TMP: Tree-structured Mixed-policy Pruning for Large-scale Image Generation and Editing
Pith reviewed 2026-06-26 04:57 UTC · model grok-4.3
The pith
A tree-structured pruning method compresses an 80B-parameter image model to 20B while preserving most generation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
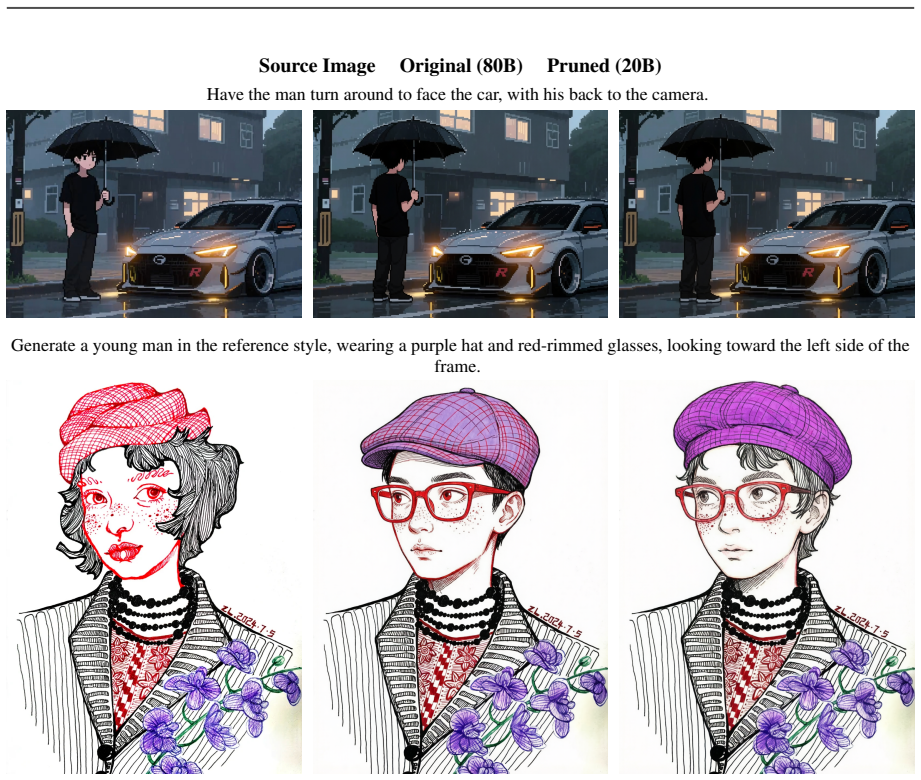
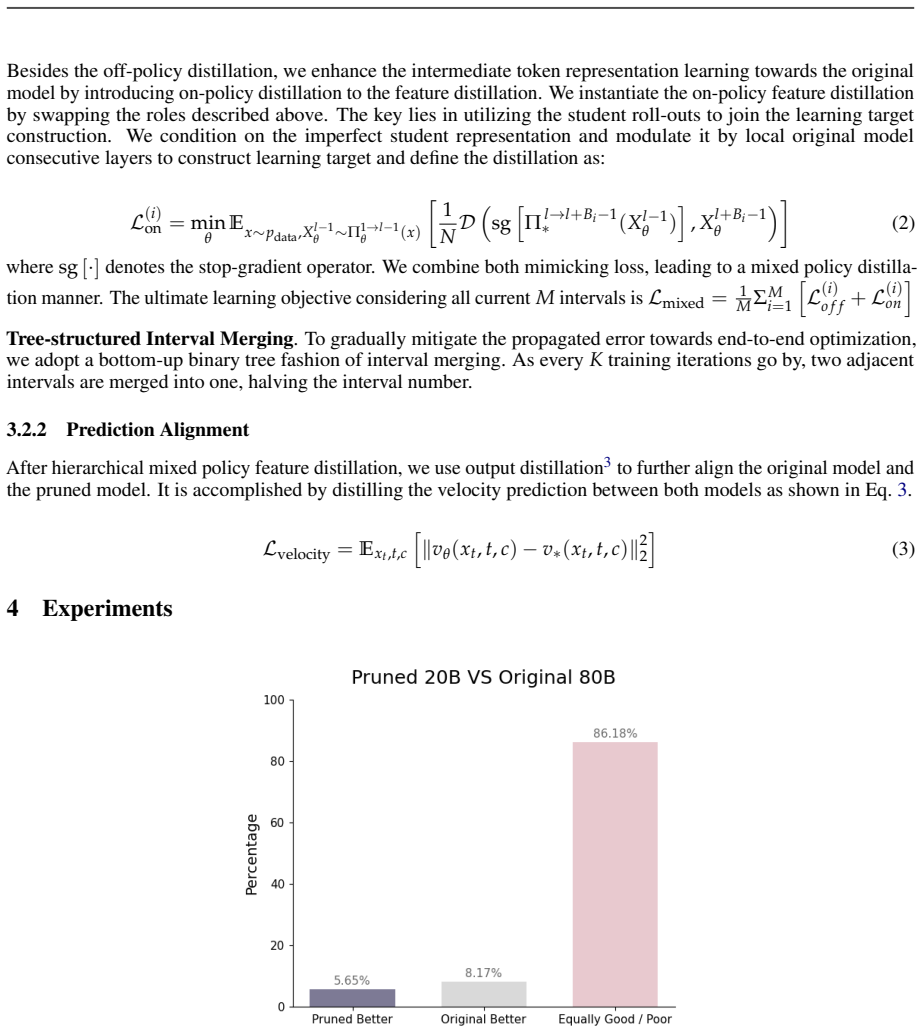
TMP is the first Tree-structured Mixed-policy Pruning framework that applies one uniform procedure to both MoE and DiT architectures across T2I and TI2I tasks, achieving a 75 percent parameter reduction on HunyuanImage 3.0 from 80B to 20B parameters with limited quality sacrifice and enabling single-GPU inference, plus a 33 percent reduction on Z-Image turbo from 6B to 4B with negligible degradation.
What carries the argument
The Tree-structured Mixed-policy Pruning (TMP) framework, which organizes pruning decisions in a tree to apply mixed policies uniformly across model layers and task types.
If this is right
- The pruned 20B model becomes runnable on consumer GPUs such as a 4090, lowering the hardware barrier for high-fidelity image synthesis.
- TMP can serve as a final compression stage after step-distillation of large models.
- The same framework delivers measurable size reductions on both very large and already-efficient image models.
- Resource requirements for training and deploying image generators drop sharply while output remains usable for practical tasks.
Where Pith is reading between the lines
- Similar structured pruning could be tested on video or 3D generation models that share MoE or DiT backbones.
- Wider availability of 20B-scale models may accelerate downstream applications such as real-time image editing on laptops.
- The tree structure might support per-task policy tuning, allowing different pruning depths for pure generation versus editing workflows.
Load-bearing premise
A single tree-structured mixed-policy pruning procedure can be applied uniformly to both Mixture-of-Experts and Diffusion transformer architectures while preserving generation quality across T2I and TI2I tasks.
What would settle it
Running the pruned 20B HunyuanImage 3.0 model and finding either substantially lower image quality scores than the 80B version or failure to execute inference on a single 24GB GPU would disprove the central claim.
Figures

read the original abstract
Modern image generation model rapidly grows their sizes to meet high-fidelity image synthesis. However, they gradually become unaffordable for their enormous parameter consumption and computation budget that lead to massive resources requirement and gpu memory footprint. In this paper, we propose TMP, the first Tree-structured Mixed-policy Pruning framework that generalizes prevalent image tasks (T2I and TI2I) and architectures (Mixture-of-Experts (MoE) and Diffusion transformer (DiT)). It could be applied to the step-distilled models and contribute as the last stage. We perform experiments upon current open-sourced SOTA HunyuanImage-3.0 instruct and a popular efficient model Z-Image turbo. The proposed pruning framework manages to compress HunyuanImage 3.0 from 80B to 20B parameters at 75% reduction ratio, sacrificing limited generation quality. We also optimize to enable the inference of the pruned 20B version of HunyuanImage 3.0 on a single 24GB 4090 GPU by engineering skills. The inference script and model weight have been integrated into the existing HunyuanImage3.0 open-source github and huggingface repository. Besides, we prove the efficacy of TMP by compressing Z-Image turbo from 6B to 4B (33% reduction) with negligible degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TMP, a tree-structured mixed-policy pruning framework asserted to generalize across T2I/TI2I tasks and MoE/DiT architectures. Experiments report compressing HunyuanImage 3.0 (80B MoE) to 20B parameters at 75% reduction with limited quality loss, enabling single-24GB-GPU inference via engineering optimizations, and compressing Z-Image turbo (6B DiT) to 4B at 33% reduction with negligible degradation; the pruned model and inference code are released in the HunyuanImage 3.0 repositories.
Significance. If the empirical claims hold under detailed scrutiny, the work would offer a practical route to deploy very large image-generation models on consumer hardware while preserving most capability, with the open-source release providing immediate reproducibility value. The attempt to unify pruning across sparse (MoE) and dense (DiT) backbones is conceptually interesting, though its load-bearing generalization claim requires stronger validation than the two reported cases supply.
major comments (2)
- [Abstract] Abstract: the central generalization claim—that a single TMP procedure works uniformly on MoE expert routing and DiT dense blocks without architecture-specific retuning—is load-bearing for the 75% and 33% compression results, yet the manuscript supplies only the two end-to-end experiments and does not isolate whether tree depth, policy-mixing ratios, or pruning criteria transfer without per-architecture adjustment.
- [Abstract] Abstract: no quantitative quality metrics (FID, CLIP score, human preference, etc.), ablation tables, or per-architecture breakdowns are referenced to substantiate “limited generation quality” sacrifice or “negligible degradation,” leaving the central trade-off claim without measurable support.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central generalization claim—that a single TMP procedure works uniformly on MoE expert routing and DiT dense blocks without architecture-specific retuning—is load-bearing for the 75% and 33% compression results, yet the manuscript supplies only the two end-to-end experiments and does not isolate whether tree depth, policy-mixing ratios, or pruning criteria transfer without per-architecture adjustment.
Authors: TMP is structured so that the tree-based policy mixing operates at a level above architecture-specific details, allowing the same pruning procedure to be applied to MoE routing in HunyuanImage-3.0 and dense blocks in Z-Image turbo without per-architecture retuning. The two reported cases therefore serve as direct demonstrations of this property. We agree that explicit isolation of hyperparameter transfer (tree depth, mixing ratios) would strengthen the claim and will add a dedicated discussion of the design choices that enable architecture-agnostic application in the revision. revision: partial
-
Referee: [Abstract] Abstract: no quantitative quality metrics (FID, CLIP score, human preference, etc.), ablation tables, or per-architecture breakdowns are referenced to substantiate “limited generation quality” sacrifice or “negligible degradation,” leaving the central trade-off claim without measurable support.
Authors: The quality statements rest on qualitative visual inspection and the successful release of the pruned models for community use. We accept that the abstract would be improved by referencing any available quantitative or human-preference results and by clarifying the evaluation protocol; we will revise the abstract and add supporting details in the main text accordingly. revision: yes
Circularity Check
No circularity: empirical compression results rest on reported experiments, not self-referential definitions or fits
full rationale
The paper introduces TMP as a pruning framework and validates it via direct experiments on HunyuanImage-3.0 (80B→20B) and Z-Image turbo (6B→4B), reporting parameter counts and qualitative degradation. No equations, parameter-fitting steps, or derivation chains appear in the abstract or description. Claims do not reduce to self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations; the generalization across MoE/DiT is asserted as an empirical outcome rather than a mathematical identity. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fuhan Cai, Yong Guo, Jie Li, Wenbo Li, Jian Chen, and Xiangzhong Fang
Accessed: 2026-05-12. Fuhan Cai, Yong Guo, Jie Li, Wenbo Li, Jian Chen, and Xiangzhong Fang. Fastflux: Pruning flux with block-wise replacement and sandwich training. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp. 2507–2515,
2026
-
[2]
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699,
-
[3]
Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951,
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951,
-
[4]
Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. Oneig-bench: Omni-dimensional nuanced evaluation for image generation.arXiv preprint arXiv:2506.07977,
-
[5]
Structural pruning for diffusion models, 2023.URL https://arxiv
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Structural pruning for diffusion models, 2023.URL https://arxiv. org/abs/2305.10924,
arXiv 2023
-
[6]
Zigang Geng, Yibing Wang, Yeyao Ma, Chen Li, Yongming Rao, Shuyang Gu, Zhao Zhong, Qinglin Lu, Han Hu, Xiaosong Zhang, et al. X-omni: Reinforcement learning makes discrete autoregressive image generative models great again.arXiv preprint arXiv:2507.22058,
-
[7]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
-
[8]
Zongfang Liu, Shengkun Tang, Zongliang Wu, Xin Yuan, and Zhiqiang Shen. Diff-es: Stage-wise structural diffusion pruning via evolutionary search.arXiv preprint arXiv:2603.05105,
-
[9]
https://thinkingmachines.ai/blog/on-policy-distillation
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation. Jian Ma, Qirong Peng, Xujie Zhu, Peixing Xie, Chen Chen, and Haonan Lu. Pluggable pruning with contiguous layer distillation for diffusion transformers.arXiv preprint arXiv:2511.16156,
-
[10]
com/Tencent-Hunyuan/Hunyuan-A13B
URL https://github. com/Tencent-Hunyuan/Hunyuan-A13B. 7 Jiangshan Wang, Zeqiang Lai, Jiarui Chen, Jiayi Guo, Hang Guo, Xiu Li, Xiangyu Yue, and Chunchao Guo. Elastic diffusion transformer.arXiv preprint arXiv:2602.13993,
-
[11]
Yulin Wang, Zanlin Ni, Shiji Song, Le Yang, and Gao Huang. Revisiting locally supervised learning: an alternative to end-to-end training.arXiv preprint arXiv:2101.10832,
-
[12]
Qwen-image technical report.arXiv preprint arXiv:2508.02324,
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324,
-
[13]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, et al. Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer.arXiv preprint arXiv:2501.18427,
-
[14]
Chaojie Yang, Tian Li, Yue Zhang, and Jun Gao. Amber-image: Efficient compression of large-scale diffusion transformers.arXiv preprint arXiv:2602.17047, 2026a. Xiaomeng Yang, Lei Lu, Qihui Fan, Changdi Yang, Juyi Lin, Yanzhi Wang, Xuan Zhang, and Shangqian Gao. Alter: All-in-one layer pruning and temporal expert routing for efficient diffusion generation....
-
[15]
Caleb Zheng and Eli Shlizerman. Igsm: Improved geometric and sensitivity matching for finetuning pruned diffusion models.arXiv preprint arXiv:2506.05398,
-
[16]
Obs-diff: Accurate pruning for diffusion models in one-shot.arXiv preprint arXiv:2510.06751,
Junhan Zhu, Hesong Wang, Mingluo Su, Zefang Wang, and Huan Wang. Obs-diff: Accurate pruning for diffusion models in one-shot.arXiv preprint arXiv:2510.06751,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.