ACALSim: A Scalable Parallel Simulation Framework for High-Performance System Design Space Exploration
Pith reviewed 2026-05-25 05:31 UTC · model grok-4.3
The pith
ACALSim supplies a pluggable thread-management architecture that lets simulator developers add custom scheduling to reach over 14x faster intra-node scaling than SST on large GPU workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
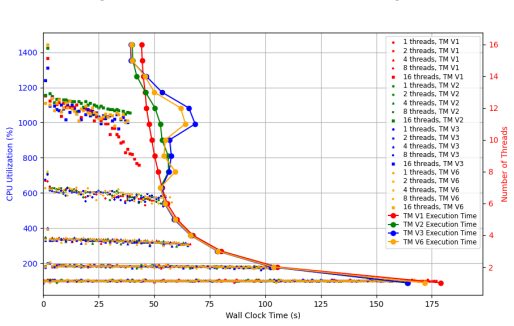
ACALSim is a scalable parallel simulation framework whose key innovation is a pluggable thread-management architecture that lets developers implement custom scheduling strategies tailored to specific simulation patterns. It adds event-driven execution with fast-forward to remove idle-cycle overhead, a shared-memory data model for zero-copy communication, and a two-phase parallel execution model for deterministic thread scaling. When HPCSim is built on top of it for A100-class architectures, the framework delivers over 14x speedup and 41 percent lower memory footprint versus an SST implementation that uses identical shared timing cores, while SST fails to finish 256-plus thread-block runs and
What carries the argument
The pluggable thread-management architecture that exposes hooks for developers to implement custom scheduling strategies tailored to their workloads.
If this is right
- Design-space exploration becomes feasible for full transformer layers on A100-class hardware that SST cannot simulate in practical time.
- Simulator developers gain the ability to match thread scheduling to the dataflow patterns of specific accelerators without rewriting the core engine.
- Hardware correlation studies can now be performed on larger models, with reported cycle-count accuracy of 0.72 to 1.22 times measured A100 values.
- Memory footprint reductions of 41 percent allow single-node runs that would otherwise require multi-node MPI setups.
Where Pith is reading between the lines
- If the pluggable interface is adopted, other simulation domains such as CPU or network modeling could add similar custom schedulers to improve their own intra-node scaling.
- The zero-copy shared-memory model may reduce communication costs enough to make single-node execution competitive with multi-node approaches for mid-sized accelerator designs.
- Workload-specific scheduling could expose new bottlenecks in timing models that were previously masked by fixed threading policies.
Load-bearing premise
The SST comparison uses identical shared timing cores so that the reported speedup and memory reduction come only from ACALSim's framework features and not from differences in workload partitioning or measurement.
What would settle it
A controlled re-run of the same LLaMA workloads in which every non-framework difference between the ACALSim and SST implementations is removed and the speedup disappears.
Figures










read the original abstract
Architectural simulation has become the critical bottleneck limiting design space exploration for high-performance computing systems. Modern GPUs and AI accelerators -- with hundreds to thousands of tightly-coupled components -- demand simulation frameworks that deliver efficient parallelism and scalable single-node execution. Existing frameworks fall short: SST focuses on multi-node MPI scalability but struggles with intra-node scaling, while GPGPU-Sim remains largely single-threaded. Critically, none expose a mechanism for users to optimize threading for their specific workloads. We introduce ACALSim, a scalable parallel simulation framework providing infrastructure and APIs for building high-performance simulators -- timing-model accuracy remains the responsibility of simulator developers. Its key innovation is a pluggable thread-management architecture that lets developers implement custom scheduling strategies tailored to specific simulation patterns, absent in existing frameworks. Complementing it are (1) event-driven execution with fast-forward to eliminate idle-cycle overhead, (2) a shared-memory data model enabling zero-copy communication, and (3) a two-phase parallel execution model for deterministic thread scaling. We demonstrate ACALSim through HPCSim, a GPU simulator targeting A100-class architectures. Against an SST implementation using identical shared timing cores to isolate framework overhead, ACALSim achieves over 14x speedup with 41% lower memory footprint; hardware validation confirms 0.72--1.22x cycle-count correlation with A100 measurements. While SST fails to complete 256+ thread-block workloads within practical time limits, ACALSim simulates full LLaMA transformer layers (single block) in 17.7 minutes for LLaMA-7B and 30.4 minutes for LLaMA-13B -- enabling design space exploration that SST cannot achieve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ACALSim, a parallel simulation framework for high-performance computing systems featuring a pluggable thread-management architecture, event-driven execution with fast-forward, a shared-memory data model for zero-copy communication, and a two-phase parallel execution model. Demonstrated through the HPCSim GPU simulator targeting A100-class architectures, it claims over 14x speedup and 41% lower memory footprint versus an SST implementation using identical shared timing cores, hardware cycle-count correlation of 0.72-1.22x, and the ability to complete LLaMA-7B/13B transformer layer simulations (17.7 and 30.4 minutes) where SST cannot handle 256+ thread-block workloads.
Significance. If the performance and correlation claims hold after detailed validation, ACALSim would address a critical scalability gap in intra-node architectural simulation for GPUs and AI accelerators, enabling design-space exploration of large workloads that current tools like SST cannot complete in practical time. The pluggable threading API is a concrete advance over existing frameworks.
major comments (2)
- [Abstract] Abstract (and implied Results section): The central claim of >14x speedup and 41% memory reduction rests on comparison to 'an SST implementation using identical shared timing cores to isolate framework overhead,' but the manuscript provides no description of the SST port construction, including event scheduling, fast-forward logic, shared-memory data model equivalence, thread-block partitioning, or measurement of completion (wall-clock vs. simulated cycles). This directly affects whether the reported gains can be attributed to the ACALSim framework.
- [Abstract] Abstract: Workload definitions, error bars, raw timing data, and hardware measurement methodology for the 0.72-1.22x cycle-count correlation and LLaMA layer timings are absent, which is load-bearing for assessing reproducibility and whether post-hoc choices affect the scalability claims versus SST.
minor comments (1)
- The abstract states concrete numerical claims without referencing a dedicated methods or experimental setup subsection; adding one would improve clarity even if the core claims are sound.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the manuscript requires additional methodological details to support the performance and correlation claims, and we will revise the paper to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract (and implied Results section): The central claim of >14x speedup and 41% memory reduction rests on comparison to 'an SST implementation using identical shared timing cores to isolate framework overhead,' but the manuscript provides no description of the SST port construction, including event scheduling, fast-forward logic, shared-memory data model equivalence, thread-block partitioning, or measurement of completion (wall-clock vs. simulated cycles). This directly affects whether the reported gains can be attributed to the ACALSim framework.
Authors: We acknowledge that the current manuscript does not provide sufficient detail on the SST baseline construction. In the revised version we will add a dedicated subsection (likely in Section 5 or a new Appendix) that describes the SST port, including the event scheduler implementation, fast-forward logic, shared-memory data model, thread-block partitioning approach, and the exact measurement protocol (wall-clock time versus simulated cycles). This will make explicit how identical timing cores were used and allow readers to attribute the reported speedups and memory reductions to ACALSim's framework features. revision: yes
-
Referee: [Abstract] Abstract: Workload definitions, error bars, raw timing data, and hardware measurement methodology for the 0.72-1.22x cycle-count correlation and LLaMA layer timings are absent, which is load-bearing for assessing reproducibility and whether post-hoc choices affect the scalability claims versus SST.
Authors: We agree these elements are necessary for reproducibility. The revised manuscript will include: explicit workload definitions (thread-block counts, layer configurations, and input sizes for the LLaMA experiments), error bars on all timing and speedup figures, selected raw timing data (in an appendix or supplementary table), and a detailed account of the hardware measurement methodology used for A100 cycle-count correlation as well as the wall-clock timings for the LLaMA-7B/13B layers. These additions will allow independent assessment of the claims. revision: yes
Circularity Check
No circularity: empirical performance claims only
full rationale
The paper introduces ACALSim as a pluggable thread-management framework and reports direct empirical results (14x speedup, 41% memory reduction, LLaMA simulation times, 0.72-1.22x hardware correlation) against an SST baseline and A100 measurements. No equations, fitted parameters, predictions derived from prior fits, or self-citation chains appear in the provided text. The central claims rest on implementation-level timing comparisons that are externally falsifiable and do not reduce to any self-definitional or fitted-input structure. This is the expected non-finding for a systems paper whose value is in measured runtime behavior rather than any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Bakhoda, G. L. Yuan, W. W. L. Fung, H. Wong, and T. M. Aamodt. 2009. Analyzing CUDA workloads using a detailed GPU simulator. In2009 IEEE International Symposium on Performance Analysis of Systems and Software. 163–174. doi:10.1109/ISPASS.2009.4919648
-
[2]
J. Bang, Y. Choi, M. Kim, Y. Kim, and M. Rhu. 2024. vTrain: A Simulation Framework for Evaluating Cost-Effective and Compute-Optimal Large Language Model Training. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). 153–167. doi:10.1109/MICRO61859.2024.00021 Proc. ACM Meas. Anal. Comput. Syst., Vol. 10, No. 2, Article 28. Publicatio...
-
[3]
I. Böhm, B. Franke, and N. Topham. 2010. Cycle-accurate performance modelling in an ultra-fast just-in-time dy- namic binary translation instruction set simulator. In2010 International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation. 1–10. doi:10.1109/ICSAMOS.2010.5642102
-
[4]
Carothers, David Bauer, and Shawn Pearce
Christopher D. Carothers, David Bauer, and Shawn Pearce. 2002. ROSS: A high-performance, low-memory, modular Time Warp system.J. Parallel and Distrib. Comput.62, 11 (2002), 1648–1669. doi:10.1016/S0743-7315(02)00004-7
-
[5]
V. Catania, A. Mineo, S. Monteleone, M. Palesi, and D. Patti. 2015. Noxim: An open, extensible and cycle-accurate network on chip simulator. In2015 IEEE 26th International Conference on Application-specific Systems, Architectures and Processors (ASAP). 162–163. doi:10.1109/ASAP.2015.7245728
-
[6]
S. P. Chenna, M. Steyer, N. Kumar, M. Garzaran, and P. Thierry. 2024. Modeling and Simulation of Collective Algorithms on HPC Network Topologies using Structural Simulation Toolkit. InSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. 909–916. doi:10.1109/SCW63240.2024.00129
-
[7]
J. Cho, M. Kim, H. Choi, G. Heo, and J. Park. 2024. LLMServingSim: A HW/SW Co-Simulation Infrastructure for LLM Inference Serving at Scale. In2024 IEEE International Symposium on Workload Characterization (IISWC). 15–29. doi:10.1109/IISWC63097.2024.00012
-
[8]
J. Choquette. 2023. NVIDIA Hopper H100 GPU: Scaling Performance.IEEE Micro43, 3 (2023), 9–17. doi:10.1109/MM. 2023.3256796
work page doi:10.1109/mm 2023
- [9]
-
[10]
Z. Guo et al. 2024. A Survey on Performance Modeling and Prediction for Distributed DNN Training.IEEE Transactions on Parallel and Distributed Systems35, 12 (2024), 2463–2478. doi:10.1109/TPDS.2024.3476390
-
[11]
H. Ham et al. 2024. ONNXim: A Fast, Cycle-Level Multi-Core NPU Simulator.IEEE Computer Architecture Letters23, 2 (2024), 219–222. doi:10.1109/LCA.2024.3484648
-
[12]
A. Ishii et al. 2018. NVSwitch and DGX-2: NVLink-Switching chip and scale-up compute server. InHot Chips 30
work page 2018
-
[13]
S. Karandikar et al. 2018. FireSim: FPGA-Accelerated Cycle-Exact Scale-Out System Simulation in the Public Cloud. In 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA). 29–42. doi:10.1109/ISCA.2018. 00014
- [14]
- [15]
-
[16]
S. Lee, A. Phanishayee, and D. Mahajan. 2025. Forecasting GPU Performance for Deep Learning Training and Inference. InProc. 30th ACM Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25), Vol. 1. 493–508. doi:10.1145/3669940.3707265
-
[17]
In: 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pp
W. Luo et al. 2024. Benchmarking and Dissecting the Nvidia Hopper GPU Architecture. In2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 656–667. doi:10.1109/IPDPS57955.2024.00064
-
[18]
P. S. Magnusson et al. 2002. Simics: A full system simulation platform.Computer35, 2 (2002), 50–58. doi:10.1109/2.982916
-
[19]
O. Matthews et al. 2020. MosaicSim: A Lightweight, Modular Simulator for Heterogeneous Systems. In2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 136–148. doi:10.1109/ISPASS48437. 2020.00029
-
[20]
L. Mei, P. Houshmand, V. Jain, S. Giraldo, and M. Verhelst. 2021. ZigZag: Enlarging Joint Architecture-Mapping Design Space Exploration for DNN Accelerators.IEEE Trans. Comput.70, 8 (2021), 1160–1174. doi:10.1109/TC.2021.3059962
-
[21]
Christian Menard, Jerónimo Castrillón, Matthias Jung, and Norbert Wehn. 2017. System simulation with gem5 and SystemC: The keystone for full interoperability. In2017 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS). 62–69. doi:10.1109/SAMOS.2017.8344612
-
[22]
NVIDIA. 2024. NVIDIA DGX H100/H200 User Guide. https://docs.nvidia.com/dgx/dgxh100-user-guide/dgxh100-user- guide.pdf
work page 2024
-
[23]
Preeti Ranjan Panda. 2001. SystemC: a modeling platform supporting multiple design abstractions. InProceedings of the 14th international symposium on Systems synthesis (ISSS ’01). ACM, 75–80. doi:10.1145/500001.500018
-
[24]
A. Parashar et al. 2019. Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 304–315. doi:10.1109/ISPASS.2019.00042
-
[25]
A. F. Rodrigues, K. S. Hemmert, B. W. Barrett, C. Kersey, R. Oldfield, M. Weston, R. Risen, J. Cook, P. Rosenfeld, E. Cooper-Balis, and B. Jacob. 2011. The structural simulation toolkit.SIGMETRICS Perform. Eval. Rev.38, 4 (2011), 37–42. doi:10.1145/1964218.1964225
-
[26]
A. Samajdar, J. M. Joseph, Y. Zhu, P. Whatmough, M. Mattina, and T. Krishna. 2020. A Systematic Methodology for Characterizing Scalability of DNN Accelerators using SCALE-Sim. In2020 IEEE International Symposium on Performance Proc. ACM Meas. Anal. Comput. Syst., Vol. 10, No. 2, Article 28. Publication date: June 2026. 28:24 Wei-Fen Lin et al. Analysis of...
-
[27]
Daniel Sanchez and Christos Kozyrakis. 2013. ZSim: fast and accurate microarchitectural simulation of thousand-core systems. InProceedings of the 40th Annual International Symposium on Computer Architecture (ISCA ’13). ACM, 475–486. doi:10.1145/2485922.2485963
-
[28]
O. Villa et al. 2021. Need for Speed: Experiences Building a Trustworthy System-Level GPU Simulator. In2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 868–880. doi:10.1109/HPCA51647.2021. 00077
-
[29]
J. Wang et al. 2014. Manifold: A parallel simulation framework for multicore systems. In2014 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 106–115. doi:10.1109/ISPASS.2014.6844466
-
[30]
W. Won, T. Heo, S. Rashidi, S. Sridharan, S. Srinivasan, and T. Krishna. 2023. ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale. In2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 283–294. doi:10.1109/ISPASS57527.2023.00035
-
[31]
Tse-Chen Yeh, Zin-Yuan Lin, and Ming-Chao Chiang. 2011. Enabling TLM-2.0 interface on QEMU and SystemC-based virtual platform. In2011 IEEE International Conference on IC Design & Technology. doi:10.1109/ICICDT.2011.5783207 Received January 2026; revised March 2026; accepted April 2026 Proc. ACM Meas. Anal. Comput. Syst., Vol. 10, No. 2, Article 28. Public...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.