FR-DETR: Frequency and Recurrent Feature Refinement for Robust Object Detection under Adverse Weather
Pith reviewed 2026-06-30 06:46 UTC · model grok-4.3
The pith
FR-DETR refines features inside the detector using frequency separation and recurrent guidance to outperform enhancer cascades in adverse weather at lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
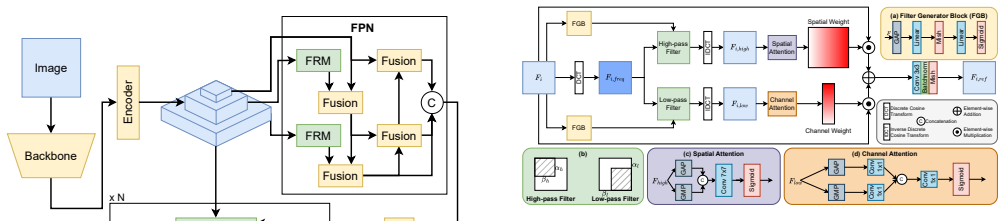
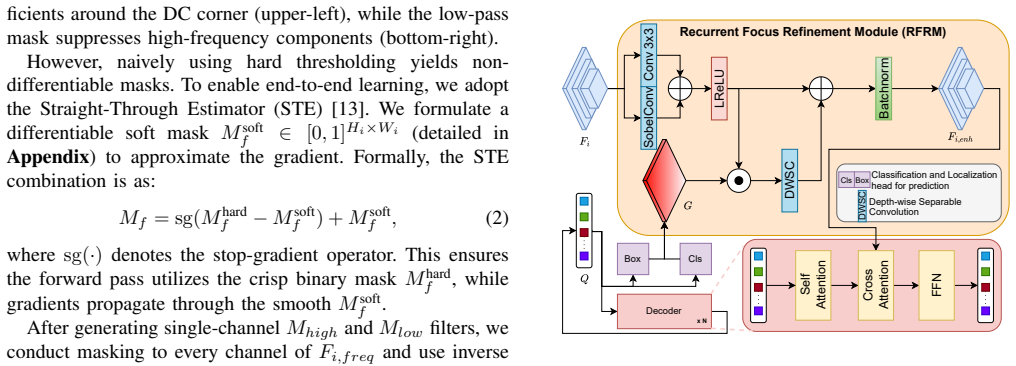
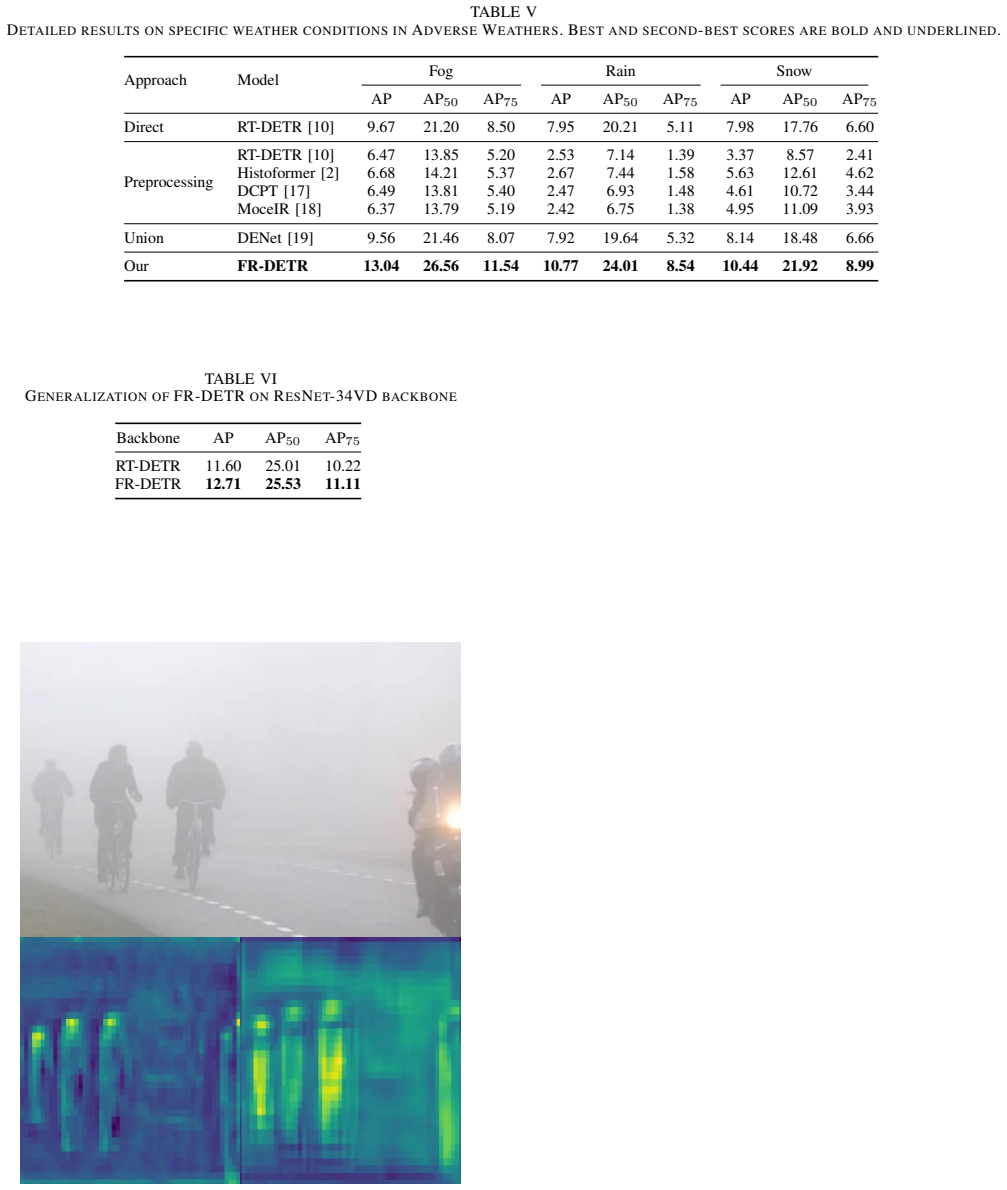
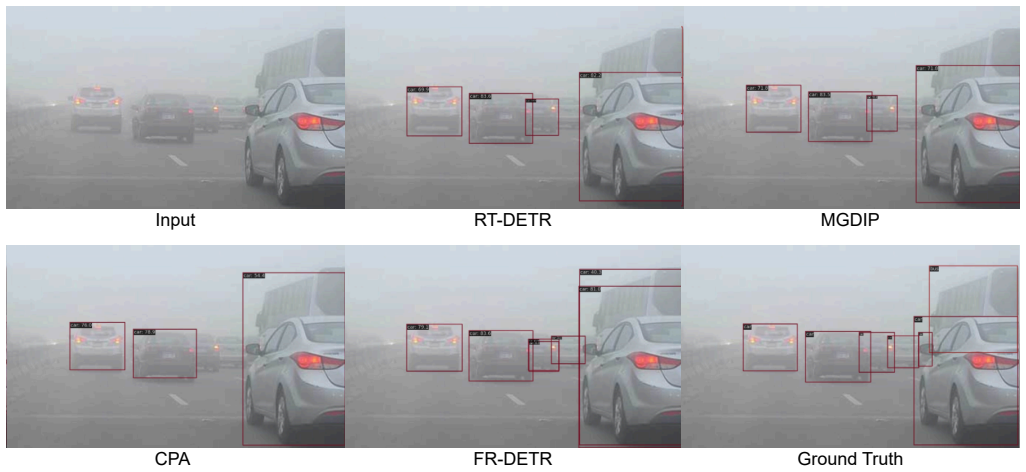
FR-DETR achieves superior detection accuracy under adverse weather while being significantly more computationally efficient than enhancer-based methods by designing a Frequency Refinement Module that dynamically separates and reweights low- and high-frequency components to improve foreground-background discrimination, and a Recurrent Focus Refinement Module that iteratively refines features using coarse predictions as guidance.
What carries the argument
Frequency Refinement Module that separates and reweights frequency components plus Recurrent Focus Refinement Module that performs iterative refinement guided by coarse predictions, both operating on detector features rather than input images.
If this is right
- Detector-centric refinement avoids the redundant feature extraction that occurs when an enhancer and detector are cascaded.
- Focusing enhancement on regions of interest using frequency cues improves handling of domain shifts without processing the entire image.
- Recurrent refinement driven by coarse predictions allows progressive improvement of feature quality inside a single forward pass.
- The resulting efficiency gains make the approach more suitable for deployment where compute budgets are limited.
Where Pith is reading between the lines
- The same frequency and recurrent modules could be tested on other degradations such as low light or sensor noise to check generality.
- Replacing the base detector with newer transformer variants might compound the accuracy gains without changing the refinement logic.
- The focus on internal feature refinement rather than image restoration opens a path toward end-to-end trainable robust detectors.
Load-bearing premise
Dynamically separating and reweighting frequency components plus iterative refinement guided by coarse predictions will reliably improve foreground-background discrimination across diverse adverse weather conditions without introducing new artifacts or missing critical object details.
What would settle it
A benchmark experiment on standard adverse-weather datasets where FR-DETR shows either lower average precision or higher inference time than an enhancer paired with the same base detector.
Figures






read the original abstract
Object detection under adverse weather remains challenging due to severe visual degradations and domain shifts. Existing enhancer-based approaches attempt to improve detection by cascading an enhancer with a detector, but they introduce redundant feature extraction and incur high computational cost with limited accuracy gains when paired with SOTA detectors. We propose FR-DETR, a detector-centric framework that refines features rather than images, focusing enhancement on regions of interest and leveraging frequency-domain cues. Specifically, we design (I) a Frequency Refinement Module that dynamically separates and reweights low- and high-frequency components to improve foreground-background discrimination, and (II) a Recurrent Focus Refinement Module (RFRM) that iteratively refines features using coarse predictions as guidance. Extensive experiments demonstrate that FR-DETR achieves superior detection accuracy under adverse weather while being significantly more computationally efficient than enhancer-based methods. Our implementation is available at https://github.com/ducnt1210/FR-DETR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FR-DETR, a detector-centric framework for object detection under adverse weather. It introduces a Frequency Refinement Module that dynamically separates and reweights low- and high-frequency components to improve foreground-background discrimination, and a Recurrent Focus Refinement Module (RFRM) that performs iterative feature refinement guided by coarse predictions. The approach avoids full-image enhancement pipelines and claims superior detection accuracy under adverse conditions together with significantly lower computational cost than enhancer-based baselines. Code is released at https://github.com/ducnt1210/FR-DETR.
Significance. If the reported gains hold, the work offers a practical efficiency advantage by embedding refinement inside the detector rather than cascading a separate enhancer network. The frequency-domain reweighting and recurrent prediction-guided refinement are targeted at foreground discrimination under domain shift. The public implementation supports reproducibility and allows direct verification of the efficiency claims.
minor comments (3)
- Abstract: the claim of 'superior detection accuracy' and 'significantly more computationally efficient' is stated without any numerical values, baselines, or dataset names; adding one or two key metrics (e.g., mAP delta and FPS) would strengthen the summary.
- §3 (method): the precise mechanism for 'dynamically separates and reweights' frequency components should be accompanied by an explicit equation or pseudocode so readers can reproduce the reweighting operation without ambiguity.
- §4 (experiments): while the abstract asserts extensive experiments, the paper should ensure that all reported tables include standard deviations across multiple runs and clearly list the adverse-weather datasets and weather-specific splits used.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of FR-DETR, the accurate summary of our contributions, and the recommendation for minor revision. No major comments were provided in the report, so we have no specific points requiring rebuttal or revision at this stage. We remain available to address any additional feedback.
Circularity Check
No significant circularity: empirical architecture proposal
full rationale
The manuscript introduces FR-DETR as an engineering framework consisting of two explicitly designed modules (Frequency Refinement Module for dynamic frequency separation/reweighting and Recurrent Focus Refinement Module for iterative refinement from coarse predictions). These are presented as detector-centric design choices motivated by efficiency and foreground discrimination goals, not as outputs of any derivation, equation, or fitted parameter. The central claims rest on experimental validation across adverse weather datasets rather than any self-referential reduction, uniqueness theorem, or ansatz smuggled via citation. No equations, predictions-by-construction, or load-bearing self-citations appear in the abstract or module descriptions. This is a standard empirical CV contribution whose validity is tested externally via benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Robust object detection in challenging weather conditions,
Himanshu Gupta, Oleksandr Kotlyar, Henrik Andreasson, and Achim J. Lilienthal, “Robust object detection in challenging weather conditions,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), January 2024, pp. 7523–7532
2024
-
[2]
Restoring images in adverse weather conditions via histogram transformer,
Shangquan Sun, Wenqi Ren, Xinwei Gao, Rui Wang, and Xiaochun Cao, “Restoring images in adverse weather conditions via histogram transformer,” inComputer Vision – ECCV 2024, Ale ˇs Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and G ¨ul Varol, Eds., Cham, 2025, pp. 111–129, Springer Nature Switzerland
2024
-
[3]
Multi-scale boosted dehazing network with dense feature fusion,
Hang Dong, Jinshan Pan, Lei Xiang, Zhe Hu, Xinyi Zhang, Fei Wang, and Ming-Hsuan Yang, “Multi-scale boosted dehazing network with dense feature fusion,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2154–2164
2020
-
[4]
Depth- attentional features for single-image rain removal,
Xiaowei Hu, Chi-Wing Fu, Lei Zhu, and Pheng-Ann Heng, “Depth- attentional features for single-image rain removal,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[5]
Multitask aet with orthogonal tangent regularity for dark object detection,
Ziteng Cui, Guo-Jun Qi, Lin Gu, Shaodi You, Zenghui Zhang, and Tatsuya Harada, “Multitask aet with orthogonal tangent regularity for dark object detection,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 2533–2542
2021
-
[6]
Rethink- ing image restoration for object detection,
Shangquan Sun, Wenqi Ren, Tao Wang, and Xiaochun Cao, “Rethink- ing image restoration for object detection,” inAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds. 2022, vol. 35, pp. 4461–4474, Curran Associates, Inc
2022
-
[7]
Image-adaptive yolo for object detection in adverse weather conditions,
Wenyu Liu, Gaofeng Ren, Runsheng Yu, Shi Guo, Jianke Zhu, and Lei Zhang, “Image-adaptive yolo for object detection in adverse weather conditions,” inProceedings of the AAAI Conference on Artificial Intelligence, 2022
2022
-
[8]
Gdip: Gated differentiable image processing for object detection in adverse conditions,
Sanket Kalwar, Dhruv Patel, Aakash Aanegola, Krishna Reddy Konda, Sourav Garg, and K Madhava Krishna, “Gdip: Gated differentiable image processing for object detection in adverse conditions,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 7083–7089
2023
-
[9]
Cpa-enhancer: Chain-of-thought prompted adaptive enhancer for downstream vision tasks under unknown degradations,
Yuwei Zhang, Yan Wu, Yanming Liu, and Xinyue Peng, “Cpa-enhancer: Chain-of-thought prompted adaptive enhancer for downstream vision tasks under unknown degradations,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[10]
Detrs beat yolos on real- time object detection,
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen, “Detrs beat yolos on real- time object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 16965–16974
2024
-
[11]
DINO: DETR with improved denoising anchor boxes for end-to-end object detection,
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum, “DINO: DETR with improved denoising anchor boxes for end-to-end object detection,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. 2023, OpenReview.net
2023
-
[12]
Detecting camouflaged object in frequency domain,
Yijie Zhong, Bo Li, Lv Tang, Senyun Kuang, Shuang Wu, and Shouhong Ding, “Detecting camouflaged object in frequency domain,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4494–4503
2022
-
[13]
Estimating or propagating gradients through stochastic neurons for conditional computation,
Yoshua Bengio, Nicholas L ´eonard, and Aaron Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” 2013
2013
-
[14]
Cbam: Convolutional block attention module,
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon, “Cbam: Convolutional block attention module,” inComputer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8–14, 2018, Proceedings, Part VII, Berlin, Heidelberg, 2018, pp. 3–19, Springer-Verlag
2018
-
[15]
Revitalizing convolutional network for image restoration,
Yuning Cui, Wenqi Ren, Xiaochun Cao, and Alois Knoll, “Revitalizing convolutional network for image restoration,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 9423–9438, Dec. 2024
2024
-
[16]
Phatnet: A physics-guided haze transfer network for domain-adaptive real-world image dehazing,
Fu-Jen Tsai, Yan-Tsung Peng, Yen-Yu Lin, and Chia-Wen Lin, “Phatnet: A physics-guided haze transfer network for domain-adaptive real-world image dehazing,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 5591–5600
2025
-
[17]
Universal image restoration pre-training via degradation classification,
JiaKui Hu, Lujia Jin, Zhengjian Yao, and Yanye Lu, “Universal image restoration pre-training via degradation classification,” inICLR, 2025
2025
-
[18]
Complexity experts are task- discriminative learners for any image restoration,
Eduard Zamfir, Zongwei Wu, Nancy Mehta, Yuedong Tan, Danda Pani Paudel, Yulun Zhang, and Radu Timofte, “Complexity experts are task- discriminative learners for any image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 12753–12763
2025
-
[19]
Denet: Detection-driven enhancement network for object detection under ad- verse weather conditions,
Qingpao Qin, Kan Chang, Mengyuan Huang, and Guiqing Li, “Denet: Detection-driven enhancement network for object detection under ad- verse weather conditions,” inProceedings of the Asian Conference on Computer Vision (ACCV), December 2022, pp. 2813–2829
2022
-
[20]
The pascal visual object classes (voc) challenge,
Mark Everingham, Luc Gool, Christopher K. Williams, John Winn, and Andrew Zisserman, “The pascal visual object classes (voc) challenge,” Int. J. Comput. Vision, vol. 88, no. 2, pp. 303–338, June 2010
2010
-
[21]
Benchmarking single-image dehazing and beyond,
Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang, “Benchmarking single-image dehazing and beyond,”IEEE Transactions on Image Processing, vol. 28, no. 1, pp. 492–505, 2019
2019
-
[22]
Mode: A model-agnostic frame- work for object detection under adverse weather conditions,
Tuan-Duc Nguyen and Duc-Trong Le, “Mode: A model-agnostic frame- work for object detection under adverse weather conditions,”Pattern Recognition, vol. 173, pp. 112868, 2026
2026
-
[23]
Benchmarking neural network robustness to common corruptions and perturbations,
Dan Hendrycks and Thomas Dietterich, “Benchmarking neural network robustness to common corruptions and perturbations,”Proceedings of the International Conference on Learning Representations, 2019
2019
-
[24]
Dsnet: Joint semantic learning for object detection in inclement weather conditions,
Shih-Chia Huang, Trung-Hieu Le, and Da-Wei Jaw, “Dsnet: Joint semantic learning for object detection in inclement weather conditions,” IEEE TPAMI, vol. 43, no. 8, pp. 2623–2633, 2021
2021
-
[25]
Multiscale domain adaptive yolo for cross-domain object detection,
Mazin Hnewa and Hayder Radha, “Multiscale domain adaptive yolo for cross-domain object detection,” inICIP, 2021, pp. 3323–3327
2021
-
[26]
Multiscale domain adaptive yolo for cross-domain object detection,
Mazin Hnewa and Hayder Radha, “Multiscale domain adaptive yolo for cross-domain object detection,” in2021 IEEE International Conference on Image Processing (ICIP), 2021, pp. 3323–3327
2021
-
[27]
Yolov3: An incremental improve- ment,
Joseph Redmon and Ali Farhadi, “Yolov3: An incremental improve- ment,” 2018
2018
-
[28]
Frequency perception network for camouflaged object detection,
Runmin Cong, Mengyao Sun, Sanyi Zhang, Xiaofei Zhou, Wei Zhang, and Yao Zhao, “Frequency perception network for camouflaged object detection,” inProceedings of the 31st ACM International Conference on Multimedia, New York, NY , USA, 2023, MM ’23, pp. 1179–1189, Association for Computing Machinery
2023
-
[29]
Frequency-spatial entanglement learning for camouflaged object detec- tion,
Yanguang Sun, Chunyan Xu, Jian Yang, Hanyu Xuan, and Lei Luo, “Frequency-spatial entanglement learning for camouflaged object detec- tion,” inComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part VI, Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and G ¨ul Varol,...
2024
-
[30]
Hs-fpn: high frequency and spatial perception fpn for tiny object detection,
Zican Shi, Jing Hu, Jie Ren, Hengkang Ye, Xuyang Yuan, Yan Ouyang, Jia He, Bo Ji, and Junyu Guo, “Hs-fpn: high frequency and spatial perception fpn for tiny object detection,” inProceedings of the Thirty- Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Sympo...
2025
-
[31]
Wavelet and prototype augmented query-based transformer for pixel-level surface defect detection,
Feng Yan, Xiaoheng Jiang, Yang Lu, Jiale Cao, Dong Chen, and Min- gliang Xu, “Wavelet and prototype augmented query-based transformer for pixel-level surface defect detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 23860–23869
2025
-
[32]
End-to-end object detection with transformers,
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko, “End-to-end object detection with transformers,” inComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part I, Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, Eds. 2020, vol. 123...
2020
-
[33]
Deformable DETR: deformable transformers for end-to- end object detection,
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai, “Deformable DETR: deformable transformers for end-to- end object detection,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. 2021, OpenReview.net
2021
-
[34]
DN-DETR: accelerate DETR training by introducing query denoising,
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M. Ni, and Lei Zhang, “DN-DETR: accelerate DETR training by introducing query denoising,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. 2022, pp. 13609–13617, IEEE
2022
-
[35]
Detrs with hybrid matching,
Ding Jia, Yuhui Yuan, Haodi He, Xiaopei Wu, Haojun Yu, Weihong Lin, Lei Sun, Chao Zhang, and Han Hu, “Detrs with hybrid matching,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. 2023, pp. 19702–19712, IEEE
2023
-
[36]
Erup-yolo: Enhancing object detection robustness for adverse weather condition by unified image-adaptive processing,
Yuka Ogino, Yuho Shoji, Takahiro Toizumi, and Atsushi Ito, “Erup-yolo: Enhancing object detection robustness for adverse weather condition by unified image-adaptive processing,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025, pp. 8597–8605
2025
-
[37]
The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results,
M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results,” http://www.pascal- network.org/challenges/VOC/voc2012/workshop/index.html, 2012
2012
-
[38]
Vision and the atmo- sphere,
Srinivasa G. Narasimhan and Shree K. Nayar, “Vision and the atmo- sphere,”Int. J. Comput. Vision, vol. 48, no. 3, pp. 233–254, July 2002
2002
-
[39]
Getting to know low-light images with the exclusively dark dataset,
Yuen Peng Loh and Chee Seng Chan, “Getting to know low-light images with the exclusively dark dataset,”Computer Vision and Image Understanding, vol. 178, pp. 30–42, 2019
2019
-
[40]
Semantic foggy scene understanding with synthetic data,
Christos Sakaridis, Dengxin Dai, and Luc Van Gool, “Semantic foggy scene understanding with synthetic data,”International Journal of Computer Vision, vol. 126, no. 9, pp. 973–992, Sep 2018
2018
-
[41]
Physics-based rendering for improving robustness to rain,
Shirsendu Sukanta Halder, Jean-Franc ¸ois Lalonde, and Raoul de Charette, “Physics-based rendering for improving robustness to rain,” inICCV, 2019
2019
-
[42]
Single image deraining: A compre- hensive benchmark analysis,
Siyuan Li, Iago Breno Araujo, Wenqi Ren, Zhangyang Wang, Eric K. Tokuda, Roberto Hirata Junior, Roberto Cesar-Junior, Jiawan Zhang, Xiaojie Guo, and Xiaochun Cao, “Single image deraining: A compre- hensive benchmark analysis,”IEEE Conference on Computer Vision and Pattern Recognition, 2019
2019
-
[43]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning,
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell, “Bdd100k: A diverse driving dataset for heterogeneous multitask learning,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[44]
ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding,
Christos Sakaridis, Dengxin Dai, and Luc Van Gool, “ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding,” inICCV, October 2021
2021
-
[45]
Desnownet: Context-aware deep network for snow removal,
Yun-Fu Liu, Da-Wei Jaw, Shih-Chia Huang, and Jenq-Neng Hwang, “Desnownet: Context-aware deep network for snow removal,”IEEE Transactions on Image Processing, vol. 27, no. 6, pp. 3064–3073, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.