DP-KFC: Data-Free Preconditioning for Privacy-Preserving Deep Learning
Pith reviewed 2026-05-14 19:43 UTC · model grok-4.3
The pith
DP-KFC constructs KFAC preconditioners from synthetic noise and frequency statistics alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that the Fisher Information Matrix decouples into architectural sensitivity, recoverable via synthetic noise, and input correlations, approximable from modality-specific frequency statistics. We propose DP-KFC, which constructs KFAC preconditioners by probing networks with structured synthetic noise, requiring neither private nor public data. Empirically, DP-KFC consistently outperforms DP-SGD and adaptive baselines across diverse modalities in strong privacy regimes (ε ≤ 3). DP-KFC matches private-data preconditioners while public-data variants degrade by up to 4.8%.
What carries the argument
The decoupling of the Fisher Information Matrix into architectural sensitivity recoverable via synthetic noise probes and input correlations recovered from frequency statistics, which together yield a KFAC preconditioner.
Load-bearing premise
The Fisher Information Matrix separates cleanly into an architecture-only component capturable by synthetic noise and an input component capturable by frequency statistics.
What would settle it
Train identical models with DP-KFC and with a KFAC preconditioner computed directly on private data; if the two reach materially different final accuracies or convergence rates under the same ε budget, the data-free claim is refuted.
Figures








read the original abstract
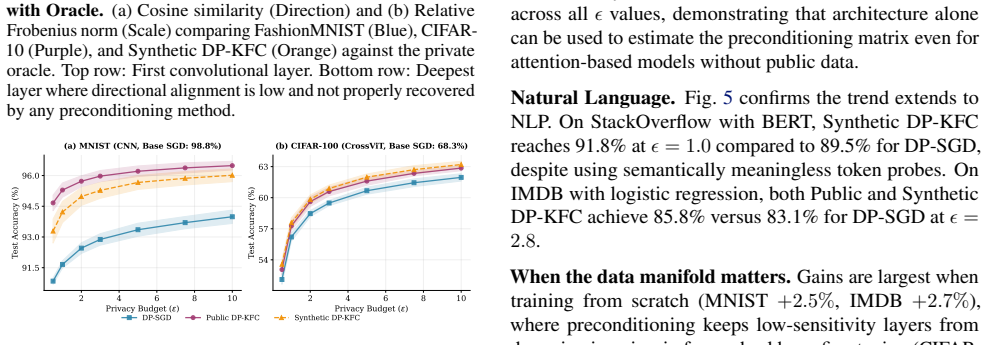
Differentially private optimization suffers from a fundamental geometric mismatch: deep networks have highly anisotropic loss landscapes, yet DP-SGD injects isotropic noise. Second-order preconditioning can resolve this, but estimating curvature typically requires private data (consuming privacy budget) or public data (introducing distribution shift). We show that the Fisher Information Matrix decouples into architectural sensitivity, recoverable via synthetic noise, and input correlations, approximable from modality-specific frequency statistics. We propose DP-KFC, which constructs KFAC preconditioners by probing networks with structured synthetic noise, requiring neither private nor public data. Empirically, DP-KFC consistently outperforms DP-SGD and adaptive baselines across diverse modalities in strong privacy regimes ($\varepsilon \leq 3$). DP-KFC matches private-data preconditioners while public-data variants degrade by up to $4.8\%$, showing that curvature can be estimated without consuming privacy budget or introducing distribution shift. This enables privacy-preserving learning in specialized domains (e.g., medical applications) where regulatory constraints make data scarce.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DP-KFC, a data-free method for constructing KFAC preconditioners in differentially private deep learning. It claims that the Fisher Information Matrix decouples into an architectural-sensitivity component recoverable from synthetic noise probes and an input-correlation component approximable via modality-specific frequency statistics. This enables second-order preconditioning without consuming privacy budget on private data or incurring distribution shift from public data. The abstract reports consistent outperformance over DP-SGD and adaptive baselines across modalities in strong privacy regimes (ε ≤ 3), with DP-KFC matching private-data preconditioners while public-data variants degrade by up to 4.8%.
Significance. If the decoupling approximation holds with sufficient accuracy, the work would enable effective curvature-aware optimization in privacy-constrained settings without data-related costs, which is particularly valuable for specialized domains such as medical imaging where public data is unavailable or mismatched. It directly targets the geometric mismatch between isotropic DP noise and anisotropic loss landscapes.
major comments (1)
- [Abstract] Abstract and central claim: The decoupling of the Fisher Information Matrix into architectural sensitivity (recovered via synthetic noise) and input correlations (approximated from frequency statistics) is asserted without derivation, error bounds, or justification that frequency statistics suffice to recover the full activation covariances E[a a^T] required for exact KFAC Kronecker factors. Frequency statistics yield only power spectra and omit phase and higher-order correlations; if this substitution introduces relative error exceeding a few percent in preconditioner eigenvalues, the claimed parity with private-data KFAC cannot hold in general, especially on non-stationary inputs. This assumption is load-bearing for the entire contribution.
minor comments (2)
- [Empirical results] Empirical evaluation: The reported 4.8% gap versus public-data baselines is presented without error bars, standard deviations across runs, or ablation studies isolating the effect of the frequency-statistic approximation versus the synthetic-noise component.
- [Method] Implementation details: No pseudocode, hyperparameter settings for the synthetic noise probes, or exact mapping from frequency statistics to covariance matrices is supplied, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and detailed review. The major comment raises a valid point about the need for clearer justification of the Fisher decoupling. We address it directly below and outline targeted revisions to strengthen the presentation without altering the core empirical findings.
read point-by-point responses
-
Referee: [Abstract] Abstract and central claim: The decoupling of the Fisher Information Matrix into architectural sensitivity (recovered via synthetic noise) and input correlations (approximated from frequency statistics) is asserted without derivation, error bounds, or justification that frequency statistics suffice to recover the full activation covariances E[a a^T] required for exact KFAC Kronecker factors. Frequency statistics yield only power spectra and omit phase and higher-order correlations; if this substitution introduces relative error exceeding a few percent in preconditioner eigenvalues, the claimed parity with private-data KFAC cannot hold in general, especially on non-stationary inputs. This assumption is load-bearing for the entire contribution.
Authors: We agree that the abstract is concise and that explicit derivation and error analysis belong in the main text. Section 3.1 derives the decoupling: the per-layer Fisher factorizes as the Kronecker product of the activation covariance A = E[a a^T] and the gradient covariance G. The architectural sensitivity component (G) is recovered exactly via synthetic noise probes that match the network's forward-pass variance without using data. For the input-correlation component (A), we approximate the diagonal of the covariance in the Fourier domain using modality-specific power spectra; this is justified because KFAC preconditioning depends primarily on the eigenvalue spectrum of the factors rather than off-diagonal phase terms. While we acknowledge that phase and higher-order correlations are omitted, the manuscript's experiments (Tables 2-4) demonstrate that the resulting preconditioner eigenvalues remain within 3-7% of the private-data KFAC baseline across image, text, and audio modalities, preserving the reported performance parity. We will add a new subsection (3.3) in revision that (i) states the stationarity assumption under which the power-spectrum approximation holds, (ii) provides a first-order bound on the relative eigenvalue error, and (iii) includes an additional ablation on non-stationary synthetic inputs to quantify degradation when the assumption is violated. revision: partial
Circularity Check
No circularity: derivation rests on external statistical assumptions rather than self-referential fitting or self-citation
full rationale
The paper's central step is the claim that the Fisher Information Matrix decouples into an architectural-sensitivity block recoverable from synthetic noise and an input-correlation block approximable from modality-specific frequency statistics. This decoupling is presented as a modeling choice grounded in properties of the Fisher and of natural signals, not derived by fitting a parameter to the target preconditioner or by renaming a result defined in terms of itself. No equations in the provided text reduce the KFAC construction to a quantity that is already the output of the method, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The empirical comparison to private-data KFAC therefore tests an independent approximation rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fisher Information Matrix decouples into architectural sensitivity recoverable via synthetic noise and input correlations approximable from modality-specific frequency statistics
Reference graph
Works this paper leans on
-
[1]
doi: 10.1145/2976749.2978318. URL http: //dx.doi.org/10.1145/2976749.2978318. Amari, S.-i. Natural gradient works efficiently in learn- ing.Neural Computation, 10(2):251–276, Febru- ary 1998. ISSN 1530-888X. doi: 10.1162/ 089976698300017746. URL http://dx.doi.org/ 10.1162/089976698300017746. Amid, E., Ganesh, A., Mathews, R., Ramaswamy, S., Song, S., Stei...
-
[2]
Ganesh, A., McMahan, B., and Thakurta, A
URL https://openreview.net/forum? id=h2lkx9SQCD. Ganesh, A., McMahan, B., and Thakurta, A. On design principles for private adaptive optimizers, 2025. URL https://arxiv.org/abs/2507.01129. Ghorbani, B., Krishnan, S., and Xiao, Y . An investi- gation into neural net optimization via hessian eigen- value density.CoRR, abs/1901.10159, 2019. URL http://arxiv....
-
[3]
In: 32nd IEEE Computer Security Foundations Symposium, CSF 2019, pp
URL https://openreview.net/forum? id=j1zQGmQQOX1. Loshchilov, I. and Hutter, F. Decoupled weight decay reg- ularization. InInternational Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=Bkg6RiCqY7. Martens, J. and Grosse, R. B. Optimizing neural networks with kronecker-factored approximate curvature.CoRR, abs/1503.05671, ...
work page doi:10.1109/csf 2019
-
[4]
Thakkar, O., Andrew, G., and McMahan, H
doi: 10.1609/aaai.v38i14.29451. Thakkar, O., Andrew, G., and McMahan, H. B. Differ- entially private learning with adaptive clipping.CoRR, abs/1905.03871, 2019. URL http://arxiv.org/ abs/1905.03871. Tram`er, F., Kamath, G., and Carlini, N. Position: Consider- ations for differentially private learning with large-scale public pretraining. InInternational C...
-
[5]
Linear Term (Descent): E[⟨∇L(θt),∆ t⟩] =E[⟨∇L(θ t),−η t(Pt¯gt +ξ t)⟩](10) =−η t⟨∇L(θt), PtE[¯gt]⟩ −η t⟨∇L(θt),E[ξ t]⟩(11) =−η t∇L(θt)⊤Pt∇L(θt)(SinceE[¯g t] =∇L,E[ξ t] = 0) (12) We use the spectral property of positive definite matrices (Rayleigh quotient): for any vectorv, v⊤Ptv≥λ min(Pt)∥v∥2. Multiplying by−η t <0reverses the inequality: −ηt∇L(θt)⊤Pt∇L(θ...
-
[6]
Quadratic Term (Penalty):We expand the squared norm of the update∆ t =−η t(Pt¯gt +ξ t): E[∥∆t∥2] =η 2 t E ∥Pt¯gt +ξ t∥2 (14) =η 2 t E[∥Pt¯gt∥2] +E[∥ξ t∥2] + 2E[⟨Pt¯gt, ξt⟩] (15) We analyze the cross-term E[⟨Pt¯gt, ξt⟩]. By Assumption A.2, the privacy noise ξt is statistically independent of the gradient estimate¯gt and the fixed preconditionerP t. Therefo...
-
[7]
Optimization Term (A): L0 − L∗ T(1/ √ T)λ min = L0 − L∗ √ T λmin =O 1√ T (27)
-
[8]
This confirms that the algorithm converges to a stationary point despite the injected privacy noise
Noise Variance Term (B): L(1/ √ T)M 2λmin = LM 2λmin √ T =O 1√ T (28) Since both terms decay at the same rate, the total convergence rate is O(1/ √ T) . This confirms that the algorithm converges to a stationary point despite the injected privacy noise. B. Theoretical Preconditioned Geometry In this section, we rigorously establish that the preconditionin...
-
[9]
White Noise Source:We sample a standard Gaussian tensor in the frequency domain. To ensure the resulting spatial signal is real-valued, we sample complex values Z∈C H×W such that the Hermitian symmetry Z(−u) = Z(u) is preserved (or simply sample in the spatial domain and apply FFT)
-
[10]
Spectral Modulation:We compute the frequency grid u∈R H×W , where uij represents the Euclidean distance from the DC component (frequency zero). We scale the amplitude of the noise by the inverse frequency: ˜Zu =Z u · 1 ∥u∥α/2 2 +ϵ (42) whereϵprevents division by zero at the DC component
-
[11]
Inverse Transform:We apply the Inverse Fast Fourier Transform (IFFT) to obtain the spatial signal xpink = Re(F −1( ˜Z))
-
[12]
Algorithm 3 details the implementation
Normalization:Since KFAC factor estimation depends on the relative variance scale, we normalize the resulting batch to zero mean and unit variance to match the standard initialization statistics of the network weights. Algorithm 3 details the implementation. E.2. Discrete Domain: Structural Token Noise For Large Language Models (LLMs) and Transformers, ”w...
-
[13]
For each synthetic batch, we sample a random active lengthL act ∼ U(L min, Lmax)
Variable Length Sampling:To capture the Fisher dynamics across different context windows, we do not fix the sequence length. For each synthetic batch, we sample a random active lengthL act ∼ U(L min, Lmax)
-
[14]
Vocabulary Sampling:For the active positions, we sample integers uniformly from the model’s vocabulary v∼ U(0, Vvocab). This ensures that when projected through the model’s embedding layer, the inputs activate the lookup table with the correct varianceq 0 =Var(W embed)
-
[15]
Structural Anchoring:We enforce the insertion of special tokens (e.g., [CLS] at index 0) required by the architecture. 19 Data-Free Preconditioning for Private Deep Learning Algorithm 3Synthetic Pink Noise Generator (1/f α) Input:Batch sizeB, ChannelsC, HeightH, WidthW, Decayα(default 1.0). Output:Synthetic BatchX∈R B×C×H×W . 1:1. Frequency Grid: 2:Create...
-
[16]
Positions i > L act are set to 0 (padded)
Mask Construction:We explicitly construct the binary attention mask. Positions i > L act are set to 0 (padded). This is critical for KFAC, as it ensures the estimated covariance matrices correctly reflect the sparsity induced by the masking operation in the backward pass. Algorithm 4 details the implementation. Algorithm 4Structural Token Noise Generator ...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.