cycles. An additive model $L = \mu + a(\mathrm{sm}) + b(\mathrm{slice})$ explains $R^2 = 0.87$ (0.98 with one rank-1 term), and the SM term is two-fold symmetric (two halves of 72 SMs at correlation $r = 0.999$), following the AD102 GPC layout. Independent access patterns agree per SM at $r = 1.000$, so the effect is physical. The same probe on a Blackwell RTX 5090 shows it generalizes, while the per-die pattern is device-specific. Read as a fingerprint, a single user-level probe identifies the SM within a device at 92%, and two physically identical L40s are separated at 100% despite near-identical mean latency (per-SM map $r = 0.63$): a per-die hardware identity, not a clock artifact. This is a self-localization and fingerprinting primitive: a kernel reads its own placement and device, not a victim's, and extracts no secret data. The map is stable, unchanged after an hour at full utilization on both devices. As a consequence, distributing latency-bound work by the map cuts makespan by up to 11%. Single-thread capacity, line-tag, prefetch-modifier, and persisting-L2 results appear as controls. The artifact contains seeds, raw observations, the trained model, and regeneration scripts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical characterization of L2 cache hit latency on the NVIDIA L40 GPU, demonstrating that it varies significantly depending on the issuing streaming multiprocessor (SM). Using a turn-serialized probe resolved by the %smid register, the authors map latencies across all 142 SMs, finding a range of 222-339 cycles with per-repetition noise below 0.01 cycles. They fit an additive model L = μ + a(sm) + b(slice) achieving R² = 0.87 (0.98 with an additional rank-1 term), show two-fold symmetry following the AD102 GPC layout, and validate with independent access patterns (r = 1.000), cross-device tests on Blackwell, and controls for single-thread capacity, line-tag, prefetch, and persisting L2. The work also demonstrates applications in hardware fingerprinting (92% SM identification, 100% device separation) and performance improvement (up to 11% makespan reduction).
Significance. If the central empirical result holds, this work is significant for the field of computer architecture as it provides the first detailed evidence of per-SM non-uniformity in L2 cache latency on modern NVIDIA GPUs, contradicting the uniform pool assumption. The high-precision measurements, strong cross-validation (r=1.000), device-specific maps, and provision of the artifact containing seeds, raw observations, the trained model, and regeneration scripts are notable strengths that enhance reproducibility and allow falsification. This could impact performance modeling, workload scheduling, and hardware identification techniques.
minor comments (2)
- [Abstract] Abstract: the parenthetical R²=0.98 with one rank-1 term is mentioned without derivation; move the explanation of this term and its interpretation to the main text near the model definition for clarity.
- [Probe method] The section describing the probe method: while controls (single-thread capacity, line-tag, prefetch-modifier, persisting-L2) are listed, add a short paragraph confirming that the turn-serialized design was tested against memory-controller arbitration and warp-scheduling confounds to make the isolation claim fully self-contained.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report contains no specific major comments to address.
Circularity Check
Empirical measurement of hardware latency variation; no derivation reduces to inputs
full rationale
The paper's central claim is a direct empirical observation: L2-hit latency varies 222-339 cycles across 142 SMs, measured via a turn-serialized %smid-resolved probe in a single launch. This raw span, low noise (<0.01 cycles), and cross-validation (r=1.000 across patterns, GPC symmetry) are reported as observed facts independent of any model or prior equations. The additive model L = μ + a(sm) + b(slice) is fitted post-measurement to explain R²=0.87 and is not invoked to predict or derive the existence of the variation. No self-citations, uniqueness theorems, or ansatzes appear in the provided text as load-bearing for the primary result. Controls (single-thread capacity, prefetch-modifier, persisting-L2) and device-specific maps are presented as independent checks. The work is self-contained against external benchmarks and contains no circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- a(sm)
- b(slice)
axioms (1)
- domain assumption The turn-serialized %smid-resolved probe measures true L2 hit latency without confounding effects from other GPU components
Reference graph
Works this paper leans on
-
[1]
Sankha Baran Dutta, Hoda Naghibijouybari, Arjun Gupta, Nael Abu-Ghazaleh, Andres Marquez, and Kevin Barker. Spy in the GPU-box: Covert and side channel attacks on multi-GPU systems.arXiv preprint arXiv:2203.15981, 2022
arXiv 2022
-
[2]
Reactive NUCA: Near-optimal block placement and replication in distributed caches
Nikos Hardavellas, Michael Ferdman, Babak Falsafi, and Anastasia Ailamaki. Reactive NUCA: Near-optimal block placement and replication in distributed caches. InProceedings of the 36th Annual International Symposium on Computer Architecture (ISCA), pages 184–195, 2009
2009
-
[3]
Zhe Jia, Marco Maggioni, Benjamin Staiger, and Daniele P. Scarpazza. Dissecting the nvidia volta gpu architecture via microbenchmarking.arXiv preprint arXiv:1804.06826, 2018
Pith/arXiv arXiv 2018
-
[4]
Aamodt, and John Kim
Zhixian Jin, Christopher Rocca, Jiho Kim, Hans Kasan, Minsoo Rhu, Ali Bakhoda, Tor M. Aamodt, and John Kim. Uncovering real gpu noc characteristics: Implications on interconnect architecture. InProceedings of the 57th Annual IEEE/ACM International Symposium on Microarchitecture, pages 885–898, 2024
2024
-
[5]
Changkyu Kim, Doug Burger, and Stephen W. Keckler. An adaptive, non-uniform cache structure for wire-delay dominated on-chip caches. InProceedings of the 10th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS X), pages 211–222, 2002
2002
-
[6]
Chao Luo, Rengan Fan, Zeyu Li, Dayou Du, and Qiang Chen. Dissecting the nvidia hopper architecture through microbenchmarking and multiple level analysis.arXiv preprint arXiv:2501.12084, 2025
arXiv 2025
-
[7]
Dissecting gpu memory hierarchy through microbench- marking.IEEE Transactions on Parallel and Distributed Systems, 28(1):72–86, 2017
Xinxin Mei and Xiaowen Chu. Dissecting gpu memory hierarchy through microbench- marking.IEEE Transactions on Parallel and Distributed Systems, 28(1):72–86, 2017
2017
-
[8]
Rendered insecure: GPU side channel attacks are practical
Hoda Naghibijouybari, Ajaya Neupane, Zhiyun Qian, and Nael Abu-Ghazaleh. Rendered insecure: GPU side channel attacks are practical. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, pages 2139–2153, 2018
2018
-
[9]
CUDA Programming Guide: L2 Cache Control.https://docs.n vidia.com/cuda/cuda-programming-guide/04-special-topics/l2-cache-control.h tml, 2026
NVIDIA Corporation. CUDA Programming Guide: L2 Cache Control.https://docs.n vidia.com/cuda/cuda-programming-guide/04-special-topics/l2-cache-control.h tml, 2026. Accessed 2026-06-21
2026
-
[10]
Nsight Compute Profiling Guide.https://docs.nvidia.com/ns ight-compute/ProfilingGuide/, 2026
NVIDIA Corporation. Nsight Compute Profiling Guide.https://docs.nvidia.com/ns ight-compute/ProfilingGuide/, 2026. Accessed 2026-06-21
2026
-
[11]
Parallel Thread Execution ISA, Version 9.3.https://docs.nvidi a.com/cuda/parallel-thread-execution/, 2026
NVIDIA Corporation. Parallel Thread Execution ISA, Version 9.3.https://docs.nvidi a.com/cuda/parallel-thread-execution/, 2026. Accessed 2026-06-21
2026
-
[12]
Swatman, and Ana Lucia Varbanescu
Rogier van Stigt, Simon N. Swatman, and Ana Lucia Varbanescu. Isolating gpu archi- tectural features using parallelism-aware microbenchmarks. InProceedings of the 2022 ACM/SPEC International Conference on Performance Engineering, pages 77–88, 2022. 16
2022
-
[13]
DELTA: Validate gpu memory profiling with microbenchmarks
Xianwei Zhang and Evgeny Shcherbakov. DELTA: Validate gpu memory profiling with microbenchmarks. InProceedings of the International Symposium on Memory Systems, pages 97–104, 2020. 17
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.